
복습
AI 에는 약 AI 와 강 AI 가 있다.
그 중에서 현실 세계에서 구현이 가능한 레벨은 약 AI 이다.
약 AI 를 학습시키기 위해서 Machine Learning 타입과 기법들을 사용하고 있다.
일반적으로 학습할 때 쓰이는 데이터의 타입은 4가지 정도가 존재한다.
- 지도학습
- 비지도학습
- 준지도학습
- 강화학습
또한 기법에는 수많은 종류가 존재한다. 기법(알고리즘)이 다양해지는 이유는, 인풋으로 들어오는 데이터의 형태(정형/비정형).. 과 같은 에 따라서 기법 마다의 효율이 달라지기 때문이다.
- Regression
- SVM
- Decision Tree
- Naive Bayes
- KNN
- ANN(인공신경망) => 딥러닝
여기서 대다수의 기법들은 편리하게 사용할 수 있도록 이미 누군가가 제공하고 있는 라이브러리가 존재한다.
그런데 딥러닝 같은 경우, 외부의 라이브러리를 사용하는 것 보다 사용자가 학습시키는 것이 더 효과적인 케이스가 나오게 된다.
Regression 기법은 두 가지로 나뉘어진다.
1. Regreesion : 결과값이 연속적인 숫자값으로 출력되는 것
2. classification : 결과값이 분류(true/false, 합/불..) 과 같이 출력되는 것
그 중 1. 타입인 Regreesion(연속숫자) 타입으로 사용할 때 사용하게 되는 것이 linear regression model 이라고 하게 된다.
또한 linear regression model 중에서도 독립변수가 1개인 케이스를
simple 타입,
독립변수가 2개 이상인 케이스를
multiple 타입이라고 부르게 된다.
- 타입인 classificaion 타입에서 사용하게 되는 모델은
Logistic Regression Model이라고 한다.
또한 logistic regression model 중에서도 0/1 과 같이 이진법으로 구분되는 케이스를
binary classification 타입,
학점과 같이 A/B/C/D/F 여러 가지로 분류되는 케이스를
Multinomial classification 타입이라고 부르게 된다.
하지만 독립변수의 갯수에 상관없이 최종적으로 리턴되게 되는 결과값은 한 줄의 데이터가 나오게 된다.
내가 가지고 있는 데이터 중에서 어떤 데이터를 Feature(독립변수)로 사용할 것인지 구분을 해야 한다.
그러한 부분을 할 때에는



verbose
테스트를 하는 코드를 보일지 말지.
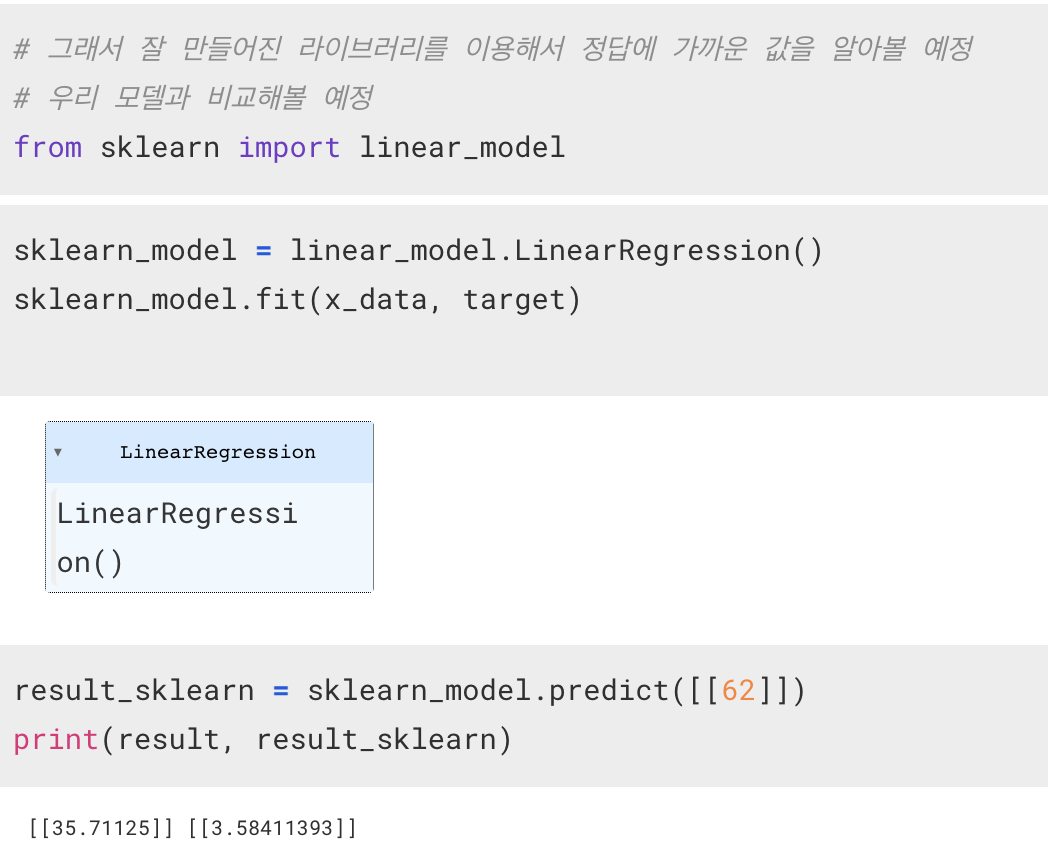
sklearn

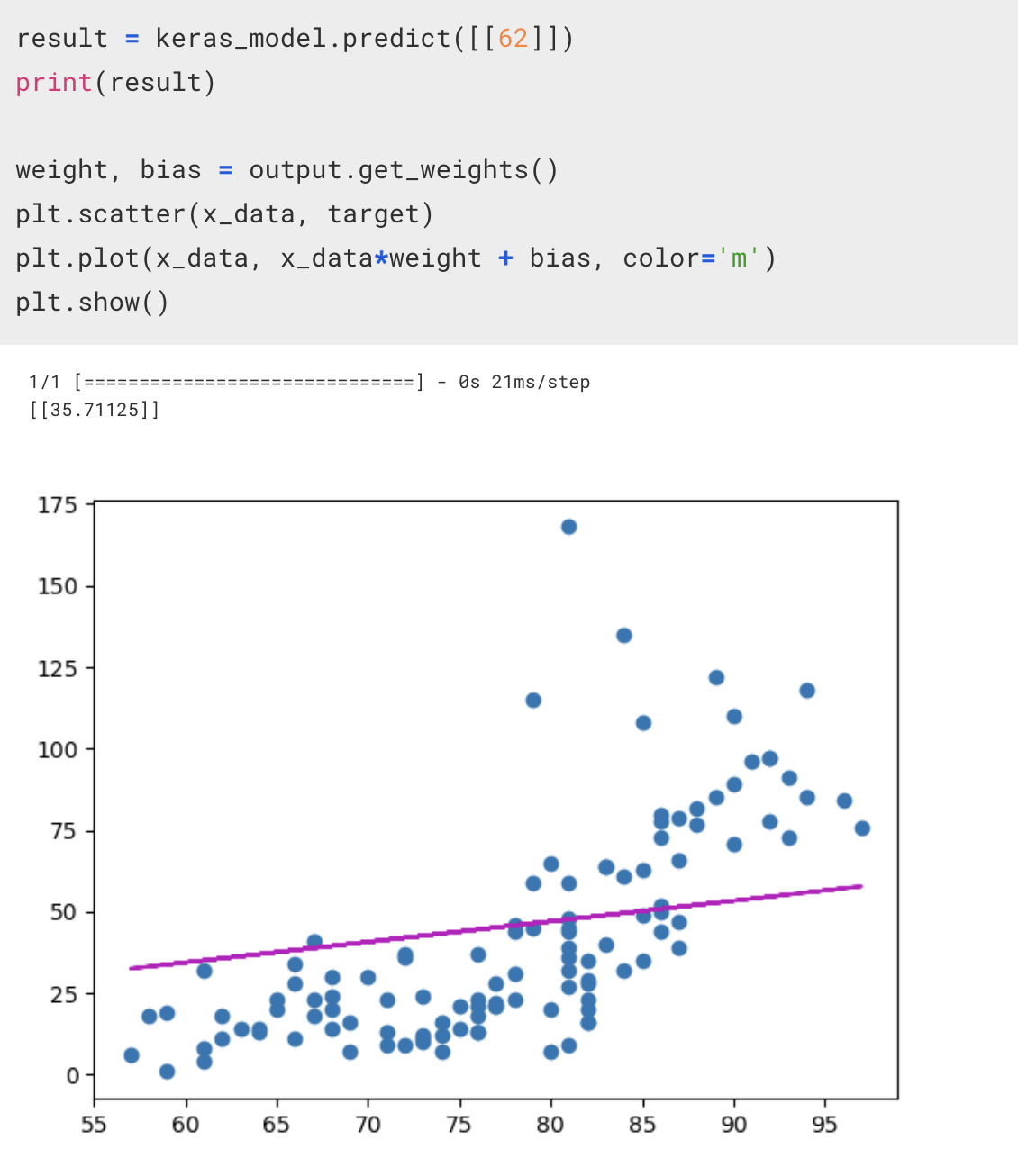
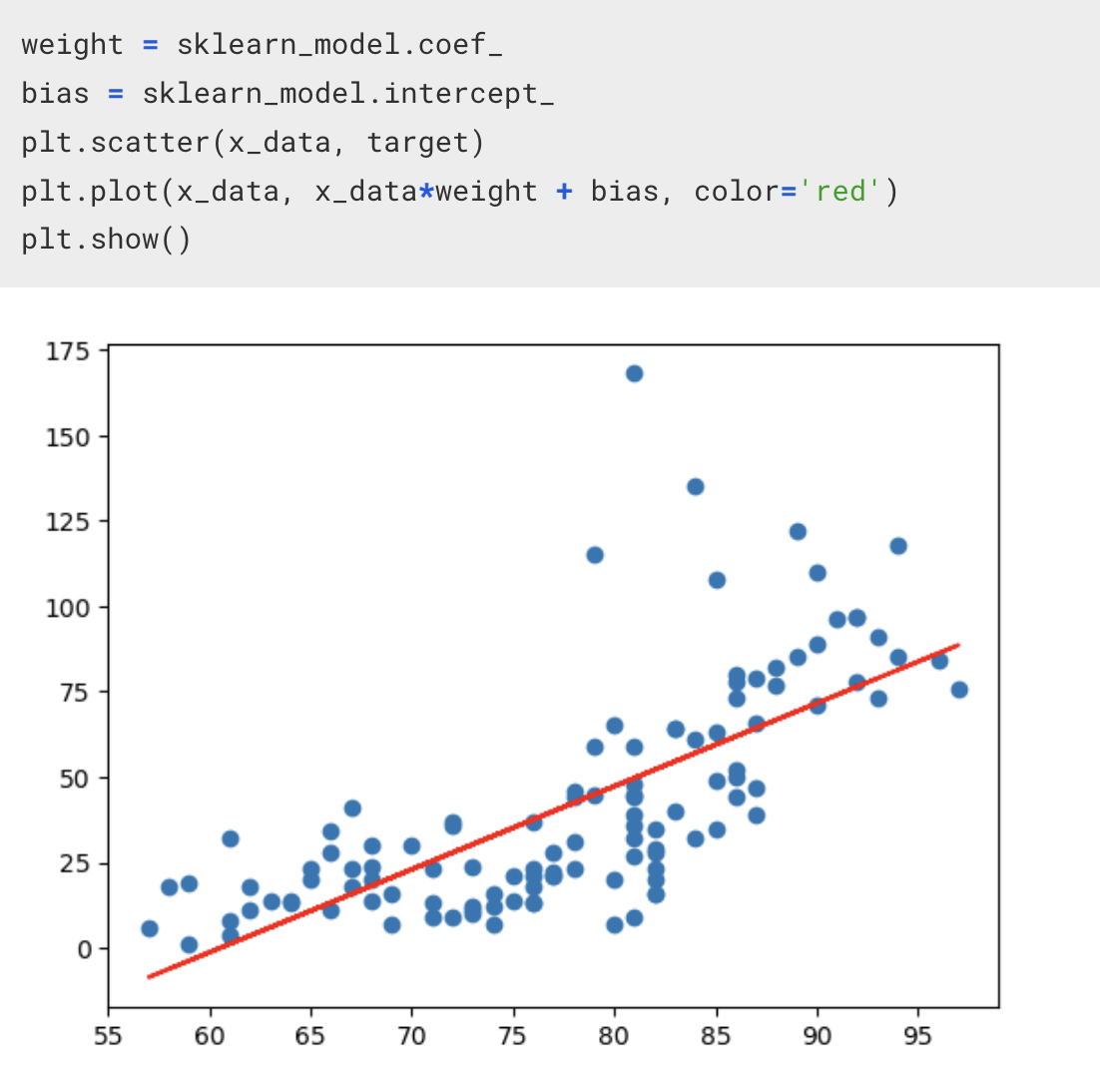
내가 만든 모델의 결과값과 sklearn 라이브러리를 사용해 얻은 결과값에서 차이가 보이는 이유
그것은 데이터의 전처리 과정에서 오류가 있었기 때문이다.
sklearn 의 경우, 데이터 전처리 역시 내부적으로 처리를 해주지만, 내가 만든 모델에서는 전처리 과정에서 오류가 존재했다.
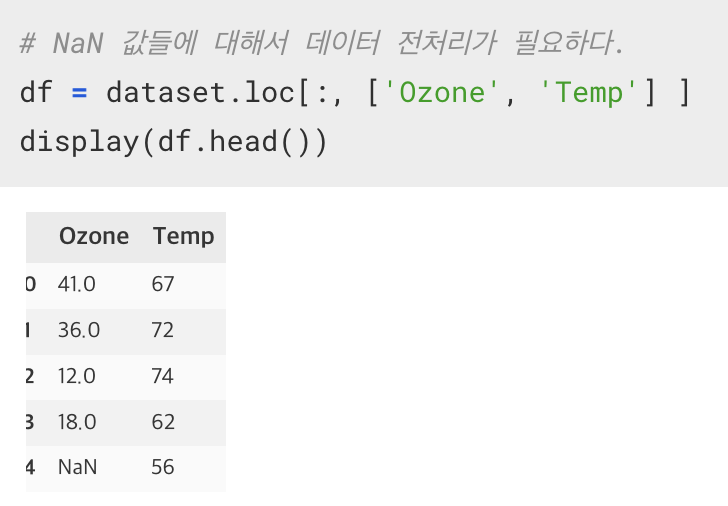
데이터 전처리
큰 틀로써 기억해야 할 데이터의 전처리 과정은 3가지 있다.
-
결측치 처리(보간/삭제)
-
이상치 처리
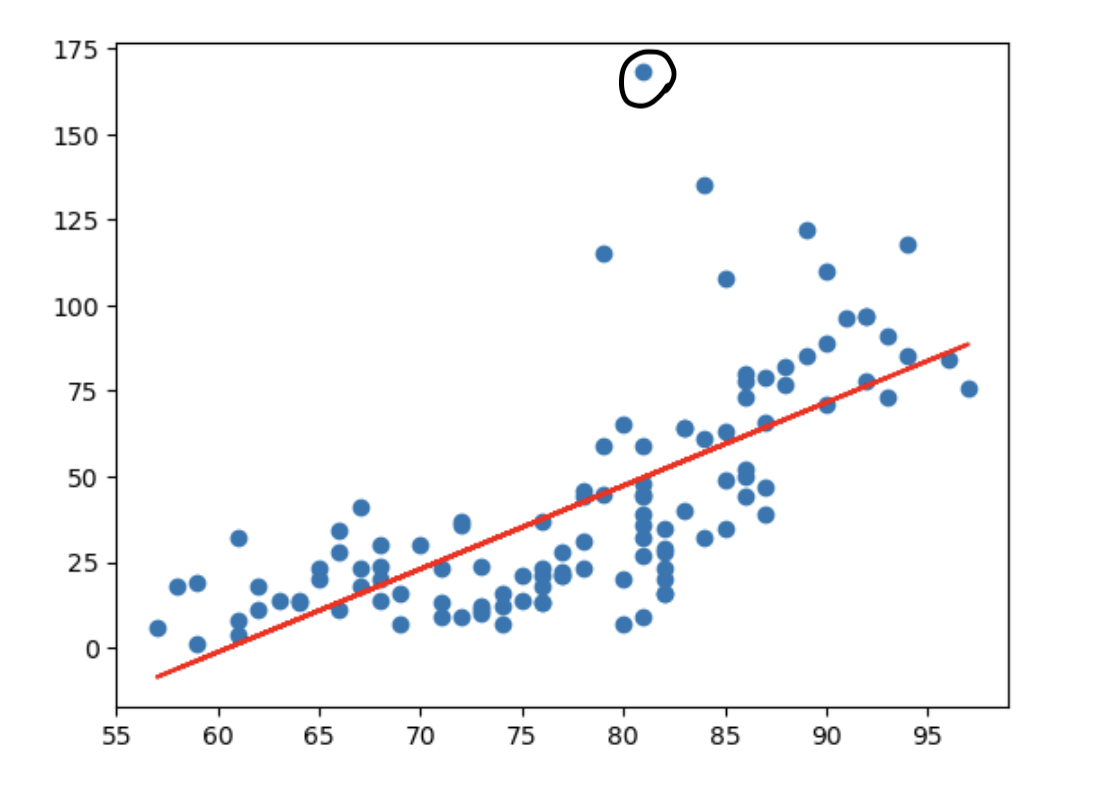
위쪽에 솟아있는, 일반적인 라인과는 완전히 동떨어진 값에 대한 처리가 필요하다.
** 3. 데이터 정규화(Nomalization)
반드시 데이터의 정규화가 필요하다!!!!!
scale 의 차이를 조율해주어야 한다.
예를 들어 아파트의 가격에 대한 데이터에 대해서
- 방의 개수
- 면적
이라는 두 개의 조건이 있다고 한다면, 방의 개수의 범위는 1~20 정도가 된다. 그런데 면적은 1~500~ 이라는 범위를 가지게 된다.
근데 숫자적으로만 본다면 머신러닝의 학습 시에는 1~20 안에서 움직이는 방의 개수보다 1~500~ 을 움직이는 면적이 더 큰 변동을 가져오게 된다.
따라서 이것들을 졍규화하는 과정이 필요하다.
정규화 시에는 min-max scaling 을 이용한다.
즉, 현재 가진 데이터에 대해서
최소값을 0 에서 최대값을 1 사이의 값으로 변환한다.

잘 보고 갑니다~^^❤️