Web
Server & Client 구조
- Client
- Request : 브라우저를 사용하여 Server에 데이터를 요청
- Server
- Response : Client의 브라우저에서 데이터를 요청하면 요청에 따라 데이터를 Client로 전송 - Response : Client의 브라우저에서 데이터를 요청하면 요청에 따라 데이터를 Client로 전송
URL
Uniform Resource Locator
http://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=105&oid=001&aid=0009847211#da_727145
- http : 프로토콜
- http :웹 브라우저와 서버 간의 데이터를 평문으로 전송 (암호화X)
- https : Secure. HTTP에 보안 계층을 추가.
- news : 서브 도메인
- naver.com : 프라이머리 도메인
- 도메인 : 어떤 서버를 찾아 들어갈지 결정하는 역할
- DNS : 도메인을 IP주소로 변환해줌
- 80 : 포트 (생략 가능)
- 서버에서 특정 서비스를 구분
- WAS나 DB를 구분해서 찾아갈 수 있도록 해줌
- /main/ : Path
- read.nhn : page(file)
- mode=LSD : Query
- #da_727145 : Fragment
- 전체 document에서 어떤 부분을 보여줄지 결정
HTTP Request methods
Get
- URL에 Query 포함 (?aid=1&sid=100)
- Query(데이터) 노출, 전송 가능 데이터 작음
Post
- Body에 Query 포함
- Query(데이터) 비노출, 전송 가능 데이터 많음.
HTTp Status Code
Client와 Server가 데이터를 주고 받은 결과 정보
- 2xx : Success
- 3xx : Redirect
- 4xx : Request Error
- 5xx : Server Error
Cookie, Session, Cache
Cookie
- Client의 Browser에 저장하는 문자열 데이터
- 사용 예시 : 로그인 정보, 내가 봤던 상품 정보, 팝업 다시보지 않음 등
session
- Client의 Browser와 Server의 연결 정보
- 사용 예시 : 자동 로그인
Cashe
- Client, Server의 RAM에 저장하는 데이터
- RAM에 데이터를 저장하면 데이터 입출력이 빠름
Scraping & Crawling
Scraping
- 특정 데이터를 수집하는 작업
Crawling
- 웹서비스의 여러 페이지를 이동하며 데이터를 수집하는 작업
- spider, web crawler, bot 용어 사용
Python
- 컴퓨터의 CPU, RAM, SSD를 활용하기 위해서 학습
- 변수 선언 : RAM 사용 문법 : 식별자 ( 저장공간을 구분하는 문자열 ) :PEP20, PEP8( autopep8, flake8 )
- 데이터 타입 : RAM 효율적 사용 문법 : int, float, bool, str, list, tuple, dict, set
- 연산자 : CPU 사용 문법 : 산술, 비교, 논리, 할당, 멤버 ...
- 조건문, 반복문 : if, elif, else : while, for, break, continue ,range() ...
- 함수 : 반복 사용되는 코드를 묶어서 코드 작성 및 실행 : def, return , scope(global), lambda ...
- 클래스 : 변수, 함수를 묶어서 코드 작성 실행 : 객체 지향 구현 : class, self, special methods (생성자 메소드)
- 모듈 : 변수, 함수, 클래스를 파일로 묶어서 코드 작성 및 실행 : 확장자 .py
- 패키지 : 여러개의 모듈을 디렉토리로 묶어서 관리 : 버전정보 포함 : import, from, as
- 입출력 : SSD 사용 문법 : RAM(Object) > SSD(file) or SSD(file) > RAM(Object) : pickle
Class
- 변수, 함수를 묶어서 코드 작성 및 실행
- 객체 지향 구현 : 실제 세계를 모델링하여 프로그램을 개발하는 개발 방법론 : 협업 용이
- 함수 사용 : 함수 선언(코드 작성) > 함수 호출(코드 실행)
- 클래스 사용
- 클래스 선언(코드 작성=설계도 작성) > 객체 생성(메모리 사용=제품 생산) > 메서드 실행(코드 실행=제품 사용)
- 메서드 : 클래스 안에 선언되는 함수
- class 식별자 : UpperCameCase , PascalCase(0), snake_case()
웹 페이지 동작 과정
동적 페이지
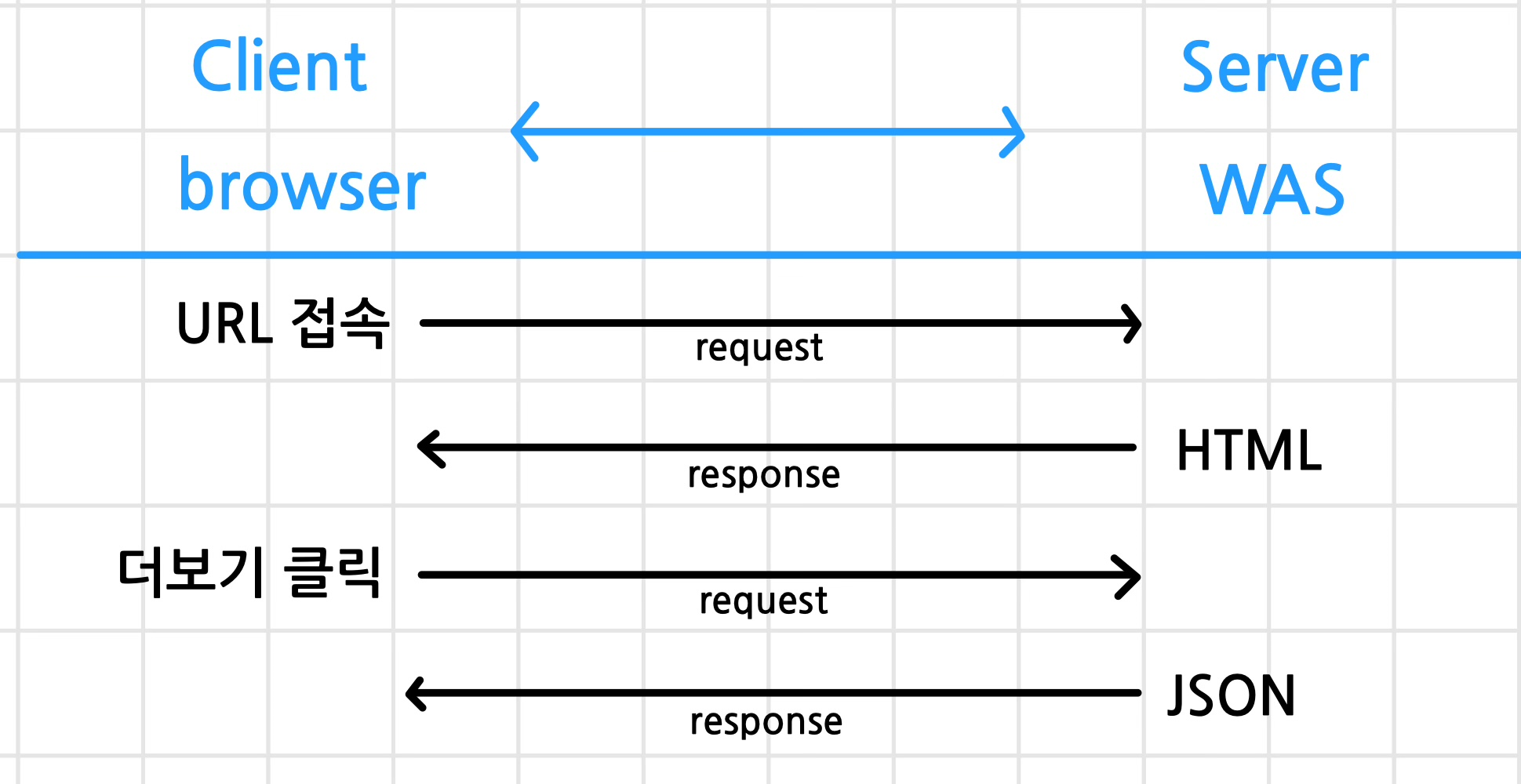
- URL : dev tools
- request(URL) -> response(JSON)
- JSON(str) -> list,dict -> DF
정적 페이지
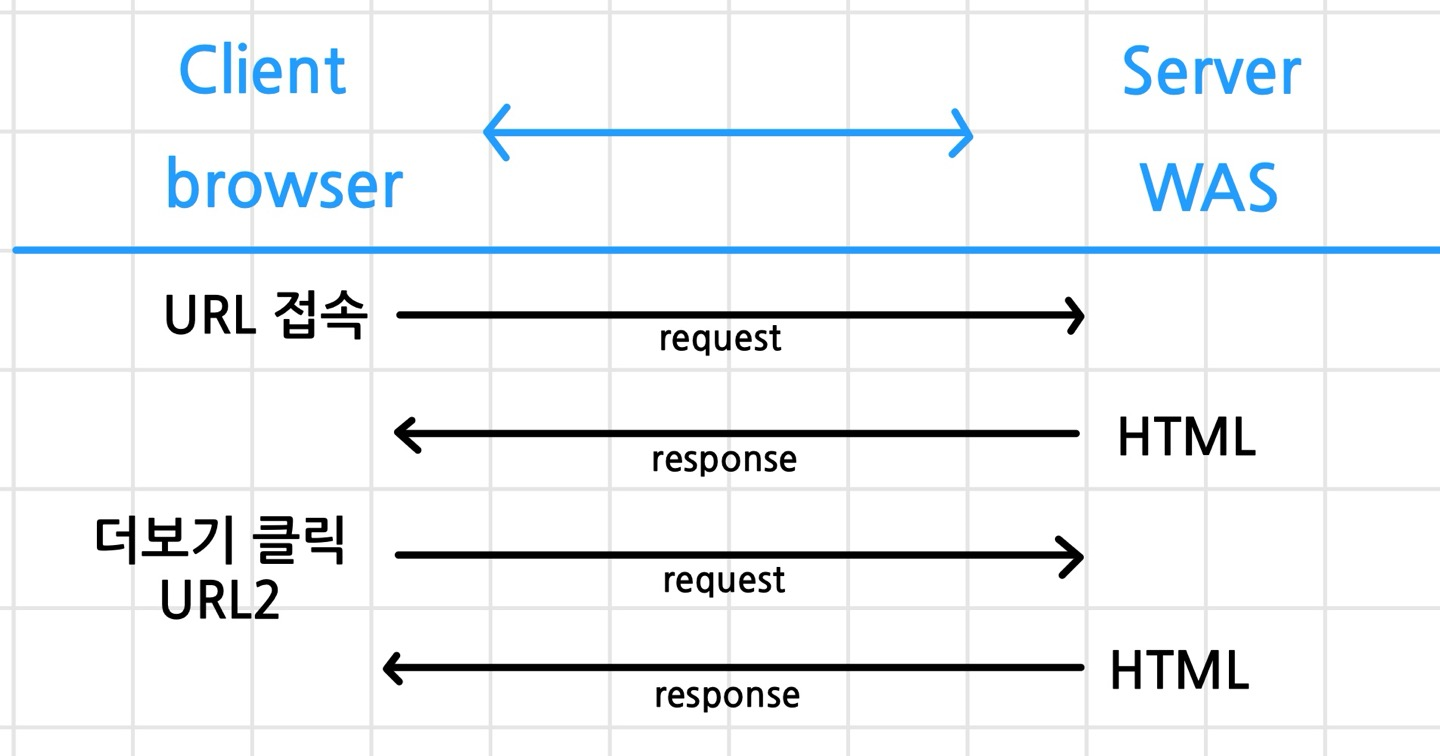
- URL : dev tools
- request(URL) -> response(html)
- html(str) -> bs4, css-select -> text -> list,dict -> DF
웹크롤링 방법
웹페이지의 종류
- 정적인 페이지 : 웹 브라우져에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
- 동적인 페이지 : 웹 브라우져에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
requests 이용
- 받아오는 문자열에 따라 두가지 방법으로 구분
- json 문자열로 받아서 파싱하는 방법 : 주로 동적 페이지 크롤링할때 사용
- html 문자열로 받아서 파싱하는 방법 : 주로 정적 페이지 크롤링할때 사용
selenium 이용
- 브라우져를 직접 열어서 데이터를 받는 방법
크롤링 방법에 따른 속도
- requests json > requests html > selenium
Crawling Naver Stock Datas
- 네이버 증권 사이트에서 주가 데이터 수집
- 수집할 데이터 : 일별 kospi, kosdaq 주가, 일별 환율(exchange rate) 데이터
- 데이터 수집 절차
- 웹서비스 분석 : url
- 서버에 데이터 요청 : request(url) > response : json(str)
- 서버에서 받은 데이터 파싱(데이터 형태를 변경) : json(str) > list, dict > DataFrame
임포트
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import requests1. 웹서비스 분석 : url
page, page_size = 1, 60
url = f'https://m.stock.naver.com/api/index/KOSPI/price?\
pageSize={page_size}&page={page}'
print(url)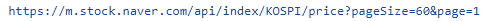
2. 서버에 데이터 요청 : request(url) > response : json(str)
- response의 status code가 200이 나오는지 확인
- 403이나 500이 나오면 request가 잘못되거나 web server에서 수집이 안되도록 설정이 된것임
- header 설정 또는 selenium 사용
- 200이 나오더라도 response 안에 있는 내용을 확인 > 확인하는 방법 : response.text
response = requests.get(url)
response
response.text[:200]

3. 서버에서 받은 데이터 파싱(데이터 형태를 변경) : json(str) > list, dict > DataFrame
columns = ["localTradedAt", "closePrice"]
data = response.json()
kospi_df = pd.DataFrame(data)[columns]
kospi_df.tail(2)
4. 함수로 만들기
def stock_price(code="KOSPI", page=1, page_size=60):
""" This function is crawling stock price from naver stock web page
parameters :
code : str : KOSPI or KOSDAQ
page : int : page number
page_size : int : one page size
return :
type : DataFame of pandas"""
url = f'https://m.stock.naver.com/api/index/{code}/price?\
pageSize={page_size}&page={page}'
response = requests.get(url)
columns = ["localTradedAt", "closePrice"]
data = response.json()
return pd.DataFrame(data)[columns]5. 원달러 환율 데이터 수집 : 실습
# 1. URL
page_size, page = 60, 1
url = f'https://m.stock.naver.com/front-api/marketIndex/prices?\
category=exchange&reutersCode=FX_USDKRW&page={page}&pageSize={page_size}'
# 2. request(URL) > response(JSON)
response = requests.get(url)
# 3. JSON > list, dict > DataFrame
data = response.json()['result']
df = pd.DataFrame(data)[['localTradedAt', 'closePrice']]
df.tail(2)
def exchange_rate(code='FX_USDKRW',page=1,page_size=60):
url = f'https://m.stock.naver.com/front-api/marketIndex/prices?\
category=exchange&reutersCode=FX_USDKRW&page={page}&pageSize={page_size}'
resonse=requests.get(url)
data = response.json()['result']
return pd.DataFrame(data)[['localTradedAt', 'closePrice']]
exchange_rate(page_size=10)
6. 시각화
# 데이터 수집
page_size = 60
kp_df = stock_price('KOSPI', page_size=page_size)
kd_df = stock_price('KOSDAQ', page_size=page_size)
usd_df = exchange_rate(page_size=page_size)
# 데이터 전처리
kp_df['closePrice'] = kp_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
kd_df['closePrice'] = kd_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
usd_df['closePrice'] = usd_df['closePrice'].apply(lambda data: float(data.replace(',', '')))# 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 3))
plt.plot(kp_df['localTradedAt'], kp_df['closePrice'], label='kospi')
plt.plot(kd_df['localTradedAt'], kd_df['closePrice'], label='kosdaq')
plt.plot(usd_df['localTradedAt'], usd_df['closePrice'], label='usd')
plt.legend()
plt.xticks(kp_df['localTradedAt'][::5])
plt.show()
7. 데이터 스케일링
from sklearn.preprocessing import minmax_scale
plt.figure(figsize=(20, 3))
plt.plot(kp_df['localTradedAt'], minmax_scale(kp_df['closePrice']), label='kospi')
plt.plot(kd_df['localTradedAt'], minmax_scale(kd_df['closePrice']), label='kosdaq')
plt.plot(usd_df['localTradedAt'],minmax_scale(usd_df['closePrice']), label='usd')
plt.legend()
plt.xticks(kp_df['localTradedAt'][::5])
plt.show()
8. 상관관계 분석
- 피어슨 상관계수(Pearson Correlation Coefficient)
- 두 데이터 집합의 상관도를 분석할때 사용되는 지표
- 상관계수의 해석
- -1에 가까울수록 서로 반대방향으로 움직임
- 1에 가까울수록 서로 같은방향으로 움직임
- 0에 가까울수록 두 데이터는 관계가 없음
# 데이터 전처리 : merge
merge_df=pd.merge(kp_df,kd_df,on='localTradedAt')
merge_df=pd.merge(merge_df,usd_df,on='localTradedAt')
merge_df.columns=['date','kospi','kosdaq','usd']
merge_df.tail(2)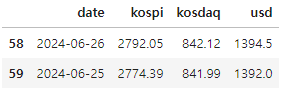
# 상관계수
# x가 증가할때 y가 감소하면 -1에 가까움
# x가 증가할때 y가 증가하면 1에 가까움
merge_df.iloc[:,1:].corr()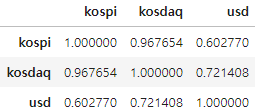
도출
- 원달러 환율이 높으면 달러를 원화로 환전하여 코스피 지수를 구매
- 원달러 환율이 낮으면 코스피 지수를 판매하여 달러로 환전한다.

복습 복습 복습