
복습
linear regression(선형회귀). 여기에는 1개의 독립변수를 사용하게 된다.
그것에 대한 식은 다음과 같다.
이 식에서 y는 예측값, x는 독립변수, w는 가중치, b는 보정치를 의미한다.
만양 독립변수가 3개라면?
이럴 경우, 여러 개 존재하는 독립변수들을 반복문을 돌면서 곱해주어야 하는데, 그것을 편하게 할 수 있도록 형태에 살짝 변형을 주게 된다. 즉, x에 대해 행렬로 변환시킨다.
x에 대한 값을 행렬로 바꾼 뒤, 행렬곱을 통해서 값을 연산하게 한다.
이 때, x가 X라는(ex 5x3) 행렬 로 바뀌었다면 w 역시 3x1 의 행렬로 표현이 되어야 한다.
Multiple Linear Regressgion




(Multiple) Logistic Regression
선형회귀와의 차이점이라함은, Data(종속변수의 형태) 가 바뀌는 점이다.
예를 들어,
1) 시험 성적에 따라서 합/불 이라는 두 가지 결과값이 나오는 케이스
2) 실험의 결과로 성공/실패 라는 두 가지 결과값이 나오는 케이스
등 결과 데이터의 형태가 binary classification 의 형태로 나오는 케이스가 있다.
이 문제들 역시 초기에는 linear regression 으로 풀기 위해 노력했지만 불가능하다는 것이 밝혀지고 나서 새로운 방법에 대해 고민하기 시작한다.
그 결과로 나온 식이
x 값에 본래의 linear regression model 을 넣는 것!
즉 linear regression 모델을 활용해서 새로운 모델을 만들어내는 것이다.
기존의 linear regression 의 모델
해당 모델에서 예측치와 실제값을 비교해주는 것이 loss function 였다.
새로운 Logistic regression 모델에서의 loss 함수
이 식 역시 예측치가 있고 실제값이 존재한다. 이 두 값을 비교하기 위해 사용하는 loss 함수가 필요하다.
기존에 사용하던 mse는 사용이 불가능했고, logistic regression model 에 맞는 새로운 loss function 이 생겨난다.
그것이 cross Entropy
binary classification의 결과는 0 아니면 1.
예측치의 값은 0 ~ 1 사이의 값이 나오게 된다. 만약 예측치가 0.3 이 나온다면, 30% 의 확률로 1이 된다. 라는 확률값이 예측치로 나오게 된다.
실습
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import MinMaxScaler
# Logistic Refression 을 구현하기
# Binary Classification(이항분류)
raw_data = pd.read_csv('./data/230403/admission.csv')
print('raw_data.info() 실행 결과 : null 을 확인해볼 수 있다.')
print(raw_data.info())
# 결측치 처리 => 현재의 데이터는 결측치가 없기 때문에 생략한다.
# raw_data = raw_data.dropna(how='any')
# display(raw_data.head(), raw_data.shape)
# 이상치 처리 => 여러가지 방법이 존재한다.
# 가장 대표적인 방법
# 1.Tukey Fence : 4분위를 이용하는 방법
# 2. Z-Score 방식 : 정규분포를 이용하는 방법
from scipy import stats # 정규분포 그래프 생성을 위한 라이브러리
# 여기서는 2. Z-Score 를 이용해서 이상치를 처리할 예정
zscore_threshold = 2.0 # zscore outliers 임계값 (2.0이하가 optimal)
for col in raw_data.columns:
outliers = raw_data[col][(np.abs(stats.zscore(raw_data[col])) > zscore_threshold)]
raw_data = raw_data.loc[~raw_data[col].isin(outliers)]
print(raw_data.shape) # (382, 4)
# 졍규화
scaler = MinMaxScaler()
scaler.fit(raw_data[['gre', 'gpa']].values)
# Training Data Set
x_data = scaler.transform(raw_data[['gre', 'gpa']].values)
t_data = raw_data['admit'].values.reshape(-1,1)
model = Sequential()
model.add(Flatten(input_shape=(2,)))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-2),
loss='binary_crossentropy')
model.fit(x_data,
t_data,
epochs=2000,
verbose=0)
scaled_x_data = scaler.transform(np.array([[550.0, 3.5]]))
scaled_result = model.predict(scaled_x_data)
print(scaled_result)이상치 처리
: 여러가지 방법이 존재한다.
1.Tukey Fence
4분위를 이용하는 방법
2. Z-Score 방식
정규분포를 이용하는 방법
Evaluation(평가)
linear regression, logistic resgression 어떤 모델을 만들었느냐에 무관하게, 만들어진 모델을 평가하는 것은 매우매우 중요하다.
1. 방법(Data관점)
가지고 있는 Training Data Set 이 400개 존재한다면 일반적으로 7:3, 8:2 비율로 가지고 있는 데이터를 쪼갠다.
7 혹은 8 분량의 데이터를 통해 model 를 학습시킨 후 2, 3 에 해당하는 데이터를 통해 모델에 대한 평가를 진행한다.
즉 7 or 8 에 해당 하는 부분이 Training Data Set 이 되고 2 or 3 이 Test Data Set 이 된다.
그리고 Test Data Set 은 모델이 완성되고나서 최종적으로 평가를 위해서만 오직 딱 한 번 사용이 이루어진다.
그런데, 학습을 하는 과정에서 평가를 같이 진행할 수도 있다. 즉, Test Data Set 를 통한 평가가 Final Test 라면, 학습 과정에서 중간중간 테스트를 해볼 수도 있다.
이 때 사용하는 데이터는 7 or 8 의 데이터를 또 다시 쪼개어내서 진정한 Training Data Set 과 중간 테스트 용 Validation Data Set 으로 구별해서 사용한다.
따라서 Data 를 구분해보면
Traing Data Set // Validation Data Set // Test Data Set 으로 구분할 수 있다.
2. 평가기준(Metric)
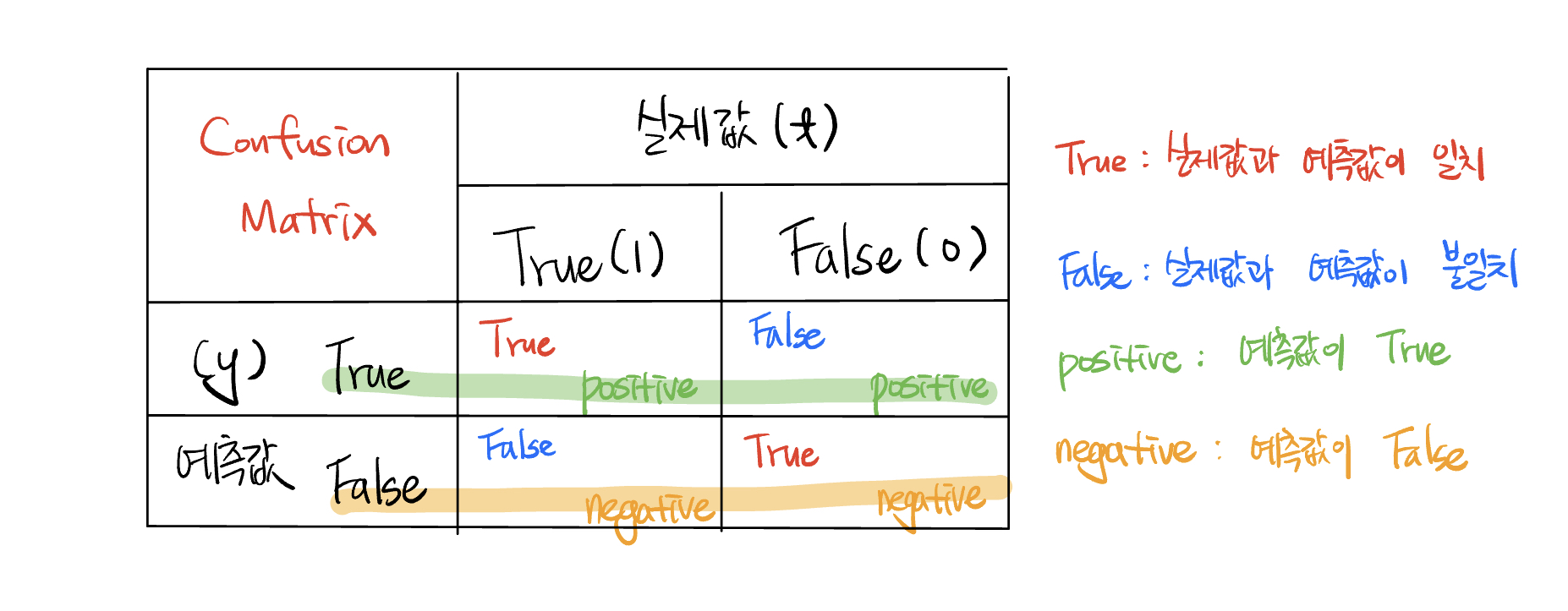
Accuracy : 정확도를 기준으로 평가를 하는 방법
# 전체 데이터를 학습용 데이터와 테스트용 데이터로 분리해주는 모듈
from sklearn.model_selection import train_test_split
# Training Data Set
x_data = scaler.transform(raw_data[['gre', 'gpa']].values)
t_data = raw_data['admit'].values.reshape(-1,1)
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(x_data,
t_data,
test_size=0.2)
# 분리를 할 때에는 랜덤으로 데이터를 섞은 뒤 분리를 해준다.
model = Sequential()
model.add(Flatten(input_shape=(2,)))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-2),
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_data_train,
t_data_train,
epochs=500,
validation_split=0.2, #중간테스트를 위해 데이터를 분리 즉 현재 epochs 에 대한 평가를 진행한다.
verbose=1)
# 학습률이 1e-4 일 때,
# Epoch 500/500
# - loss: 0.6792 - accuracy: 0.5902 - val_loss: 0.6416 - val_accuracy: 0.6721
# 정확도는 0.59. 평가시의 정확도는 0.67
# 학습률이 1e-2 일 때,
# Epoch 500/500
# - loss: 0.6184 - accuracy: 0.6639 - val_loss: 0.5491 - val_accuracy: 0.7705
# 모델이 최종적으로 완성되었다고 느낀다면 가장 마지막으로 test data set을 이용해서 모델의 평가를 시작한다.
eval_result = model.evaluate(x_data_test, t_data_test)
sklearn.model_selection 이 가지고 있는 train_test_split 모듈을 사용해서
train_test_split(x_data,t_data, test_size=0.2)
큰 틀에서의 Training Data Set 과 Test Data Set 을 구분한다.
평가를 위해서는 Model에도 환경설정을 해주어야 한다.
model.compile(... metrics=['accuracy'])
모델 객체를 만들고, 레이어를 추가하는 것들은 단순히 모델의 틀을 잡는 것에 불과하다.
결국 머신러닝 모델을 만든다는 것은
hyper parameter, 학습률이나 epochs 등의 수치를 조정해서 모델을 튜닝함으로써 그 평가결과의 졍확도를 끌어올리는 것이다.
