
Pandas
pandas 란, 실제로 데이터 처리(분석)을 하기 위해 사용하게 되는 실제적인 module 이다.
pandas 가 사용하는 자료구조는 2 가지가 존재한다.
1. Series
1차원 ndarray 를 기반으로 해서 만드는 자료구조
2. DataFrame
1차원 ndarray 를 기반으로 만드는 series 를 열 로 삼아서 여러 개의 series 를 세로로 이러 붙여 만든 2차원 자료 구조가 존재한다.
그것이 DataFrame 이다.
Series
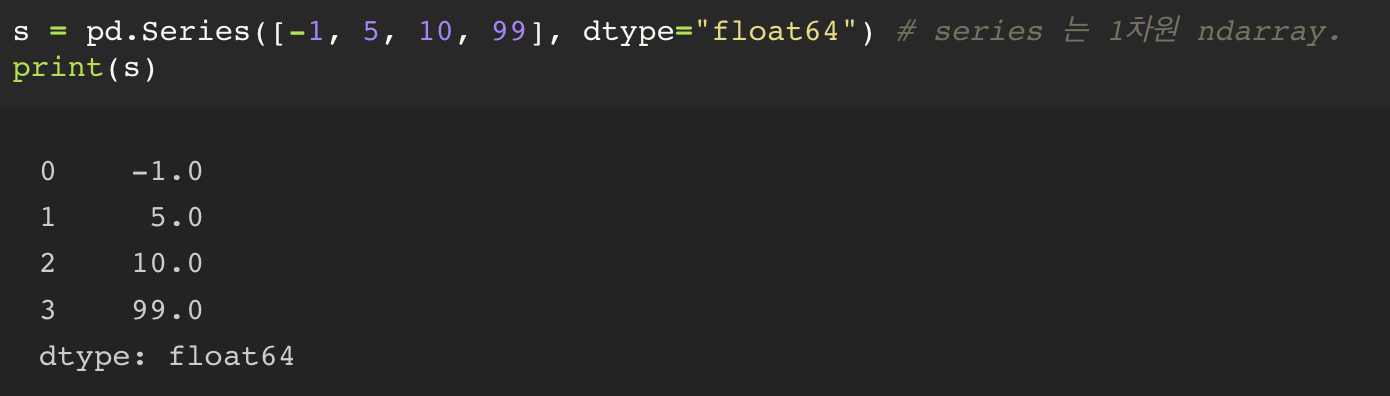
series 생성 시, 인자로는 list 가 들어가게 된다.
다만, 정수 값을 입력하게 되면 데이터 클래스가 정수형으로 들어가게 된다. series 의 산술 시에는 대부분 실수를 기반으로 하기 때문에 dtype 으로 float64 라는 데이터 타입을 같이 선언해줄 수 있다.
series 는 가지고 있는 데이터를 세로로 표현한다.
가장 먼저 앞에 나오는 숫자는 index 를 의미하고, 그 값이 출력된다. 가장 마지막으로 해당 ndarray 의 dtype 이 나오게 된다.
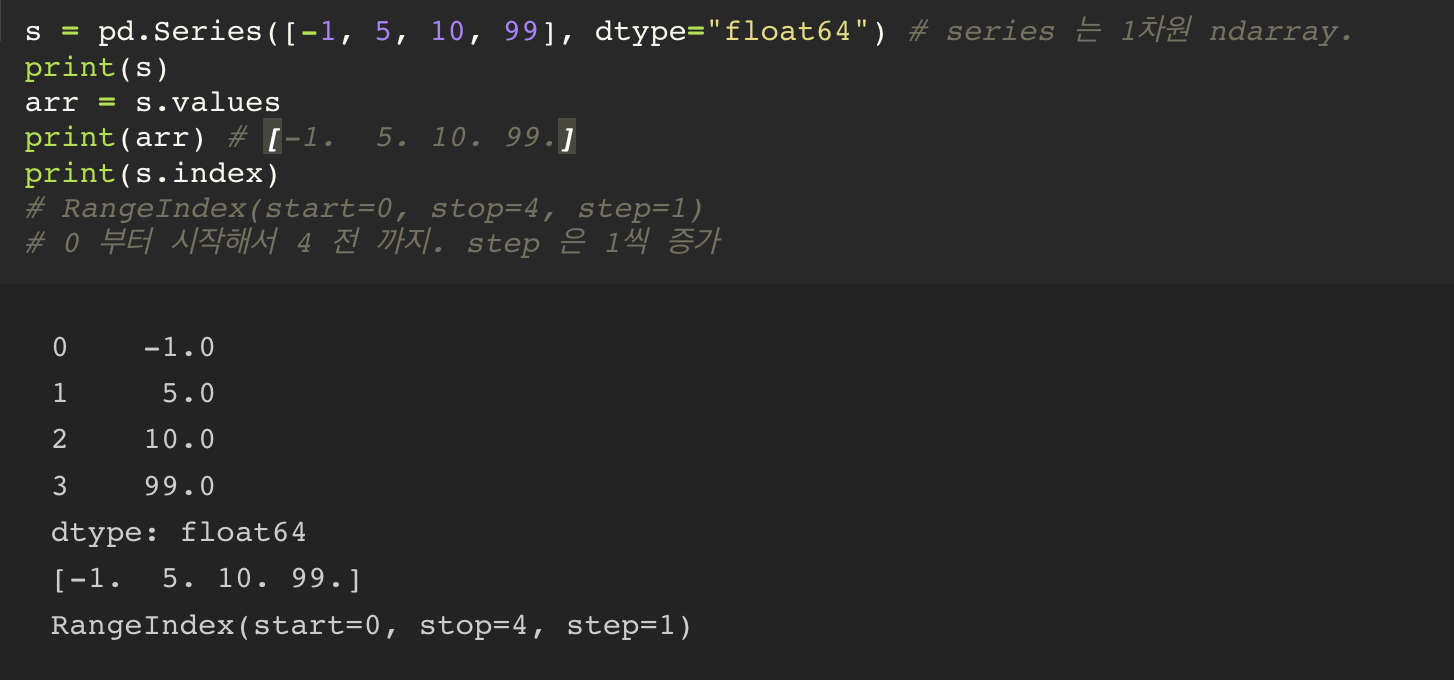
seires 에서 values 라는 속성을 통해서 series 를 ndarray 로 변환할 수 있다.
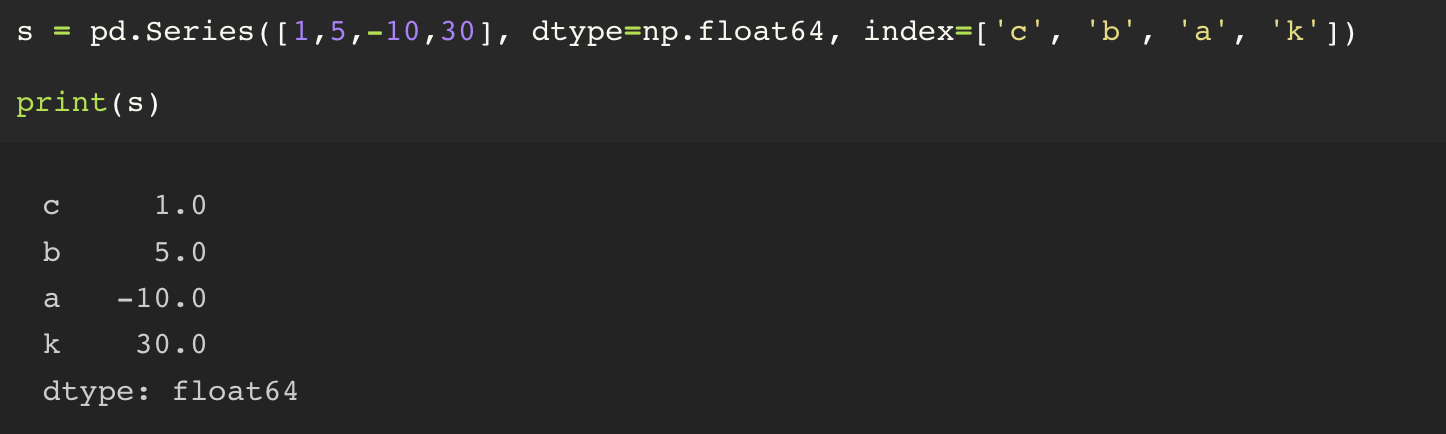
또한, index 를 지정함에 있어서 무조건적으로 정수의 index만 사용하는 것이 아니라, 임의의 사용자가 지정한 index 값을 지정해줄 수 있다.

그러면 정수의 index 뿐만 아니라, 사용자가 지정한 index 도 같이 사용이 가능해진다.
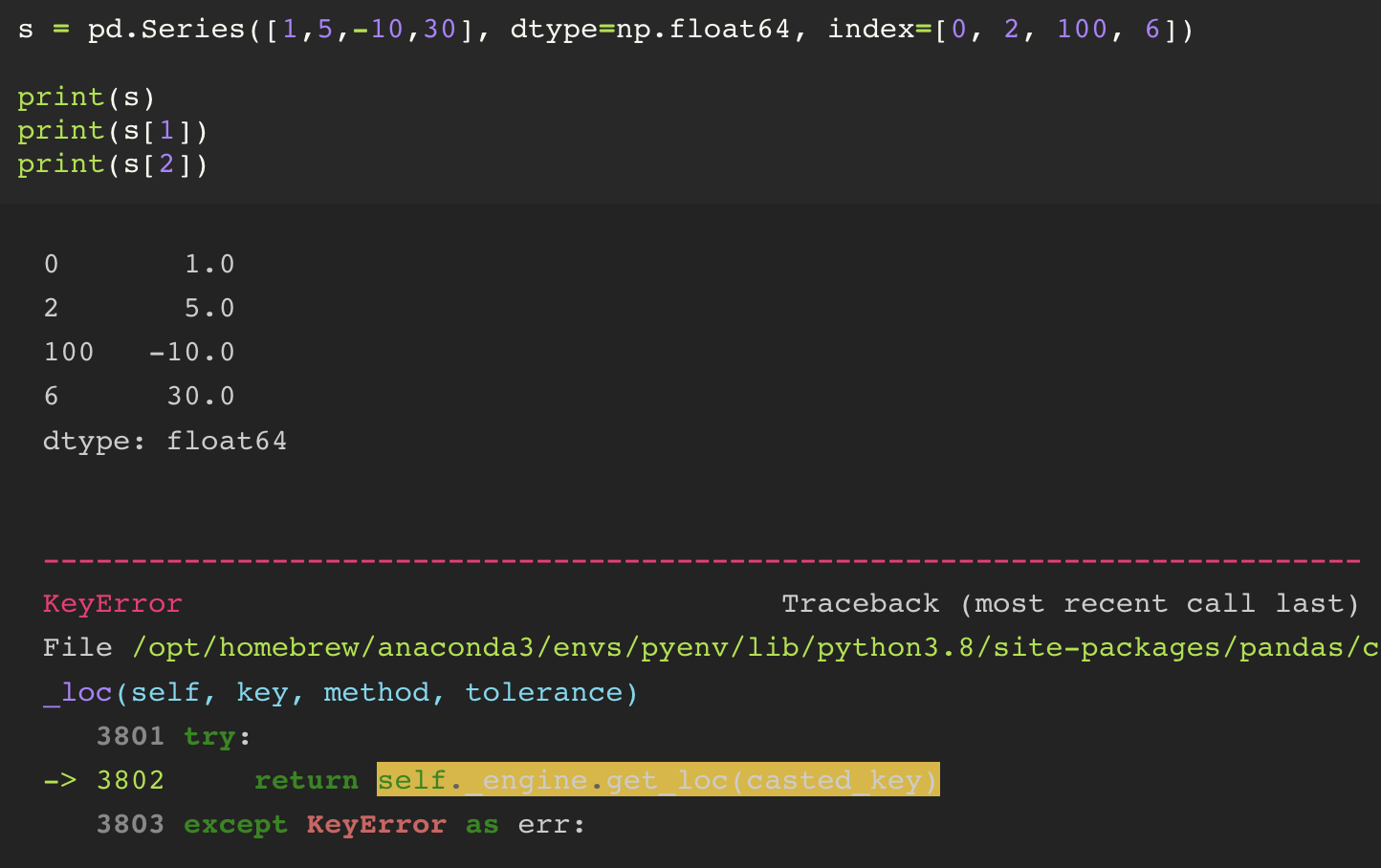
주의하야 할 점으로, 사용자 지정 index 를 숫자타입으로도 지정이 가능하다.
그런데, 숫자타입으로 지정할 경우 default 로 생기게 되는 정수 타입의 index 가 사용이 불가능해진다.
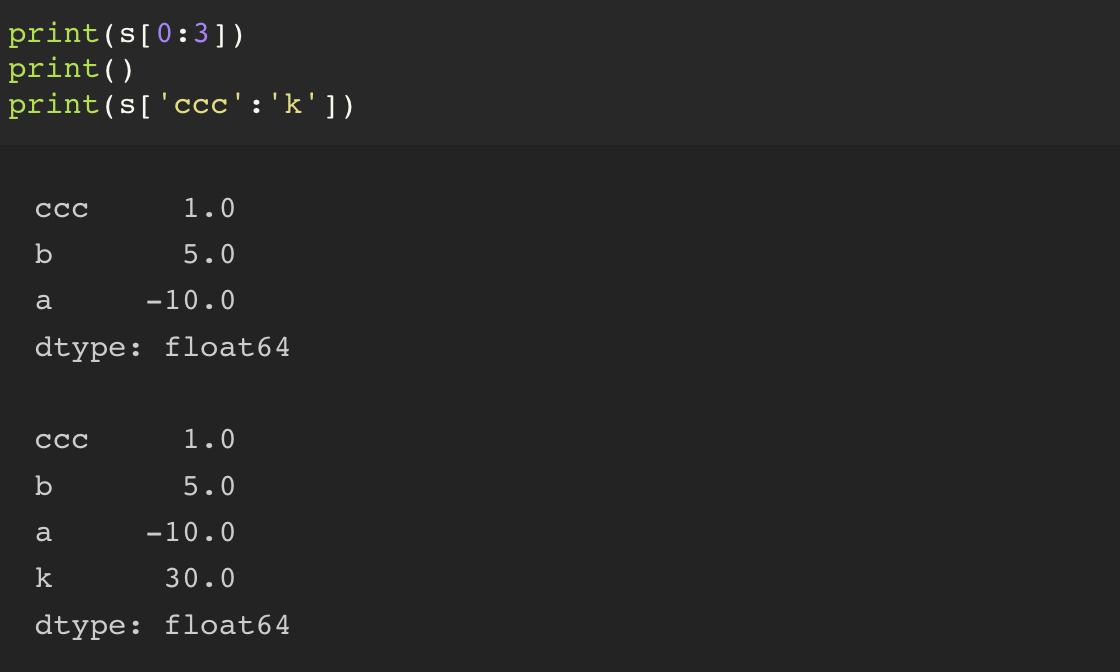
default index 로 슬라이싱을 하게 되면, 가장 마지막에 적은 데이터는 exclusive 된다.
그러나, 사용자 지정 index 로 슬라이싱을 하게 되면 가장 마지막에 적은 데이터 또한 inclusive 된다.
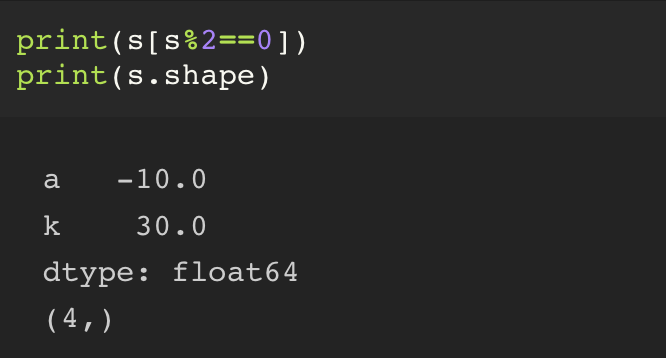
Series 에는 boolean_mask indexing, fancy indexing 모두 가능하다.
또한 shape 를 이용해서 데이터의 갯수나 차원의 종류도 알 수 있다.
또한 numpy 의 sum(), average() .. 와 같은 집계함수도 모두 사용이 가능하다.
dictionary 를 이용해 Series 만들기
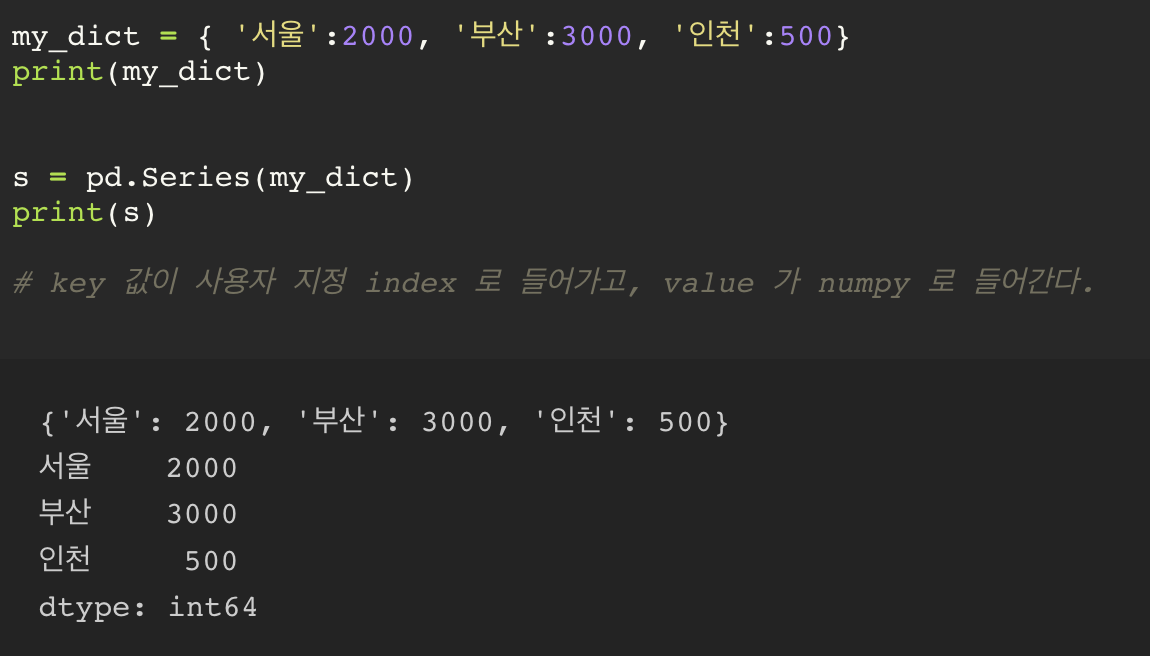
key 값이 사용자 지정 index 로 들어가고, value 가 numpy 로 들어간다.
결국, Series 는 1차원 ndarray 에 사용자 지정 index 를 추가한 자료구조라고 볼 수 있다.
일반적으로 Series 를 직접 만들어 사용하는 경우는 많지 않다. 대부분 DataFrame 을 사용한다.(훨씬 편하고, 기능도 많기 때문)
DataFrame
Excel 과 동일하다. 즉 테이블 구조이다.
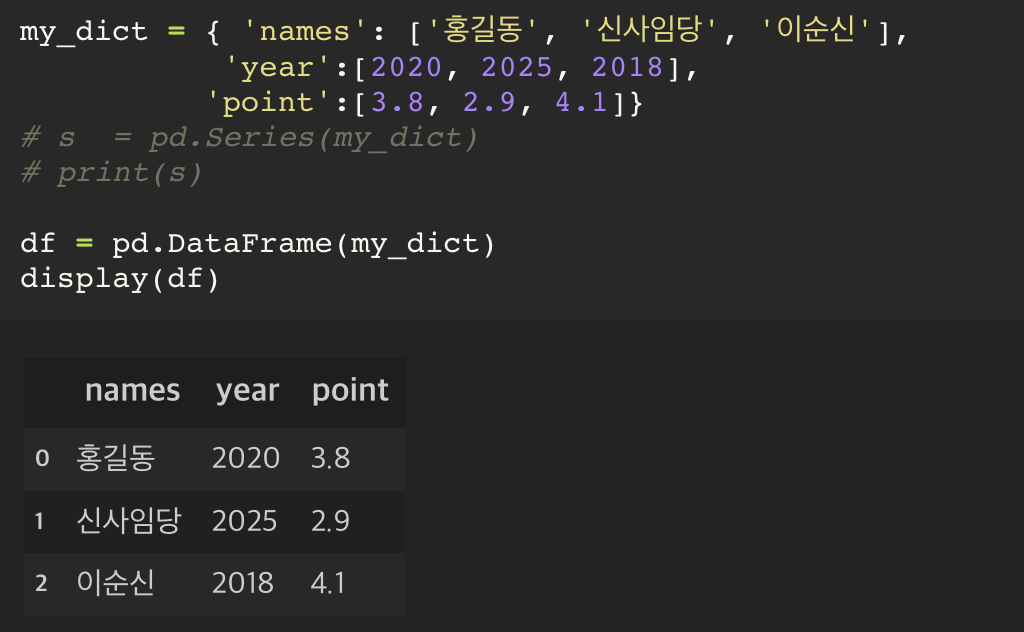
print() 와 display() 의 차이점으로 인해서, df(DataFarame) 의 경우에는 display() 가 출력에 좀 더 적합하다.
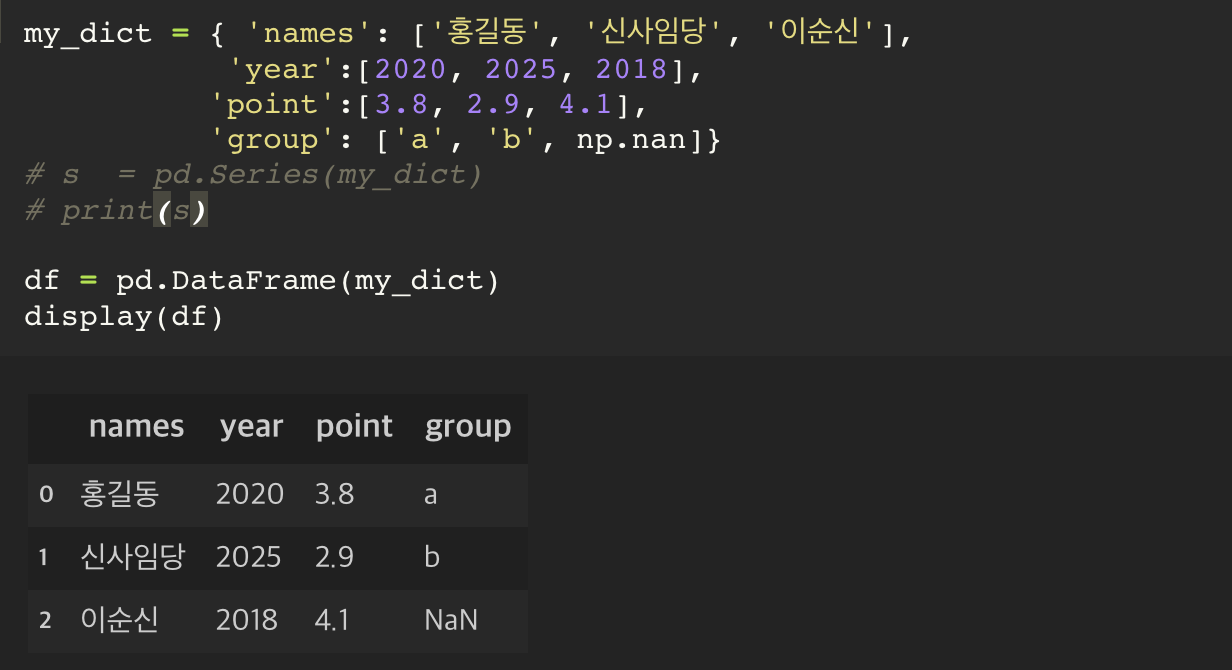
만약, 데이터가 없는 상태에서 DataFrame 안에 값을 넣으려면, np.nan 이라는 키워드를 사용해서라도 빈 값임을 나타내주는 단계가 필요하다.
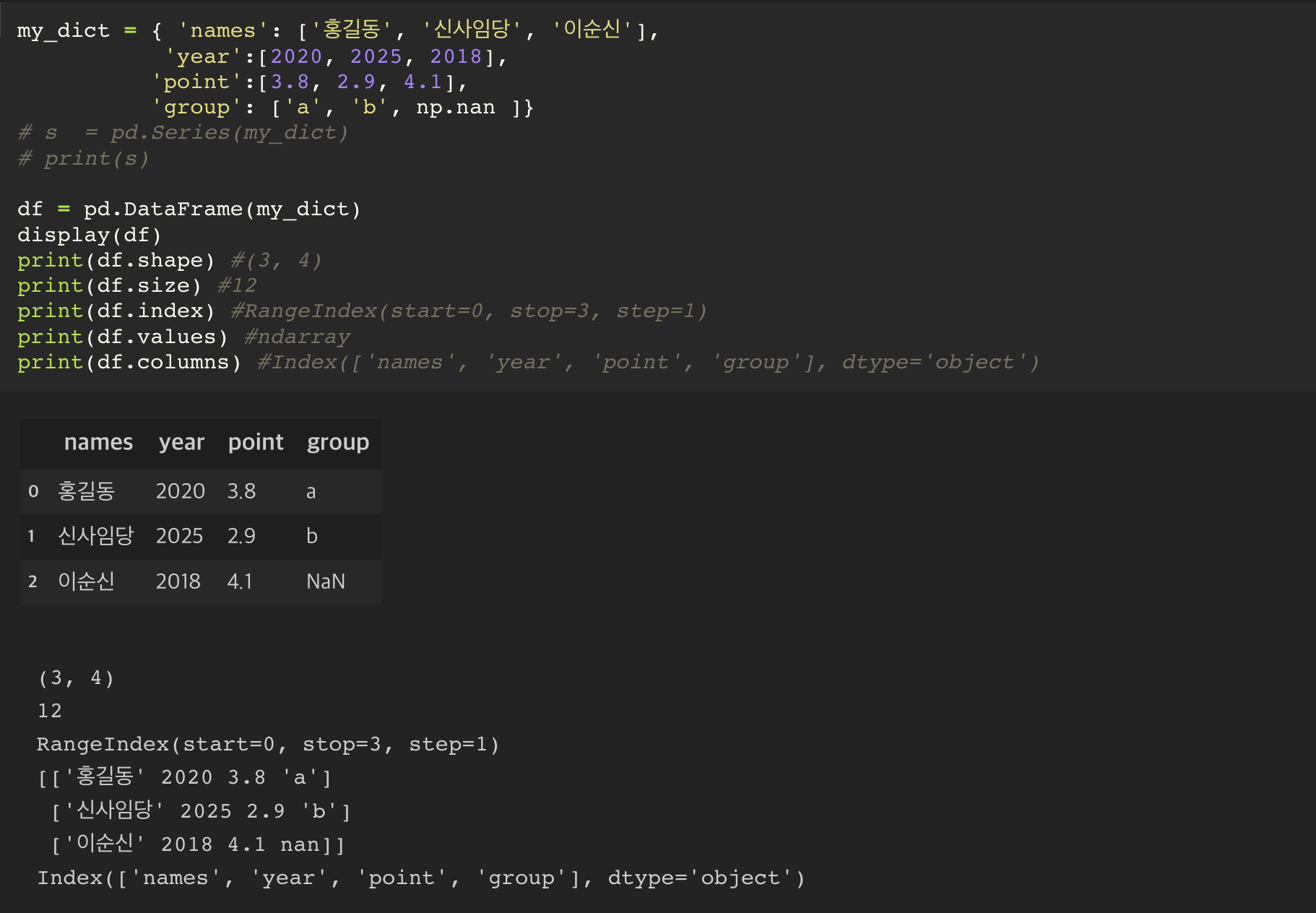
그 외에 DataFrame 에서 사용하게 되는 여러 함수들
- shape : df 의 shape
- size : df 의 전체 data 갯수
- index : df 의 rangeIndex
- values : df 를 ndarray 화
- columns : df 의 columns 를 출력
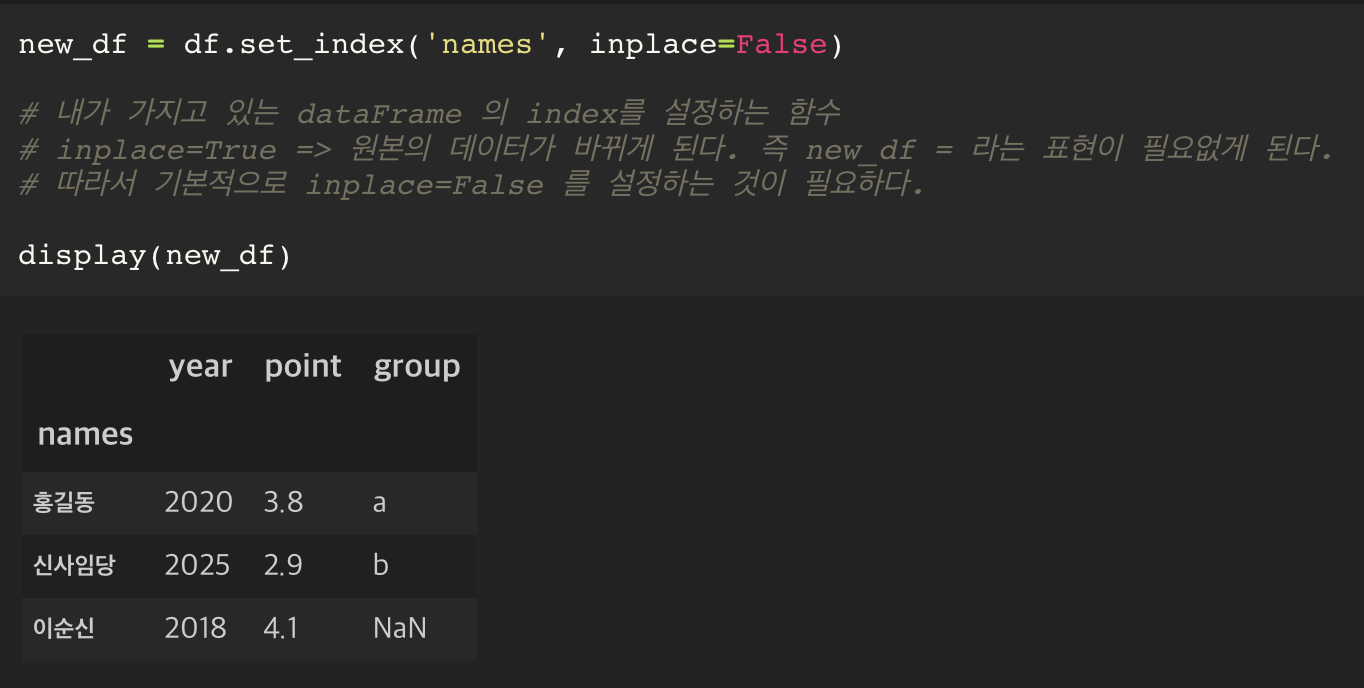
set_index() 라는 함수를 통해서 columns 중 하나를 index 로 만들어서 df 를 만들 수도 있다.
외부 파일을 통해 DataFrame 를 만들기
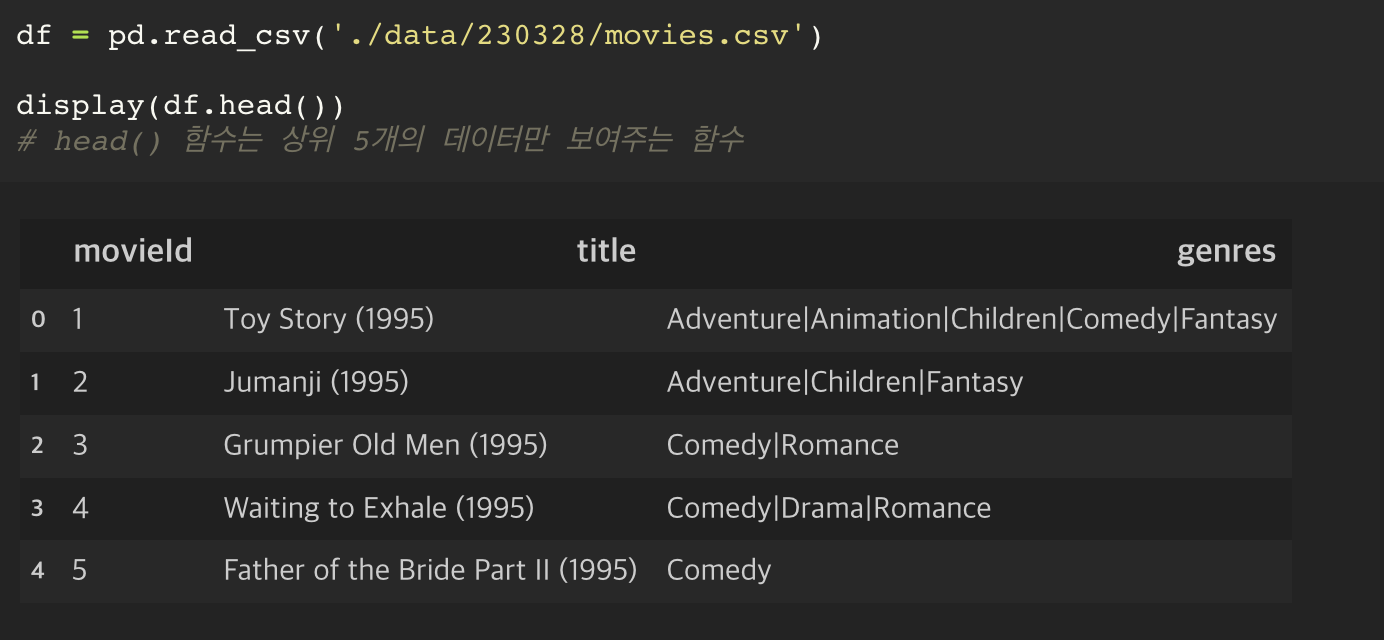
df.read_csv('경로') 라는 함수를 통해서 파일을 읽을 수 있다. 이 때, 시작하게 되는 경로는 로컬에서 설정해놓은 jupyter notebook 의 시작 디렉토리이다.
head() 함수는 상위 5개의 데이터만 보여주는 함수
이 방법 외에도 open api, database 로 부터 데이터를 받아서 DataFrame 를 생성할 수도 있다.
DataFrame 의 데이터를 조작하기
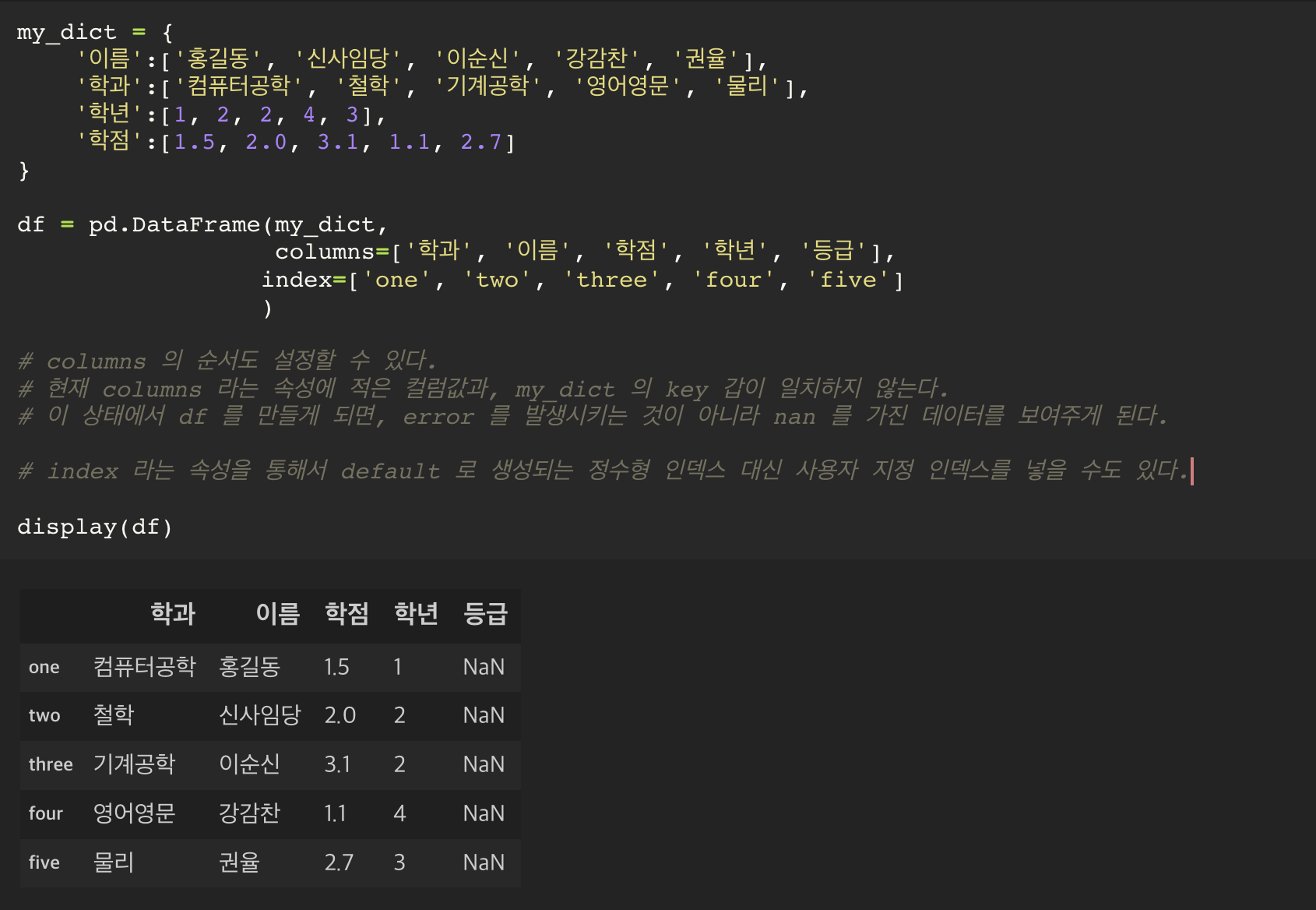
columns 의 순서도 설정할 수 있다.
현재 columns 라는 속성에 적은 컬럼값과, my_dict 의 key 갑이 일치하지 않는다.
이 상태에서 df 를 만들게 되면, error 를 발생시키는 것이 아니라 nan 를 가진 데이터를 보여주게 된다.
index 라는 속성을 통해서 default 로 생성되는 정수형 인덱스 대신 사용자 지정 인덱스를 넣을 수도 있다.
df.describe()
계산이 가능한 컬럼에 대해서 기본적인 통계 정보를 알려준다.
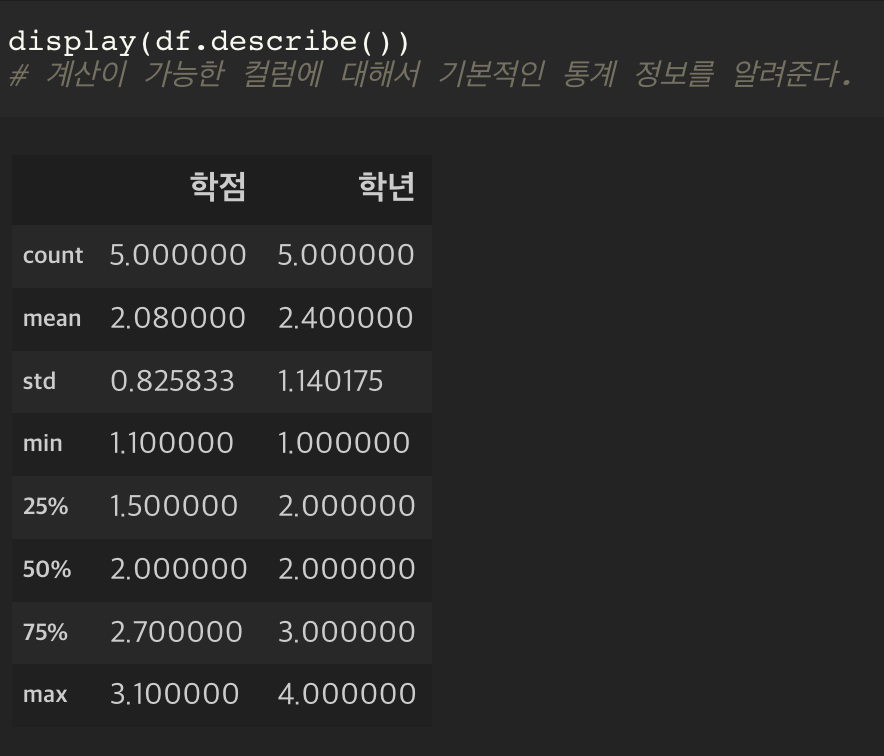
| 용어 | 의미 |
|---|---|
| count | 갯수 |
| mean | 평균 |
| std | 표준편차 |
| min | 최소값 |
| 25% | 1사분위 |
| 50% | 2사분위 |
| 75% | 3사분위 |
| max | 최대값 |
원하는 columns 만 뽑기
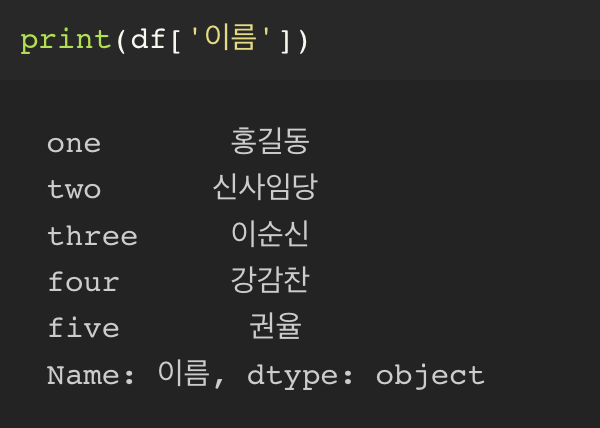
이렇게 추출된 것은 결국 하나의 Series 가 된다.
또한, 숫자형이 아닌 데이터는 모두 Object 타입이 된다.
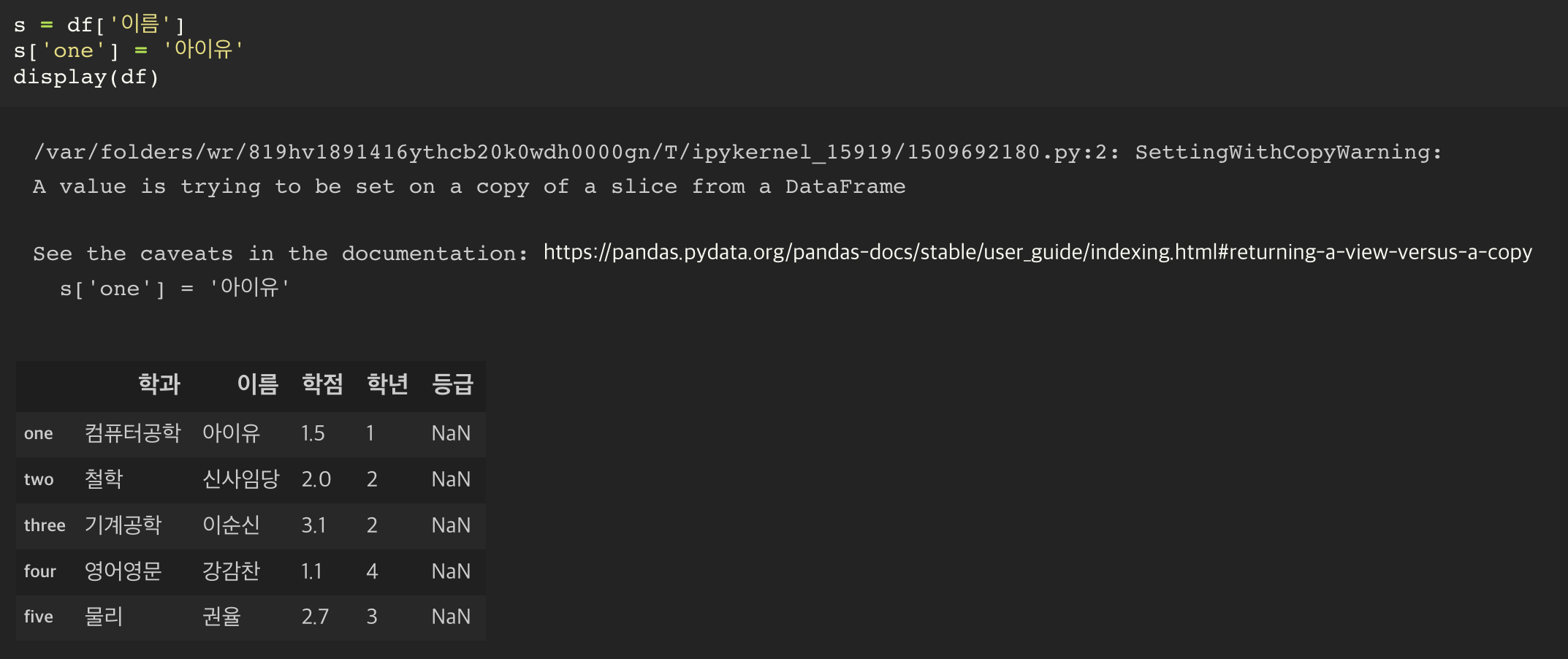
indexing 을 통해 가지고 온 Series 에서 값을 바꾸게 되면, 원본인 dataframe 의 값 역시 변경이 이루어진다.
즉 indexing 을 통해 가지고 온 Series 는 view 일 뿐, 새로운 데이터가 아니다.
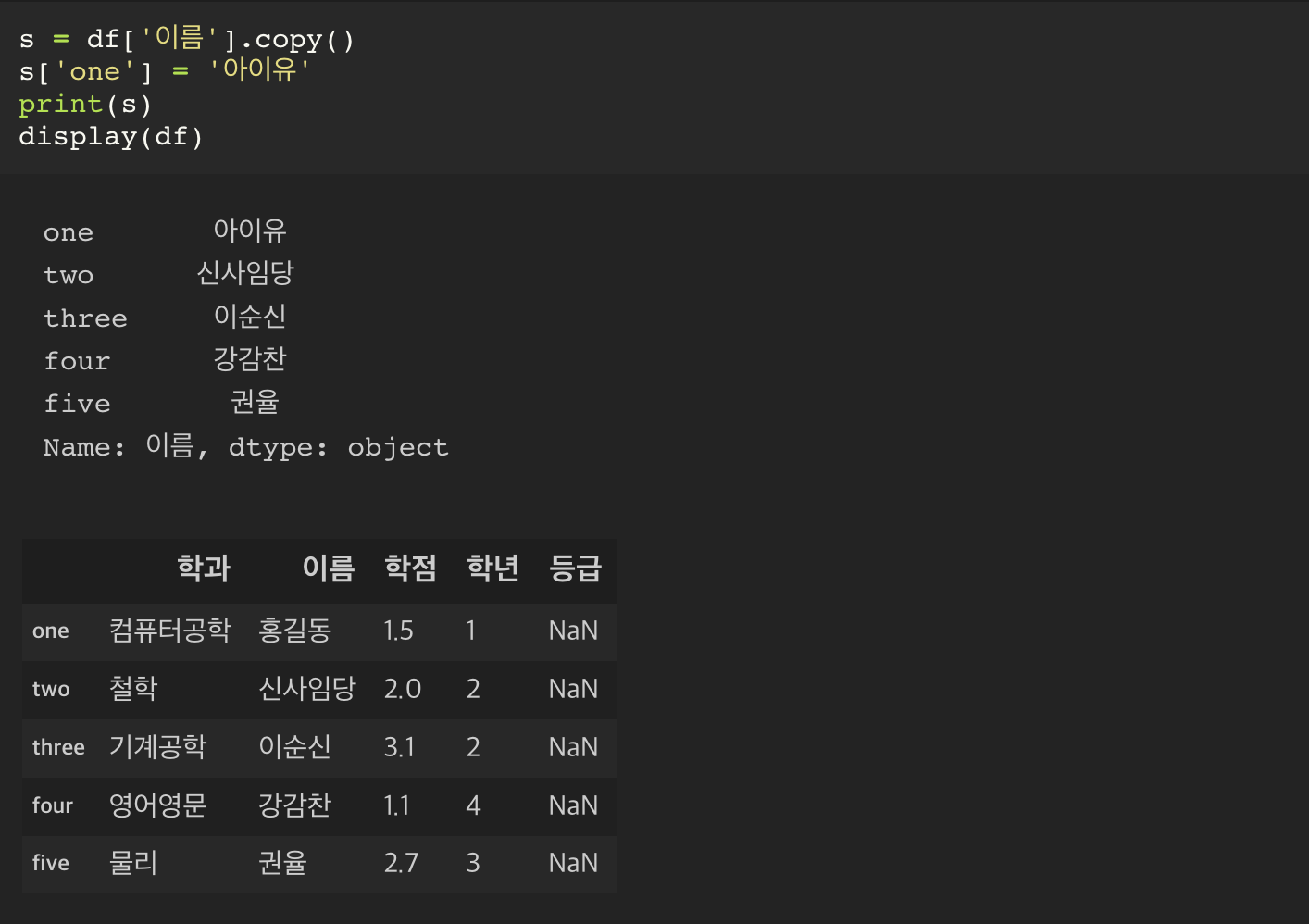
때문에, dataframe 에서 하나의 series 를 추출하되, 추출한 값에서 변화를 주고자 한다면 copy() 함수를 사용해서 원본을 복사해서 새롭게 만든 dataframe 을 사용할 필요가 있다.
이 경우에는 값을 변경해도 원본 데이터프레임의 값에 변경이 일어나지 않는다.

Facny indexing 을 통해 값을 가져온다. fancy indexing 을 할 때에는(원하는 것들을 특정해서 뽑아오고자 할 때에는) 리스트 형태[] 안에 원하는 값들을 입력한 뒤에 출력한다.
컬럼을 추가하기
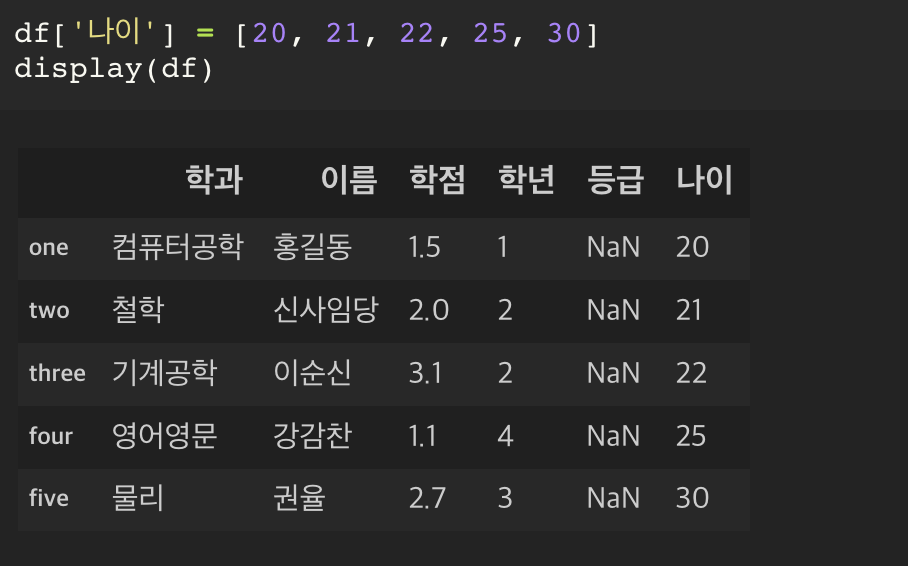
추가할 때에는 [20, 21, 22, 25, 30] 이라는 list 값이
1) numpy 을 거쳐 ndarray 로 바뀌고,
2) 그 다음에 pandas 를 통해서 series 로 바뀌고,
3) 그 후에 df 의 열에 해당 값이 추가되게 된다.
조건을 통해 대상을 찾아내기
만약 학점이 3.0 이상인 학생을 찾는다면,
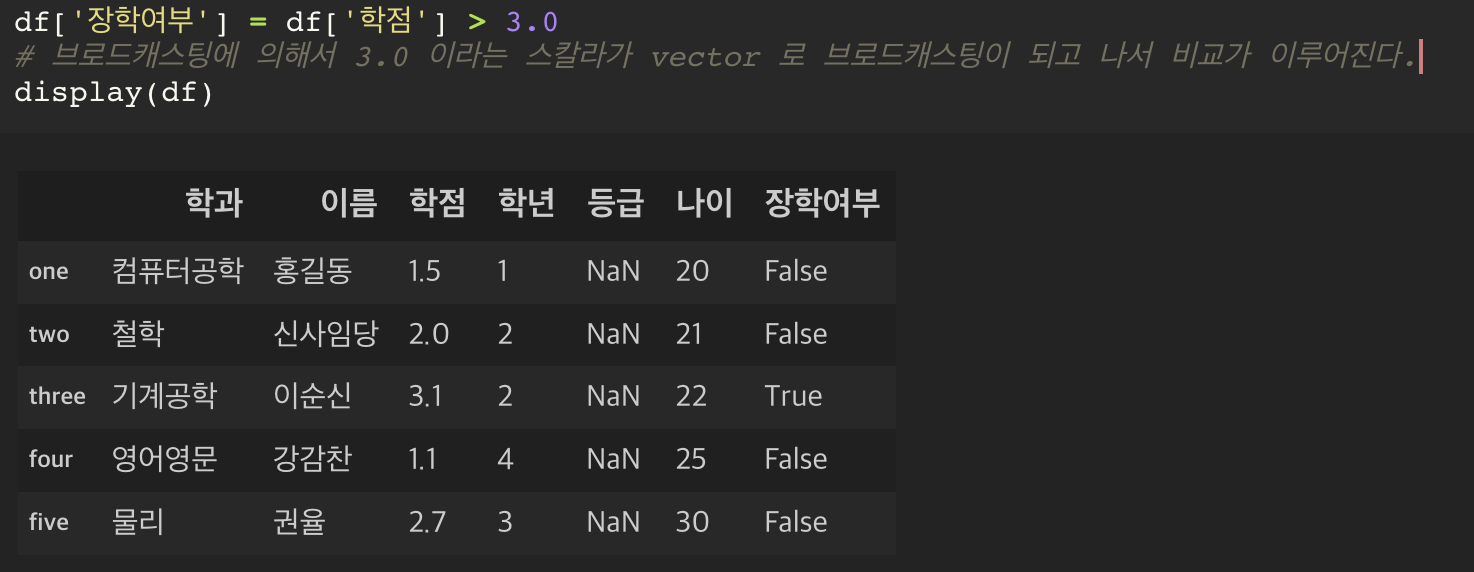
브로드캐스팅에 의해서 3.0 이라는 스칼라가 vector 로 브로드캐스팅이 되고 나서 비교가 이루어진다.
즉, 기존 데이터의 연산을 통해서 새로운 컬럼을 추가할 수 있다.
데이터를 제거하기
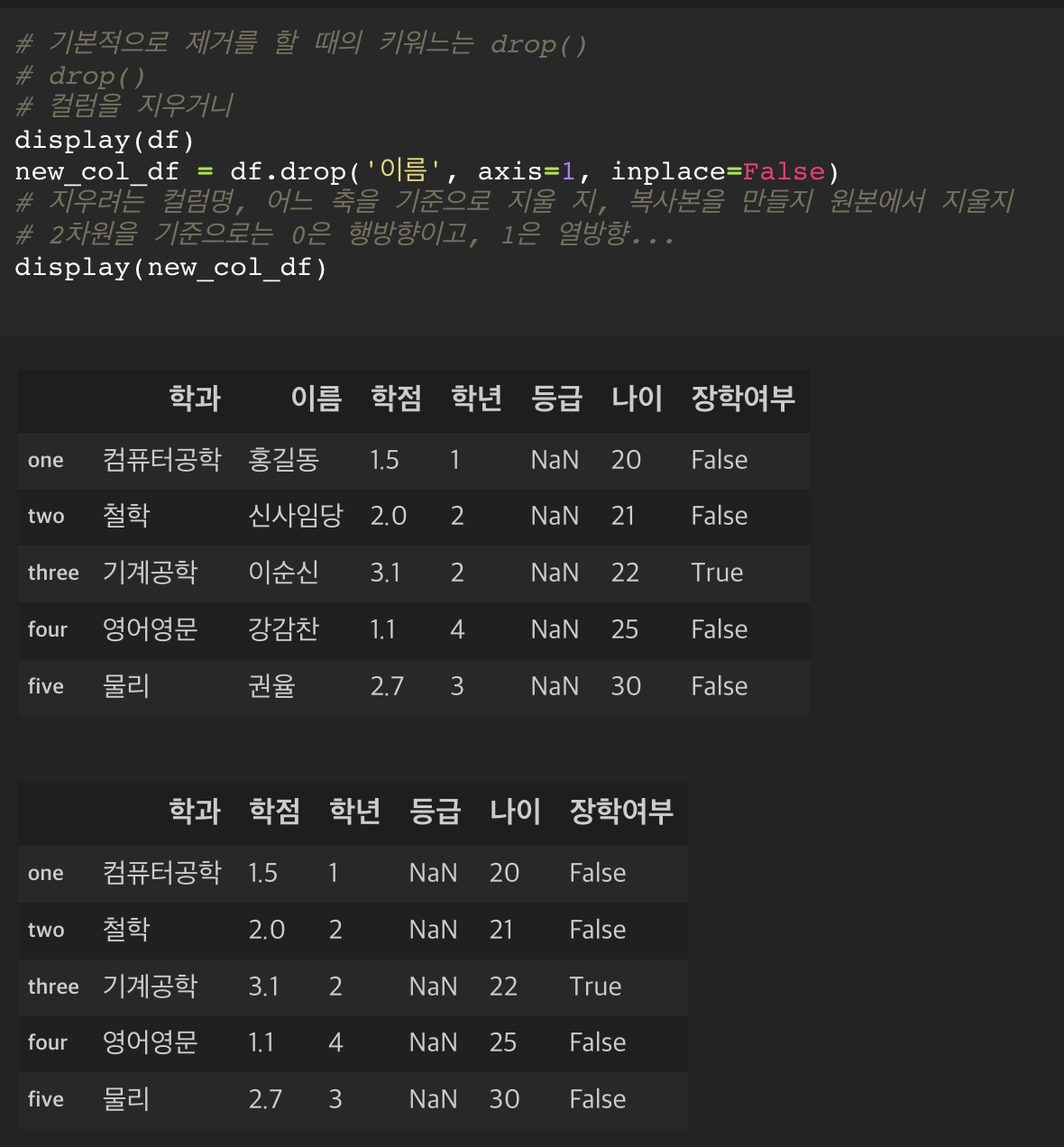
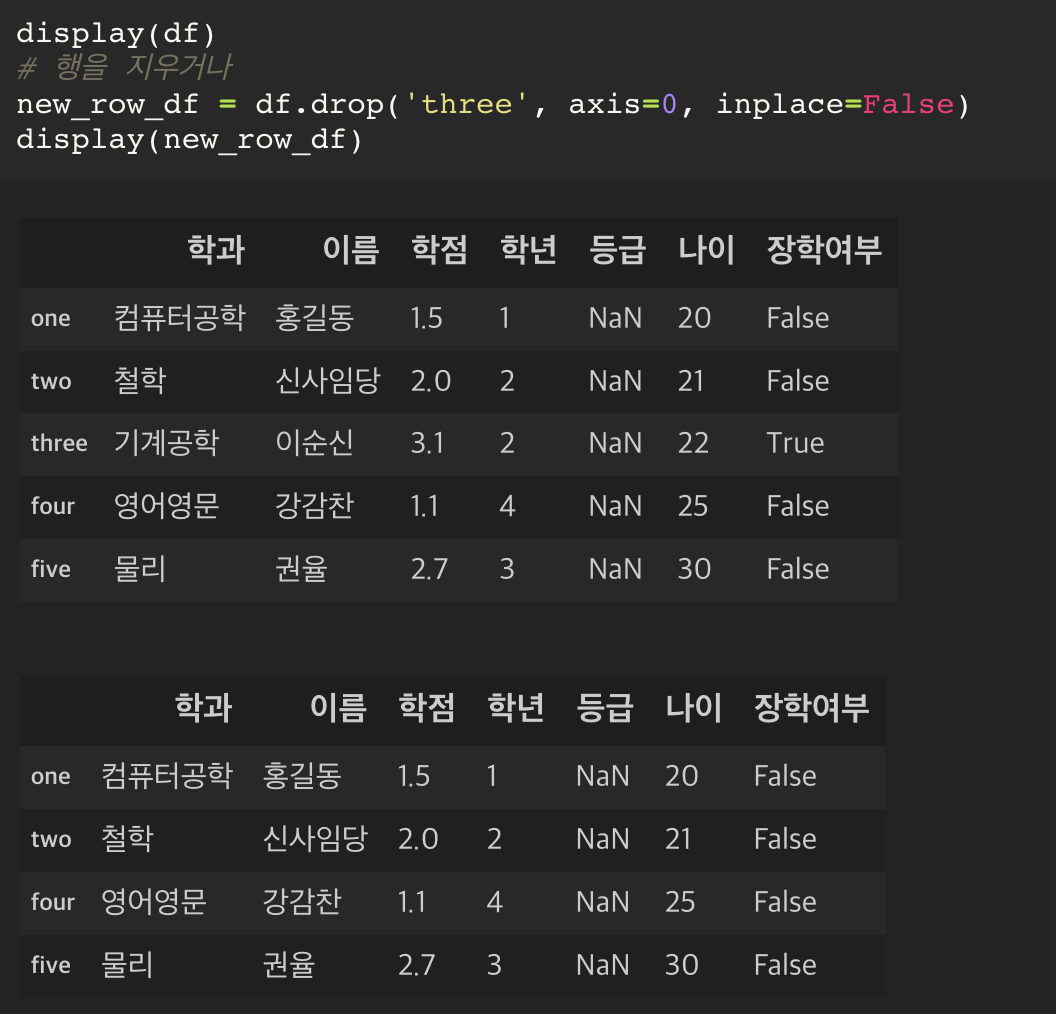
컬럼에 대한 slicing : 불가능하다.
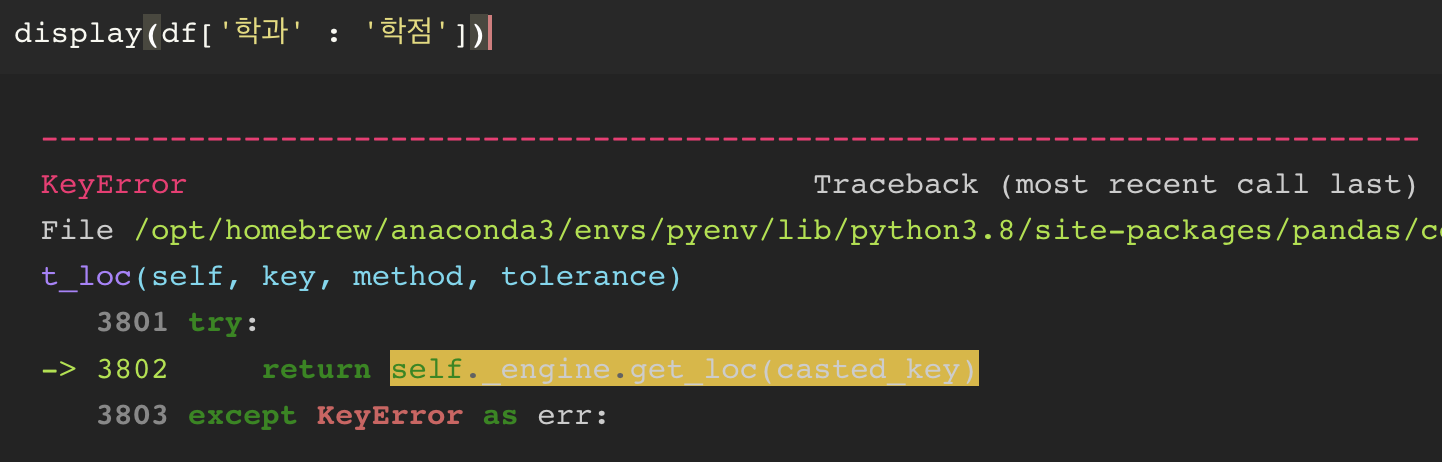
row indexing(행을 가지고 오는 방법)
display(df[0]) => 에러
display(df[0:2]) => 가능
... 왜? 그런 식으로 slicing 으로 행을 가져오다면
너무 헷갈리기 때문에 loc 를 사용하자.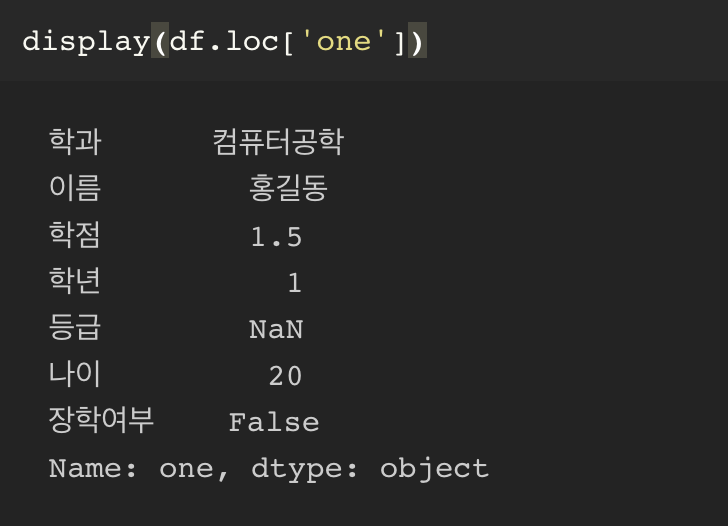
loc 를 사용할 때에는 사용자가 임의로 지정한 인덱스를 사용해야만 사용이 가능하다.
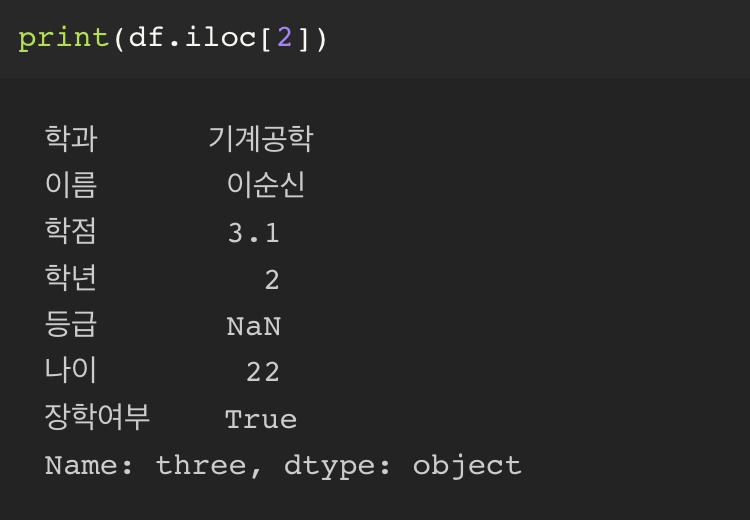
만약, loc 를 사용하되, 숫자형 인덱스를 사용하겠다고 한다면
일반 loc 가 아니라 iloc 를 사용해야 한다.
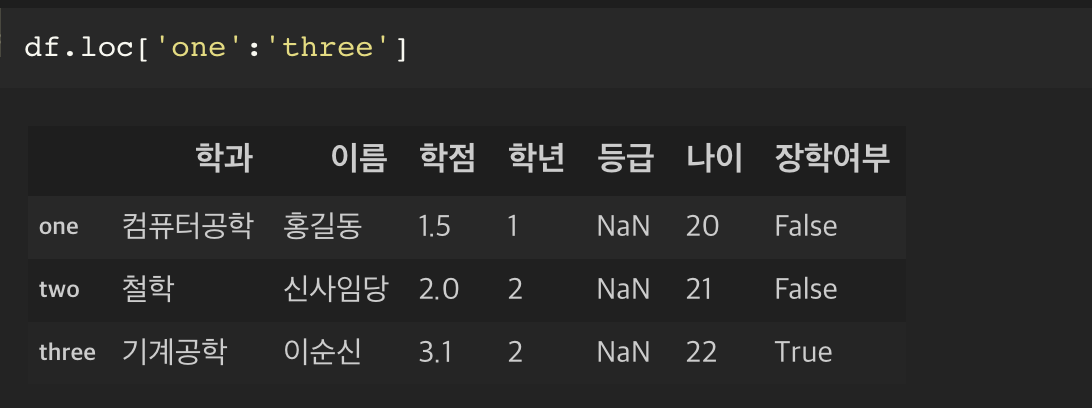
loc 를 사용할 때에는 사용자 지정 인덱스를 사용해 슬라이싱 인덱스가 가능하다.
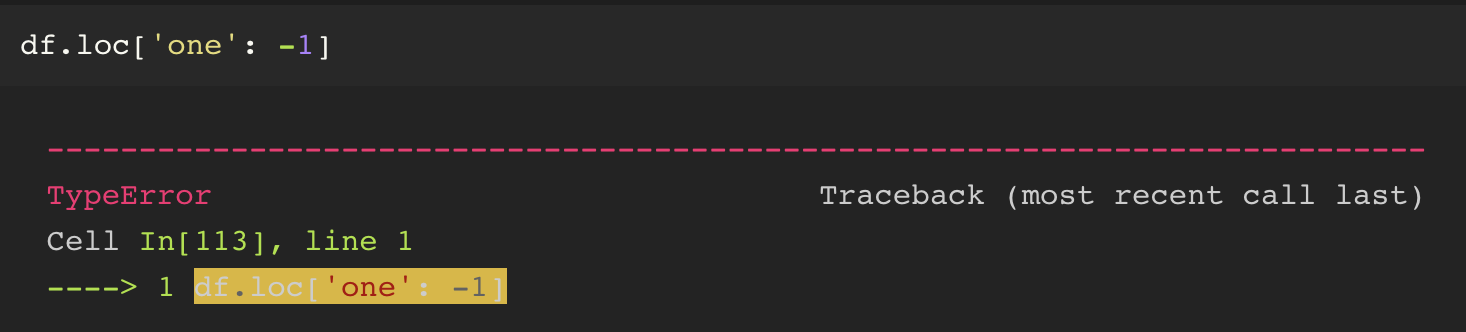
loc 를 사용할 때에는 -1 의 사용이 불가능하다.

loc 역시 fancy indexing 이 가능하다.
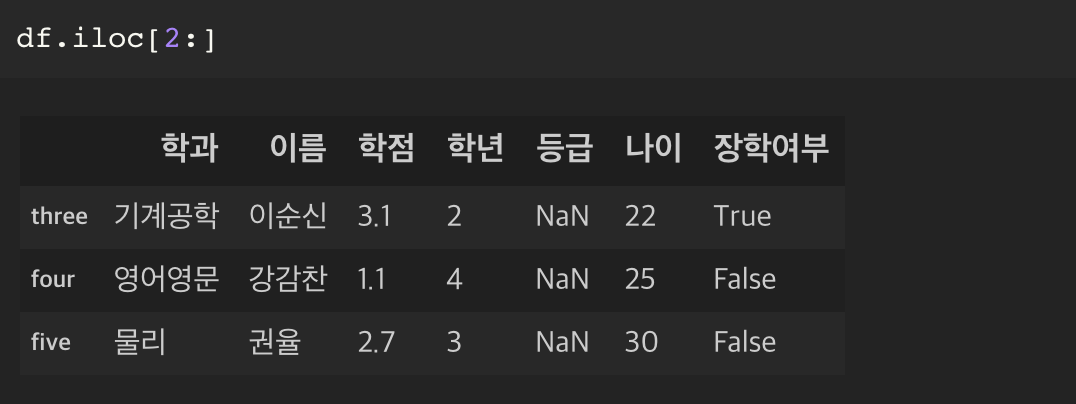
행과 열을 구분해서 값을 추출하는 방식

loc 의 인자로 [] 에 조건을 넣는데, 먼저 행을 기준으로 fancy indexing 을 하고, 콤마와 함께 인자로 columns 의 값을 fancy indexing 을 넣어준다.
