CNN 모델 구성
pytorch를 통해 간단한 CNN 모델을 구성해볼 것이다.
CNN 모델 학습에 사용할 데이터셋은 CIFAR-10이다.
CIFAR-10 데이터셋은 10개의 클래스(plane, car, bird, cat, deer, dog, frog, horse, ship, truck), 3개의 채널(RGB)로 이루어져 있는 (32X32) 사이즈의 데이터셋이다.
train 데이터셋은 50000장, test 데이터셋은 10000장으로 나누어져 있다.
import
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.init
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt필요한 것들을 import 해준다.
dataset download & load
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5 ,0.5), (0.5 ,0.5 ,0.5))]
)
train_data = datasets.CIFAR10(
root = "./dataset", # 데이터셋이 다운로드될 경로 설정
train = True, # Train 데이터셋으로 다운받을지 결정
download = True, # 다운로드할지 결정
transform = transform
)
test_data = datasets.CIFAR10(
root = "./dataset",
train = False,
download = True,
transform = transform
)데이터셋을 텐서로 변환하고, 정규화 하기 위해 transform을 정의한다. 그후 데이터셋을 하고 텐서변환, 정규화 한다.
batch_size = 4
train_dataloader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=batch_size, shuffle=True)DataLoader를 이용해 batch_size로 데이터셋을 나눠주고 shuffle한다.
Model
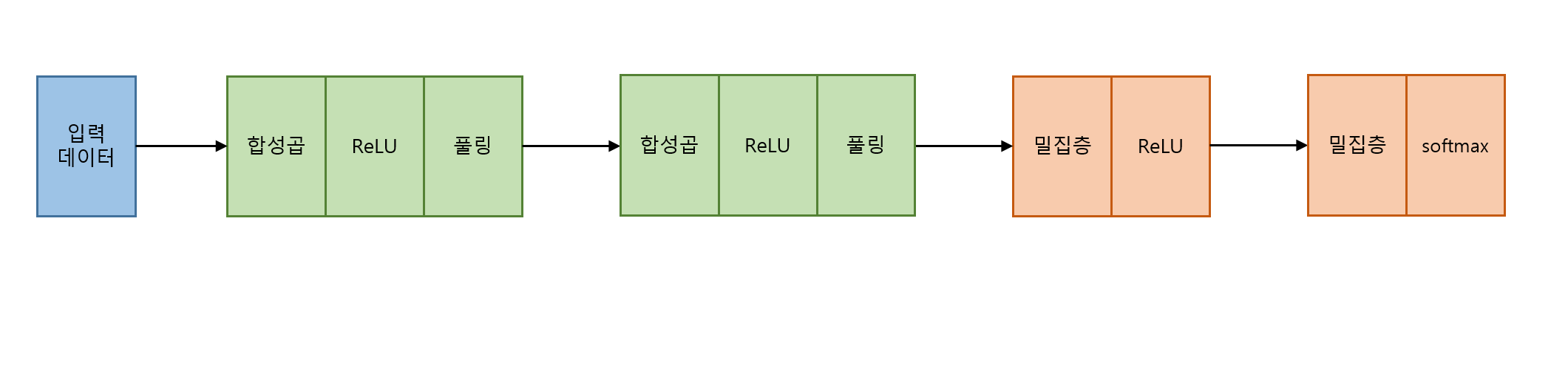 모델의 구조를 위처럼 정의할 것이다.
모델의 구조를 위처럼 정의할 것이다.
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5, stride=1)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=5*5*16, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=84)
self.fc3 = nn.Linear(in_features=84, out_features=10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(-1, 5*5*16) # 밀집층에 입력하기 위해 데이터를 Flatten
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x # 이후에 사용할 nn.CrossEntropyLoss()에서 softmax를 자동적으로 해줌 입력 채널, 데이터 차원에 따라 변수들을 잘 맞춰준다.
Training
model = CNN()
# GPU를 통해 연산을 할 수 있다면 GPU로, 그렇지 않다면 CPU로 연산
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device) # model을 GPU로
learing_rate = 0.001
epochs = 50
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = learing_rate, momentum = 0.9)학습을 진행하기 위해 learning rate, epoch, loss function, optimizer를 정의해준다.
for epoch in range(epochs):
running_loss = 0.0
for i, traindata in enumerate(train_dataloader):
img, label = traindata
img = img.to(device)
label = label.to(device)
prediction = model.forward(img) # 모델에 입력 후 예측값 출력(순전파)
optimizer.zero_grad() # Gradient를 0으로
loss = loss_function(prediction, label) # loss 구하기
loss.backward() # backpropagation(역전파)
optimizer.step() # 최적화
running_loss += loss.item()
if i % 12500 == 12499:
print(f'Epoch: {epoch + 1} ---------------------------------')
print(f'loss: {running_loss / 12500:.3f}')
running_loss = 0.0
학습 Loop를 구성해준다. 1 epoch마다 평균 loss가 출력되도록 해준다.
Epoch: 1 ---------------------------------
loss: 1.703
Epoch: 2 ---------------------------------
loss: 1.320
Epoch: 3 ---------------------------------
loss: 1.173
Epoch: 4 ---------------------------------
loss: 1.077
Epoch: 5 ---------------------------------
loss: 1.009
Epoch: 6 ---------------------------------
loss: 0.956
Epoch: 7 ---------------------------------
loss: 0.909
Epoch: 8 ---------------------------------
loss: 0.869
Epoch: 9 ---------------------------------
loss: 0.842
Epoch: 10 ---------------------------------
loss: 0.813
Epoch: 11 ---------------------------------
loss: 0.781
Epoch: 12 ---------------------------------
loss: 0.759
Epoch: 13 ---------------------------------
loss: 0.741
Epoch: 14 ---------------------------------
loss: 0.719
Epoch: 15 ---------------------------------
loss: 0.704
Epoch: 16 ---------------------------------
loss: 0.696
Epoch: 17 ---------------------------------
loss: 0.676
Epoch: 18 ---------------------------------
loss: 0.665
Epoch: 19 ---------------------------------
loss: 0.665
Epoch: 20 ---------------------------------
loss: 0.653
.
.
.
loss: 0.594
Epoch: 48 ---------------------------------
loss: 0.597
Epoch: 49 ---------------------------------
loss: 0.592
Epoch: 50 ---------------------------------
loss: 0.594Test
def imgshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1,2,0)))
plt.show()
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')테스트 결과값을 출력하기 위해 이미지를 출력할 수 있는 함수와 데이터셋 내의 데이터들의 class들을 정의해준다.
for i in range(5):
random_data = iter(test_dataloader)
image, label = next(random_data)
imgshow(torchvision.utils.make_grid(image))
print(' '.join(f'{classes[label[j]]:5s}' for j in range(batch_size)))batch size 단위로 test 데이터를 모델에 입력해 모델의 예측값을 출력한다. 총 5번 반복해보겠다.
 나쁘지 않은 성능을 보이는 것 같다.
나쁘지 않은 성능을 보이는 것 같다.
이번에는 각 클래스별 정확도를 알아보겠다.
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
with torch.no_grad():
for data in test_dataloader:
images, labels = data
outputs = model(images)
_, predictions = torch.max(outputs, 1)
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')Accuracy for class: plane is 64.9 %
Accuracy for class: car is 79.3 %
Accuracy for class: bird is 43.9 %
Accuracy for class: cat is 45.6 %
Accuracy for class: deer is 51.6 %
Accuracy for class: dog is 43.6 %
Accuracy for class: frog is 61.8 %
Accuracy for class: horse is 60.8 %
Accuracy for class: ship is 70.2 %
Accuracy for class: truck is 70.3 %위와 같은 결과가 출력된다.
CNN 모델의 구조를 개선하면 정확도를 개선할 수 있을 것이다. 기회가 된다면 관련 내용을 포스팅해보겠다.
