
Temporary Views
- 데이터프레임을 만든 후, sql를 사용할 수 있도록 만들어 주는 형식.
- spark session이 끝나고나면 없어진다.
peopleDF.createOrReplaceTempView("People10M")# To view the contents of temporary view, use select notation
spark.sql("select * from People10M where firstName = 'Donna'")DataFrame[id: int, firstName: string, middleName: string, lastName: string, gender: string, birthDate: timestamp, ssn: string, salary: int]display(spark.sql("select * from People10M where firstName = 'Donna'"))DataFrame[id: int, firstName: string, middleName: string, lastName: string, gender: string, birthDate: timestamp, ssn: string, salary: int]womenBornAfter1990DF = peopleDF.\
select("firstName", "middleName", "lastName", year('birthDate').alias("birthYear")).\
filter("birthYear > '1990'").\
filter("gender = 'F'")display(womenBornAfter1990DF) # dataframe으로 확인할 수 있음DataFrame[firstName: string, middleName: string, lastName: string, birthYear: int]#Create Temporary Views from the womenBornAfter1990DF Dataframe
womenBornAfter1990DF.createOrReplaceTempView('womenBornAfter1990')spark.sql("select count(*) from womenBornAfter1990 where firstName = 'Mary'").show()+--------+
|count(1)|
+--------+
| 268|
+--------+Exercise1
step 1
Create a DataFrame called top10FremaleFirstNamesDF and display the results.
from pyspark.sql.functions import count, desc
top10FemaleFirstNamesDF = (peopleDF
.select("firstName")
.filter("gender == 'F'")
.groupBy("firstName")
.agg(count(col('firstname')).alias('total'))
.orderBy((desc('total')))
.limit(10)
)
top10FemaleFirstNamesDF.show()+---------+-----+
|firstName|total|
+---------+-----+
| Sharyn| 1394|
| Lashell| 1387|
| Alice| 1384|
| Lucille| 1384|
| Louie| 1382|
|Jacquelyn| 1381|
| Cristen| 1375|
| Katherin| 1373|
|Bridgette| 1373|
| Alesha| 1368|
+---------+-----+step 2
top10FemaleNamesDF = top10FemaleFirstNamesDF.orderBy("firstName")
display(top10FemaleNamesDF)DataFrame[firstName: string, total: bigint]# 위와 같은 기능
top10FemaleFirstNamesDF.createOrReplaceTempView("Top10FemaleFirstNames")
resultsDF = spark.sql("SELECT * FROM Top10FemaleFirstNames ORDER BY firstName")
display(resultsDF)
resultsDF.show()DataFrame[firstName: string, total: bigint]
+---------+-----+
|firstName|total|
+---------+-----+
| Alesha| 1368|
| Alice| 1384|
|Bridgette| 1373|
| Cristen| 1375|
|Jacquelyn| 1381|
| Katherin| 1373|
| Lashell| 1387|
| Louie| 1382|
| Lucille| 1384|
| Sharyn| 1394|
+---------+-----+Pyspark Join
valuesA = [('Pirate',1), ('Monkey', 2), ('Ninja', 3), ('Spaghetti', 4)]
TableA = spark.createDataFrame(valuesA, ['name', 'id'])
valuesB = [('Rutabaga', 1), ('Pirate', 2), ('Ninja',3), ('Darth Vader', 4)]
TableB = spark.createDataFrame(valuesB, ['name','id'])
TableA.show()
TableB.show()+---------+---+
| name| id|
+---------+---+
| Pirate| 1|
| Monkey| 2|
| Ninja| 3|
|Spaghetti| 4|
+---------+---+
+-----------+---+
| name| id|
+-----------+---+
| Rutabaga| 1|
| Pirate| 2|
| Ninja| 3|
|Darth Vader| 4|
+-----------+---+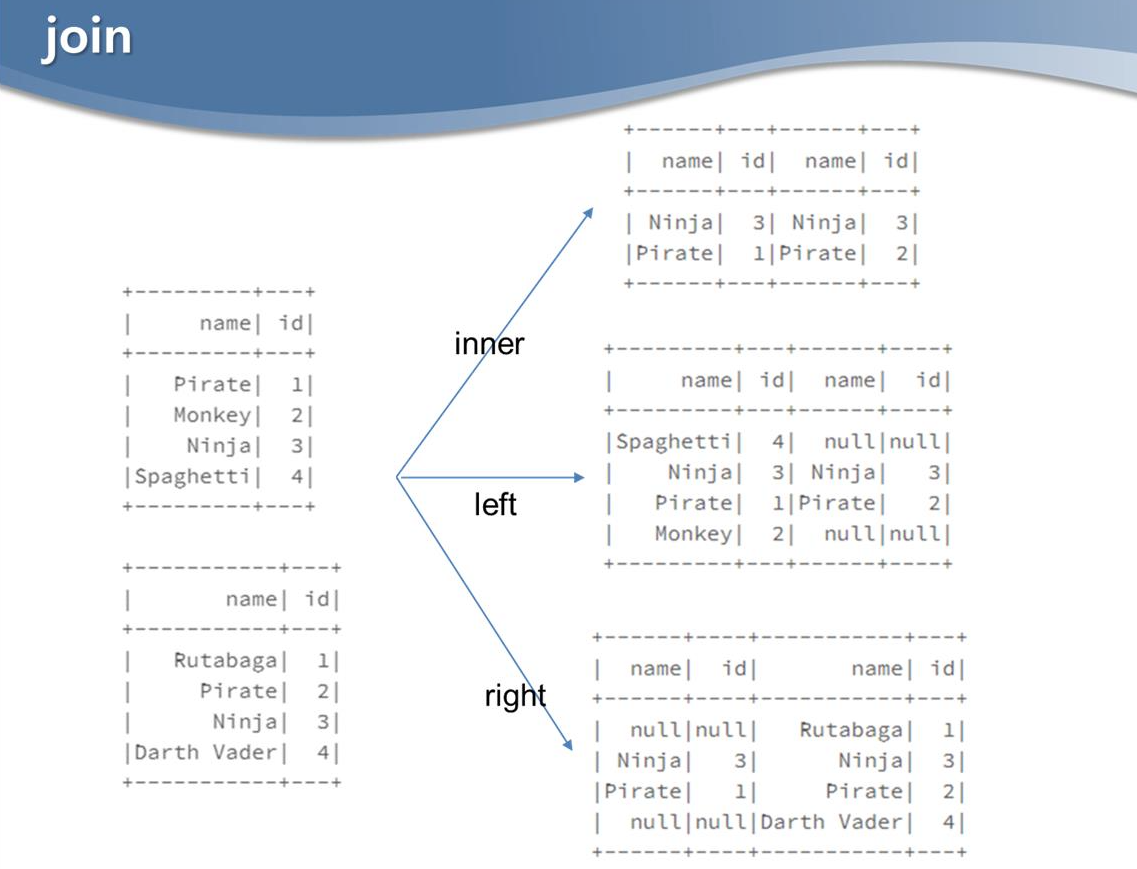
innerJoin은 양쪽 테이블 모두에 공통적으로 존재하는 것을 join
leftJoin은 왼쪽 테이블이 키가 되서 join
rightJoin은 오른쪽테이블이 키가되서 join
없는 것들은 null
InnerJoin
ta = TableA.alias('ta') # ta로 alias
tb = TableB.alias('tb')inner_join = ta.join(tb, ta.name == tb.name) # join 명령어와 조건을 이용하여 ta와 tb를 join
inner_join.show()+------+---+------+---+
| name| id| name| id|
+------+---+------+---+
| Ninja| 3| Ninja| 3|
|Pirate| 1|Pirate| 2|
+------+---+------+---+LeftJoin
left_join = ta.join(tb, ta.name == tb.name, how='left') # Colud also use 'left_outer'
# how를 이용하여 left 명시
left_join.show()+---------+---+------+----+
| name| id| name| id|
+---------+---+------+----+
|Spaghetti| 4| null|null|
| Ninja| 3| Ninja| 3|
| Pirate| 1|Pirate| 2|
| Monkey| 2| null|null|
+---------+---+------+----+from pyspark.sql.functions import col
left_join = ta.join(tb, ta.name == tb.name, how='left')
left_join.filter(col('tb.name').isNull()).show() ## null을 포함하는 행을 출력+---------+---+----+----+
| name| id|name| id|
+---------+---+----+----+
|Spaghetti| 4|null|null|
| Monkey| 2|null|null|
+---------+---+----+----+RightJoin
right_join = ta.join(tb, ta.name == tb.name, how='right') # Colud also use 'right_outer'
right_join.show()+------+----+-----------+---+
| name| id| name| id|
+------+----+-----------+---+
| null|null| Rutabaga| 1|
| Ninja| 3| Ninja| 3|
|Pirate| 1| Pirate| 2|
| null|null|Darth Vader| 4|
+------+----+-----------+---+OuterJoin
full outer join을 하는 경우에는 left, right 두 테이블을 모두 본다.
left join, right join을 모두 사용한 결과

full_outer_join = ta.join(tb, ta.name == tb.name, how='full') # Colud also use 'full_outer'
full_outer_join.show()+---------+----+-----------+----+
| name| id| name| id|
+---------+----+-----------+----+
| null|null| Rutabaga| 1|
|Spaghetti| 4| null|null|
| Ninja| 3| Ninja| 3|
| Pirate| 1| Pirate| 2|
| Monkey| 2| null|null|
| null|null|Darth Vader| 4|
+---------+----+-----------+----+필드의 네임이 같은 경우 혼란이 생길 수 있음.
ta.name, tb.name 등과 같이 네임 필드의 이름을 바꿔주는 것이 좋음
inner_join = ta.join(tb, ta.name == tb.name)
inner_join.show()+------+---+------+---+
| name| id| name| id|
+------+---+------+---+
| Ninja| 3| Ninja| 3|
|Pirate| 1|Pirate| 2|
+------+---+------+---+llist = [('bob', '2015-01-13', 4), ('alice', '2015-04-23', 10)]
left = spark.createDataFrame(llist, ['name', 'date', 'duration'])
right = spark.createDataFrame([('alice', 100), ('bob', 23)], ['name','upload'])
df = left.join(right, left.name == right.name)
display(df)
df.show()
## 스키마가 달라도 join 하기에는 상관이 없음, 공통적인 필드만 존재하면 된다.DataFrame[name: string, date: string, duration: bigint, name: string, upload: bigint]
+-----+----------+--------+-----+------+
| name| date|duration| name|upload|
+-----+----------+--------+-----+------+
|alice|2015-04-23| 10|alice| 100|
| bob|2015-01-13| 4| bob| 23|
+-----+----------+--------+-----+------+# 중복된 name 칼럼이 없어진다.
df = left.join(right, on = "name")
df.show()+-----+----------+--------+------+
| name| date|duration|upload|
+-----+----------+--------+------+
|alice|2015-04-23| 10| 100|
| bob|2015-01-13| 4| 23|
+-----+----------+--------+------+# 중복된 name 칼럼이 없어진다.
df = left.join(right, ["name"])
df.show()+-----+----------+--------+------+
| name| date|duration|upload|
+-----+----------+--------+------+
|alice|2015-04-23| 10| 100|
| bob|2015-01-13| 4| 23|
+-----+----------+--------+------+Preprocessing peopled: avg, round, min, max, col
avg
# avg
from pyspark.sql.functions import avg
avgSalaryDF = peopleDF.select(avg("salary").alias("averageSalary"))
avgSalaryDF.show()+-------------+
|averageSalary|
+-------------+
|72633.0076033|
+-------------+round
# round
from pyspark.sql.functions import round
roundedAvgSalaryDF = avgSalaryDF.select(round("averageSalary").alias("roundedAverageSalary"))
roundedAvgSalaryDF.show()+--------------------+
|roundedAverageSalary|
+--------------------+
| 72633.0|
+--------------------+min, max
# max, min
from pyspark.sql.functions import min, max
salaryDF = peopleDF.select(max("salary").alias("max"), min("salary").alias("min"),\
round(avg("salary")).alias("averageSalary"))
salaryDF.show()+------+------+-------------+
| max| min|averageSalary|
+------+------+-------------+
|180841|-26884| 72633.0|
+------+------+-------------+# distinct
print(peopleDF.count())
peopleDFDistinctNamesDF = peopleDF.select("firstName").distinct()
print(peopleDFDistinctNamesDF.count())
peopleDFDistinctNamesDF.show(1)10000000
5113
+---------+
|firstName|
+---------+
| Alayna|
+---------+
only showing top 1 rowColumnRenamed
peopleDFDistinctNamesDF = peopleDF.select("firstName")\
.withColumnRenamed("firstName", "peopleFirstName").distinct() # firstName -> peopleFirstName
print(peopleDFDistinctNamesDF.count())
peopleDFDistinctNamesDF.show(3)5113
+---------------+
|peopleFirstName|
+---------------+
| Alayna|
| Melaine|
| Faye|
+---------------+
only showing top 3 rowscol
a = peopleDF.select("salary").show(3)
b = peopleDF.select(col("salary")).show(3)+------+
|salary|
+------+
| 56172|
| 40203|
| 53417|
+------+
only showing top 3 rows
+------+
|salary|
+------+
| 56172|
| 40203|
| 53417|
+------+
only showing top 3 rowspeopleDF.select(avg("salary")).show(3)
peopleDF.select(avg(col("salary"))).show(3)+-------------+
| avg(salary)|
+-------------+
|72633.0076033|
+-------------+
+-------------+
| avg(salary)|
+-------------+
|72633.0076033|
+-------------+peopleDF.select(round("salary")).show(3)
peopleDF.select(round(col("salary"))).show(3)+----------------+
|round(salary, 0)|
+----------------+
| 56172|
| 40203|
| 53417|
+----------------+
only showing top 3 rows
+----------------+
|round(salary, 0)|
+----------------+
| 56172|
| 40203|
| 53417|
+----------------+
only showing top 3 rowspeopleDF.select(min("salary")).show(3)
peopleDF.select(min(col("salary"))).show(3)+-----------+
|min(salary)|
+-----------+
| -26884|
+-----------+
+-----------+
|min(salary)|
+-----------+
| -26884|
+-----------+- abs, upper 등은 string을 argument로 받지 않음 -> col 으로 argument passing 이 필요함
from pyspark.sql.functions import abs
#peopleDF.select(abs("salary")).show(3) # error
peopleDF.select(abs(col("salary"))).show(3)+-----------+
|abs(salary)|
+-----------+
| 56172|
| 40203|
| 53417|
+-----------+
only showing top 3 rowsfrom pyspark.sql.functions import upper
peopleDF.select(upper(col("firstName"))).show(3)+----------------+
|upper(firstName)|
+----------------+
| PENNIE|
| AN|
| QUYEN|
+----------------+
only showing top 3 rowssalary sorting
from pyspark.sql.functions import abs
peopleWithFixedSalariesDF = peopleDF.select("firstName", "middleName",\
"lastName", "gender", "birthDate", "ssn", abs(col("salary")).alias("salary"))
peopleDFDistinctNamesDF.count()5113peopleWithFixedSalariesDF.show(3)+---------+----------+----------+------+-------------------+-----------+------+
|firstName|middleName| lastName|gender| birthDate| ssn|salary|
+---------+----------+----------+------+-------------------+-----------+------+
| Pennie| Carry|Hirschmann| F|1955-07-02 13:30:00|981-43-9345| 56172|
| An| Amira| Cowper| F|1992-02-08 14:00:00|978-97-8086| 40203|
| Quyen| Marlen| Dome| F|1970-10-11 13:00:00|957-57-8246| 53417|
+---------+----------+----------+------+-------------------+-----------+------+
only showing top 3 rowspeopleWithFixedSalariesSortedDF = peopleWithFixedSalariesDF.select("*").\
orderBy("salary").limit(20)peopleWithFixedSalariesSortedDF.show(4)+---------+----------+--------+------+-------------------+-----------+------+
|firstName|middleName|lastName|gender| birthDate| ssn|salary|
+---------+----------+--------+------+-------------------+-----------+------+
| Janene| Lili| Prinn| F|1986-04-06 14:00:00|923-50-6804| 2|
| Brook| Winifred| Durnell| F|1999-09-07 13:00:00|989-18-7019| 3|
| Garret| Garrett| Ashling| M|1959-10-19 12:30:00|918-39-6461| 4|
| Doloris| Domenica| Matic| F|1984-08-03 13:00:00|928-53-3688| 5|
+---------+----------+--------+------+-------------------+-----------+------+
only showing top 4 rowspeopleWithFixedSalariesSortedDF = peopleWithFixedSalariesDF.select("*").\
orderBy("salary", ascending=False).limit(20).show(4)+---------+----------+---------+------+-------------------+-----------+------+
|firstName|middleName| lastName|gender| birthDate| ssn|salary|
+---------+----------+---------+------+-------------------+-----------+------+
| Belinda| Talia| Jessard| F|1955-05-15 13:30:00|966-31-6469|180841|
| Shena| Patty| Grinston| F|1989-09-02 13:00:00|980-60-8702|173969|
| Courtney| Kip| Liell| M|1986-12-06 14:00:00|981-68-2592|170562|
| Clarence| Allan|MacDuffie| M|1967-07-02 13:00:00|924-59-6873|170371|
+---------+----------+---------+------+-------------------+-----------+------+
only showing top 4 rows
'당신을 한 줄로 소개해보세요'를 이 블로그로 대신 해볼까합니다.