지도학습(Supervised Learning)
지도학습에서 데이터는 2가지로 분류된다.
Data 의 구조
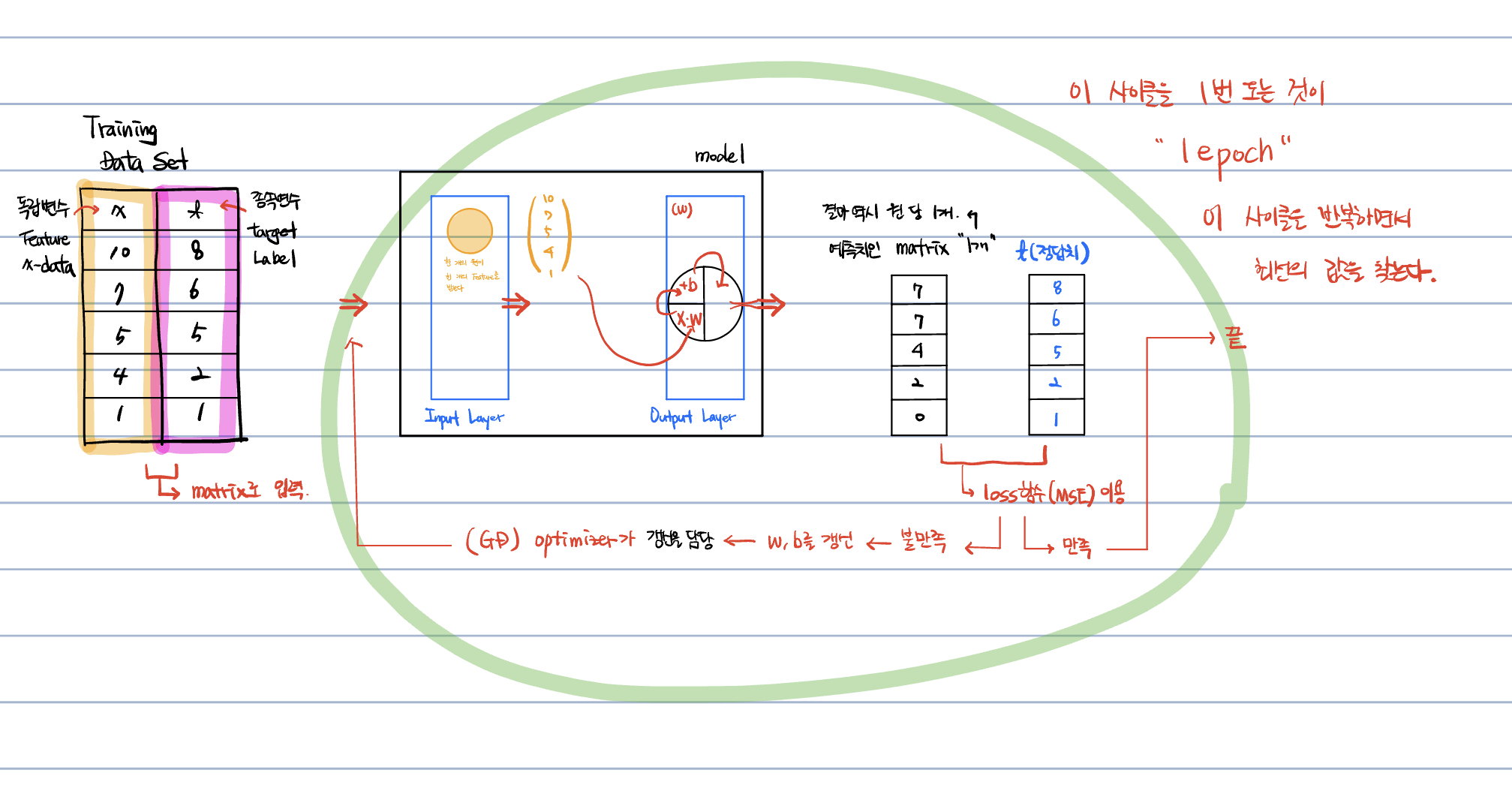
[ 학습 데이터 | Lebel ] - 입력 -> 프로그램의 실행 - 결과 -> Model(수식)
완성된 모델을 가지고 예측 을 하게 된다.
단변량이란, Label 의 값이 하나만 주어지는 것을 의미한다.
Label 은 무조건 한 가지가 쓰이는 것은 아니다.
사람의 학습 데이터에 대해 Label 을 사람, 남자, 성인.. 이런 식으로 여러 Label 이 주어질 수도 있다.
다변량 이라 한다.
데이터의 Label 타입으로 연속적인 숫자 데이터가 나올 수도 있고, True/False 의 이산적인 숫자(분류->합격/불합격, 가능/불가능, 성공/실패..) 데이터로 나올 수도 있다.
Label 타입으로
- 연속적인 숫자 데이터가 나오는 타입을
Regression - 이산적인 숫자(분류) 데이터가 나오는 타입을
Classification
** 주의해야 할 점은 Label 타입에서의 Regression 이란 것은 모델의 결과 데이터를 지칭하고, machine learning 기법 중의 Regression 은 통계의 회귀분석 기법을 기반으로 한 기법을 의미. 문맥 상에서 어떤 것을 의미하는지 구분해야 한다.
1. Regression(회귀분석)
어떤 데이터에 대해 그 데이터의 영향을 주는
조건들의 영향력을 이용해서
데이터에 대한 조건부 평균 을 구하는 기법
===>>>
어떤 데이터에 대해 그 데이터의 영향을 주는
조건들의 영향력을 이용해서
데이터들에 대해서 그 데이터를 가장 잘 표현하는 함수 을 구하는 기법
표로 만들면 사용이 너무 어려워지기 때문에, 이를 수식으로 바꾸게 된다.
예를 들어 아파트의 가격을 알아보는 수식을 작성해보자면,

이렇게 만들어진 수식의 결과 정확도가 좋다면, 앞으로는 복잡한 계산이 필요없이 해당 수식에다가 필요한 데이터만 넣게 되면 향후에도 예측이 가능해진다는 것이다.
회귀분석이라는 것은 결국 이러한 수식을 만들어내는 것을 의미한다.
결국 최종적으로 Regression(회귀분석) 은 보다 정확한 평균을 구하는 수식을 찾는 것을 의미한다.
평균은 대표값으로 가장 많이 이용하는 값이다. 대표값이란 여러 개의 데이터 중에서 어떤 값이 이 전체 데이터를 대표할 수 있는가를 의미한다. 대표값으로 사용할 수 있는 수를 찾을 때에는 몇몇 기법을 사용한다. 최소값, 최대값, ***평균, 중간값, 최빈값 ...
그 중에서 평균이 데이터를 가장 잘 표현하는 값, 이라고 대다수가 생각하기 때문에 주로 대표값으로 이용이 되곤 한다.
Regression Model
독립변수(Feature) 와 종속변수(target)
독립변수는 독립적으로 존재하는 변수.
독립변수의 데이터를 가지고 2차 가공된 변수. 즉 독립변수가 바뀌게 될 경우 종속변수 역시 값이 바뀌게 된다.
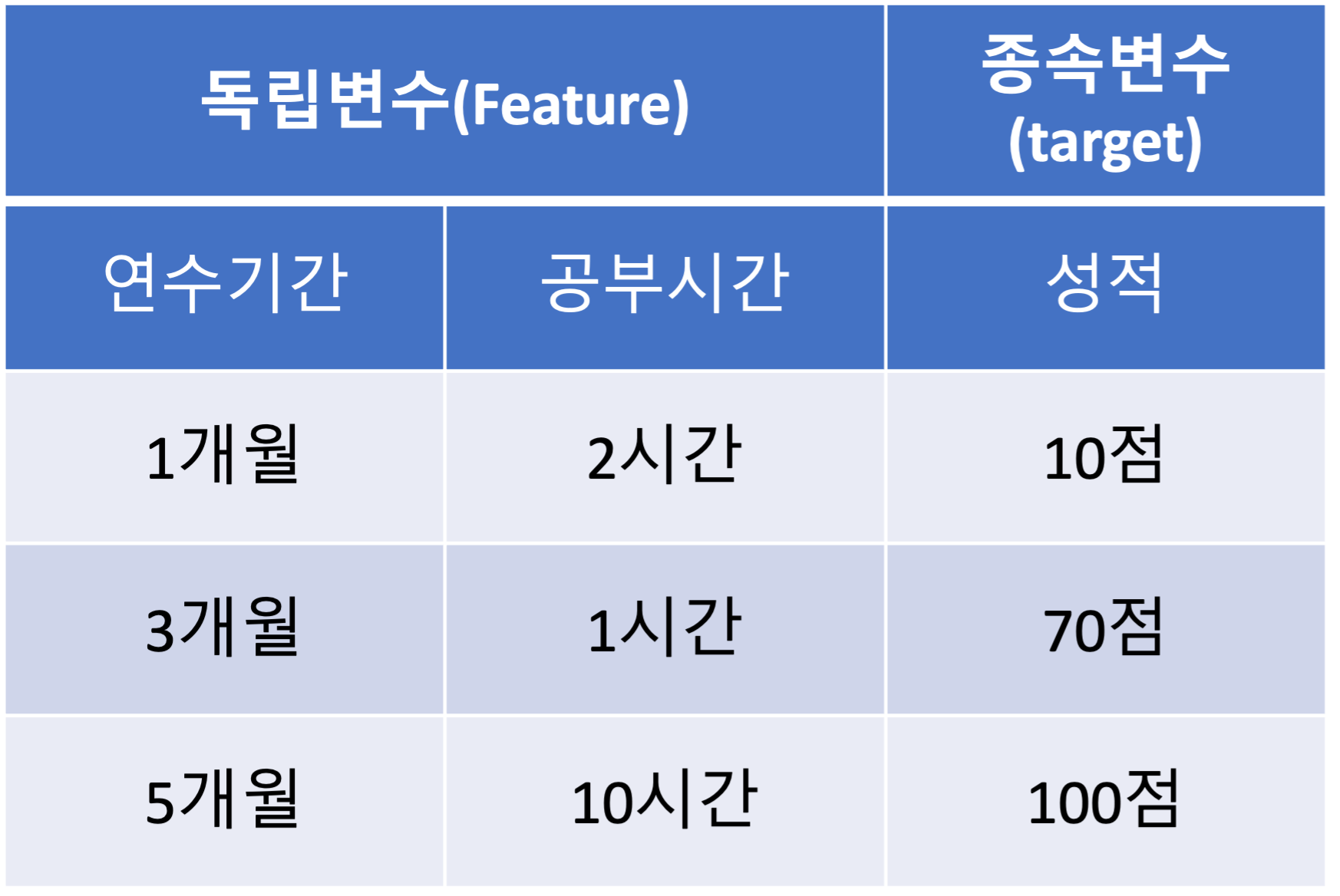
연수기간과 공부시간에 따라서 성적이 변화한다.
지도학습에서 보자면, 독립변수는 x-data 를 의미하고, 종속변수는 label 을 의미하게 된다.

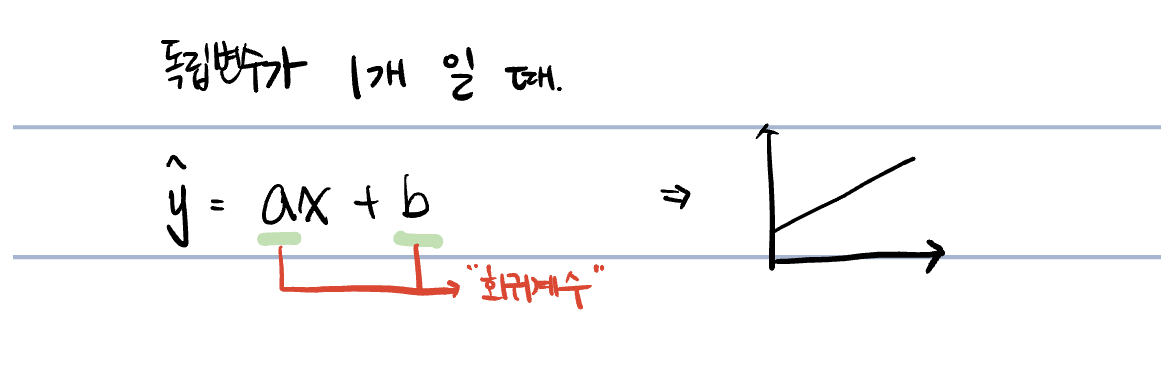
기본적으로 한 개의 독립변수와 한 개의 종속변수를 가지고 수식을 만들게 되면 1차원 직선의 수식이 나오게 된다.
그리고 1차원 직선 수식을 classical linear Regression 이라고 부른다.
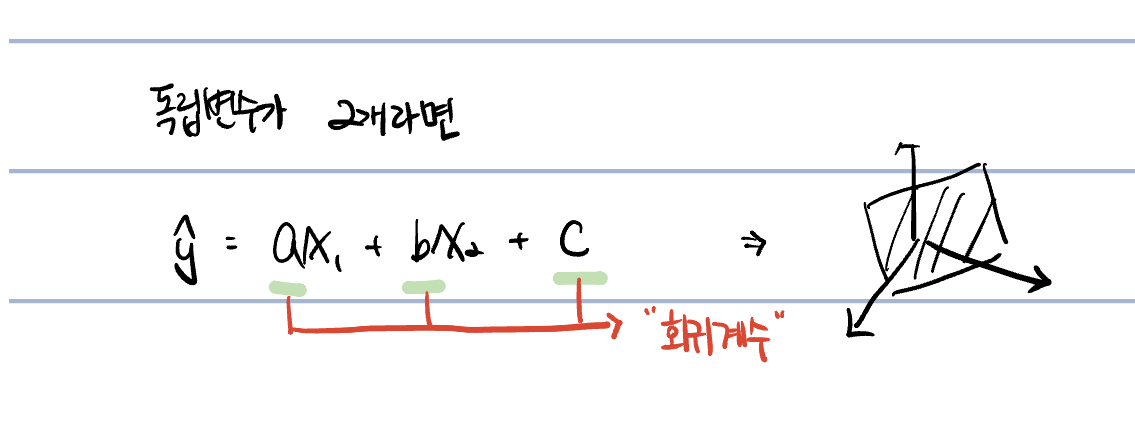
그런데 독립변수 혹은 종속변수의 갯수가 1개씩 늘어갈수록 2차원, 3차원으로 늘어나게 되고 수식 역시 면, 공간 등으로 바뀌게 된다.
만약 데이터가 평균을 사용하기 힘든 데이터라면 회귀모델 사용을 고려해야 한다.
(데이터 상에서 큰 사이즈의 아웃라이너가 존재한다면)
따라서, 데이터의 분포도를 알아야만 한다.
예시로 성인의 키 데이터를 보게 되면 정규분포의 형태를 띄게 된다.
반대로 연봉 데이터의 경우에는 분포도가 편향되게 나오게 된다. 만약 편향된 데이터를 사용해야만 할 경우, 이 편향을 보간해주는 과정이 필요해진다.
왜 Regression(회귀) 일까
1800년 대 찰스 다윈의 책인 "종의 기원"
찰스 다윈의 친인척 중 프란시스 라는 인물이 우성인자를 이용헤 더 나은 인류가 되자라는 의미로 우생학을 시작했다.
그 때 큰 키를 우성, 작은 키를 열성으로 생각하고 데이터를 모으기 시작했다.
데이터를 모으다보니, 큰 키의 아버지를 가진 자식 중에도 작은 키의 아이가 태어나기도 하고 작은 키의 아버지를 가진 자식 중에도 큰 키의 아이가 태어나기도 한다.
이를 결국 모아서 평균을 내보니... Regression towoard Mean... => Regression
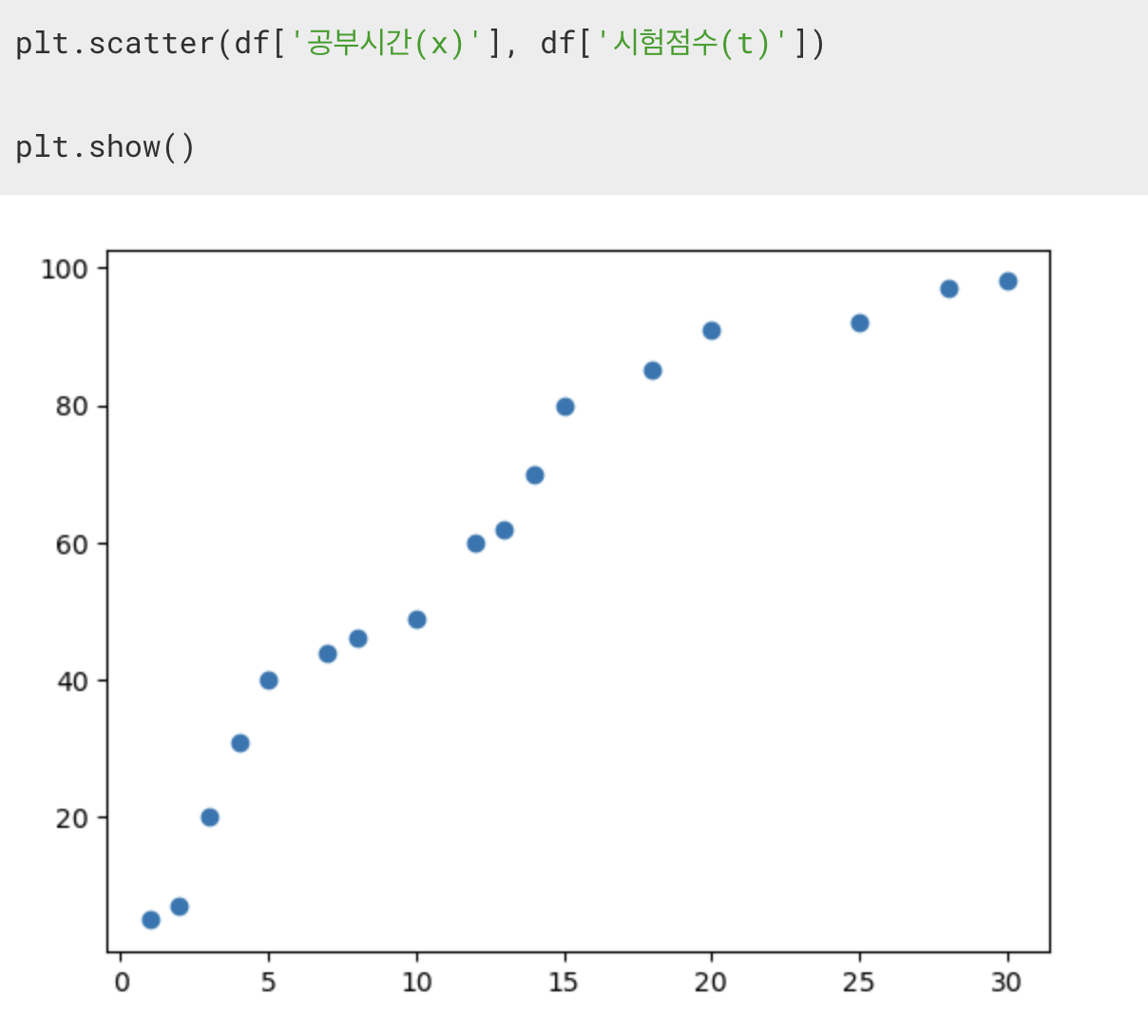
matplotlib.pyplot
plt.scatter('독립변수', '종속변수')
그래프로 데이터의 분포를 보여주는 함수
plot(x, y)
직선을 그려주는 함수
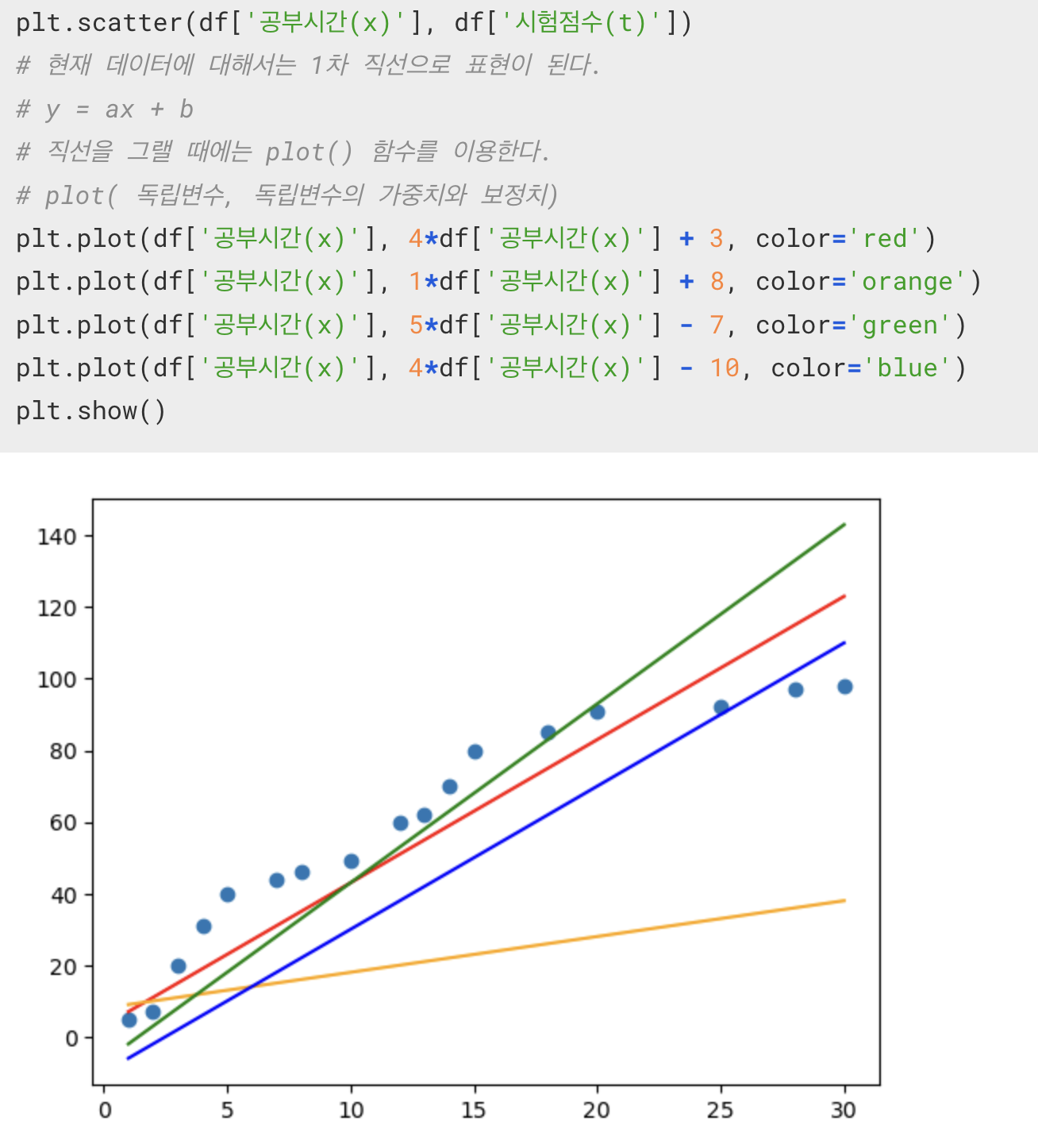
직선을 계속해서 고쳐가면서 어떤 직선이 우리의 값을 가장 잘 대표하는지를 찾아내는 과정. 정확히는 y 인자로 들어가는 가중치와 보정치의 값이 어떤 것이 가장 알맞은 값인지를 찾아가는 과정.
y = ax + b
=>
y = wx + b
w = weight
b = bias
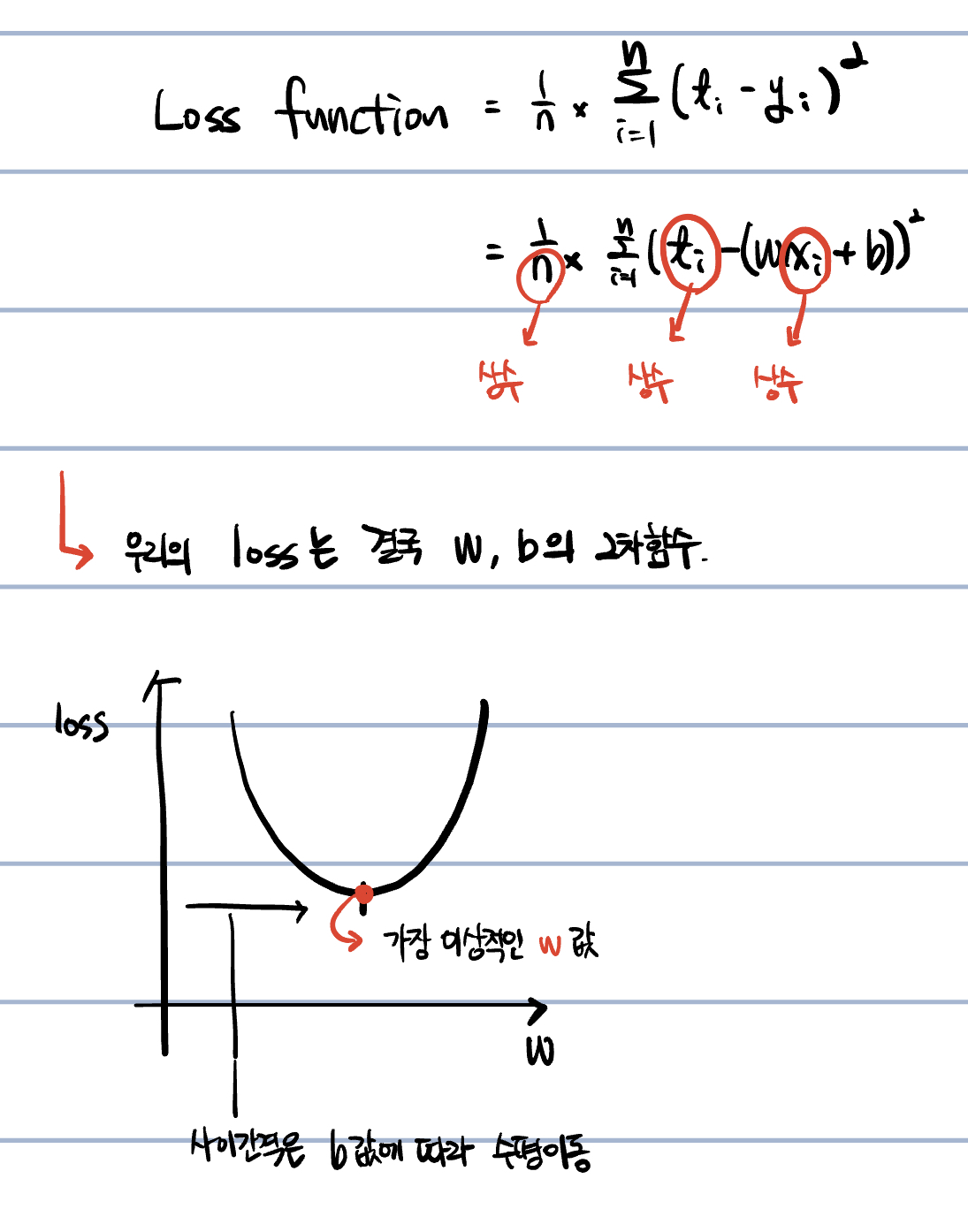
이 그래프가 점들을 잘 대표하고 있는지 판단해야만 한다.
잘 표현하고 있지 못하다면, 더 나은 w와 b를 찾아야 한다.
이 판단의 기준이 뭘까?? => 오차(ERROR)
오차는 실제값 - 추정값 ( t - y )
오차는 평균제곱오차(MSE) Min Squared Error 를 가지고 하게 된다.
내가 만든 모델이 잘 만들어졌는지를 판단하는 기준이 평균제곱오차가 된다.
Loss 함수 : 내 모델이 좋은지 나쁜지를 판단하는 함수. 즉, 우리는 Loss 함수로써 MSE 를 사용하게 되는 것이다!

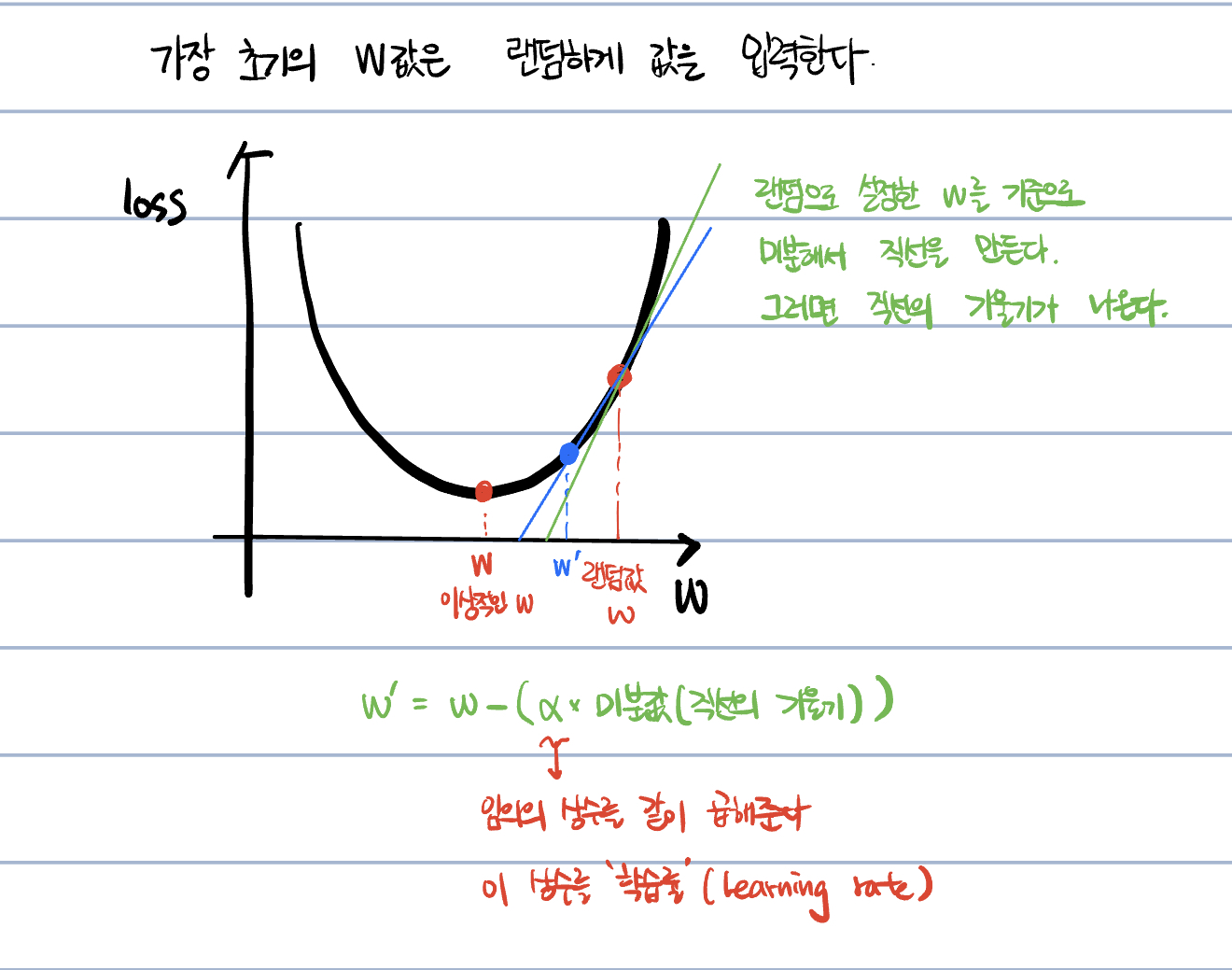
정답(t) - 예측값(y)을 비교해서 괜찮다면 종료.
만약 그 간격이 너무 커서 ng 라면 w와 b를 갱신한다.
w' = w - a(미분값)
b' = b - a(미분값)
새로운 w와 b 값을 가지고 다시 예측값을 만들고, 정답과 예측값을 비교한다.
이 과정을 계속해서 반복하면서 궁극적으로 이 모델이 만들어질 때 까지 반복한다.
이를 반복학습을 통해 만든다.
원래라면, y를 찾기 위해서 y=wx+b 의 수식에 반복적으로 대입을 해야 했는데, 이것을 행렬곱을 이용해 빠르게 해결할 수 있도록 한다.
x 의 데이터가 4x1 의 행렬이라면, w 데이터를 1x1 의 행렬로 만들어서 바로 4x1 의 행렬 데이터를 만든다.
머신러닝의 라이브러리
1. google 의 Tensorflow + keras
2. meta 의 pytouch
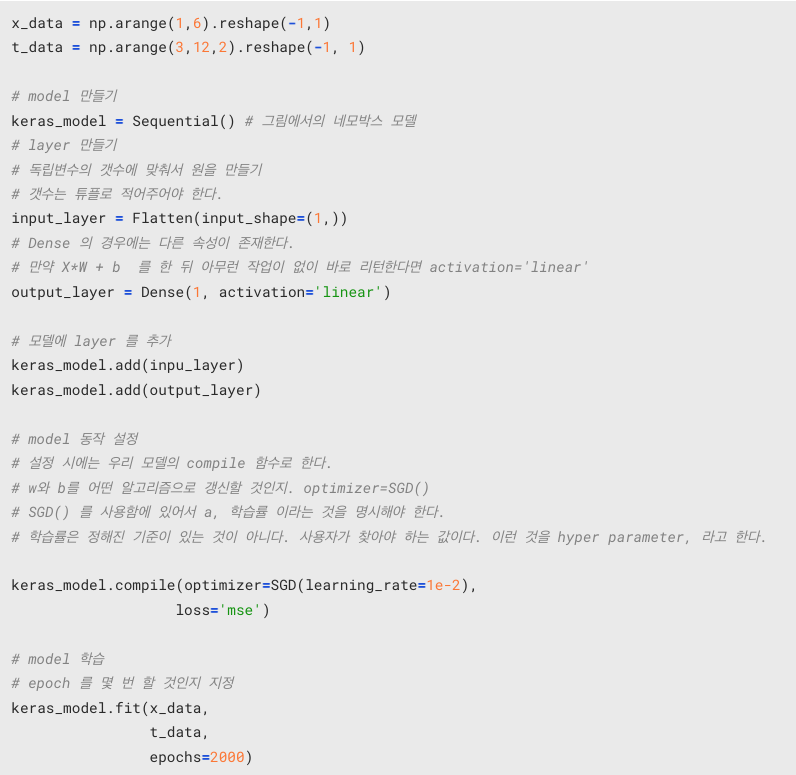
from tensorflow.keras.models import Sequential

왜 Sequential 이냐 하면, Model 의 박스에서 왼쪽에서 오른쪽으로 순차적으로 흐르면서 프로세스가 진행되기 때문이다.
Model 내부에 있는 layer 에는 두 가지가 있다.