Paper Link : https://arxiv.org/pdf/2309.11495
※ 본 포스팅은 논문의 가장 중요한 내용에 대한 리뷰를 정리하여 올리기 때문에 다소 축약되거나 의역된 내용이 많습니다. 참고하세요.Abstract
사실적으로 그럴듯하지만 잘못된 정보를 생성하는 것, 즉 환각현상(=Hallucinations)은 LLMs에서 해결되지 않은 문제입니다. 우리는 언어 모델이 응답에 대해 스스로 검토하여 실수를 수정할 수 있는 능력을 연구합니다. 우리는 언어 모델이 먼저 (i) 초기 응답을 초안으로 작성한 다음, (ii) 초안을 사실 확인하기 위해 검증 질문을 계획하고, (iii) 이러한 질문에 독립적으로 답하여 다른 응답에 의해 편향되지 않도록 하며, (iv) 최종 검증된 응답을 생성하는 Chain-of-Verification (CoVe) 방법을 개발했습니다. 실험에서 CoVe가 Wikidata의 목록 기반 질문, 책 없이 답하는 MultiSpanQA, 장문 텍스트 생성 등 다양한 작업에서 환각을 감소시킨다는 것을 보여주었습니다.
1. Introduction
대형 언어 모델(LLMs)은 수십억 개의 토큰으로 구성된 방대한 텍스트 문서 코퍼스를 학습합니다. 모델 매개변수의 수가 증가함에 따라 책 없이 답하는 QA와 같은 작업의 정확도가 향상되고, 더 큰 모델이 더 정확한 사실 진술을 생성할 수 있다는 것이 입증되었습니다 (Radford et al., 2019; Petroni et al., 2019). 그러나 가장 큰 모델조차도 여전히 실패할 수 있으며, 특히 학습 코퍼스에서 상대적으로 드물게 발생하는 잘 알려지지 않은 중간 빈도 및 꼬리 분포 사실에 대해서는 더 그렇습니다 (Sun et al., 2023a). 이러한 경우 모델이 틀린 답을 생성하면 대신 그럴듯해 보이는 대체 응답(예: 유사하지만 잘못된 개체)을 생성합니다. 이러한 사실적으로 부정확한 생성물을 환각(Hallucinations)이라고 합니다 (Maynez et al., 2020). 또한 여러 문장이나 단락을 생성하는 장문 작업에서는 노출 편향 문제로 인해 환각 문제가 더욱 악화될 수 있습니다 (Wang & Sennrich, 2020).
현재의 언어 모델 연구는 단순한 다음 단어 예측을 넘어, 모델의 추론 능력에 초점을 맞추고 있습니다. 추론 작업의 성능 향상은 언어 모델이 응답하기 전에 내부 사고나 추론 체인을 먼저 생성하도록 유도함으로써 얻을 수 있습니다 (Wei et al., 2022; Adolphs et al., 2021; Wang et al., 2022; Lanchantin et al., 2023). 또한, 초기 응답을 자기 비판을 통해 업데이트하는 방법도 있습니다 (Press et al., 2022; Madaan et al., 2023). 본 연구에서는 이러한 연구 방향을 따르며, 언어 모델 기반 추론이 환각을 줄이는 데 어떻게 그리고 언제 사용될 수 있는지를 연구합니다. 우리는 Chain-of-Verification (CoVe)라는 접근법을 개발했으며, 초기 초안 응답을 받은 후 먼저 작업을 검증하기 위한 질문을 계획하고, 체계적으로 그 질문에 답하여 최종적으로 개선된 수정 응답을 생성합니다. 독립적인 검증 질문이 원래의 장문 응답에서보다 더 정확한 사실을 제공하는 경향이 있어 전체 응답의 정확성을 향상시킨다는 것을 발견했습니다. 우리는 목록 기반 질문, 책 없이 답하는 QA, 장문 텍스트 생성 등 다양한 작업에서 이 방법의 변형을 연구합니다. 처음에는 왼쪽에서 오른쪽으로 전체 검증 체인을 생성하는 공동 접근법을 제안했으며, 이는 기본 언어 모델에 비해 성능을 향상시키고 환각을 감소시켰습니다. 그러나 자신의 생성물에서 기존의 환각을 참조하는 모델은 환각을 반복하는 경향이 있습니다. 따라서 우리는 어떤 맥락을 참조할 것인가에 따라 검증 체인 단계를 분리하는 분할 변형을 도입하여 추가적인 개선을 도모했습니다. 이러한 분할 변형이 고려된 세 가지 작업 모두에서 성능을 더욱 향상시킨다는 것을 보여줍니다.

🔼 Figure 01: Chain-of-Verification (CoVe) 방법. 사용자 질문이 주어지면 대형 언어 모델이 부정확성, 예를 들어 사실적 환각을 포함할 수 있는 기본 응답을 생성합니다. 여기서 ChatGPT가 실패한 질문을 보여줍니다(자세한 내용은 9장을 참조하세요). 이를 개선하기 위해 CoVe는 먼저 물어볼 검증 질문 세트를 계획하고, 이를 실행하여 질문에 답하고 일치 여부를 확인합니다. 개별 검증 질문은 일반적으로 원래 장문 생성의 사실 정확도보다 더 높은 정확도로 답변된다는 것을 발견했습니다. 마지막으로 수정된 응답은 이러한 검증을 반영합니다. CoVe의 분할 버전은 원래 응답을 조건으로 할 수 없도록 검증 질문에 답변하여 반복을 피하고 성능을 향상시킵니다.
2. Related Work
환각(hallucination)은 요약(Maynez et al., 2020)에서 오픈 도메인 대화(Roller et al., 2020)까지 다양한 작업에서 나타나는 언어 모델 생성의 일반적인 문제로, 단순히 학습 데이터나 모델 크기를 확장한다고 해결되지 않습니다(Zhang et al., 2023). 환각 문제에 대한 개요는 Ji et al. (2023)을 참조하십시오. 환각을 줄이기 위한 방법의 대부분은 대략 세 가지로 나눌 수 있습니다.
훈련 시 수정 방법에서는 인코더-디코더 또는 디코더 전용 언어 모델의 좌에서 우로 진행되는 원시 생성을 개선하려고 시도합니다. 이는 모델 가중치를 훈련하거나 조정하여 환각된 생성의 확률을 낮추는 방법을 포함합니다. 여기에는 강화 학습(Roit et al., 2023; Wu et al., 2023), 대조 학습(Chern et al., 2023b; Sun et al., 2023b) 및 기타 방법(Li et al., 2023)이 포함됩니다.
생성 시 수정 방법에서는 기본 대형 언어 모델(LLM) 위에 추론 결정을 추가하여 더 신뢰할 수 있도록 하는 것이 일반적인 주제입니다. 예를 들어, 생성된 토큰의 확률을 고려하는 방법(Mielke et al., 2022; Kadavath et al., 2022)이 있습니다. Manakul et al. (2023)에서는 모델에서 여러 샘플을 추출하여 환각을 감지합니다. Varshney et al. (2023)에서는 낮은 신뢰 점수를 사용하여 환각을 식별하고, 검증 절차를 통해 그 정확성을 확인하고 이를 완화한 후 생성을 계속합니다.
신뢰 점수를 사용하는 것 대신, LLM 출력의 불일치를 활용하여 환각을 감지할 수 있습니다. Agrawal et al. (2023)는 여러 샘플과 일관성 감지를 함께 사용하여 직접 및 간접 질문을 통해 환각된 참조를 확인합니다. Cohen et al. (2023)는 LM vs LM이라는 방법을 도입하여 두 개의 LLM 간 상호 작용을 시뮬레이션합니다. 여기서 하나의 LLM이 검사관 역할을 하여 반복된 교차 검사로 출력의 일관성을 테스트합니다. Cohen et al. (2023)는 QA 작업에서 불일치를 사용하는 것이 환각 감지를 위한 신뢰 점수 사용보다 뛰어날 수 있음을 보여줍니다. COVE 또한 관련된 자기 일관성 접근법을 사용하지만, 다중 에이전트(다중 LLM) 토론 개념은 포함하지 않습니다.
세 번째 접근 방식은 언어 모델 자체의 능력에만 의존하지 않고 외부 도구를 사용하여 환각을 완화하는 것입니다. 예를 들어, 검색 증강 생성(retrieval-augmented generation)은 사실적 문서를 사용하여 기반을 마련함으로써 환각을 감소시킬 수 있습니다 (Shuster et al., 2021; Jiang et al., 2023b; Yu et al., 2023) 또는 연쇄 추론 검증(chain-of-thought verification)을 사용할 수 있습니다 (Zhao et al., 2023). 다른 접근 방식으로는 사실 확인을 위한 도구를 사용하는 것(Chern et al., 2023a; Galitsky, 2023; Peng et al., 2023)이나, 출처가 명시된 외부 문서에 연결하는 것(Menick et al., 2022; Rashkin et al., 2023; Gao et al., 2023)이 포함됩니다.
환각 감소를 명시적으로 다루지 않더라도 논리적 및 수학적 작업의 추론을 개선하는 데 관련된 여러 연구가 있습니다. 시스템에 의한 확장된 추론 단계를 통해 결과를 개선하는 여러 접근 방식이 입증되었습니다. 여기에는 연쇄 추론(Wei et al., 2022), 연역 검증(Ling et al., 2023), 자기 검증(Miao et al., 2023; Jiang et al., 2023a; Weng et al., 2022)이 포함됩니다. 자기 검증 방법은 수학 문제에 대한 답을 기반으로 (마스킹된) 질문을 예측하고, 이를 올바른 해결책이라는 증거로 사용합니다.
3. CHAIN-OF-VERIFICATION
우리의 접근 방식은 기본 LLM에 접근할 수 있다는 가정을 기반으로 합니다. 이 모델은 환각이 발생할 가능성이 있더라도 몇 가지 예제(few-shot) 또는 예제 없이(zero-shot) 일반적인 지시를 수행할 수 있어야 합니다. 우리의 방법의 주요 가정은 이 언어 모델이 적절히 프롬프트될 때, 스스로를 검증하기 위한 계획을 생성하고 실행할 수 있으며, 이를 통해 자신의 작업을 확인하고 최종적으로 이 분석을 개선된 응답에 반영할 수 있다는 것입니다.
우리의 전체 과정인 Chain-of-Verification (CoVe)은 다음 네 가지 핵심 단계를 수행합니다:
- 기본 응답 생성: 질문이 주어지면 LLM을 사용하여 응답을 생성합니다.
- 검증 계획: 질문과 기본 응답을 바탕으로 원래 응답에 실수가 있는지 자가 분석할 수 있도록 도와줄 검증 질문 목록을 생성합니다.
- 검증 실행: 각 검증 질문에 차례대로 답변하고, 이를 원래 응답과 비교하여 불일치나 실수를 확인합니다.
- 최종 검증된 응답 생성: 발견된 불일치(있는 경우)를 고려하여 검증 결과를 반영한 수정된 응답을 생성합니다.
이 각 단계는 동일한 LLM에 다른 방식으로 프롬프트를 주어 원하는 응답을 얻음으로써 수행됩니다. 1, 2, 4단계는 모두 단일 프롬프트로 호출할 수 있지만, 3단계에서는 공동, 2단계, 분할 버전 등의 변형을 조사합니다. 이러한 변형은 단일 프롬프트, 두 개의 프롬프트 또는 질문당 독립적인 프롬프트를 포함하며, 더 정교한 분해가 더 나은 결과를 도출할 수 있습니다.
이 단계들을 더 자세히 설명합니다. 접근 방식의 개요는 그림 1과 부록의 그림 3에 나와 있습니다.
3.1 Baseline Response
질문이 주어지면 LLM을 사용하여 평소처럼 좌에서 우로 응답을 생성합니다. 이는 CoVe 파이프라인의 첫 번째 단계이자, 실험에서 개선하고자 하는 기준 응답이 됩니다(즉, 이 기준 응답과 전체 방법을 통해 생성된 최종 검증된 응답을 직접 비교할 것입니다). 이러한 기준 생성물이 일반적으로 환각에 취약하기 때문에, CoVe는 다음 단계에서 이러한 환각을 식별하고 수정하려고 시도합니다.
3.2 Plan Verifications
원래 질문과 기준 응답을 바탕으로 모델은 기준 응답의 사실적 주장을 검증하는 일련의 검증 질문을 생성하도록 프롬프트됩니다. 예를 들어, 장문 모델 응답의 일부에 “미국-멕시코 전쟁은 1846년부터 1848년까지 미국과 멕시코 간의 무력 충돌이었다”라는 문장이 포함된 경우, 이러한 날짜를 확인하는 하나의 가능한 검증 질문은 “미국-멕시코 전쟁은 언제 시작되고 끝났나요?”가 될 수 있습니다. 검증 질문은 템플릿화되지 않으며, 언어 모델은 이를 원하는 형태로 표현할 자유가 있습니다. 또한, 원래 텍스트의 표현과 꼭 일치할 필요는 없습니다.
우리의 실험에서는 (응답, 검증) 데모를 몇 가지 제공하여 LLM에게 이러한 검증 계획을 수행하게 합니다. 실험에서 사용할 몇 가지 예제 프롬프트는 8장을 참조하십시오. 충분히 성능이 좋은 지시를 따르는 LLM의 경우, 이를 제로샷으로 수행하는 것도 가능합니다.
3.3 Execute Verifications
계획된 검증 질문이 주어지면 다음 단계는 이를 답변하여 환각이 존재하는지 평가하는 것입니다. 검색 엔진을 통한 검증과 같은 검색 증강 기술을 사용할 수 있지만, 이 작업에서는 도구 사용을 탐구하지 않습니다. 대신, CoVe의 모든 단계에서 LLM 자체만을 사용하여 모델이 스스로의 작업을 확인하도록 합니다. 우리는 검증 실행의 여러 변형을 조사합니다. 이를 공동(joint), 2단계(2-Step), 분할(factored), 그리고 분할+수정(factor+revise)이라고 부릅니다.
Joint: 공동 방법에서는 계획과 실행(단계 2와 3)을 단일 LLM 프롬프트를 사용하여 수행합니다. 이때 몇 가지 예시 데모는 검증 질문과 그 질문 직후에 답변을 포함합니다. 이 접근법에서는 별도의 프롬프트가 필요하지 않습니다. 즉, 단일 프롬프트를 통해 검증 질문을 생성하고, 그 질문에 즉시 답변하도록 합니다. 이렇게 하면 검증 질문과 답변이 하나의 프롬프트 내에서 처리됩니다.
2단계(2-Step): 공동 방법의 잠재적 단점은 검증 질문이 LLM 맥락에서 기준 응답에 조건화되어야 하며, 이 방법이 공동으로 이루어지기 때문에 검증 답변도 초기 응답에 조건화되어야 한다는 점입니다. 이는 반복의 가능성을 증가시킬 수 있으며, 이는 현대 LLM의 알려진 문제 중 하나입니다 (Holtzman et al., 2019). 따라서 검증 질문이 원래 기준 응답과 유사하게 환각할 수 있으며, 이는 목적에 어긋납니다.
따라서 우리는 계획과 실행을 각각 별도의 단계로 분리하여, 각 단계에서 자체 LLM 프롬프트를 사용합니다. 첫 번째 단계에서 계획 프롬프트는 기준 응답에 조건화됩니다. 계획에서 생성된 검증 질문은 두 번째 단계에서 답변되며, 이때 LLM 프롬프트에 제공된 맥락은 질문만 포함하고 원래 기준 응답은 포함하지 않아 직접적인 답변 반복을 방지합니다.
분할(Factored): 더 정교한 접근 방식은 모든 질문에 대해 각각 독립적으로 프롬프트를 사용하는 것입니다. 이 프롬프트에는 원래 기준 응답이 포함되지 않아 단순히 복사하거나 반복할 가능성이 줄어듭니다. 분할 접근 방식의 추가 장점은 기준 응답뿐만 아니라 답변 맥락 간의 잠재적 간섭도 제거할 수 있다는 점입니다. 이는 Radhakrishnan et al. (2023)의 최근 연구에서 분할 분해를 통한 하위 질문 답변과 유사하여 그들의 명명 방식을 채택합니다. 또한 단일 맥락에 맞출 필요가 없어 더 많은 검증 질문을 처리할 수 있습니다.
이 접근 방식은 많은 LLM 프롬프트를 실행해야 하므로 계산 비용이 더 많이 들 수 있지만, 병렬로 실행할 수 있어 배치 처리할 수 있습니다. 이를 수행하기 위해 먼저 3.2절에서 생성된 질문 세트를 개별 질문으로 분리해야 합니다. 이는 몇 가지 예시 데모를 통해 질문이 쉼표로 구분된 목록으로 생성되도록 하면 비교적 쉬운 작업입니다. 그런 다음 이를 개별 LLM 프롬프트로 분할할 수 있습니다.
분할+수정(Factor+Revise): 검증 질문에 답한 후, 전체 CoVe 파이프라인은 이러한 답변이 원래 응답과 일치하지 않는지 암묵적 또는 명시적으로 교차 검토해야 합니다. 분할+수정 접근 방식에서는 이를 추가 LLM 프롬프트를 통해 의도적으로 실행하여, 최종 시스템이 이 단계를 명시적으로 추론하기 쉽게 만듭니다. 검증 질문에 답하는 것과는 달리, 교차 검토 단계는 기준 응답과 검증 질문 및 답변 모두에 조건화될 필요가 있습니다. 따라서 이를 별도의 LLM 프롬프트로 실행합니다. 각 질문에 대해 하나의 "교차 검토" 프롬프트를 사용하며, 몇 가지 예시 데모를 통해 원하는 출력을 보여줍니다.
3.4 Final Verified Response
마지막으로, 검증을 반영한 개선된 응답을 생성합니다. 이는 최종 몇 가지 예시 프롬프트를 통해 실행되며, 맥락은 이전의 모든 추론 단계, 기준 응답, 검증 질문 및 답변 쌍을 고려하여 수정이 이루어질 수 있도록 합니다. 분할+수정(Factor+Revise) 접근 방식을 사용하는 경우, 교차 검토 불일치 감지의 결과도 함께 제공됩니다.
4. Experiments
우리는 다양한 실험 벤치마크를 사용하여 CoVe가 환각을 줄이는 효과를 측정하고, 여러 기준선과 비교합니다.
4.1 Tasks
우리가 사용하는 벤치마크는 요구되는 답변이 엔터티 집합인 목록 기반 질문부터 여러 자유 형식 문장으로 구성된 장문 생성까지 다양합니다.
4.1.1 WikiData
우리는 먼저 CoVe를 Wikidata API1을 사용하여 자동 생성된 질문 세트로 테스트합니다. 다음과 같은 형식의 목록 질문을 만듭니다: "누가 [도시]에서 태어난 [직업]인가요?" 예를 들어, "보스턴에서 태어난 정치인은 누구인가요?" 이러한 질문에 대한 답은 엔터티 집합이며, 정답 목록은 Wikidata 지식 베이스에서 얻습니다. 이를 통해 56개의 테스트 질문으로 구성된 데이터셋이 만들어지며, 각 질문에는 약 600개의 알려진 정답 엔터티가 포함됩니다. 그러나 일반적으로 LLM은 훨씬 더 짧은 목록을 생성합니다.
우리는 성능을 측정하기 위해 정밀도(micro-averaged) 지표를 사용하며, 생성된 긍정적 엔터티와 부정적 엔터티의 평균 수를 보고합니다.
4.1.2 Wiki-Category List
그 다음으로 우리는 더 어려운 집합 생성 작업으로 나아갑니다. Wikipedia 카테고리 목록을 사용하여 생성된 QUEST(Malaviya et al., 2023) 데이터셋을 사용합니다. 이 카테고리 이름을 질문으로 변환하기 위해 "몇 가지 이름을 말해 주세요(Name some)"라는 구문을 앞에 추가합니다. 예를 들어 "몇 가지 멕시코의 애니메이션 공포 영화를 말해 주세요" 또는 "베트남의 자생 난초 몇 가지를 말해 주세요"와 같은 다양한 질문으로 인해 이 작업이 더 큰 도전 과제가 될 수 있다고 생각합니다.
논리적 연산을 필요로 하지 않는 모든 예제를 데이터셋에서 모아 각 55개의 테스트 질문 세트를 만들고, 각 질문에는 약 8개의 정답이 포함됩니다. Wikidata 작업과 유사하게, 성능을 측정하기 위해 정밀도(micro-averaged) 지표를 사용하며, 생성된 긍정적 엔터티와 부정적 엔터티의 평균 수를 보고합니다.
4.1.3 MultiSpanQA
다음으로, 우리는 우리의 접근 방식을 독해 벤치마크인 MultiSpanQA(Li et al., 2022)에서 테스트합니다. MultiSpanQA는 여러 독립적인 답변을 가지는 질문들로 구성되어 있으며, 이는 텍스트에서 여러 비연속적 구간으로부터 파생됩니다. 질문은 원래 Natural Questions 데이터셋에서 가져온 것입니다. 우리는 지원 문서를 제공하지 않는 책 없이(closed-book) 설정을 고려하며, 따라서 기본 LLM이 더 잘 답변할 수 있도록 사실 기반의 질문 하위 집합을 사용합니다. 이에 따라 각 구간당 짧은 답변(항목당 최대 3개의 토큰)을 가진 418개의 질문 테스트 세트를 사용합니다.
예를 들어, 질문: "최초의 인쇄기를 발명한 사람과 연도는?"
답변: "요하네스 구텐베르크, 1450".
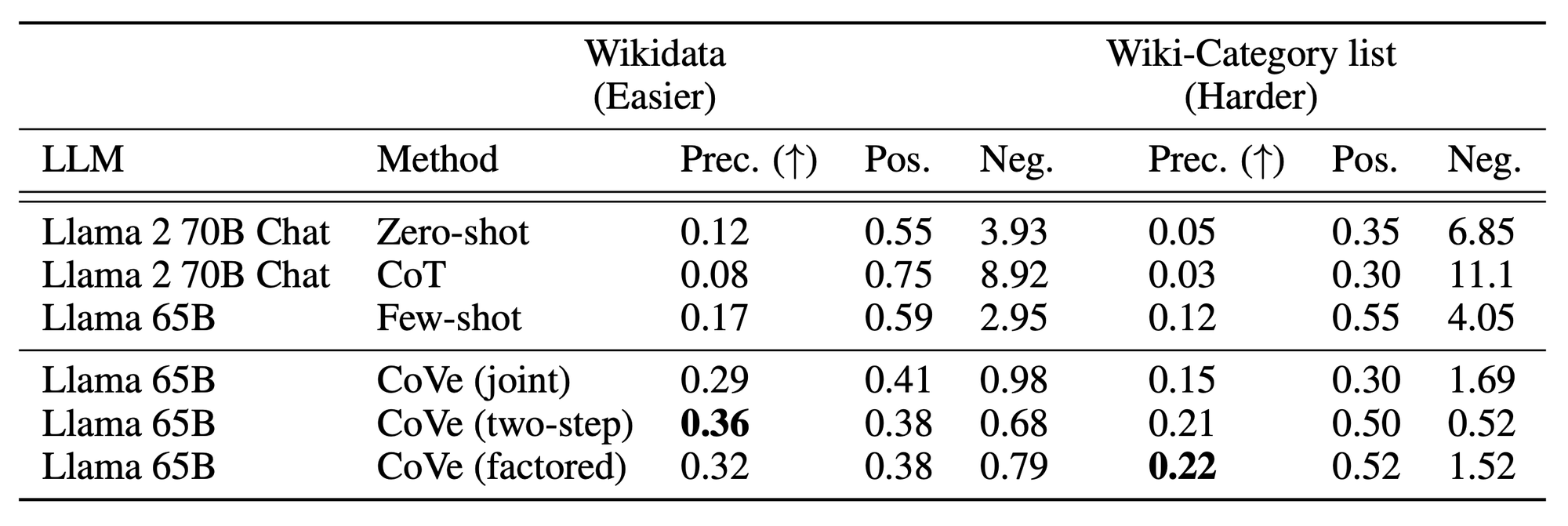
🔼 Table 1: Wikidata 및 Wiki-Category 목록 작업에서 리스트 기반 질문에 대한 테스트 정밀도와 긍정적 및 부정적(환각) 엔터티의 평균 수.
4.1.4 Longform Generation of Biographies
다음으로 우리는 장문 텍스트 생성에서 CoVe의 성능을 검증합니다. 이 설정에서는 Min et al. (2023)이 제안한 벤치마크를 채택하여 전기를 생성하는 방법을 평가합니다. 여기서 모델은 다음과 같은 프롬프트를 사용하여 선택된 엔터티의 전기를 생성하도록 단순히 프롬프트됩니다: “entity의 전기를 말해 주세요”. 우리는 이 접근 방식의 효과를 해당 연구에서 개발된 FACTSCORE 지표(Min et al., 2023)를 사용하여 평가합니다. 이 지표는 검색 증강 언어 모델(Instruct-Llama, “Llama + Retrieval + NP”)을 사용하여 응답을 사실 확인하며, 인간 판단과 높은 상관관계가 있음을 보여주었습니다.
4.2 Baselines
우리는 강력한 오픈 모델인 Llama 65B(Touvron et al., 2023a)를 기본 LLM으로 사용하며, 모든 모델에 대해 탐욕적 디코딩을 사용합니다. Llama 65B는 지시 조정이 되지 않았으므로, 각 벤치마크에서 성능을 측정하기 위해 각 작업에 맞는 몇 가지 예시를 사용합니다. 이는 CoVe가 개선하려는 주요 기준선이 됩니다. CoVe는 동일한 Llama 65B 기반을 사용하지만, 동일한 몇 가지 예시에 대해 검증 질문과 최종 검증된 응답의 예시를 포함합니다(그림 1 및 3절 참조). 따라서 동일한 LLM에 대해 원래 기준선 응답을 개선할 수 있는 능력을 측정합니다. CoVe의 경우, 모든 작업에서 공동(joint) 및 분할(factored) 버전을 특히 비교합니다.
우리는 또한 Llama 지시 조정 모델인 Llama 2(Touvron et al., 2023b)와 비교합니다. 이 모델에 대해 작업의 제로샷 성능과 제로샷 프롬프트에 "단계별로 생각해 봅시다"를 추가한 연쇄 추론(chain-of-thought) 성능을 측정합니다. 지시 조정 모델은 쿼리 시 불필요한 내용을 생성하는 경향이 있으며, 이는 특히 목록 기반 작업에서 문제가 될 수 있습니다. 이를 해결하기 위해 프롬프트에 "쉼표로 구분된 답변만 나열하십시오"라는 추가 줄을 추가합니다. 또한 상용 NER 모델을 사용하여 답변을 추출하는 후처리 단계를 추가하여 이 문제를 더 잘 피하도록 합니다. 그러나 Multi-Span-QA와 같이 모든 답변이 명명된 엔터티가 아닌 작업의 경우 몇 가지 예시가 작업의 도메인을 효과적으로 보여주기 때문에 여전히 몇 가지 예시(few-shot)가 이를 개선할 것으로 기대합니다.
전기 생성과 같은 장문 생성 작업에서도 우리는 Min et al. (2023)에서 보고된 여러 기존 모델 결과와 비교합니다. 특히 InstructGPT (Ouyang et al., 2022), ChatGPT 2, 그리고 PerplexityAI 3와 비교합니다.
4.3 Results
우리는 다음 연구 질문에 대해 실증적으로 답하고자 합니다:
RQ1: CoVe가 LLM이 생성하는 환각 콘텐츠의 비율을 효과적으로 줄일 수 있는가?
RQ2: CoVe가 올바른 콘텐츠의 양을 줄이지 않고 잘못된 생성을 수정하거나 제거할 수 있는가?
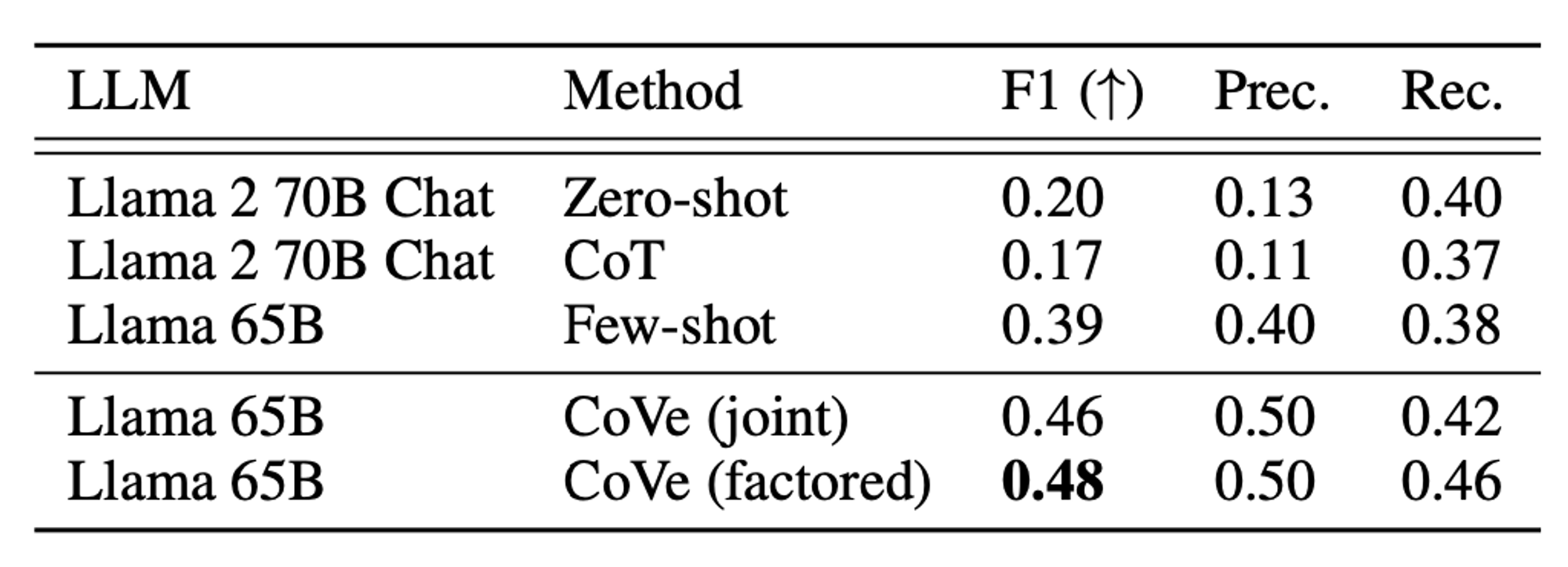
🔼 Table 2 : Closed book MultiSpanQA 테스트 성능에서 CoVe와 다양한 기준선을 비교한 결과는 다음과 같습니다.
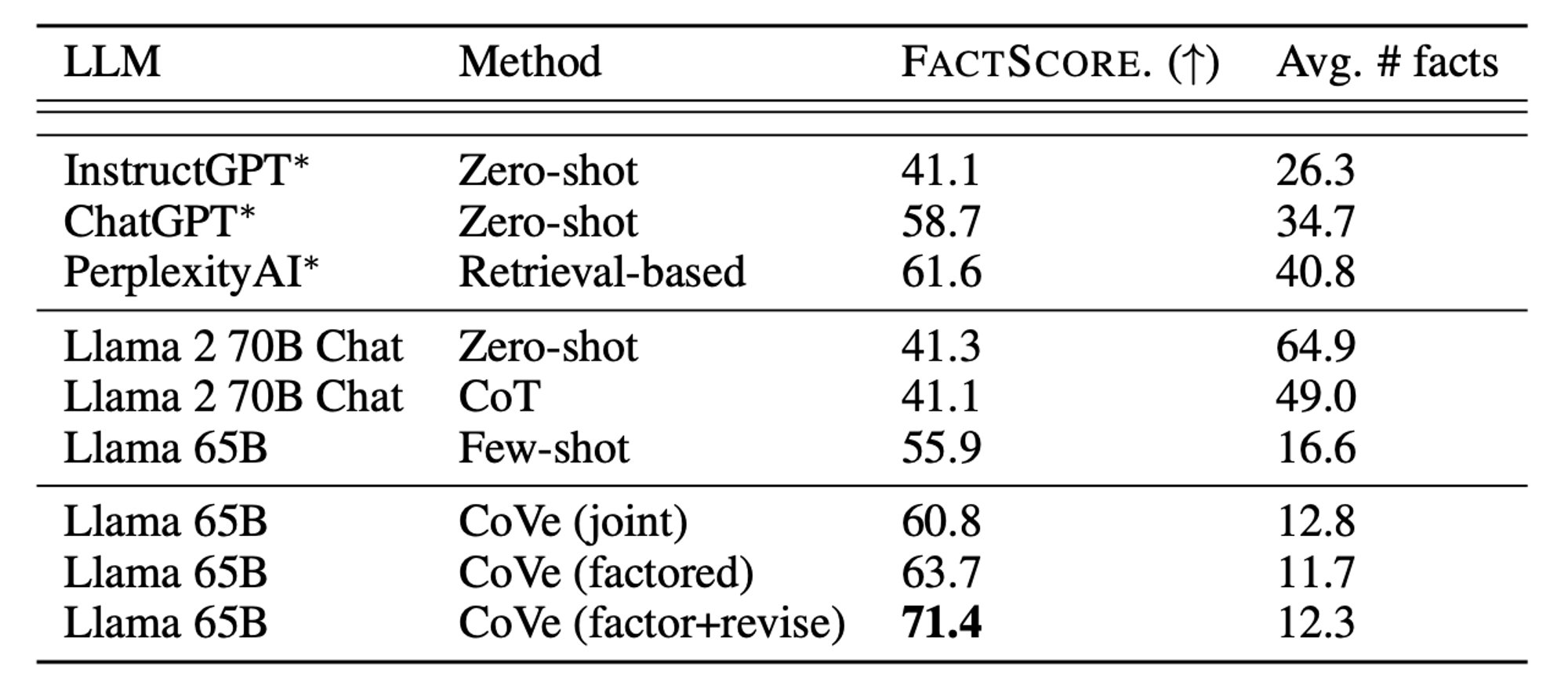
🔼 Table 3 : Min et al. (2023)에서 정의된 지표를 사용한 전기 장문 생성. ∗로 표시된 모델은 이전 연구에서 보고된 것들입니다. FACTSCORE는 "Instruct-Llama"(Retrieve → LM + NP)를 사용하여 자동으로 계산되었으며, 이는 최고의 오픈 액세스 모델입니다.
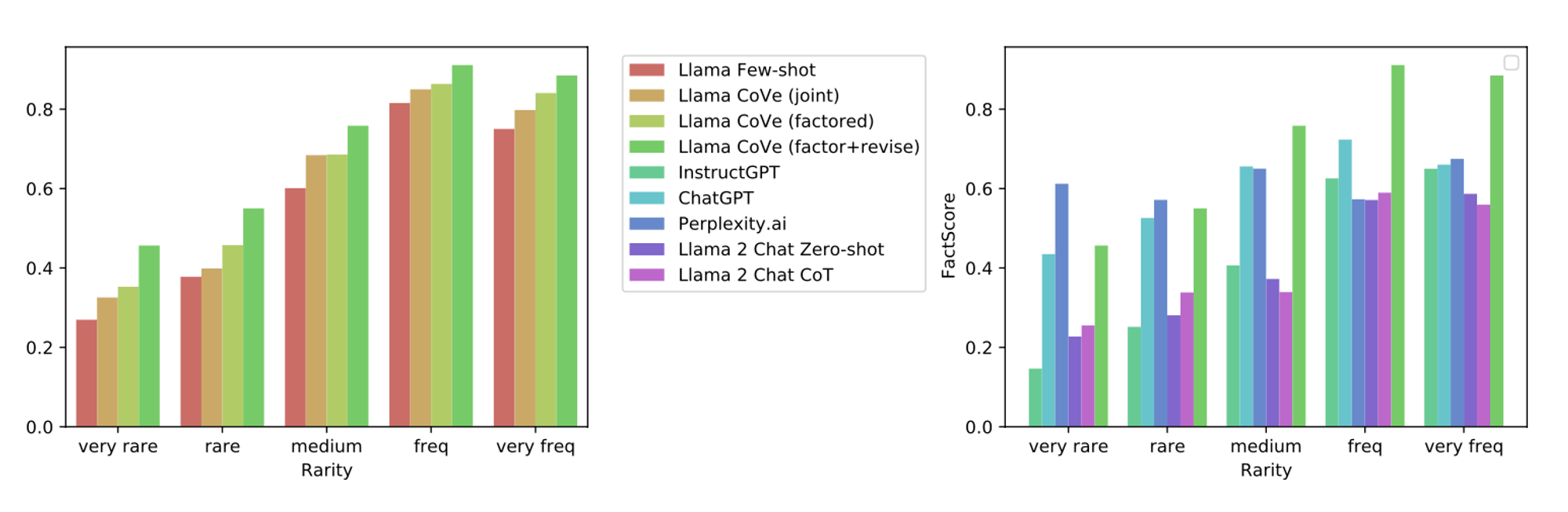
🔼 Figure 02 : 전기 장문 생성에서 CoVe 변형 및 다양한 기준선에 대한 FACTSCORE 성능 분포는 주요 사실, 중간 빈도 사실, 그리고 드문 사실에 걸쳐 있습니다.
우리의 주요 결과는 네 가지 벤치마크 작업에 대해 표 1, 표 2, 표 3에 제시되어 있으며, 주요 발견 사항은 다음과 같습니다.
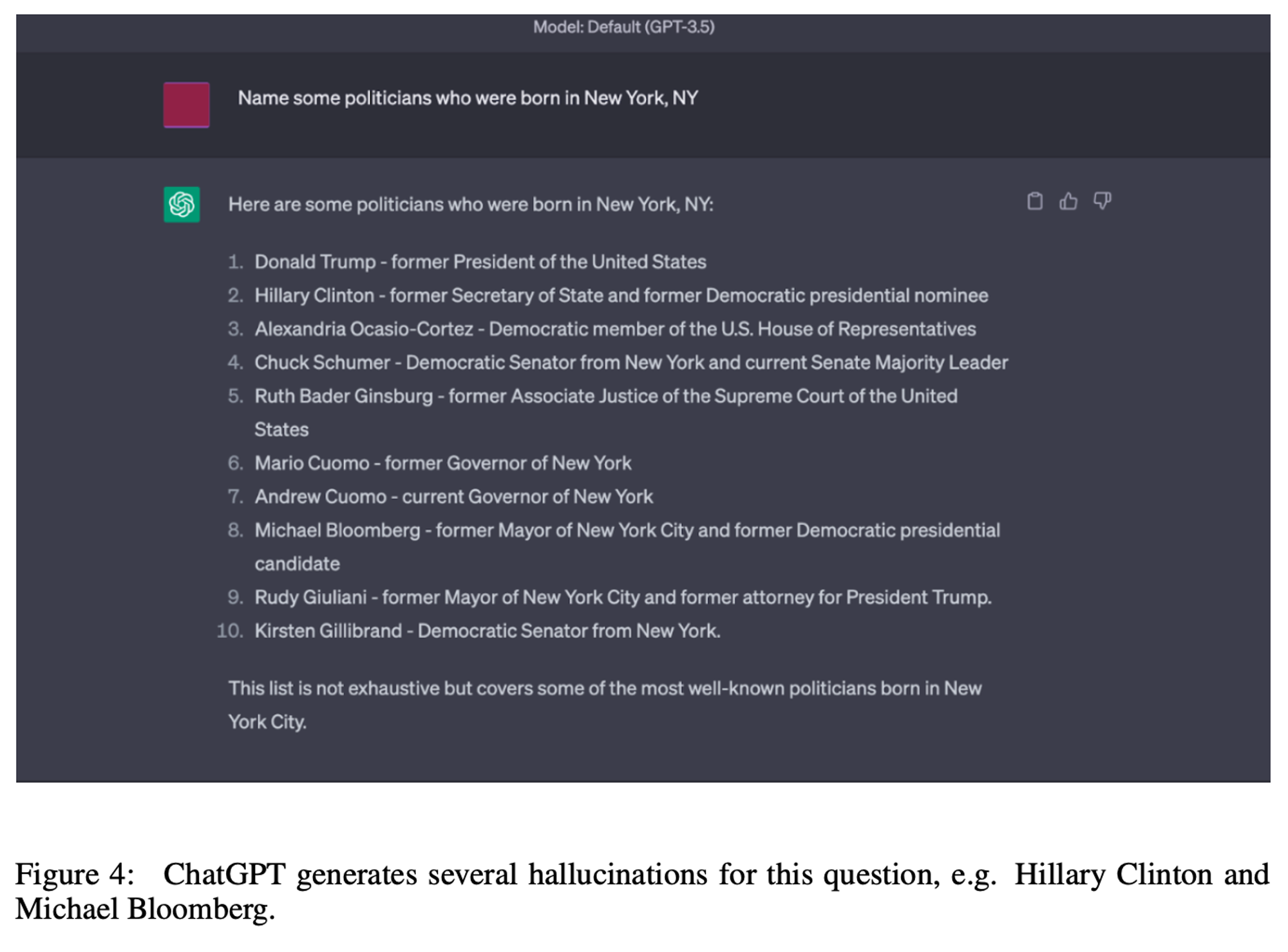
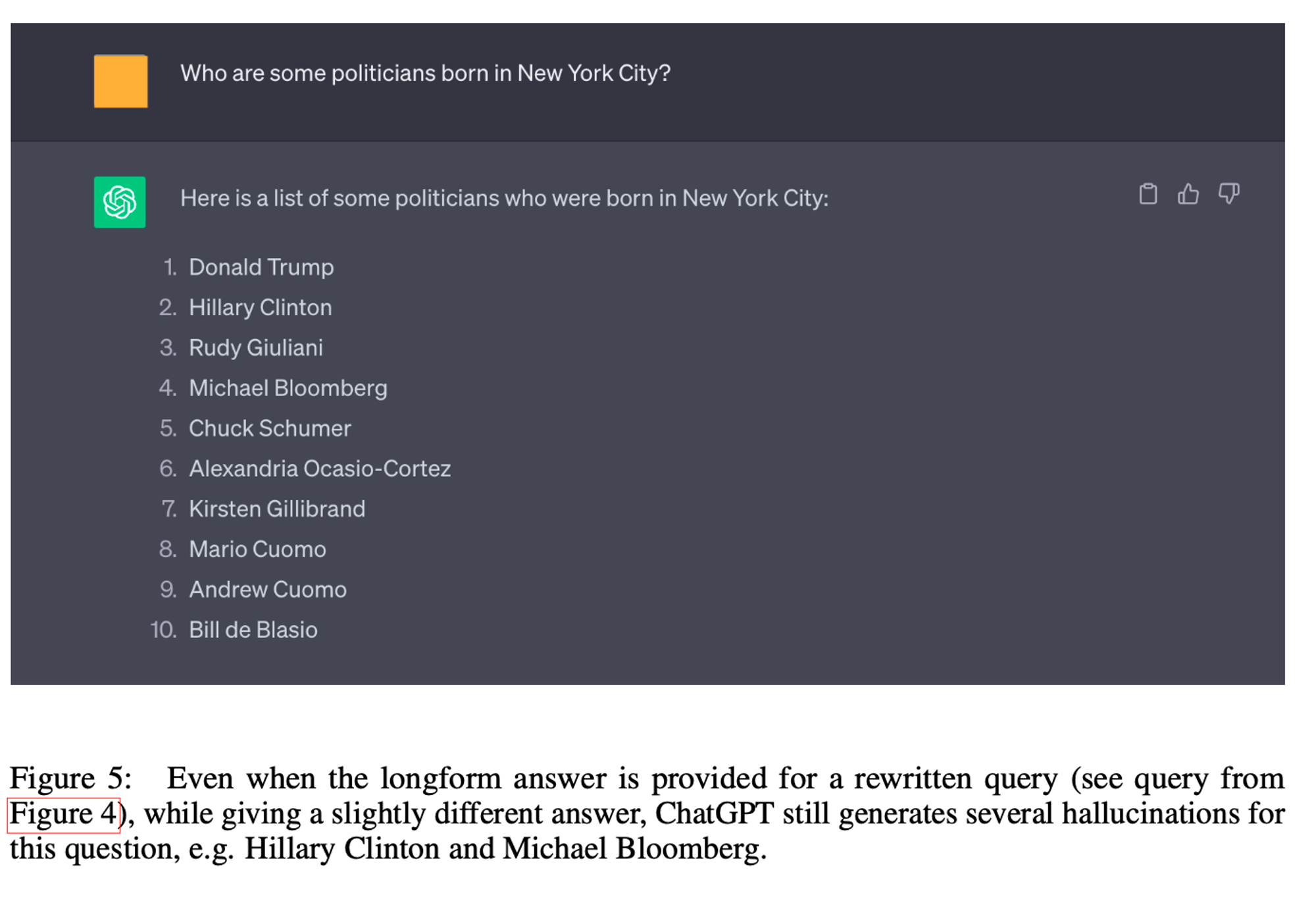
CoVe는 목록 기반 답변 작업에서 정밀도를 향상시킵니다. 우리는 CoVe가 목록 기반 작업에서 정밀도를 크게 향상시킨다는 것을 발견했습니다. 예를 들어, Wikidata 작업에서 Llama 65B 몇 가지 예시 기준선의 정밀도를 두 배 이상 증가시켰습니다(0.17에서 0.36으로). 긍정적 및 부정적 결과 분석에서, 환각된 답변의 수가 크게 감소한 반면(부정적: 2.95 → 0.68), 환각이 아닌 답변의 수는 상대적으로 적게 감소했습니다(긍정적: 0.59 → 0.38).
CoVe는 closed book QA 성능을 향상시킵니다. 우리는 CoVe가 MultiSpanQA에서 측정한 일반적인 QA 문제에서도 성능을 향상시킨다는 것을 발견했습니다. 정밀도와 재현율 모두에서 향상되어, 몇 가지 예시 기준선보다 F1 점수가 23% 증가했습니다(0.39 → 0.48).
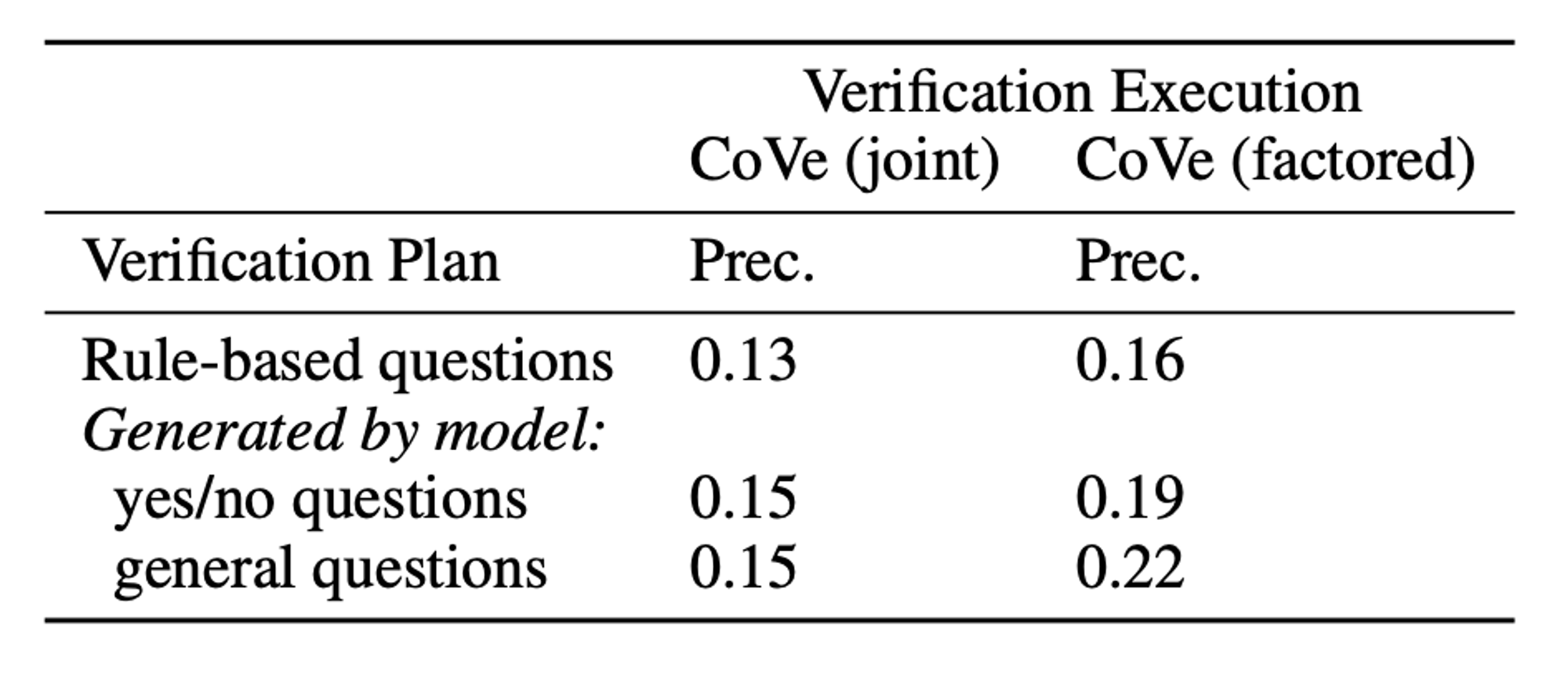
🔼 Table 4 : Wiki-Category 작업에서 다양한 CoVe 검증 계획 전략(행)과 검증 실행 기법(열)을 비교한 내용입니다.
CoVe는 장문 생성에서도 정밀도를 향상시킵니다. 이러한 결과는 실제로 QA 설정보다 더 큰 향상을 보이는 장문 생성에도 적용됩니다. FACTSCORE는 몇 가지 예시 기준선에서 28% 증가했습니다(55.9 → 71.4). 제공된 사실의 평균 수는 비교적 적게 감소했습니다(16.6 → 12.3). 그림 2에서 사실별로 개선된 내역을 보여주며, CoVe가 드문 사실과 더 자주 발생하는 사실 모두에서 결과를 향상시킨다는 것을 알 수 있습니다.
지시 조정과 연쇄 추론(CoT)은 환각을 줄이지 못합니다. 우리는 사전 학습된 Llama 모델을 사용하는 몇 가지 예시 기준선이 모든 작업에서 지시 조정된 모델인 Llama 2 Chat보다 성능이 뛰어나다는 것을 발견했습니다. 몇 가지 예시를 통해 모델이 작업에 맞는 출력을 제공하도록 유도하는 반면, 일반적인 지시 조정은 더 많은 환각이나 부정확한 출력을 생성합니다. 표준 연쇄 추론(CoT) 프롬프트도 이러한 작업의 결과를 개선하지 못했습니다. CoT가 추론 작업에 도움이 된다는 것이 입증되었지만, 우리가 측정한 환각 문제에는 적합하지 않은 것으로 보입니다.
분할 CoVe와 2단계 CoVe는 성능을 향상시킵니다. 모든 작업에서 분할 CoVe 접근 방식이 공동 CoVe에 비해 일관된 성능 향상을 보였습니다. 예를 들어, 장문 생성에서 FACTSCORE가 60.8에서 63.7로 향상되었습니다. 마찬가지로, 2단계 접근 방식도 공동 접근 방식보다 뛰어난 성능을 보였으며, Wikidata 및 Wiki-Category 목록 작업에서 테스트한 결과 2단계 접근 방식이 Wikidata에서 가장 좋은 결과를, 분할 방식이 Wiki-Category에서 가장 좋은 결과를 제공했습니다. 이 모든 결과는 검증 질문이 원래 기준 응답에 의존하지 않아야 한다는 우리의 가설을 지지하며, 이는 공동 방법이 반복할 수 있는 경향이 있기 때문입니다.
명시적인 추가 추론은 환각을 제거하는 데 도움이 됩니다. 장문 생성 작업에서 우리는 검증 답변이 불일치를 나타내는지 명시적으로 교차 검토하는 CoVe "분할+수정" 방법의 더 정교한 추론 단계를 탐구했습니다. 이러한 명시적인 추가 추론으로 FACTSCORE 지표에서 큰 향상을 보였습니다(63.7에서 71.4로). 이는 LLM에서 적절하고 명시적인 추론이 환각을 완화하는 데 있어 개선을 가져올 수 있다는 추가적인 증거를 제공합니다.
CoVe 기반 Llama는 InstructGPT, ChatGPT, PerplexityAI를 능가합니다. 장문 생성 작업에서, 기본 몇 가지 예시 Llama 65B는 FACTSCORE 지표에서 ChatGPT와 PerplexityAI 모델에 비해 성능이 떨어집니다. 그러나 CoVe를 기본 Llama 65B에 적용하면 ChatGPT와 PerplexityAI를 능가하고 InstructGPT보다도 뛰어난 성능을 발휘합니다. 이는 PerplexityAI가 검색 증강을 통해 사실을 지원할 수 있는 모델임을 고려할 때 특히 인상적입니다. 반면, CoVe는 검증(verification)을 통한 개선된 추론을 사용하여 기본 언어 모델만을 사용합니다. 그러나 그림 2에서 볼 수 있듯이, 매우 드문 사실의 경우 PerplexityAI가 CoVe를 여전히 능가하지만, 더 빈번한 사실에서는 CoVe가 PerplexityAI를 능가합니다. 일부 모델은 다른 모델보다 전체 사실 수가 적지만, FACTSCORE 지표는 정규화되어 있으므로 모델 간 비교가 가능합니다. Llama 2 70B chat의 출력을 실험적으로 잘라내어 사실 수를 줄였을 때도 FACTSCORE가 크게 변하지 않았음을 확인했습니다(예: 10문장으로 잘라낼 경우 점수가 41.3에서 42.7로 증가). 몇 가지 예시 기반 모델의 생성 길이는 본질적으로 몇 가지 예시로 결정되며, 이는 다시 맥락 길이에 의해 제한됩니다.
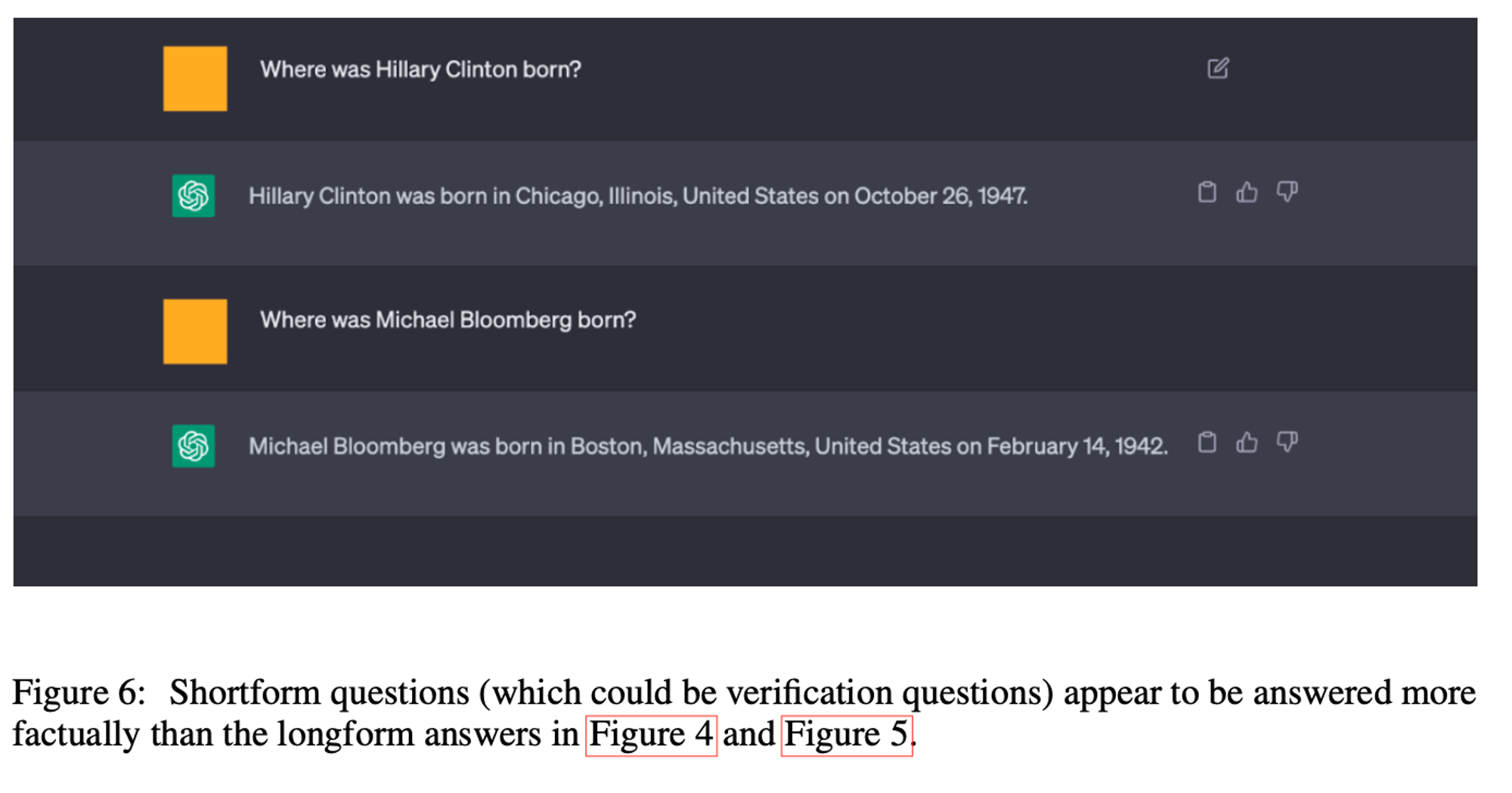
짧은 검증 질문이 장문의 질문보다 더 정확하게 답변됩니다. 장문 응답에서 LLM은 여러 환각을 생성하는 경향이 있습니다. 그러나 개별 사실에 대해 구체적으로 질문할 경우, LLM 자체가 이러한 환각이 잘못되었다는 것을 알 수 있는 경우가 많습니다(그림 1, 그림 3, 섹션 9 참조). 이는 Wikidata 작업에서 정량적으로 확인할 수 있으며, 목록 기반 질문에서 Llama 몇 가지 예시 기준선 응답 엔터티의 약 17%만이 정확합니다. 그러나 각 개별 엔터티를 검증 질문을 통해 조회할 때 약 70%가 정확하게 답변된다는 것을 발견했습니다.
LLM 기반 검증 질문이 휴리스틱을 능가합니다. CoVe 방법에서는 작업에 따라 LLM이 검증 질문을 생성합니다. 이러한 질문의 품질을 측정하기 위해, LLM 질문을 "X가 질문에 답합니까?" 형식의 템플릿 예/아니오 질문으로 대체하여 휴리스틱으로 구성된 질문과 비교합니다. Wiki-Category 작업에 대한 결과는 표 4에 나와 있으며, 규칙 기반 검증 질문에서는 정밀도가 감소한 것을 보여줍니다. 이러한 차이는 필요한 검증 질문의 유형이 더 다양해질 수 있는 장문 생성에서 더 크게 나타날 것이며, LLM 기반 검증이 더욱 필요하게 됩니다.
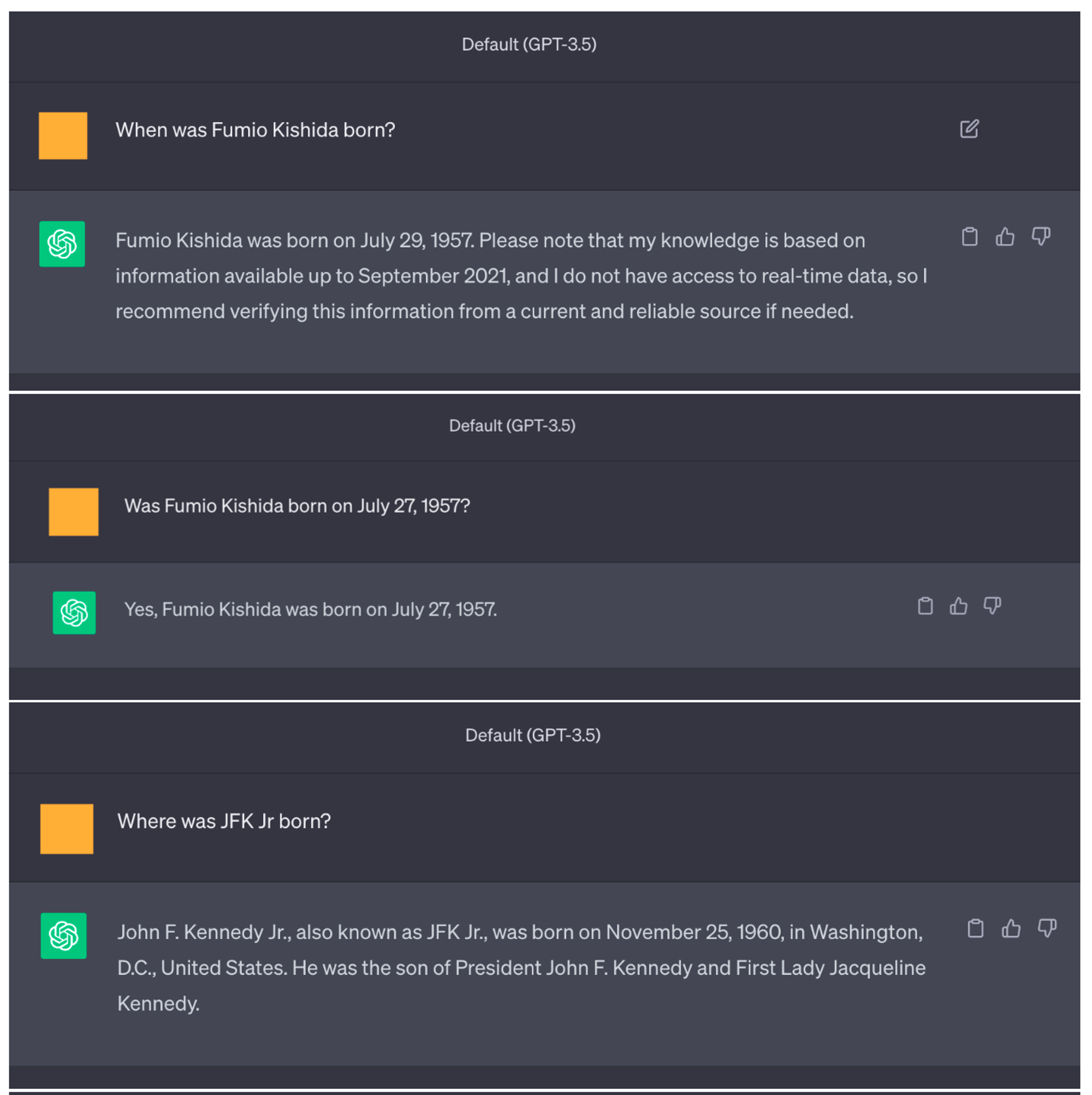
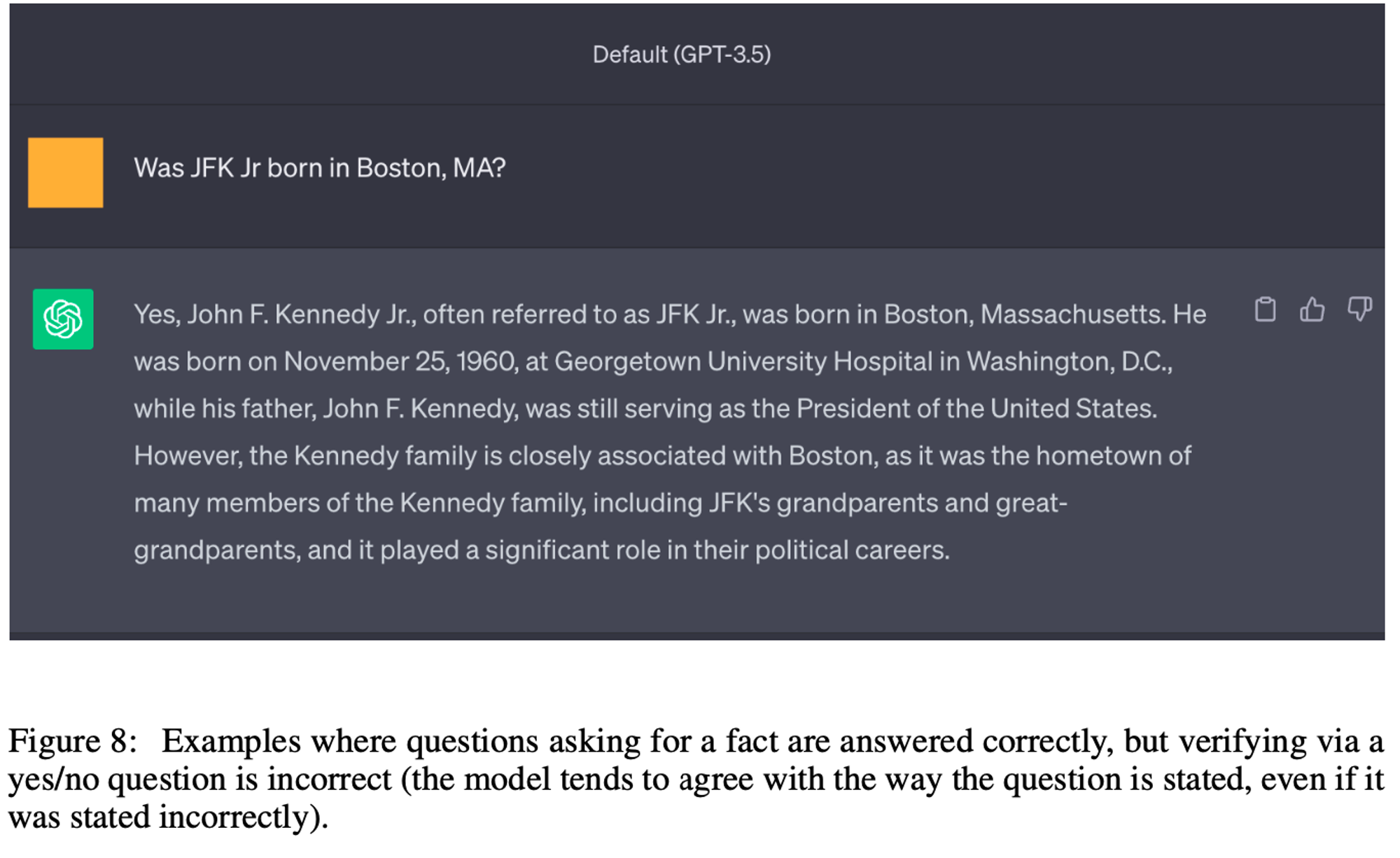
열린 검증 질문이 예/아니오 기반 질문을 능가합니다. 주요 실험에서 우리는 예상되는 답변이 사실인 검증 질문을 사용합니다. 대안으로, 사실을 검증 질문의 일부로 포함시키고 예/아니오 형식으로 묻는 방법도 있습니다. 표 4에서 이러한 차이를 평가한 결과, 예/아니오 유형의 질문이 CoVe의 분할 버전에서는 더 나쁜 성능을 보였습니다. 부록 9장에는 ChatGPT에 대한 일화적 예가 포함되어 있으며, 여기서 모델이 예/아니오 질문 형식에서는 사실이든 아니든 동의하는 경향이 있음을 발견했습니다.
5. Conclusion
우리는 Chain-of-Verification(CoVe)를 소개했습니다. CoVe는 대형 언어 모델의 환각을 줄이기 위해 모델이 자신의 응답을 검토하고 자기 교정하는 접근 방식입니다. 특히, 검증을 더 단순한 질문 세트로 분해함으로써 모델이 원래 질문에 답변할 때보다 검증 질문에 더 높은 정확도로 답할 수 있음을 보여주었습니다. 두 번째로, 검증 질문 세트에 답변할 때 모델이 이전 답변에 주의를 기울이지 않도록 제어하는 것이(분할 CoVe) 동일한 환각을 반복하는 것을 완화하는 데 도움이 됨을 입증했습니다. 전반적으로, 우리의 방법은 동일한 모델에게 자신의 답변을 검토(검증)하도록 요청함으로써 원래 언어 모델 응답보다 상당한 성능 향상을 제공합니다. 우리의 연구를 확장할 수 있는 분명한 방향은 CoVe에 도구 사용을 추가하는 것입니다. 예를 들어, 검증 실행 단계에서 검색 증강을 사용하면 추가적인 성능 향상이 있을 가능성이 큽니다.
6. Limitations
우리의 Chain-of-Verification(CoVe) 방법은 환각을 줄이는 것을 목표로 하지만, 생성물에서 이를 완전히 제거하지는 않습니다. 이는 CoVe가 기준선에 비해 개선되더라도 주어진 쿼리에 대해 여전히 잘못되거나 오해의 소지가 있는 정보를 생성할 수 있음을 의미합니다. 또한, 우리의 실험에서는 직접적으로 명시된 사실적 부정확성의 형태로만 환각을 다루었음을 주목해야 합니다. 그러나 환각은 잘못된 추론 단계, 의견의 일부 등 다른 형태로 나타날 수 있습니다. 또한, CoVe가 생성하는 결과물에는 검증 과정이 포함되는데, 이는 사용자가 볼 경우 결정의 해석 가능성을 높여주지만, 출력에서 더 많은 토큰을 생성하게 되어 계산 비용이 증가한다는 단점이 있습니다. 이는 Chain-of-Thought와 같은 다른 추론 방법과 유사합니다.
우리의 방법은 대형 언어 모델이 자신의 실수를 식별하기 위해 더 많은 시간을 들여 숙고함으로써 개선된 응답을 생성하도록 하는 것입니다. 우리는 이것이 명확한 개선을 가져온다는 것을 보여주었지만, 이러한 개선의 상한선은 모델의 전반적인 능력, 예를 들어 무엇을 알고 있는지 식별하는 능력에 의해 명확히 제한됩니다. 이와 관련하여, 2장에서 논의된 바와 같이, 언어 모델이 외부 도구를 사용하여 가중치에 저장된 것 이상의 추가 정보를 얻는 연구는 또 다른 방향입니다. 본 연구에서는 이 방안을 탐구하지 않았지만, 이러한 기법을 본 연구의 발견과 결합하면 유익할 것입니다.
7. CoVe - Further Detail
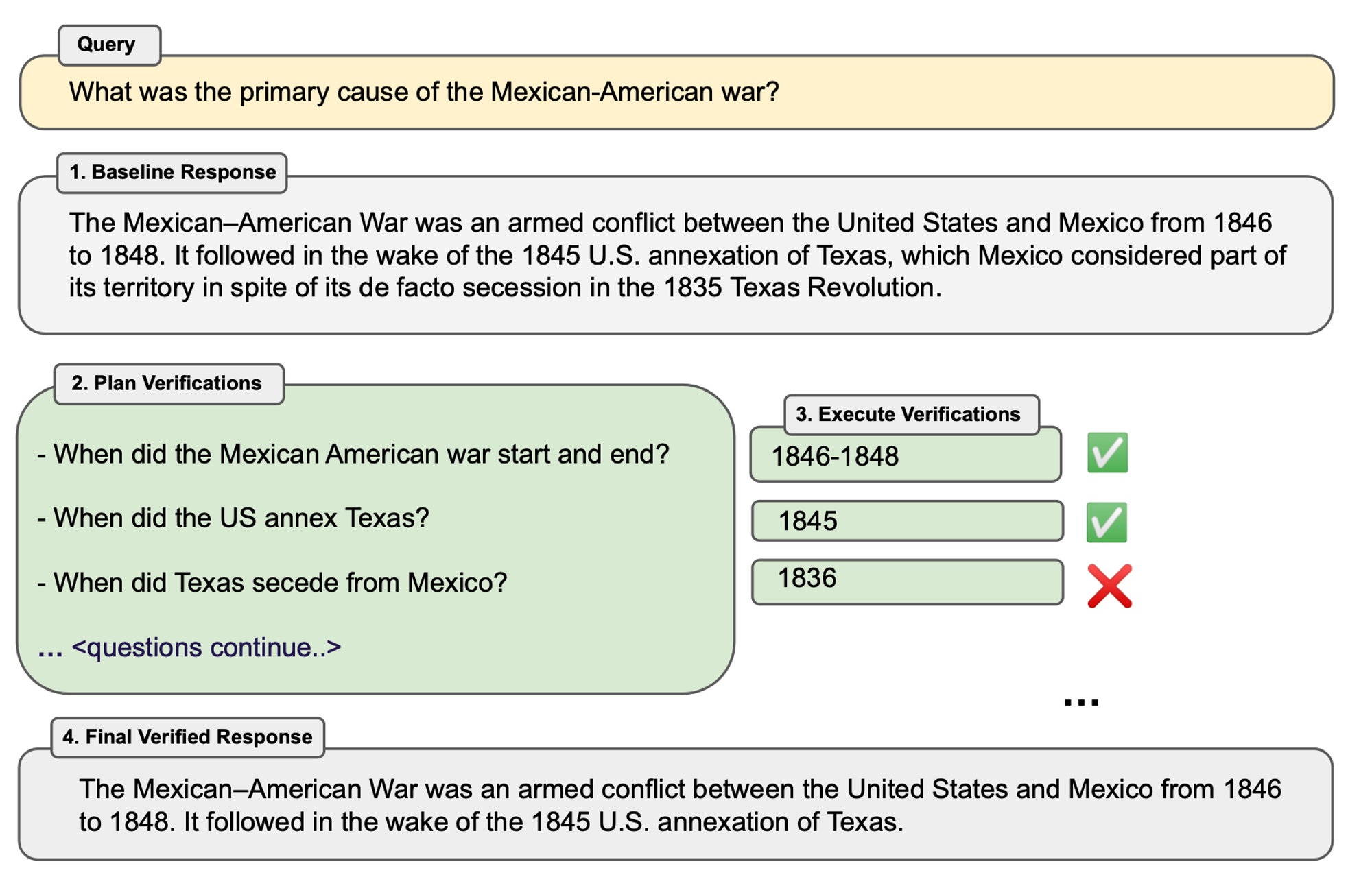
장문 생성에 있어, Chain-of-Verification(CoVe) Factor + Revise 방법이 우리의 장문 생성 실험에서 가장 효과적입니다. CoVe Factor + Revise는 모델이 실행한 검증과 일치하는 사실을 독립적으로 식별(교차 검토)하도록 합니다(그림에서 체크 표시와 엑스 표시로 표시됨). 이 추가 단계에서 우리는 일치하지 않는 사실을 무시하고 일치하는 사실을 사용하여 응답을 재생성하는 것을 목표로 합니다.
8. Prompt Template
아래에 전기 장문 생성 작업을 위한 CoVe의 다양한 단계와 변형에 대한 프롬프트 템플릿을 제공합니다(3장 참조). 다른 작업을 위한 템플릿도 유사하지만, 해당 작업의 몇 가지 예시를 사용합니다.
8.1 Generate Baseline Prompt

🔼 Table 05 : 전기 장문 생성 작업을 위한 3가지 예시를 사용한 몇 가지 예시 프롬프트. 다른 작업들도 동일한 표준 몇 가지 예시 설정을 사용합니다(해당 작업의 3가지 예시를 포함).
8.2 Plan Verifications

🔼 Table 06 : CoVe의 2단계는 검증 질문을 계획하는 것입니다. 전기 작업의 경우 장문 생성을 개별 구절(예: 전기의 문장)로 분할합니다. 이는 과도한 문맥 길이 때문이며, 다른 작업에서는 필요하지 않습니다. 그런 다음 모델은 각 구절에서 관찰된 각 사실에 대해 검증 질문을 생성합니다(구절 하나에 여러 사실이 포함될 수 있습니다).
8.3 Execute Verifications

🔼 Table 07 : CoVe의 3단계에서는 모델이 각 검증 질문에 대한 답변을 생성합니다. 이때도 3가지 예시를 사용합니다.
8.4 General Final Verified Response

🔼 Table 08 : CoVe의 4단계(분할)에서는 모델에게 원래 생성된 내용(전기 작업의 경우 과도한 문맥 길이로 인해 구절, 예: 문장으로 분할됨)과 모델 자체의 검증 단계 결과를 함께 제시합니다. 모델에게 이 정보가 "다른 출처"에서 온 것이라고 알려줍니다. 모델은 두 출처 간에 일치하는 사실을 기반으로 새로운 최종 답변을 종합해야 합니다.
8.5 Factor + Revise : Identify which facts are consistent

🔼 Table 09 : CoVe (Factor + Revise) 변형에서는 8.3절 이후 3단계의 일환으로, 모델이 두 출처 간에 일치하는 사실을 명시적으로 식별하도록 합니다. 그런 다음 일치하는 사실들을 결합할 수 있습니다.
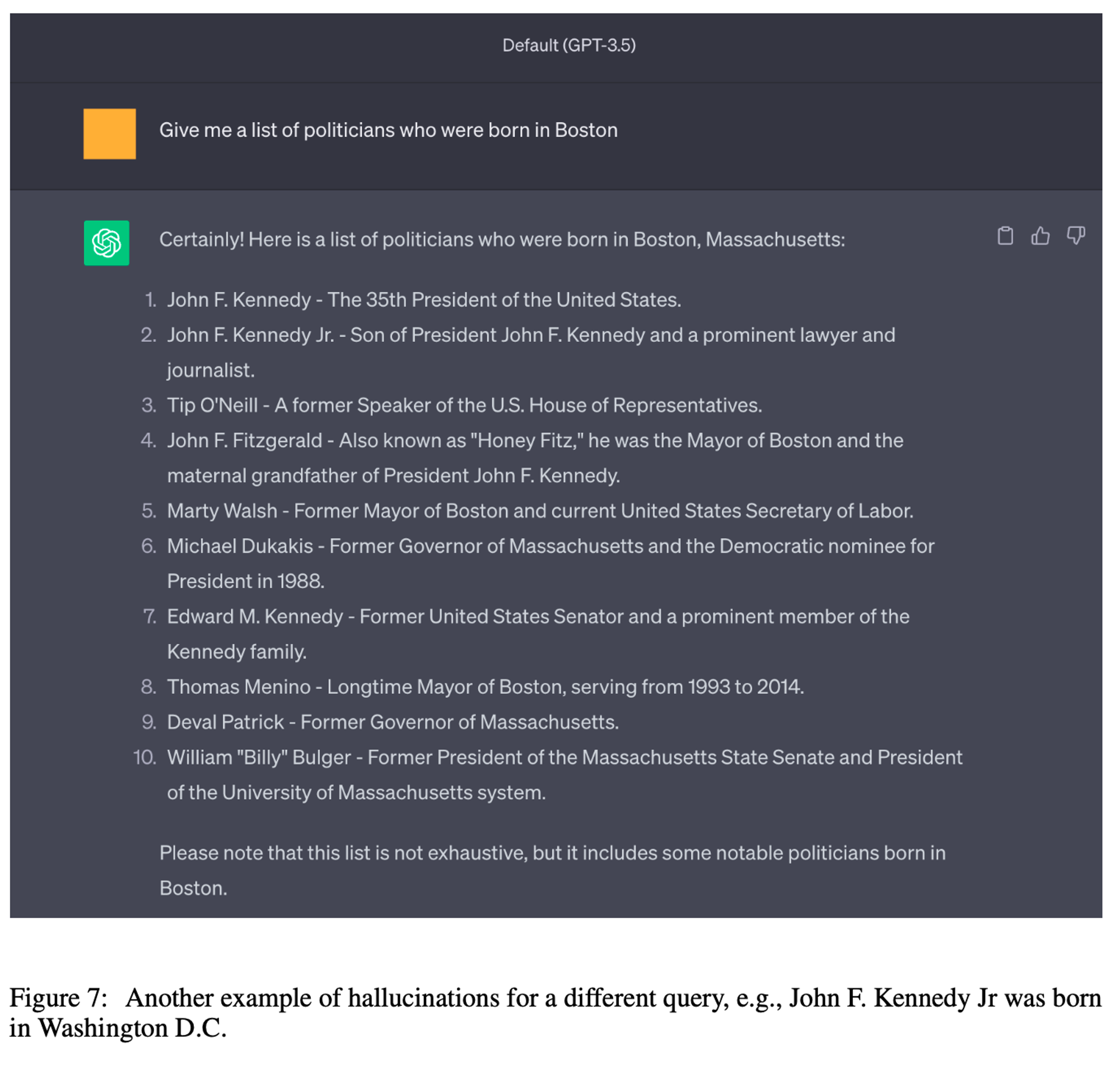
9. ChatGPT Example Screenshot