RAG Survey : A Survey on Retrieval-Augmented Text Generation for Large Language Models (2024)
Paper-Review

Paper Link : https://arxiv.org/pdf/2404.10981
※ 본 포스팅은 논문의 가장 중요한 내용에 대한 리뷰를 정리하여 올리기 때문에 다소 축약되거나 의역된 내용이 많습니다. 참고하세요.Abstract
Retrieval-Augmented Generation (RAG)은 대규모 언어 모델(LLM)의 정적인 한계를 극복하기 위해 검색 방법과 딥러닝 발전을 결합하여 최신 외부 정보를 동적으로 통합할 수 있도록 합니다. 이 방법론은 주로 텍스트 분야에 초점을 맞추어, LLM이 생성하는 그럴듯하지만 잘못된 응답의 문제를 해결하는 비용 효율적인 해결책을 제공합니다. 실제 데이터를 활용하여 LLM의 출력물의 정확성과 신뢰성을 향상시키는 것입니다. RAG가 복잡성이 증가하고 성능에 영향을 미칠 수 있는 여러 개념을 통합함에 따라, 이 논문은 RAG 패러다임을 검색 관점에서 사전 검색(pre-retrieval), 검색(retrieval), 사후 검색(post-retrieval), 생성(generation) 네 가지 범주로 나누어 체계적으로 정리하고 있습니다. 논문에서는 RAG의 진화를 개요하고 주요 연구를 분석하여 이 분야의 발전 과정을 논의합니다. 또한 RAG에 대한 평가 방법을 소개하고, 직면한 문제들을 다루며 미래의 연구 방향을 제안합니다. 이 연구는 체계적인 프레임워크와 범주화를 통해 기존 RAG 연구를 통합하고, 그 기술적 기초를 명확히 하며, LLM의 적응성과 응용 가능성을 확대할 수 있는 잠재력을 강조하고자 합니다.
Ⅰ. Introduction
ChatGPT의 출현은 그 상호작용 능력과 광범위한 응용 덕분에 학계와 산업에 큰 영향을 미쳤으며, 이를 통해 ChatGPT는 주요 인공지능 도구로 자리매김하였습니다 (Laskar et al., 2023; Jahan et al., 2023; Huang and Huang, 2024). ChatGPT의 핵심에는 GPT-4라는 대규모 언어 모델(LLM)이 있으며, 이는 이전 버전에 비해 많은 향상을 이뤄내어 다양한 자연어 처리(NLP) 작업에서 뛰어난 능력을 보여주고 있습니다 (OpenAI et al., 2023; Laskar et al., 2020). 이러한 발전에도 불구하고, 대규모 데이터셋에 의존하는 특성으로 인해 LLM의 채택 과정에서 몇 가지 중요한 문제가 부각되었습니다. 이러한 의존성은 모델이 훈련 이후 새로운 정보를 통합하는 능력을 제한하며, 아래 3가지 주요 문제를 초래합니다.
첫째, 접근성과 적용 가능성을 극대화하기 위해 광범위하고 일반적인 데이터에 초점을 맞추는 것은 전문 분야(=specific domains)에서의 성능을 저하시킵니다.
둘째, 온라인 데이터의 급속한 생성과 데이터 주석 및 모델 훈련에 필요한 막대한 자원은 대규모 언어 모델(LLM)이 최신 상태를 유지하는 것을 방해합니다.
셋째, LLM은 그럴듯하지만 부정확한 응답, 일명 "환각(hallucination)"을 생성할 수 있으며, 이는 사용자를 헷갈리게 할 수 있습니다.
이러한 문제를 해결하는 것은 LLM이 다양한 분야에서 효과적으로 활용되기 위해 중요합니다. 유망한 해결책으로는 검색-증강 생성(Retrieval-Augmented Generation, RAG) 기술의 통합이 있습니다. 이 기술은 모델이 쿼리에 응답하여 외부 데이터를 가져오도록 보완함으로써, 더 정확하고 최신의 출력을 보장합니다. Figure 01은 RAG가 ChatGPT가 초기 훈련 데이터 범위를 넘어 정확한 답변을 제공할 수 있도록 하는 방법을 보여줍니다.
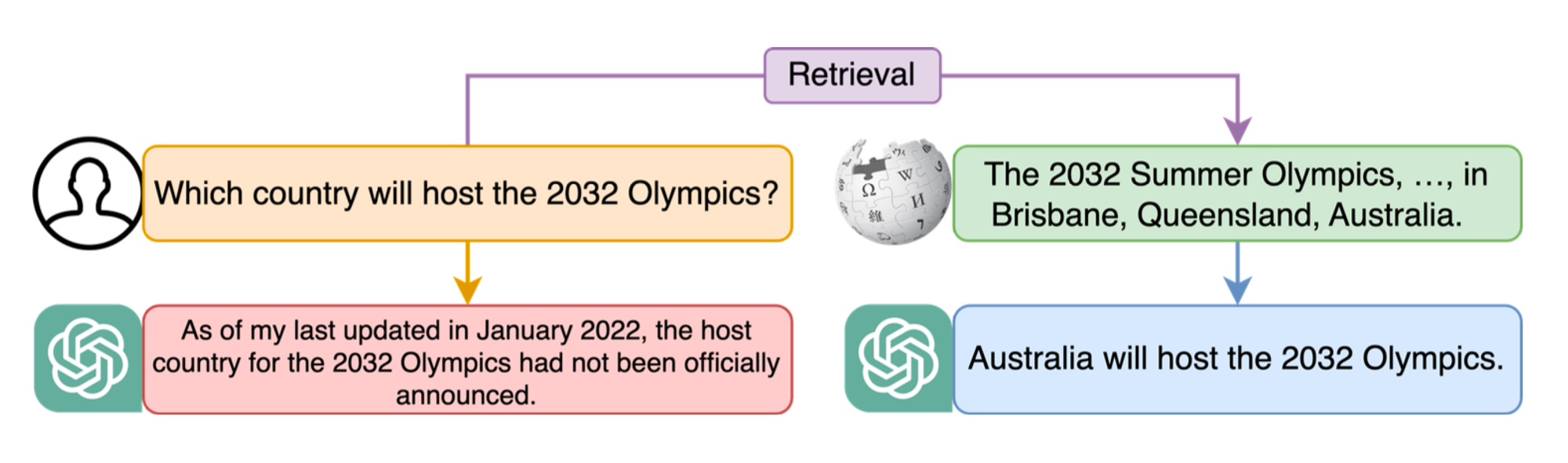
🔼 Figure 01 : RAG의 장점중 한 예시로, ChatGPT는 훈련 데이터 범위를 벗어난 질문을 해결하고 올바른 결과를 생성합니다.
RAG 기술은 2020년 Lewis 등(Lewis et al., 2020b)에 의해 도입된 이후, 특히 ChatGPT의 성공에 영향을 받아 상당한 발전을 이루었습니다. 그러나 RAG의 메커니즘과 후속 연구에서 이루어진 진전에 대한 철저한 분석이 부족하다는 점이 문헌에서 눈에 띄게 나타납니다. 또한, 이 분야는 다양한 연구 초점과 유사한 방법에 대해 모호한 용어를 사용하는 것으로 특징지어져 혼란을 초래하고 있습니다.
이 논문은 RAG에 대한 체계적인 개요를 제공하고 다양한 방법들을 분류하며, 이 연구 분야에 대한 심도 있는 이해를 제시함으로써 이러한 측면을 명확히 하는 것을 목표로 합니다. 이 조사는 주로 RAG의 텍스트적 응용에 초점을 맞추어, 이 분야에서 현재의 연구 노력을 반영할 것입니다.
RAG는 두 가지 주요 질문을 해결하기 위해 검색 방법과 고급 딥러닝을 결합합니다: 관련 정보를 효과적으로 검색하고 정확한 응답을 생성하는 것입니다. RAG의 작업 흐름은 섹션 2에서 설명되며, 방법론을 사전 검색, 검색, 사후 검색, 생성 단계로 분류합니다. 섹션 3에서 6까지는 이 단계 내에서 사용되는 기술들에 대한 심도 있는 분석을 제공합니다. 섹션 7에서는 검토된 연구들에 대한 요약과 함께 사용된 검색기와 생성기를 제시합니다. 섹션 8에서는 RAG에 대한 평가 방법론을 상세히 설명합니다. 섹션 9에서는 텍스트 기반 연구에 중점을 두고 이미지 및 다중 모드 데이터로 확장하여 향후 연구 방향을 탐구합니다. 결론은 섹션 10에 제시됩니다.
이 논문의 기여는 세 가지로 요약할 수 있습니다. 첫째, 이 논문은 RAG 분야를 이해하기 위한 포괄적인 프레임워크를 제공하여 개선이 필요한 영역과 미래 연구를 위한 과제를 식별합니다. 둘째, RAG의 핵심 기술에 대한 상세한 분석을 제공하여, 검색 및 생성 문제를 해결하는 데 있어서의 강점을 조사합니다. 마지막으로, RAG 연구에서 사용되는 평가 방법을 소개하며, 현재의 과제를 강조하고 미래 연구를 위한 유망한 방향을 제시합니다.
2. RAG Framework
환각(hallucinations)은 대규모 언어 모델(LLM)이 최신 정보를 접근하지 못하는 데 주로 기인합니다. 이러한 한계는 모델이 그들의 훈련 데이터셋에 의존하는 것에서 비롯됩니다. RAG는 검색 모델을 통해 외부 소스로부터 최신 정보를 보충하여 LLM의 훈련 데이터를 보완함으로써, 정확한 응답을 생성할 수 있는 해결책을 제안합니다. RAG는 LLM에 대해 일반적으로 필요한 광범위한 훈련 및 미세 조정 과정을 대체할 수 있는 비용 효율적인 대안을 제공합니다. 이는 전통적인 검색 방법이나 사전 훈련된 언어 모델을 통해 최신 정보를 동적으로 통합할 수 있게 하며, 이 새로운 데이터를 직접 LLM에 통합할 필요가 없습니다. 이러한 특징 덕분에 RAG는 유연성과 확장성을 갖추고 있어 다양한 목적을 위한 다양한 대규모 언어 모델(LLM)에서 적용하는데 유용합니다. RAG를 통해 검색된 정보는 실제 데이터를 기반으로 하며, 인간이 작성한 것으로, 이는 생성 과정을 단순화할 뿐만 아니라 생성된 응답의 신뢰성을 높여줍니다. Figure 02는 기본 작업 흐름과 패러다임을 포함한 통합된 RAG 프레임워크를 보여줍니다.
Khandelwal 등(Khandelwal et al., 2020)의 연구는 훈련 데이터셋 자체에서 관련 정보를 접근하는 것이 LLM 성능을 크게 향상시킬 수 있음을 보여주며, RAG의 효과를 강조합니다. 시간이 지나면서, RAG는 보충 정보를 제공하는 수단에서 검색과 생성 구성 요소 간의 여러 상호작용을 가능하게 하는 방식으로 진화해왔습니다. 이는 정보의 정확성을 높이기 위해 여러 차례의 검색을 수행하고, 생성된 출력물의 품질을 반복적으로 개선하는 것을 포함합니다. LangChain과 LlamaIndex와 같은 플랫폼은 RAG 접근 방식을 모듈화하여, 적응성을 높이고 응용 범위를 확장했습니다. 이들 플랫폼은 RAG의 다양한 측면을 다루기 위해 여러 검색 반복부터 반복적인 생성까지 다양한 방법론을 사용하고 있지만, 기본적인 RAG 작업 흐름을 준수하고 있습니다. 이러한 일관성은 이들의 작동 방식을 이해하고 추가 개발의 기회를 식별하는 데 있어 매우 중요합니다.
2.1 Basic RAG Workflow
RAG의 기본 작업 흐름은 외부 소스를 포함하는 인덱스의 생성으로 시작됩니다. 이 인덱스는 특정 쿼리에 기반하여 검색 모델이 관련 정보를 검색하는 기초로 작용합니다. 마지막 단계에서는 생성 모델이 검색된 정보와 쿼리를 결합하여 원하는 출력을 생성합니다.
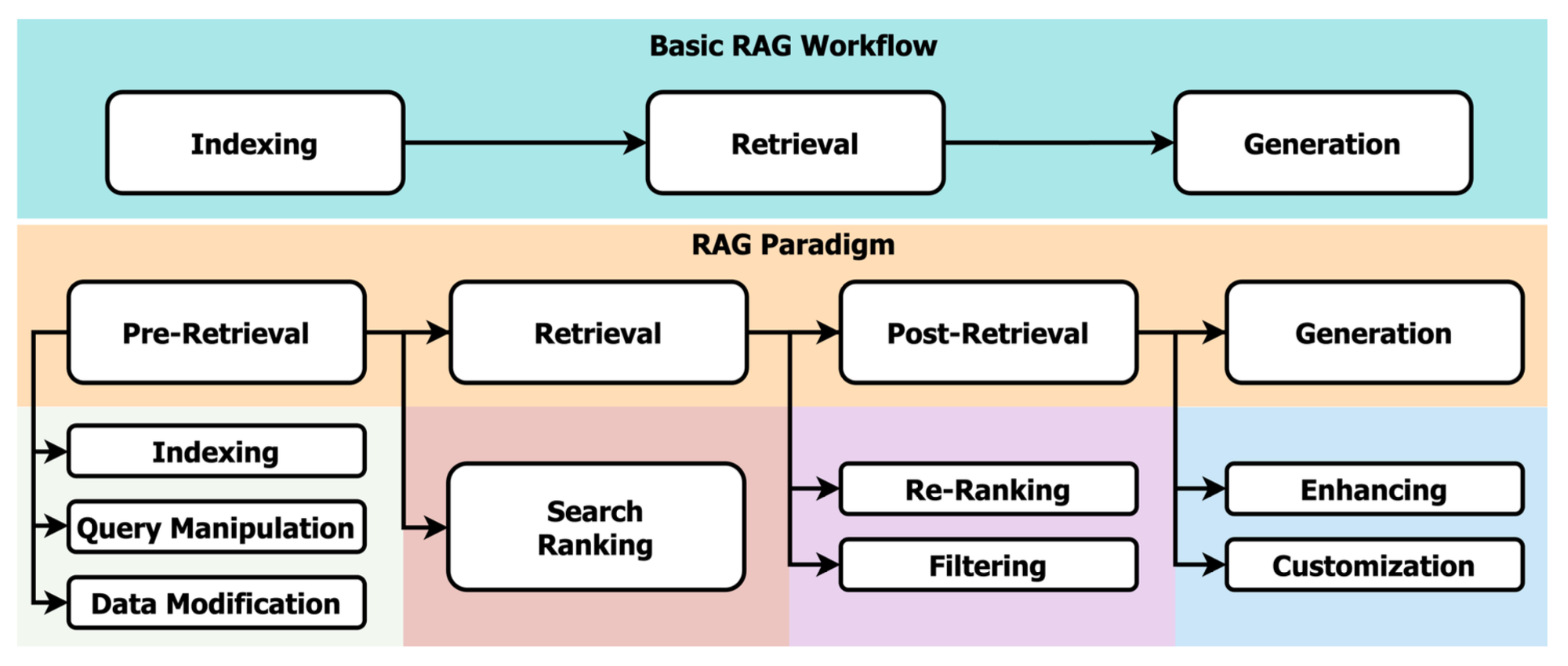
🔼 Figure 02 : 기본 작업 흐름과 패러다임을 포함한 통합 RAG 프레임워크.
2.1.1 Indexing
효율적인 검색은 포괄적인 인덱싱에서 시작되며, 데이터 준비가 핵심입니다. 이 단계는 텍스트를 인덱싱에 적합하도록 하는 텍스트 정규화 과정인 토큰화(=Tokenization), 스테밍(Stemming), 불용어 제거(Removal Stop Words) 등을 포함합니다 (Manning et al., 2008). 그런 다음 텍스트를 문장 또는 단락으로 구성하여 더 집중된 검색을 가능하게 하며, 관련 키워드를 포함한 세그먼트를 정확하게 찾아낼 수 있게 합니다. 딥러닝의 통합은 사전 훈련된 언어 모델을 사용하여 텍스트의 의미론적 벡터 표현을 생성함으로써 인덱싱에 혁신을 가져왔습니다. 이렇게 생성된 벡터는 저장되어 방대한 데이터 컬렉션에서 빠르고 정확한 검색을 가능하게 하여, 검색 효율성을 크게 향상시킵니다.
2.1.2 Retrieval
전통적인 검색 방법, 예를 들어 BM25 알고리즘(Hancock-Beaulieu et al., 1996)은 문서 순위를 매길 때 용어 빈도와 존재에 중점을 두지만, 쿼리의 의미론적 정보를 간과하는 경우가 많습니다. 현재의 전략은 BERT(Devlin et al., 2019)와 같은 사전 훈련된 언어 모델을 활용하여 쿼리의 의미를 보다 효과적으로 파악합니다. 이러한 모델은 동의어와 구문의 구조를 고려하여 검색 정확도를 향상시키며, 의미론적 유사성을 감지하여 문서 순위를 세분화합니다. 이는 일반적으로 문서와 쿼리 간의 벡터 거리를 측정함으로써 이루어지며, 전통적인 검색 지표와 의미론적 이해를 결합하여 사용자 의도와 일치하는 관련 검색 결과를 도출합니다.
2.1.3 Generation
생성 단계는 쿼리와 관련이 있으며 검색된 문서의 정보를 반영하는 텍스트를 생성하는 역할을 맡고 있습니다. 일반적인 방법은 쿼리와 검색된 정보를 결합하여 이를 대규모 언어 모델(LLM)에 입력하여 텍스트를 생성하는 것입니다(Li et al., 2022). 생성된 텍스트가 검색된 내용과의 일치성과 정확성을 보장하는 것은 도전 과제가 되지만, 원본 자료에 충실하면서도 출력물에 창의성을 부여하는 균형을 유지하는 것도 필수적입니다. 생성된 텍스트는 검색된 문서의 정보를 정확하게 전달하고 쿼리의 의도와 일치해야 하며, 동시에 검색된 데이터에 명시적으로 포함되지 않은 새로운 통찰이나 관점을 도입할 수 있는 유연성을 제공해야 합니다.
2.2 RAG Paradigm
RAG 패러다임은 연구를 체계적으로 정리하여 LLM의 성능을 향상시키기 위한 간단하면서도 견고한 프레임워크를 제공합니다. RAG의 핵심은 고품질의 결과를 생성하기 위해 중요한 검색 메커니즘입니다. 따라서 이 패러다임은 검색 관점에서 사전 검색, 검색, 사후 검색, 생성이라는 네 가지 주요 단계로 구성됩니다. 단일 단계 검색과 다중 단계 검색 접근법 모두 반복적인 검색-생성 사이클을 포함하여 이 네 단계 구조를 따릅니다. Figure 03은 RAG의 핵심 기술에 대한 분류 트리입니다.
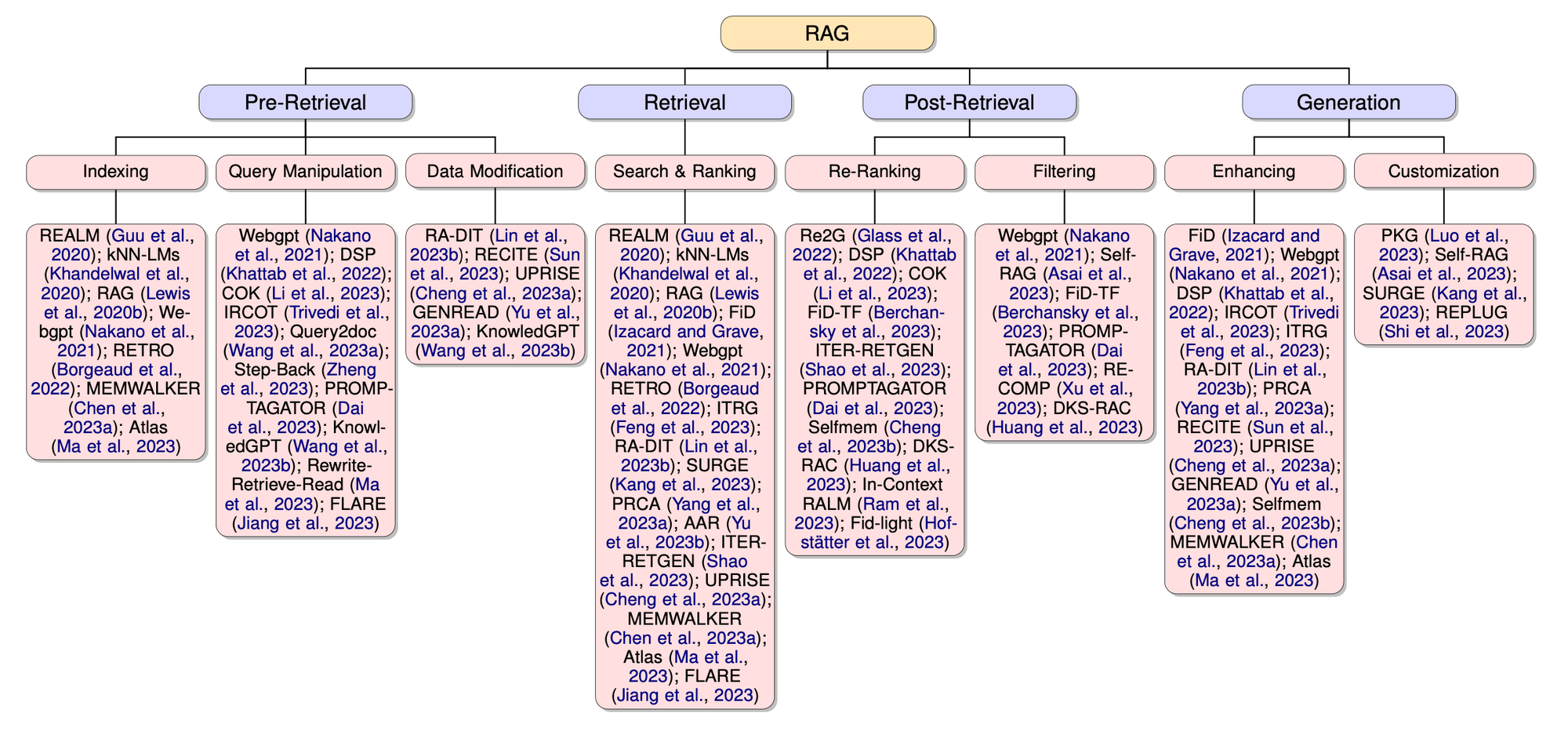
🔼 Figure 03 : RAG의 핵심 기술에 대한 분류 트리
2.2.1 Pre-Retrieval
검색 증강 생성(RAG)의 사전 검색 단계(Pre-Retrieval)는 성공적인 데이터 및 쿼리 준비를 위한 기초를 마련하며, 효율적인 정보 검색을 보장합니다. 이 단계에서는 효과적인 데이터 접근을 준비하기 위한 필수 작업을 포함합니다.
Indexing
이 과정은 인덱싱으로 시작되며, 이는 빠르고 정확한 정보 검색을 가능하게 하는 체계적인 시스템을 구축하는 것입니다. 인덱싱의 구체성은 작업과 데이터 유형에 따라 달라집니다. 예를 들어, 질문-응답 시스템에서는 정답을 정확하게 찾기 위해 문장 수준의 인덱싱이 유용하며, 문서의 주요 개념과 아이디어를 이해하기 위해 문서를 요약할 때는 문서 수준의 인덱싱이 더 적합합니다.
Query Manipulation
인덱싱 이후에는 사용자 쿼리를 인덱싱된 데이터와 더 잘 맞추기 위해 쿼리 조작이 수행됩니다. 이 과정에는 쿼리를 사용자 의도에 더 가깝게 재작성하는 쿼리 재구성(Jansen et al., 2009; Yu et al., 2020), 동의어나 관련 용어를 통해 더 관련성 있는 결과를 얻기 위해 쿼리를 확장하는 쿼리 확장(Huang et al., 2013), 그리고 쿼리 매칭의 일관성을 위해 철자나 용어의 차이를 해결하는 쿼리 정규화가 포함됩니다.
Data Modification
데이터 수정도 검색 효율성을 향상하는 데 중요합니다. 이 단계에는 결과의 품질을 개선하기 위해 불필요하거나 중복된 정보를 제거하는 전처리 기법과 검색된 콘텐츠의 관련성과 다양성을 높이기 위해 메타데이터와 같은 추가 정보를 데이터에 보강하는 작업이 포함됩니다 (Bevilacqua et al., 2022a).
2.2.2 Retrieval
Search & Ranking
검색 단계는 탐색과 순위 매기기의 조합입니다. 이는 데이터셋에서 문서를 선택하고 우선순위를 매겨서 생성 모델의 출력 품질을 향상시키는 데 중점을 둡니다. 이 단계에서는 검색 알고리즘을 사용하여 인덱싱된 데이터를 탐색하고 사용자의 쿼리와 일치하는 문서를 찾습니다. 관련 문서를 식별한 후, 이 문서들을 쿼리와의 관련성에 따라 정렬하는 초기 순위 매기기 과정이 시작됩니다.
2.2.3 Post-Retrieval
사후 검색 단계는 처음 검색된 문서들을 정제하여 텍스트 생성의 품질을 향상시키는 역할을 합니다. 이 단계는 재순위 매기기와 필터링으로 구성되며, 각각 최종 생성 작업을 위한 문서 선택을 최적화하는 것을 목표로 합니다.
Re-Ranking
재순위 매기기 단계에서는 이전에 검색된 문서들을 재평가하고, 점수를 매기며, 재구성합니다. 목표는 쿼리와 가장 관련성 높은 문서를 더 정확하게 강조하고, 덜 관련성 있는 문서의 중요성을 낮추는 것입니다. 이 단계에서는 정밀도를 높이기 위해 추가적인 지표와 외부 지식 소스를 통합합니다. 이와 같은 맥락에서, 효율성은 낮지만 정확도가 높은 사전 훈련된 모델을 후보 문서 집합이 제한된 경우 효과적으로 사용할 수 있습니다 (Huang and Hu, 2009).
Filtering
필터링은 지정된 품질 또는 관련성 기준을 충족하지 못하는 문서를 제거하는 것을 목표로 합니다. 이는 특정 관련성 수준 이하의 문서를 제외하기 위해 최소 관련성 점수 임계값을 설정하는 등의 여러 접근 방식을 통해 수행될 수 있습니다. 또한, 사용자 피드백이나 이전 관련성 평가를 사용하여 필터링 과정을 조정함으로써, 텍스트 생성에 가장 관련성이 높은 문서만 유지되도록 보장합니다 (Khattab and Zaharia, 2020; Huang and Huang, 2023).
2.2.4 Generation
생성 단계는 RAG 과정의 중요한 구성 요소로, 검색된 정보를 활용하여 생성된 응답의 품질을 향상시키는 역할을 합니다. 이 단계는 가독성 있고, 흥미롭고, 유익한 콘텐츠를 생성하기 위한 여러 하위 단계를 포함합니다.
Enhancing
생성 단계의 핵심은 향상 단계이며, 이 단계의 목적은 검색된 정보와 사용자의 쿼리를 결합하여 일관되고 관련성 있는 응답을 생성하는 것입니다. 여기에는 검색된 콘텐츠에 추가 세부 사항을 더해 이를 풍부하게 만드는 과정이 포함됩니다. 출력물의 품질을 향상시키기 위해 재구성 및 재구성을 통해 명확성, 일관성, 스타일적인 매력을 높이는 방법에 집중합니다. 다양한 출처의 정보를 결합하여 포괄적인 관점을 제공하고, 콘텐츠의 정확성과 관련성을 보장하기 위해 검증을 실시합니다.
Customization
맞춤화는 선택적인 단계로, 사용자의 특정 선호도나 요청의 맥락에 맞게 콘텐츠를 조정하는 것을 포함합니다. 이 맞춤화에는 콘텐츠를 목표 청중의 요구에 맞추거나 제공될 형식에 적합하도록 조정하고, 정보의 본질을 간결하게 전달하기 위해 내용을 요약하는 것이 포함됩니다. 이 과정에는 주요 요점이나 논점을 강조하는 요약이나 개요를 작성하여 출력물이 유익하고 간결하게 되도록 하는 것도 포함됩니다.
3. Pre-Retrieval
3.1 Indexing
k-최근접 이웃(kNN) 알고리즘을 사전 훈련된 신경망 언어 모델(LM)과 통합한 사례인 kNN-LM(Khandelwal et al., 2020)은 언어 모델링에서 중요한 진전을 나타냅니다. 이 방법은 텍스트 모음에서 생성된 데이터스토어를 사용하여 추가 훈련 없이도 문맥적으로 관련 있는 예시를 동적으로 검색하여 당혹도(perplexity)를 개선합니다.
FAISS(Johnson et al., 2021)는 그 효율성으로 인해 인덱싱 목적으로 많은 연구에서 채택되었습니다(Khandelwal et al., 2020; Lewis et al., 2020b; Khattab et al., 2022). 일부 연구에서는 Hierarchical Navigable Small World (HNSW) 근사법(Malkov and Yashunin, 2020)과 같은 향상된 기법을 통합하여 더 빠른 검색을 달성하고 있습니다(Lewis et al., 2020b). 또한, WebGPT(Nakano et al., 2021)에서 설명된 실제 사용자 검색 기록을 기반으로 인덱싱하기 위해 Bing API 3을 사용하는 대체 도구와 같은 다양한 인덱싱 기법도 조사되고 있습니다.
또한, MEMWALKER (Chen et al., 2023a)는 입력 텍스트로부터 메모리 트리를 생성하여 대규모 언어 모델(LLM)에서 문맥 창 크기의 한계를 극복하는 혁신적인 방법을 도입합니다. 이 트리는 텍스트를 먼저 작은 조각으로 나눈 다음, 이러한 세그먼트를 요약 노드의 계층적 구조로 요약하여 대량의 정보를 효율적으로 인덱싱하고 관리할 수 있도록 형성됩니다.
3.2 Query Manipulation
FiD(Izacard and Grave, 2021), COK(Li et al., 2023), Query2doc(Wang et al., 2023a)와 같은 연구는 더 관련성 있는 검색 결과를 얻기 위해 새로운 쿼리를 생성하거나 기존 쿼리를 정제하는 것의 중요성을 강조합니다. 이러한 연구들은 구조화된 데이터든 비구조화된 데이터든 다양한 지식 소스에 맞추어 쿼리를 조정하고 여러 문단에서 효율적으로 증거를 수집하는 필요성을 강조합니다. 의사 문서를 생성하여 쿼리를 강화하는 기법들은 다양한 정보 검색 데이터셋에서 검색 성능을 향상시키는 것으로 나타났습니다.
Step-Back(Zheng et al., 2023)와 PROMPTAGATOR(Dai et al., 2023)에서는 쿼리 조작에 대한 추가 탐구가 이루어졌습니다. 이들은 고차원 개념을 추상화하거나, 프롬프트 기반 쿼리 생성을 위해 대규모 언어 모델(LLM)을 활용하는 데 중점을 둡니다. 이러한 전략은 쿼리를 더 일반화된 버전으로 재구성하거나, 제한된 예시에서 작업에 특화된 쿼리를 작성함으로써 검색 시스템의 기능과 쿼리를 더 잘 맞추려고 합니다. 이러한 방법론은 쿼리와 인덱싱된 데이터 간의 일관성을 높여 더 관련성 있고 통찰력 있는 정보를 검색하는 데 도움을 줍니다.
게다가, KnowledGPT(Wang et al., 2023b)와 Rewrite-Retrieve-Read(Ma et al., 2023)는 "사고의 프로그램" 프롬프트와 혁신적인 쿼리 재작성 기법을 통해 쿼리 조작에 접근하는 방법을 소개합니다. KnowledGPT는 사용자 쿼리를 구조화된 검색 명령어로 변환하여 지식 베이스와 상호작용할 수 있는 코드를 생성하는 혁신적인 방법을 도입합니다. 반면에, Rewrite-Retrieve-Read는 쿼리 재구성을 위해 훈련 가능한 간결한 언어 모델을 사용하여, 사용자 의도와 맥락을 더 효과적으로 반영하도록 조정합니다.
마지막으로, FLARE(Jiang et al., 2023)는 쿼리 작성에 있어 신뢰도를 기반으로 한 전략을 제시합니다. 이는 정보 요구를 정확하게 반영하는 쿼리를 만드는 데 중점을 둡니다. 이 방법은 생성된 문장이나 그 일부를 검색 쿼리의 기초로 사용하는 것을 포함합니다. 이 접근 방식은 문장을 직접 사용하거나 신뢰도가 낮은 토큰을 제외하거나 명시적인 질문을 작성함으로써 검색 프로세스의 효율성을 높이고, 검색된 정보가 생성 과정의 요구 사항을 충실하게 만족하도록 하는 것을 목표로 합니다.
3.3 Data Modification
RA-DIT(Lin et al., 2023b)와 RECITE(Sun et al., 2023)는 내부 데이터 수정에 의한 향상을 강조합니다. RA-DIT는 LLM(대규모 언어 모델)과 검색기를 위한 데이터셋을 미세 조정하는 것을 구분하여, LLM의 문맥 이해력과 쿼리에 맞추는 검색기의 능력을 강화하는 것을 목표로 합니다. 반면에 RECITE는 단락 힌트와 합성된 질문-단락 쌍을 활용하여, 생성된 인용문과 응답의 다양성과 관련성을 높입니다. 이러한 접근법은 모델의 지식 기반을 확장하고 응답의 정확성을 향상시키는 것을 목표로 합니다.
UPRISE(Cheng et al., 2023a)와 GENREAD(Yu et al., 2023a)는 외부 데이터의 정제를 목표로 합니다. UPRISE는 원시 작업 데이터를 구조화된 형식으로 변환하고, 검색 결과를 향상시키기 위해 프롬프트 선택을 정제합니다. 반면에 GENREAD에서 사용된 클러스터링 기반 프롬프트 방법은 질문에서 문서를 생성하고 이를 클러스터링하여 관련성이 없는 데이터를 제거하고, 다양한 문맥적 통찰로 입력을 풍부하게 합니다. 이 기법은 생성 모델의 성능을 개선하기 위해 보다 풍부한 정보 세트를 제공하는 것을 목표로 합니다.
게다가, KnowledGPT(Wang et al., 2023b)는 엔티티 연결을 통해 원시 텍스트 데이터를 구조화되고 의미가 풍부한 정보로 확장하는 데 중점을 둡니다. 이 확장 과정은 데이터의 구조를 더 일관성 있게 만들어 쿼리에 더 적합하게 할 뿐만 아니라 모델의 검색 효율성도 향상시킵니다. 정밀하게 연결된 지식을 활용하여 모델의 이해와 관련 응답 생성 능력을 강화함으로써 전반적인 성능을 개선합니다.
4. Retrieval
4.1 Search & Ranking
Atlas(Izacard et al., 2023)는 Attention Distillation과 Perplexity Distillation을 포함한 소수의 예시만을 사용하여 학습하는 방법을 조사하여 검색기가 더 관련성 높은 문서를 검색하도록 유도합니다. IRCOT(Trivedi et al., 2023)은 검색의 효과를 높이기 위해 검색과 추론을 통합합니다. SURGE(Kang et al., 2023)는 지식 그래프에서 관련 서브그래프를 추출하기 위해 서브그래프 검색기를 사용하며, AAR(Yu et al., 2023b)은 대규모 언어 모델(LLM)이 관련 문서를 검색하는 데 도움이 되도록 검색 선호도를 수정합니다.
PRCA(Yang et al., 2023a)는 도메인에 특화된 추상적 요약을 사용하여 문서에서 관련성과 문맥이 풍부한 정보를 추출하는 데 중점을 두고, 감독 학습 전략을 통해 정확한 쿼리 응답에 중요한 콘텐츠를 우선시합니다. 한편, MEMWALKER(Chen et al., 2023a)는 구성된 메모리 트리에서 내부 검색 및 순위 매기기 메커니즘을 활용하여 긴 문맥 질문에 대한 답변을 위해 적절한 정보를 식별합니다. 또한, FLARE(Jiang et al., 2023)의 신뢰 기반 능동 검색 접근법은 생성된 문장의 신뢰도 수준에 따라 동적으로 정보 검색을 활성화하며, 낮은 신뢰도의 토큰이 외부 지식이 필요함을 나타낸다는 통찰을 이용합니다.
5. Post-Retrieval
5.1 Re-Ranking
Re2G(Glass et al., 2022)은 쿼리와 단락을 동시에 분석하기 위해 BERT 트랜스포머를 활용하는 시퀀스 쌍 분류 접근법을 도입하여 재순위를 매깁니다. 이 상호작용 모델은 시퀀스 간의 교차 주의를 사용하여 초기 검색 단계에서 일반적으로 사용되는 표현 모델과 대조를 이룹니다. PROMPTAGATOR(Dai et al., 2023) 또한 재점수를 매기기 위해 교차 주의 모델을 사용합니다. "스스로를 들어올려라" 전략은 풀에서 최상의 후보를 반복적으로 선택하여 추가 생성 라운드를 수행하고, 자가 생성 콘텐츠를 통해 콘텐츠의 품질을 점진적으로 개선합니다.
재순위 매기기는 In-Context RALM(Ram et al., 2023)에서도 중요한 초점입니다. 두 가지 재순위 매기기 접근법이 탐구되었습니다: 언어 모델을 사용한 제로샷 재순위 매기기와 훈련된 모델을 통한 예측적 재순위 매기기. 이 단계는 언어 모델 성능 향상을 위해 문서의 예상 유용성에 따라 문서 선택을 정제하는 것을 목표로 합니다. 특히 ITER-RETGEN(Shao et al., 2023)은 재순위 매기기에서 밀집 검색기로 지식 증류를 활용하여, LLM 출력에서 관련성 신호를 기반으로 검색 작업을 미세 조정합니다. 이 검색 모델의 최적화는 쿼리의 미묘한 차이를 더 정확하게 포착하여 문서 선택을 개선하는 것을 목표로 합니다.
DKS-RAC(Huang et al., 2023)는 답변과 검색된 단락 간의 지식을 시퀀스 수준에서 일치시키기 위해 밀집 지식 유사성(DKS)을 도입합니다. 이 접근법은 지식 유사성을 기반으로 단락 선택에 직접적인 영향을 미치기 때문에 재순위 매기기 범주에 속하며, 쿼리와 문서 간의 일치를 정교하게 합니다.
FiD-light(Hofstätter et al., 2023)는 순차적인 생성 과정에서 소스 포인터를 사용하여 순위 순서를 최적화하는 목록형 자기회귀 재순위 매기기 방법을 도입합니다. 이 방법은 생성된 텍스트와 소스 단락 간의 연계를 유지하여 더 구조화된 생성 과정을 가능하게 합니다. 모델의 출력물 내에 텍스트 인용을 관련 정보 소스로서 포인터로 통합함으로써, 이 접근법은 체계적인 검색 및 생성 과정을 촉진하여 생성된 콘텐츠의 전체적인 일관성과 관련성을 향상시킵니다.
5.2 Filtering
COK(Li et al., 2023)는 검색된 지식을 통해 근거를 반복적으로 정제하는 Progressive Rationale Correction 기법을 제시합니다. 이 방법은 지속적인 최적화 과정을 구성하여 콘텐츠 생성에 사용되는 정보의 관련성과 품질을 크게 향상시킵니다. Self-RAG(Asai et al., 2023)는 불필요한 콘텐츠를 효율적으로 걸러내기 위한 자기 성찰 메커니즘을 도입합니다. 이 접근법은 비판적 토큰을 사용하여 검색된 단락의 관련성, 지원성, 유용성을 평가함으로써 콘텐츠 생성 과정에 오직 고품질 정보만 통합되도록 보장합니다.
또한, FiD-TF(Berchansky et al., 2023)와 RECOMP(Xu et al., 2023)는 검색된 문서에서 관련 없거나 중복된 토큰과 정보를 제거하는 데 중점을 둡니다. FiD-TF는 불필요한 토큰을 식별하고 제거하기 위해 동적 메커니즘을 사용하여 정보 처리의 효율성을 향상시킵니다. 반면에 RECOMP는 문서를 간결한 요약으로 압축하여 생성 과정에서 가장 관련성 있는 콘텐츠만을 선택하는 데 초점을 맞춥니다. 이러한 방법들은 오직 관련 있고 지원적인 정보만 사용하도록 하여 콘텐츠 생성 작업 흐름을 간소화함으로써, 생성된 콘텐츠의 전체적인 품질과 관련성을 향상시킵니다.
6. Generation
6.1 Enhancing
DSP(Khattab et al., 2022)는 여러 검색 쿼리를 생성하여 다양한 단락에서 수집된 정보를 바탕으로 질문을 요약하고 답변하는 프레임워크를 소개합니다. 이 프레임워크는 다양한 검색 목록에서 단락의 누적 확률 점수를 계산하기 위해 CombSUM(Fox and Shaw, 1994)을 사용하여 여러 출처로부터 포괄적인 응답을 작성할 수 있도록 합니다.
PRCA(Yang et al., 2023a)는 보상 기반 단계(Reward-Driven Stage)를 개요로 설명하며, 이 단계에서는 생성기의 피드백을 바탕으로 정제된 문맥이 세분화됩니다. 이 단계에서는 강화 학습을 활용하여 관련 문맥 제공에 대해 받은 보상에 따라 PRCA의 매개변수를 조정합니다. 목표는 추출된 문맥을 생성기의 특정 요구 사항에 맞게 미세 조정하여 생성 과정을 최적화하는 것입니다.
REPLUG(Shi et al., 2023)은 블랙박스 언어 모델(LM)이 최종 예측을 수행하기 전에 검색된 문서를 입력 문맥에 앞서 추가하는 방법을 제안합니다. 이 방법은 검색된 문서를 병렬로 인코딩하여 언어 모델의 문맥 길이 한계를 극복하고, 더 많은 계산 자원을 할당함으로써 정확성을 향상시키는 앙상블 전략을 도입합니다. 이 접근 방식은 언어 모델이 더 넓은 범위의 관련 정보를 접근할 수 있도록 보장하여 생성 과정을 개선합니다.
RECITE(Sun et al., 2023)은 여러 번의 답변을 독립적으로 생성한 후, 다수결 시스템을 사용하여 가장 적합한 답변을 결정하는 자기 일관성 기법을 구현합니다. 이 방법은 답변의 신뢰성과 정확성을 높여 출력물의 품질과 신뢰성을 향상시키도록 설계되었습니다.
6.2 Customization
PKG 프레임워크는 (Luo et al., 2023)에서 도입된 것으로, 언어 모델(LM)의 출력을 맞춤화하는 접근 방식을 나타냅니다. PKG는 사전 훈련된 모델을 사용하여 내부적으로 배경 지식을 생성함으로써 전통적인 외부 검색 과정을 불필요하게 만듭니다. 이 방법은 도메인 또는 작업별 지식을 생성 단계에 직접 통합하여 주어진 맥락이나 요구 사항에 맞춤화된 응답을 생성하는 언어 모델의 능력을 크게 향상시킵니다.
Self-RAG(Asai et al., 2023)은 맞춤형 디코딩 알고리즘 내에 성찰 토큰을 통합하는 전략을 제공합니다. 이 기술은 특정 작업에 따라 모델의 검색 및 생성 행동을 동적으로 조정할 수 있어, 보다 다양한 응답 생성을 용이하게 합니다. 요구 사항에 따라 이 접근 방식은 정확성 또는 창의성을 위해 조정될 수 있으며, 다양한 필요를 충족하는 출력을 생성할 수 있는 유연성을 제공합니다.
SURGE(Kang et al., 2023)는 그래프-텍스트 대조 학습을 적용하여 맞춤화를 달성합니다. 이 방법은 생성된 대화 응답이 검색된 서브그래프에 포함된 지식과 긴밀하게 일치하도록 보장하여, 구체적이고 관련성이 있으며 대화 맥락에 깊이 뿌리박힌 응답을 생성합니다. 검색된 지식과 생성된 텍스트 간의 일관성을 유지함으로써, SURGE는 서브그래프의 상세한 지식을 정확하게 반영하는 출력을 생성할 수 있으며, 응답의 관련성과 구체성을 높입니다.
7. Comparison of RAG
7.1 The Comprehensive Summary of RAG
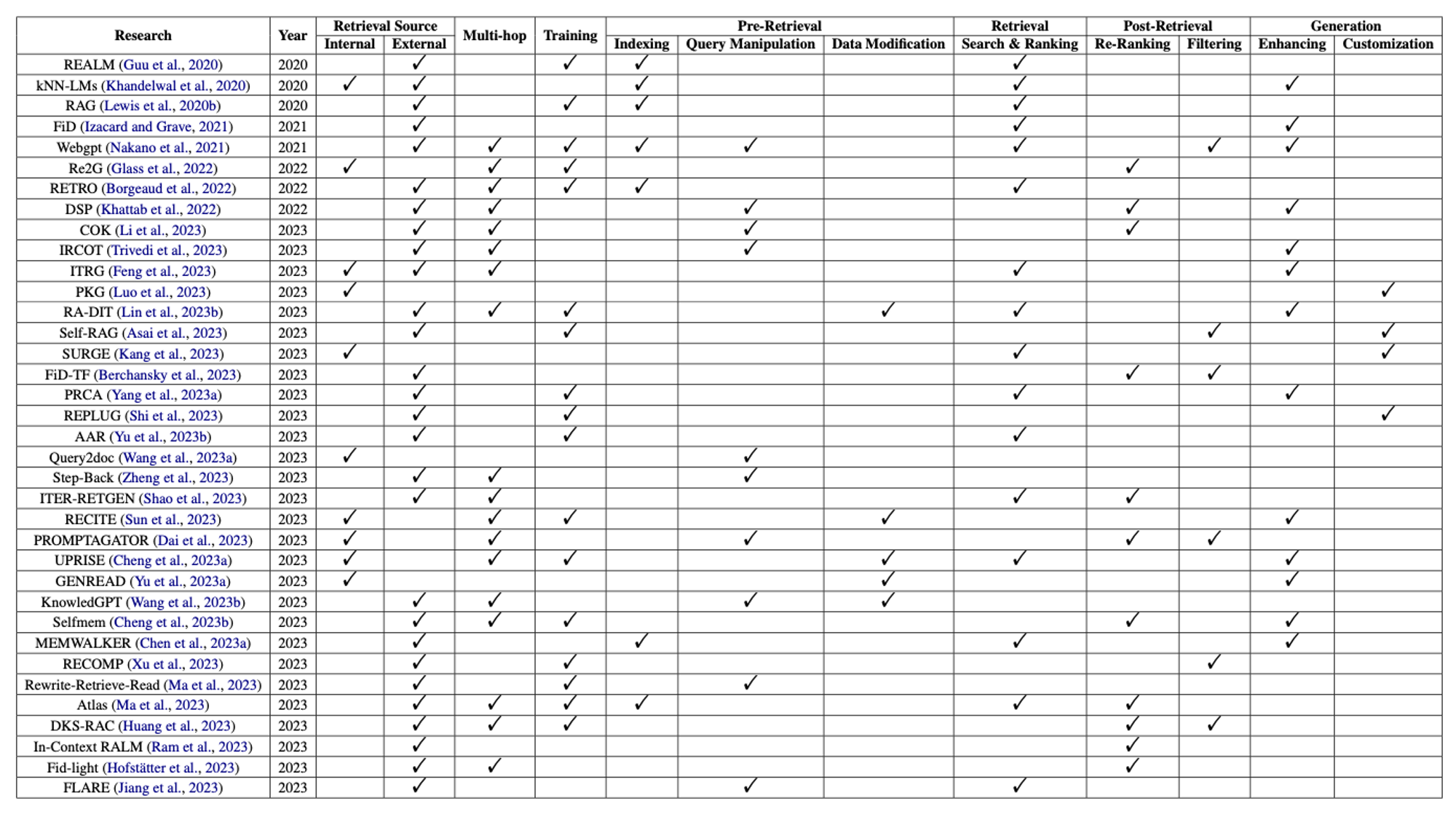
🔼 Table 01 : RAG 연구에 대한 종합적인 요약입니다. “Multi-hop” 열의 체크표시는 연구가 다중 검색 라운드를 포함한다는 것을 의미합니다. 마찬가지로, “Training” 열의 체크표시는 연구가 훈련 단계를 포함했다는 것을 나타냅니다. 여기서 "Training"은 초기 모델 훈련과 미세 조정 과정을 모두 포함한다는 점에 유의해야 합니다.
Table 01은 이 논문에서 논의된 RAG 연구들에 대한 상세한 분석을 제시합니다. 이 분석에 따르면, 대부분의 연구에서 LLM(대규모 언어 모델)의 콘텐츠를 풍부하게 하기 위해 외부 데이터 소스를 사용한 것으로 나타났습니다. 단일 단계 검색보다 다중 단계 검색을 선호하는 경향이 있었으며, 이는 반복적인 검색 라운드가 일반적으로 더 우수한 결과를 도출한다는 것을 의미합니다. 즉, 대부분의 방법은 고품질의 후보 문서를 확보하기 위해 밀집 검색을 사용합니다. 사전 검색 단계에서 데이터셋을 수정하는 것과 비교하여, 검색 성능을 개선하기 위해 쿼리를 조작하는 것에 초점을 맞춘 연구가 더 많습니다. 또한, 검색 단계를 최적화하는 것에 상당한 중점을 두고 있으며, 이는 연구에서 중요한 역할을 하고 있음을 강조합니다. 그러나 생성 단계에서의 맞춤화에 집중하는 연구는 부족한 것으로 보이며, 이는 미래 탐구의 잠재적인 영역으로 지적되고 있습니다. 전반적으로, RAG의 목표는 LLM의 응답 품질을 향상시키는 것이지만, 검색 측면을 개선하는 데 더 많은 노력이 기울여져 왔습니다.
7.2 Retriever and Generator
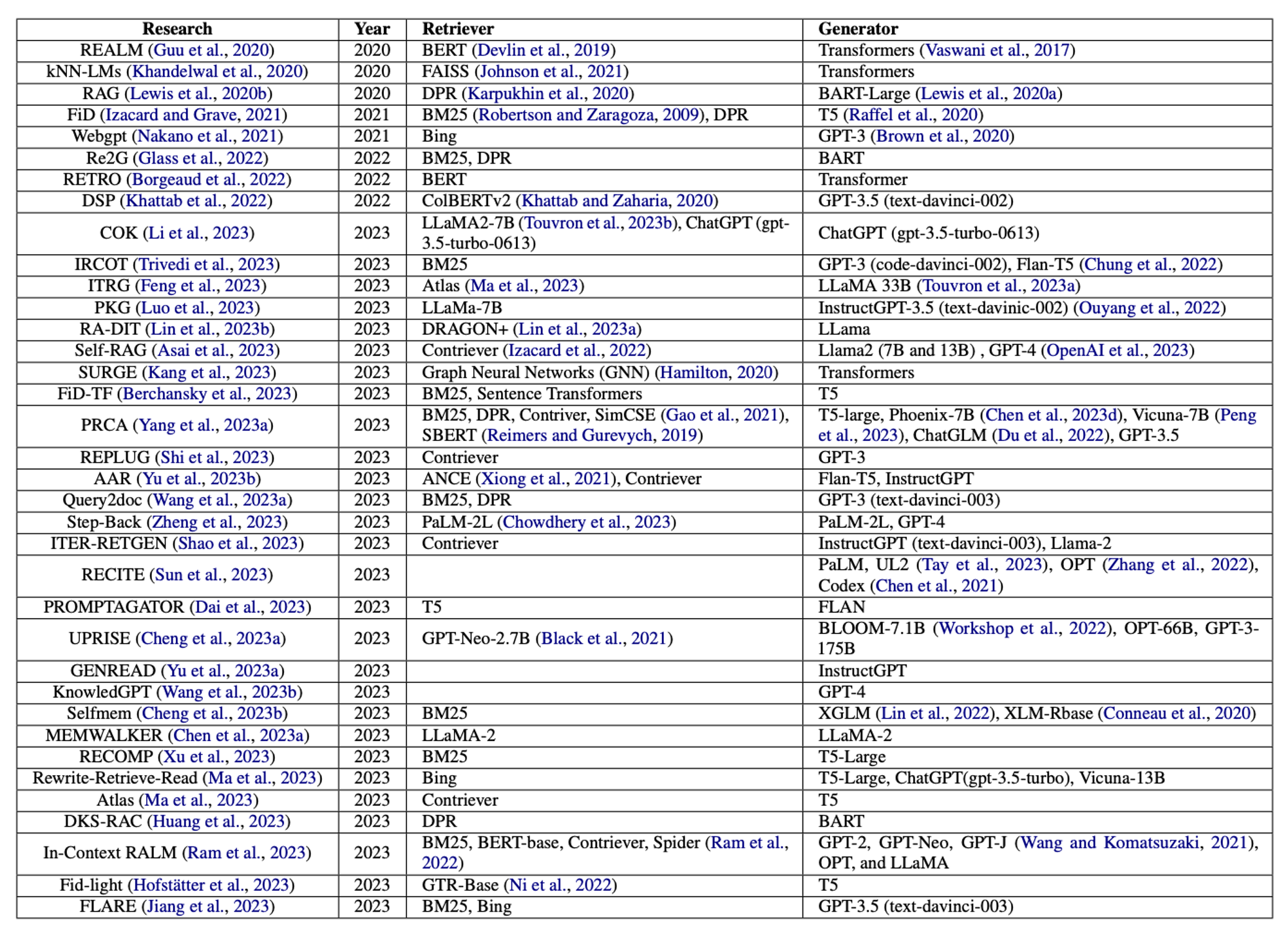
🔼 Table 02 : 검색기와 생성기의 요약입니다. 이 연구들에서 명시적으로 언급된 검색 모델과 사전 훈련된 언어 모델이 기록되었습니다.
RAG에서는 검색기와 생성기가 주요 구성 요소입니다. Table 02는 이 논문에서 논의된 연구들에서 사용된 검색기와 생성기를 요약합니다. 표에서 알 수 있듯이, 대부분의 생성기가 고급 언어 모델을 사용하는 반면, 상당수의 검색기는 여전히 그 효율성 때문에 전통적인 BM25를 사용하고 있습니다. 검색 방법은 RAG에서 중요한 측면이며, 효율성을 저해하지 않으면서 검색 성능을 향상시키는 방법을 모색하는 것이 중요합니다. 마찬가지로, 강력한 언어 모델(LLM)인 LLaMA2, GPT-3.5, 또는 GPT-4와 같은 생성기를 채택한 연구는 많지 않습니다. T5와 같은 언어 모델은 여전히 인기가 있지만, BERT와 트랜스포머와 같은 기본 모델은 2023년에 거의 사용되지 않았습니다. 생성기와 비교했을 때, 정보 검색 기반 LLM이 검색기에 많이 사용되지 않은 것이 분명하며, 이는 미래에 그러한 모델을 개발할 수 있는 유망한 방향을 시사합니다.
8. Evaluation in RAG
외부 지식을 활용하여 대규모 언어 모델(LM)이 더 정확하고 관련성 있으며 강력한 응답을 생성하는 효과를 이해하기 위해, RAG 시스템의 평가가 중요한 연구 분야로 부각되었습니다. 대화 기반 상호작용의 인기가 높아짐에 따라, 최근 연구는 이러한 다운스트림 작업에서 RAG 모델의 성능을 평가하는 데 중점을 두고 있으며, 이를 위해 정확 일치(Exact Match, EM)와 F1 점수와 같은 확립된 지표를 사용하고 있습니다. 또한, 이 목적을 위해 TriviaQA(Joshi et al., 2017), HotpotQA(Yang et al., 2018), FEVER(Thorne et al., 2018), Natural Questions(Kwiatkowski et al., 2019), Wizard of Wikipedia(Dinan et al., 2019), T-REX(ElSahar et al., 2018)와 같은 다양한 데이터셋이 활용되었습니다.
그러나 다운스트림 작업의 관점에서만 평가하는 것은 RAG 개발의 변화하는 요구를 충분히 반영하지 못합니다. 최근 연구에서는 생성된 텍스트의 품질, 검색된 문서의 관련성, 그리고 모델의 허위 정보에 대한 내성을 포함한 여러 차원에서 이 시스템을 평가하는 다양한 프레임워크와 벤치마크를 도입했습니다. 이러한 평가들은 노이즈 내성, 부정적 프롬프트, 정보 통합, 그리고 반사실적 내성과 같은 특정 능력을 평가하는 데 중점을 두며, 실제 응용에서 RAG 시스템이 직면하는 복잡한 문제들을 강조합니다. 이는 Table 03에서 확인할 수 있습니다. 평가 프레임워크와 지표의 지속적인 개발은 이 분야의 발전, RAG 시스템의 적용 범위 확장, 그리고 복잡하고 변화하는 정보 환경의 요구를 충족시키는 데 있어 매우 중요합니다.
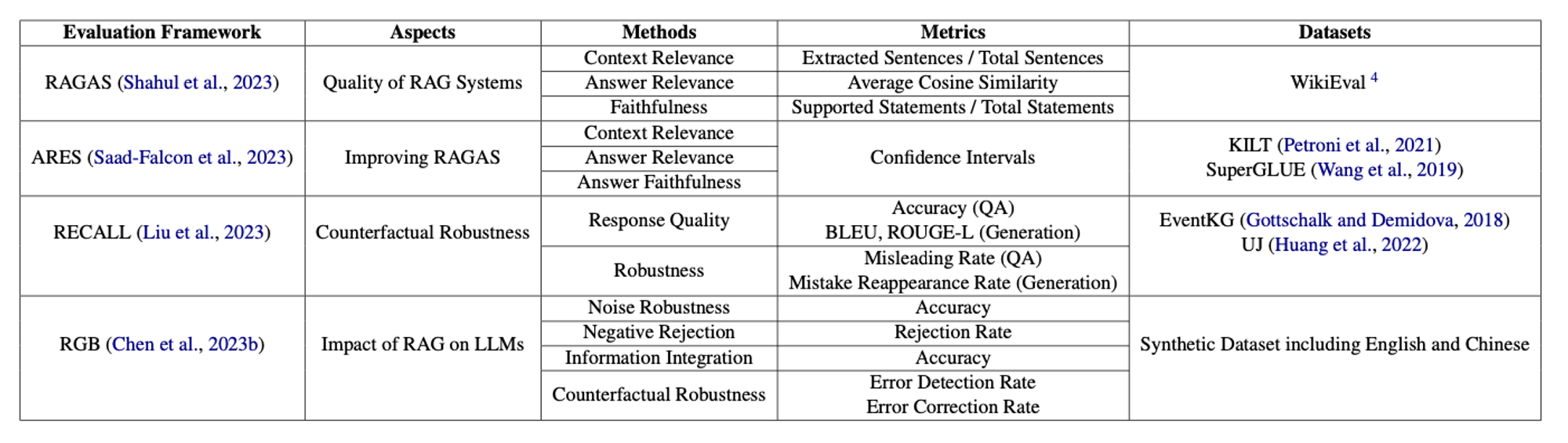
🔼 Table 03 : 서로 다른 RAG 평가 프레임워크의 비교
8.1 Retrieval-based Aspect
정보 검색에서 검색 결과의 품질은 일반적으로 평균 정밀도(MAP), 정밀도, 역순위, 정규화 할인 누적 이득(NDCG)과 같은 표준 지표를 사용하여 평가됩니다 (Radlinski and Craswell, 2010; Reimers and Gurevych, 2019; Nogueira et al., 2019). 이러한 지표들은 주로 주어진 쿼리에 대해 검색된 문서의 관련성을 평가합니다. RAG에서 검색 기반 지표는 생성 작업을 지원하기 위해 관련 정보를 검색하는 효과에 중점을 둡니다. 여기에는 쿼리에 대한 정답 정보를 제공하는 검색된 문서의 정확도를 측정하는 정확도(Accuracy), 그리고 관련 정보가 없을 때 응답을 거부할 수 있는 시스템의 능력을 평가하는 거부율(Rejection Rate)(Chen et al., 2023b)가 포함됩니다. 또한, 오류 탐지율(Error Detection Rate)(Chen et al., 2023b)은 검색된 문서에서 잘못되거나 오해의 소지가 있는 정보를 식별하고 무시하는 모델의 능력을 평가합니다. 문맥 관련성(Context Relevance)은 또 다른 중요한 지표로, 검색된 문서가 쿼리와 얼마나 관련이 있는지를 평가합니다. 이는 생성된 응답에 사용된 정보가 쿼리의 문맥과 직접적으로 관련이 있음을 보장하는 데 중요합니다. 신뢰성(Faithfulness)(Shahul et al., 2023)은 생성된 콘텐츠가 검색된 문서의 정보를 얼마나 정확하게 반영하는지를 측정하며, 생성 과정에서 잘못된 정보가 없는지 확인합니다.
8.2 Generation-based Aspect
대규모 언어 모델(LLM)이 생성한 텍스트의 품질을 평가하는 것은 다양한 다운스트림 작업에서의 성능을 표준 지표를 사용하여 분석하는 것을 포함합니다. 이러한 지표는 언어적 품질, 일관성, 정확성, 생성된 텍스트가 실제 데이터를 얼마나 반영하는지를 평가합니다. 언어적 품질과 일관성은 인간이 작성한 텍스트와의 유창성과 유사성을 측정하는 BLEU(Papineni et al., 2002)와 참조 요약과의 중복을 정량화하여 텍스트가 주요 아이디어와 구문을 얼마나 잘 포착하는지를 평가하는 ROUGE-L(Lin, 2004)과 같은 지표를 통해 평가됩니다. 정확성과 실제 데이터와의 중복은 각각 완전히 정확한 답변의 비율을 결정하는 EM과 관련 답변을 검색하면서 부정확성을 최소화하는 정밀도와 재현율의 균형 잡힌 평가를 제공하는 F1 점수와 같은 지표를 사용하여 측정됩니다.
이 표준 지표 외에도, 평가에는 특정 응용 분야에 맞춘 작업별 기준과 새로운 지표가 포함될 수 있습니다. 예를 들어, 대화 생성에서는 응답의 다양성과 자연스러움을 평가하기 위해 당혹도(perplexity)와 엔트로피(entropy)가 사용됩니다. 또한, Misleading Rate와 Mistake Reappearance Rate(Liu et al., 2023)과 같은 지표는 모델이 허위 정보와 부정확성을 피하는 능력을 측정합니다. 다른 특화된 지표로는 쿼리에 대한 응답의 정확성을 평가하는 Answer Relevance(Shahul et al., 2023), RAG 시스템의 순위를 평가하는 Kendall’s tau(Saad-Falcon et al., 2023), 여러 개의 정답이 있는 작업에서 정확성 평가를 미세 조정하는 Micro-F1(Saad-Falcon et al., 2023), 그리고 생성된 답변이 예상 응답과 얼마나 일치하는지를 직접 측정하여 시스템이 정확한 콘텐츠를 생성하는 효과를 직접적으로 평가하는 Prediction Accuracy가 있습니다.
9. Future Directions
9.1 Retrieval Quality
RAG를 대규모 언어 모델(LLM)에 통합하는 데는 인터넷에 존재하는 방대한 양의 신뢰할 수 없는 정보, 특히 가짜 뉴스로 인해 상당한 어려움이 따릅니다. 이는 유용한 지식을 정확하게 검색하는 데 어려움을 초래하여, LLM이 신뢰할 수 없는 응답을 생성하게 만듭니다. 그 결과, LLM은 잘못된 정보를 바탕으로 콘텐츠를 생성할 수 있으며, 이는 모델의 신뢰성을 저하시킬 수 있습니다. 최근 연구 노력은 LLM이 정확하고 신뢰할 수 있는 응답을 생성하는 데 있어 효율성, 확장성, 효과성을 향상시키기 위해 검색 방법을 개선하는 데 초점을 맞추고 있습니다.
Differentiable Search Indices
차별화된 검색 인덱스(Tay et al., 2022)와 (Bevilacqua et al., 2022b)는 검색 과정을 트랜스포머 모델 내에 통합하여 텍스트 쿼리를 문서 식별자로 직접 매핑할 수 있는 차별화된 검색 인덱스를 개발했습니다. 이러한 접근 방식은 더 높은 성능을 제공하며, 더 효율적이고 확장 가능한 검색의 가능성을 제시합니다.
Generative Models for Search
GERE(Chen et al., 2022a)는 사실 검증 작업을 위해 문서 제목과 증거 문장을 직접 생성할 수 있습니다. PARADE(Li et al., 2024)는 문서의 여러 단락을 통합하여 단일 문서 관련성 점수로 집계하는 문서 재순위 매기기 방법입니다. 이 두 가지 방법 모두 전통적인 방법에 비해 검색 품질에서 상당한 향상을 보여줍니다.
Fine-tuning Pre-trained Language Models
RankT5(Zhuang et al., 2023)은 텍스트 순위를 매기기 위해 T5 프레임워크를 특화하여 미세 조정한 모델입니다. 이 모델은 순위 손실을 활용하여 성능 지표를 최적화하고, 도메인 외 데이터에서도 유망한 제로샷 성능을 보여줍니다.
Noise Power
Noise Power(Cuconasu et al., 2024)는 RAG 시스템에서 정보 검색(IR) 구성 요소의 영향에 대한 포괄적인 분석을 제공하며, 관련이 없는 문서의 포함이 정확도를 상당히 개선할 수 있음을 밝혀냅니다. 이 연구는 기존의 검색 전략에 도전하며, 검색을 언어 생성 모델과 통합하는 특화된 접근 방식을 개발할 가능성을 강조합니다.
9.2 MultiModal RAG
Multi Modal RAG 분야는 텍스트와 시각적 이해의 융합에서 중요한 발전을 이루며 상당한 성장을 경험했습니다. MuRAG(Chen et al., 2022b)의 도입은 텍스트와 시각 정보를 결합하여 언어 생성을 수행하는 혁신적인 성과로, 멀티모달 데이터셋의 새로운 기준을 확립했습니다. 이 모델은 다중 모드 메모리 시스템을 활용하여 질문 응답 및 추론 작업의 정확성을 향상시키는 데 효과적임을 보여주었습니다. MuRAG 이후, REVEAL(Hu et al., 2023)과 Re-Imagen(Chen et al., 2023c)와 같은 연구들은 시각적 질문 응답 및 텍스트-이미지 생성의 향상에 중점을 두었습니다. 이들은 각각 동적 검색 메커니즘을 통합하고 이미지 충실도를 개선함으로써 이러한 목표를 달성했습니다. 이러한 발전은 Sarto et al.(Sarto et al., 2022)의 이미지 캡셔닝과 Yuan et al.(Yuan et al., 2023)의 텍스트-오디오 생성과 같은 연구자들에 의해 더 발전된 모델을 위한 기초를 마련했으며, RAG의 적용 범위를 다양한 모달리티로 확장하고 생성된 출력물의 품질과 현실성을 개선했습니다. 또한, Re-ViLM(Yang et al., 2023b)은 검색 증강 시각 언어 모델을 통해 이미지 캡셔닝 기능을 정제했습니다. 모델 매개변수를 미세 조정하고 혁신적인 필터링 전략을 구현하여 보다 정확하고 문맥적으로 적절한 캡션을 생성하는 데 큰 진전을 이루었습니다. 이러한 모델들은 외부 리소스를 활용하여 전통적인 벤치마크보다 상당한 향상을 이루었으며, 다양한 지식 소스를 통합하는 것의 이점을 강조했습니다.
10. Conclusion
이 논문에서는 RAG 분야를 이해하기 위한 포괄적인 프레임워크를 제시하고, RAG가 LLM(대규모 언어 모델)의 기능을 향상시키는 데 중요한 역할을 한다는 점을 강조하였습니다. RAG에 대한 체계적인 개요, 다양한 방법의 분류, 핵심 기술 및 평가 방법에 대한 심도 있는 분석을 통해, 이 연구는 향후 연구를 위한 방향을 밝혀줍니다. 이 논문은 중요한 개선 영역을 식별하고, 특히 텍스트 문맥에서 RAG 응용을 발전시키기 위한 잠재적인 방향을 제시합니다. 이 조사의 목적은 검색 관점에서 RAG 분야의 핵심 개념을 명확히 하고, 정보의 정확한 검색 및 생성을 위한 추가 탐구와 혁신을 촉진하는 데 있습니다.
11. Limitations
본 survey는 기존 RAG 모델을 포괄적으로 검토하고, 검색 관점에서 그 핵심 기술을 네 가지 주요 단계로 요약합니다. 일부 방법이 여러 단계를 포함할 수 있으며, 이러한 단계를 분리하면 본질적인 연결이 모호해질 수 있음을 인식합니다. 그럼에도 불구하고, 주요 목적은 접근 방식의 복잡성을 단순화하고, 해결하려는 특정 문제를 명확히 구분하는 것입니다. 이를 통해 추가 최적화 및 개선이 가능한 영역을 더 명확하게 식별할 수 있습니다. 철저한 조사를 했음에도 불구하고, 이 분야의 빠른 발전과 페이지 제한으로 인해 특정 측면이 완전히 분석되고 탐구되지 못했거나 최근의 발전이 누락되었을 수 있습니다. 논문에서는 RAG 개발에 도움이 될 수 있는 평가 방법을 언급하고 있으며, LangChain 및 LlamaIndex와 같은 성숙한 도구들을 유용한 자원으로 인정하고 있습니다. 그러나 이 조사의 초점은 평가 절차의 세부 사항이나 이러한 도구가 어떻게 사용되는지를 설명하는 것이 아니라, 평가 측면이 어떻게 RAG의 발전을 지원할 수 있는지를 보여주는 데 있습니다. 이 선택은 방법론의 명확성과 RAG 모델을 정제하고 개선하는 데 평가 도구를 적용하는 것의 중요성을 강조하는, 향후 연구를 위한 영역을 부각시킵니다.
