GAN(Generative Adversarial Network)
GAN은 Generative Adversarial Network의 줄임말로, 두 개의 신경망을 통해 서로 경쟁하면서 데이터의 생성과 분류를 수행하는 Generative Model이다.
이러한 GAN 모델은 Image-to-Image Translation, Image generation, Super Resolution 등의 분야에 활용된다.
두 개의 신경망은 각각 Generator와 Discriminater로, Generator는 데이터를 생성하는 역할을 하고, Discriminator는 데이터를 구분하는 역할을 한다.
GAN 구조
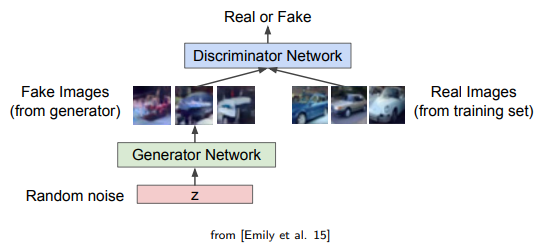
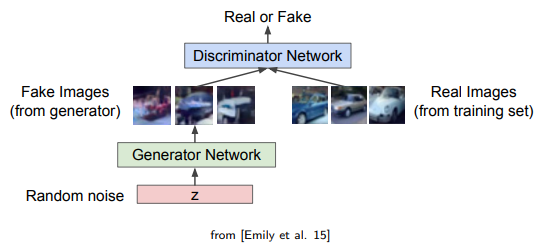 Generator는 Random noise를 입력으로 받아서 이를 통해 새로운 데이터를 생성한다. 생성된 새로운 데이터가 Training에 쓰이는 실제 데이터와 유사해지도록 하는 것을 목표로 한다.
Generator는 Random noise를 입력으로 받아서 이를 통해 새로운 데이터를 생성한다. 생성된 새로운 데이터가 Training에 쓰이는 실제 데이터와 유사해지도록 하는 것을 목표로 한다.
Discriminator는 실제 데이터와 생성자가 만든 (가짜)데이터를 입력으로 받아서 이것이 실제인지 가짜인지 판별하는 역할을 한다.
Generator는 Discriminator를 속이기 위해 실제 데이터와 유사한 데이터를 생성하려고 할 것이고, Discriminator는 Generator가 만든 데이터를 가짜 데이터로, 실제 데이터를 진짜 데이터로 구별하려고 할 것이다. 이 과정이 반복되면서 Generator는 점점 더 실제 데이터와 유사한 데이터를 생성하게 되고, Discriminator는 점점 두 데이터 사이의 더 미세한 차이를 감지하게 된다.
이러한 과정을 아래 예시를 통해 더 설명해보겠다.
Example
 Generator를 위조지폐를 만드는 위조지폐범, Discriminator를 위조지폐를 판별하는 경찰관으로 비유를 해보겠다.
Generator를 위조지폐를 만드는 위조지폐범, Discriminator를 위조지폐를 판별하는 경찰관으로 비유를 해보겠다.
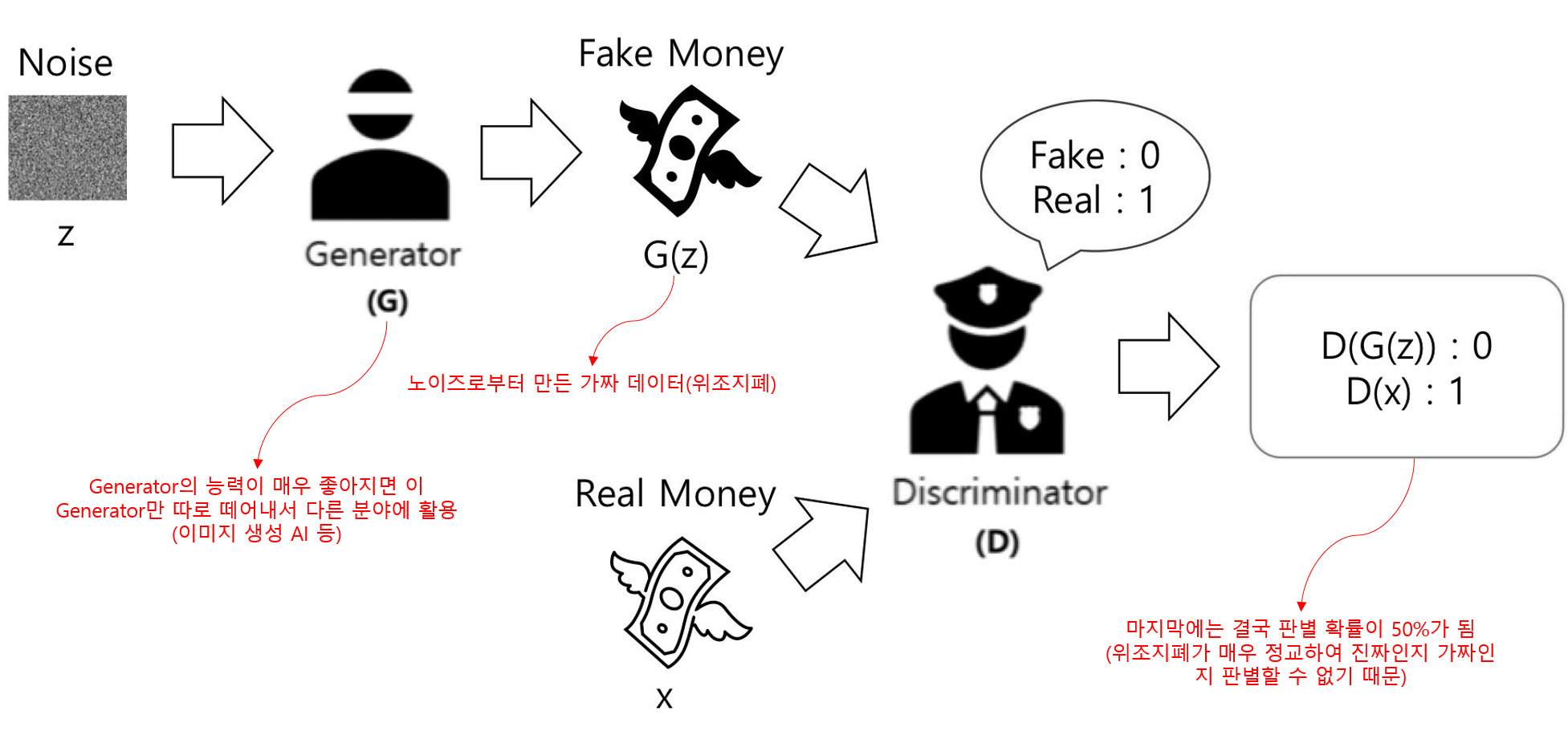 처음 범인의 위조지폐 생성 능력은 매우 낮아 경찰관은 이것을 쉽게 판별할 수 있을 것이다. 그 후에 범인이 생성 능력을 향상시킬수록 판별하기 어려워지므로 경찰관 또한 위조지폐 판별 능력을 향상시키게 된다. 즉, 서로 간의 경쟁을 하게 되는 것이다.
처음 범인의 위조지폐 생성 능력은 매우 낮아 경찰관은 이것을 쉽게 판별할 수 있을 것이다. 그 후에 범인이 생성 능력을 향상시킬수록 판별하기 어려워지므로 경찰관 또한 위조지폐 판별 능력을 향상시키게 된다. 즉, 서로 간의 경쟁을 하게 되는 것이다.
이렇게 경쟁을 통해 서로의 능력이 향상되게 되고, 결국 위조지폐범의 생성 능력이 매우 정교해지기 때문에 경찰관이 진짜 지폐인지 위조지폐인지 판별할 수 없어 찍어야 하는 상황이 발생하게 된다. 판별 확률이 50%가 된다는 말이다.
Loss function
 GAN 모델의 Loss function은 위와 같다. 위 loss funtion의 범위는 부터 까지이다.
GAN 모델의 Loss function은 위와 같다. 위 loss funtion의 범위는 부터 까지이다.
첫번째 항은 실제 데이터를 Discriminator에 넣었을 때 나온 결과를에 log를 취했을 때 얻을 수 있는 기댓값이고,
두번째 항은 Generator로부터 만들어진 가짜 데이터를 Discriminator에 넣은 결과를 log(1-결과)fmf 취했을 때 얻을 수 있는 기댓값이다.
이를 Discriminator와 Generator의 관점을 따로 나눠서 생각해보겠다.
Discriminator
Discriminator의 관점에서 최적의 조건은 실제 데이터를 Real로, 가짜 데이터를 Fake로 잘 판별하는 것(, )이다. 이를 위해선 가 1로 수렴하도록, 가 0으로 수렴하도록 Discriminator를 학습시켜야 할 것이다.
위처럼 , 이라면 해당 Loss function값은 최대값인 0으로 수렴하게 된다. 즉, Discriminator는 Loss funtion의 값이 최대가 되는 방향으로 학습을 진행하게 된다.
Generator
Generator의 관점에서는 실제 데이터에 관한 첫번째 항에는 관심이 없다. 즉, 는 신경쓰지 않는다. 그러므로 두번째 항만 고려한다.
Generator의 목표는 Discriminator가 Generator로부터 만들어진 가짜 데이터를 진짜라고 판별, 즉 인 것이다. 이라면 Loss function의 값은 최소값인 로 수렴하게 된다. 그러므로 Generator는 Loss function의 값이 최소값이 되도록 학습을 진행하게 된다.
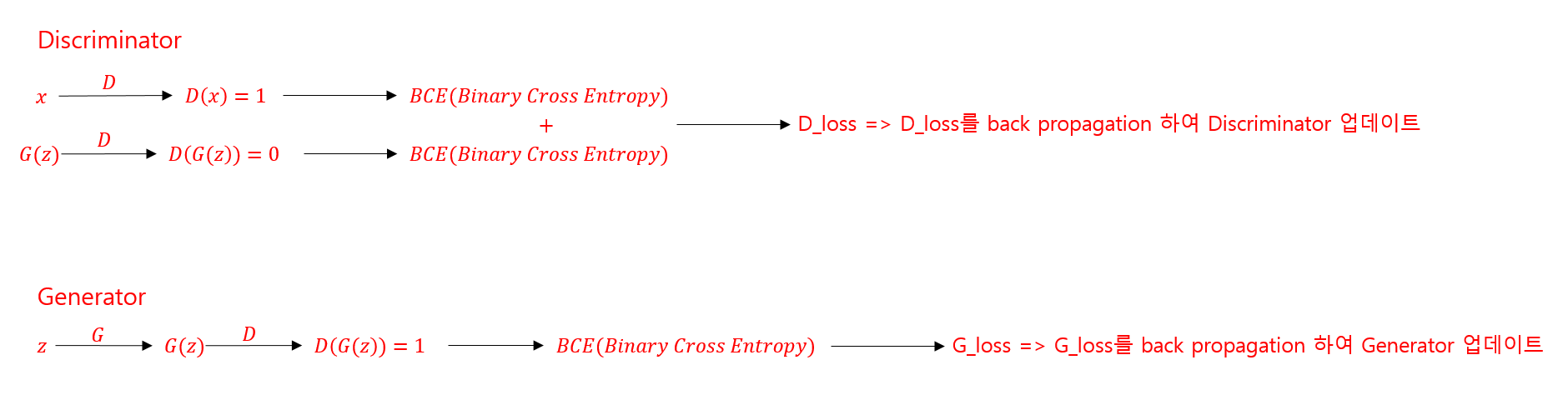
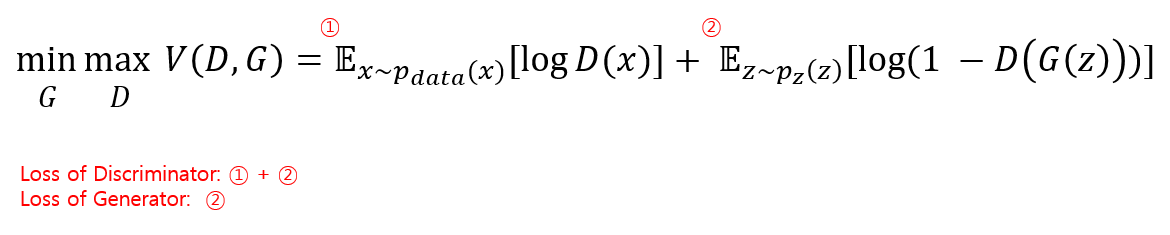 Generator와 Discriminator는 다른 모델이므로 이에 대한 Loss도 따로 계산해주어야 한다.
Generator와 Discriminator는 다른 모델이므로 이에 대한 Loss도 따로 계산해주어야 한다.
위 내용들을 요약하자면 아래와 같다.
DCGAN(Deep Convolutional Generative Adversarial Network)
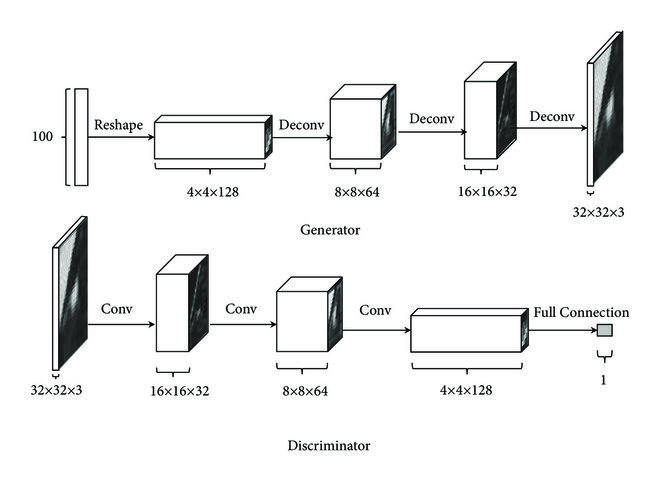
DCGAN은 Generator와 Discriminator에서 Fully connected layer가 아닌 Convolutional layer를 사용하는 모델이다. CNN의 특성으로 인해 공간적 정보를 더 잘 학습하여 DCGAN으로 만들어진 latent vector(noise)는 이미지의 연속성을 더 잘 표현한다.
Convolutional layer를 사용하지만 Polling layer는 사용하지 않는다. 대신 Strided convolutions를 사용한다.
또한 DCGAN을 통해 Batch normalization을 사용하여 GAN이 가지고 있던 안정성 문제를 어느정도 해결할 수 있다.
