
Segmentation
우리는 보통 여러 물체들이 존재하는 이미지를 보면 특정 픽셀이 어느 물체 종류에 속하는지 분류할 수 있다. 예를 들자면, 우리는 야외의 모습이 찍힌 이미지를 보고 하늘, 땅, 사람, 자동차 등을 분석해낼 수 있다.
Segmentation은 이미지 혹은 영상의 각각의 Pixel에 대해 분류 혹은 탐지를 하는 task를 의미한다.
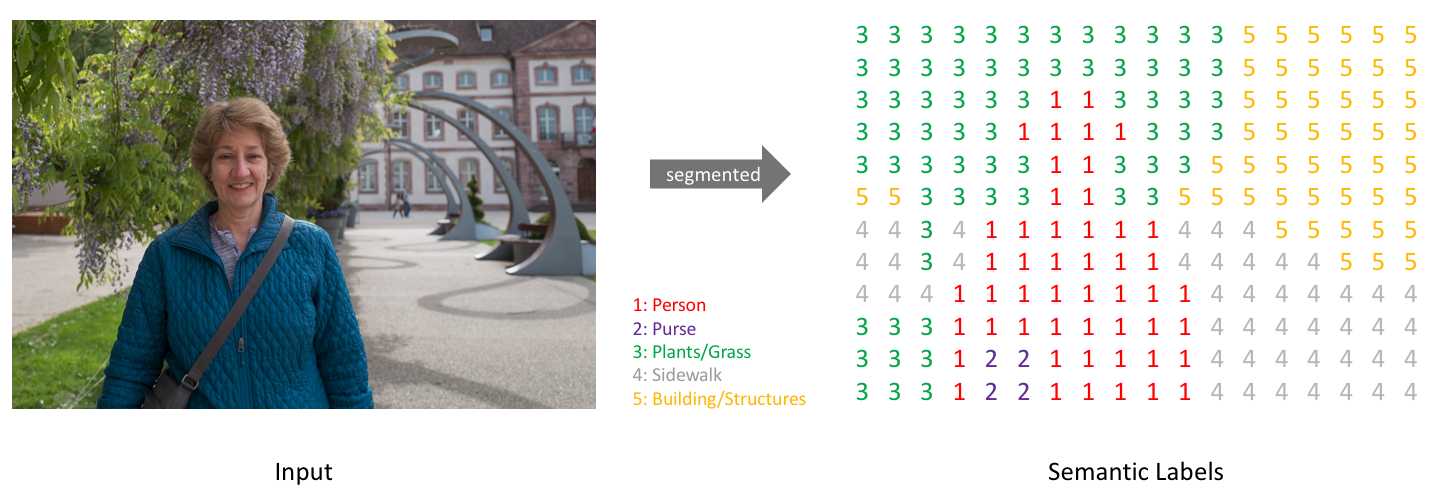 동일한 label을 가진 모든 픽셀이 동일한 Object 혹은 Class에 속하도록 각 Pixel에 label을 할당하는 프로세스를 따른다.
동일한 label을 가진 모든 픽셀이 동일한 Object 혹은 Class에 속하도록 각 Pixel에 label을 할당하는 프로세스를 따른다.
 Segmentation은 의료, 자율주행, 로봇공학, 위성사진 분석 등의 많은 분야에 활용된다.
Segmentation은 의료, 자율주행, 로봇공학, 위성사진 분석 등의 많은 분야에 활용된다.
Types of Segmentation
- Semantic Segmantation
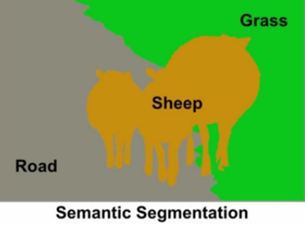 같은 Class 내에서 Instance를 구별하지 않는다.
같은 Class 내에서 Instance를 구별하지 않는다.
- Instance Segmentation
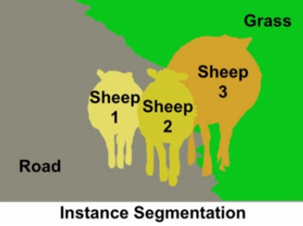 같은 Class 내에서도 Instance를 구분한다.
같은 Class 내에서도 Instance를 구분한다.
Segmentation Methods
Pixel-wise Classification
가장 단순한 방법으로, Pixel 하나하나 Classification 하는 방법이다. 학습이 효과적으로 진행된다면 가장 정확하고 강력한 방법이 될 수 있지만, 굉장히 비효율적이다. 만약 이미지 사이즈가 512 X 512 라고 가정하면, 한 장의 이미지를 학습하는 데에만 262,144번의 연산이 시행되어야 할 것이다.
Bilinear Interpolation
Interpolation이란, 알려진 지점의 값 사이에 위치한 값을 알려진 값으로부터 추정하는 것을 의미한다. 즉, 모든 픽셀들을 전부 학습하지 않고 몇 개 만을 학습한 후에 학습하지 않은 중간의 픽셀은 Interpolation으로 추정한다.
모든 픽셀들을 전부 학습하지 않기 때문에 정확도는 다소 감소할 수 있어도, 계산량이 현저히 줄어들기 때문에 학습 효율성이 좋다.
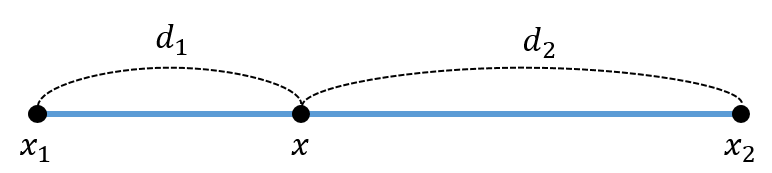 위 그림처럼 과 사이의 점 가 존재할 때, 점 의 데이터값 은 아래와 같다.
위 그림처럼 과 사이의 점 가 존재할 때, 점 의 데이터값 은 아래와 같다.
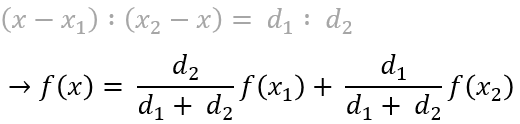 이때 와 는 과 의 데이터 값이다.
이때 와 는 과 의 데이터 값이다.
이를 2차원으로 확대하면 아래와 같다.
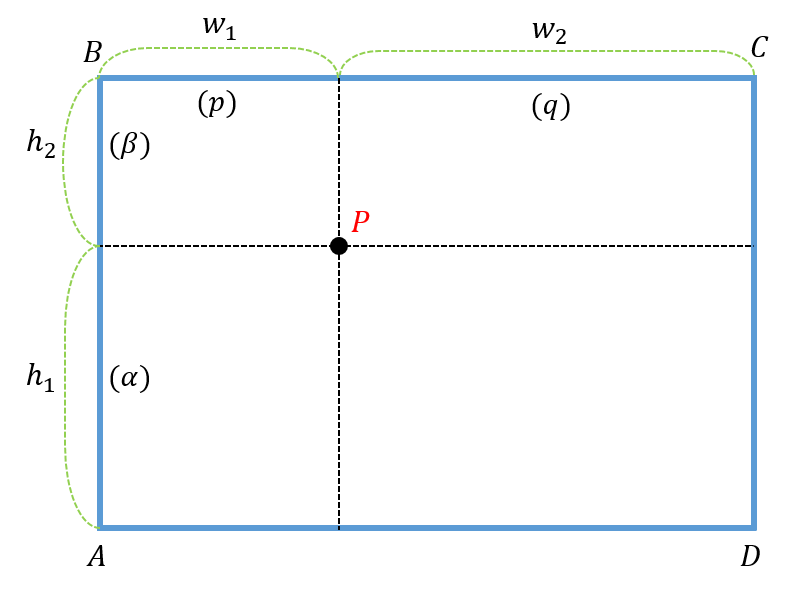 이때 P의 데이터값은 아래의 식을 통해 구할 수 있다.
이때 P의 데이터값은 아래의 식을 통해 구할 수 있다.
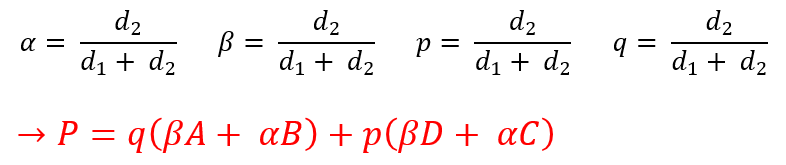
Convolution-based Models
Bilinear Interpolation 방법 만으로는 한계가 있으므로 Convolution 기법을 추가하는 방식이다.
이때 VGG, Resnet 등 Classification task에서 쓰이는 Model들은 Sementic Segmentation에서는 적합하지 않다.
위치 정보를 잃지 않기 위해 Pooling과 Fully Connected Layer 등을 없애고 Stride와 Padding을 일정하게 한다고 하면, 학습량이 너무 많아지기 때문에 비효율적이다.
그러므로 Downsampling과 Upsampling을 활용한다.
 보통 Downsampling을 Encoder, Upsampling을 Decoder라고 부른다.
보통 Downsampling을 Encoder, Upsampling을 Decoder라고 부른다.
Encoder를 통해 입력 받은 이미지의 정보를 벡터로 압축시키고, Decoder를 통해서 원하는 결과물로 다시 확대한다.
Encoder: 차원을 줄여서 적은 메모리로 Convolution 연산을 할 수 있다. 주로 Convolutional Layer와 Pooling Layer를 이용한다.
Decoder: Encoder를 통해 축소된 데이터의 차원을 다시 늘려서 입력 데이터와 같은 차원으로 만드는 과정이 일어난다. 주로 Transposed Convolution 연산과 관련된 Transpose Convolutional Layer을 이용한다.
아래에 Transposed Convolution 연산에 대해 간단히 설명하겠다.
Transposed Convolution
Transposed Convolution 연산은 Convolution 연산과 반대로 Upsampling 과정을 수행할 수 있다. 즉, Input Data에 비해 Output Data의 차원이 커지게 된다.
Pytorch의 nn.ConvTranspose2d를 통해 Transpose Convolution Layer를 구현할 수 있다.
nn.ConvTranspose2d도 nn.Conv2d처럼 Kernel, Stride, Padding과 같은 Parameter들을 이용하는 것은 같다. 하지만 연산과정에서는 약간의 차이가 있다.
만약 Input Data의 Shape가 (2, 2, 1), Kernel의 Shape가 (3, 3, 1), Stride = 1, Padding = 1 인 경우의 연산의 양상은 아래와 같다.
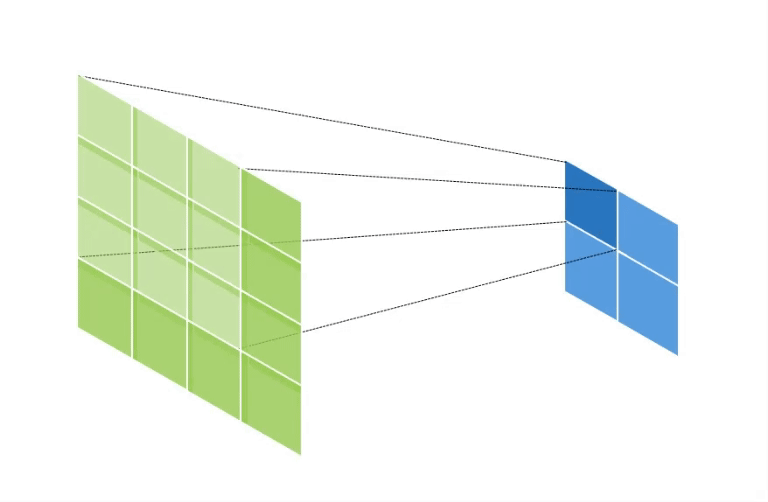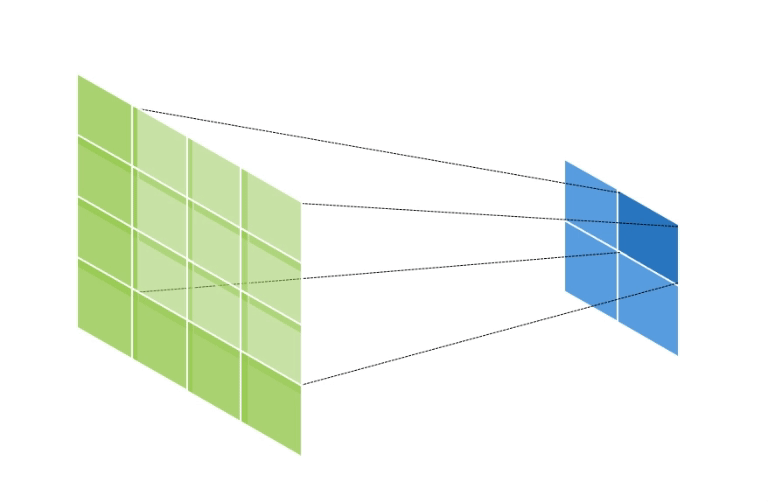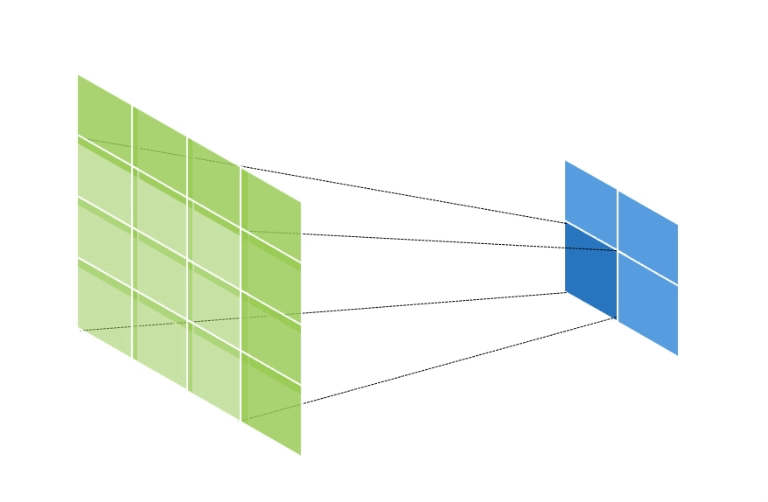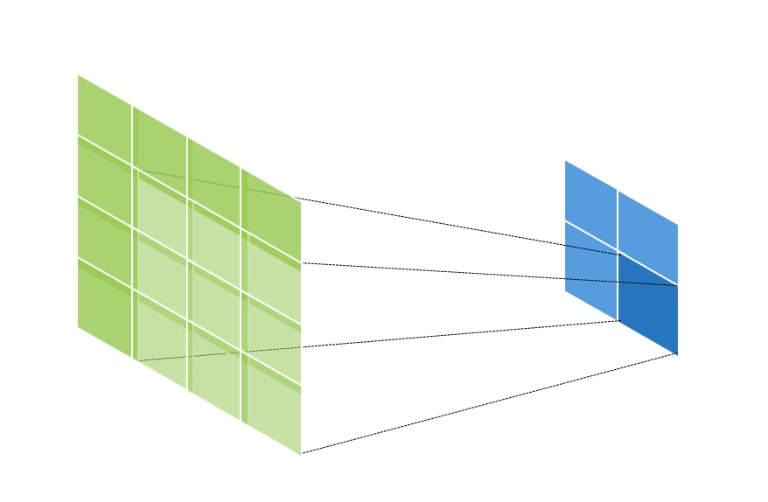 초록색은 Output Data이고, 파란색은 Input Data이다.
초록색은 Output Data이고, 파란색은 Input Data이다.
이와 같이 Output Data의 크기가 Input Data에 비해 증가하게 된다.
Output Data의 한 변의 크기를 구하는 공식은 아래와 같다.
Input Data의 크기:
Output Data의 크기:
Kernel의 크기:
Stride:
Padding:
다시 돌아와서, Encoder - Decoder 구조를 가지는 대표적인 모델은 FCN(Fully Convolutional Network), U-Net 등이다.
FCN(Fully Convolutional Network)
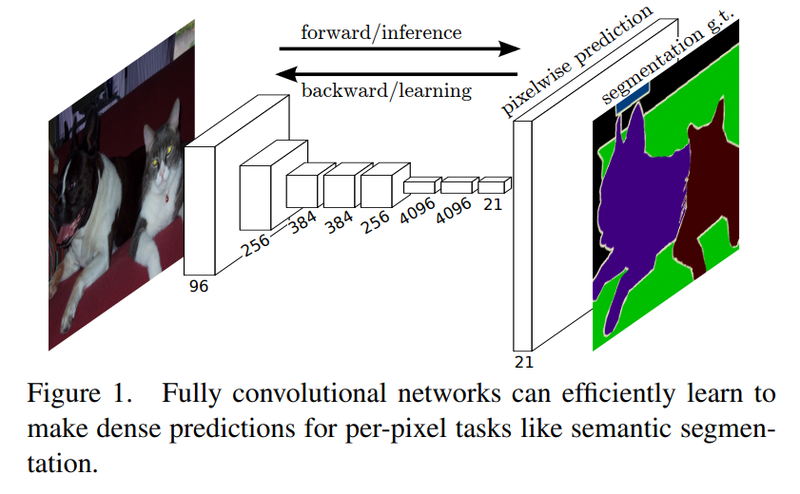 FCN(Fully Convolutional Network)은 Semantic Segmentation을 위해 Image Classification에서 우수한 성능을 보인 CNN 기반 모델, 예를 들면 AlexNet, VGG16 등과 같은 모델을 목적에 맞춰 변형시킨 것이다.
FCN(Fully Convolutional Network)은 Semantic Segmentation을 위해 Image Classification에서 우수한 성능을 보인 CNN 기반 모델, 예를 들면 AlexNet, VGG16 등과 같은 모델을 목적에 맞춰 변형시킨 것이다.
기존의 Image Classification에서 사용한 Fully Connected Layer의 위치 정보 소실 문제를 방지하기 위해 모든 Fully Connected Layer를 Convolutional Layer로 대체하였다.
또한 Transfer Learning을 이용한다.
Transfer Learning
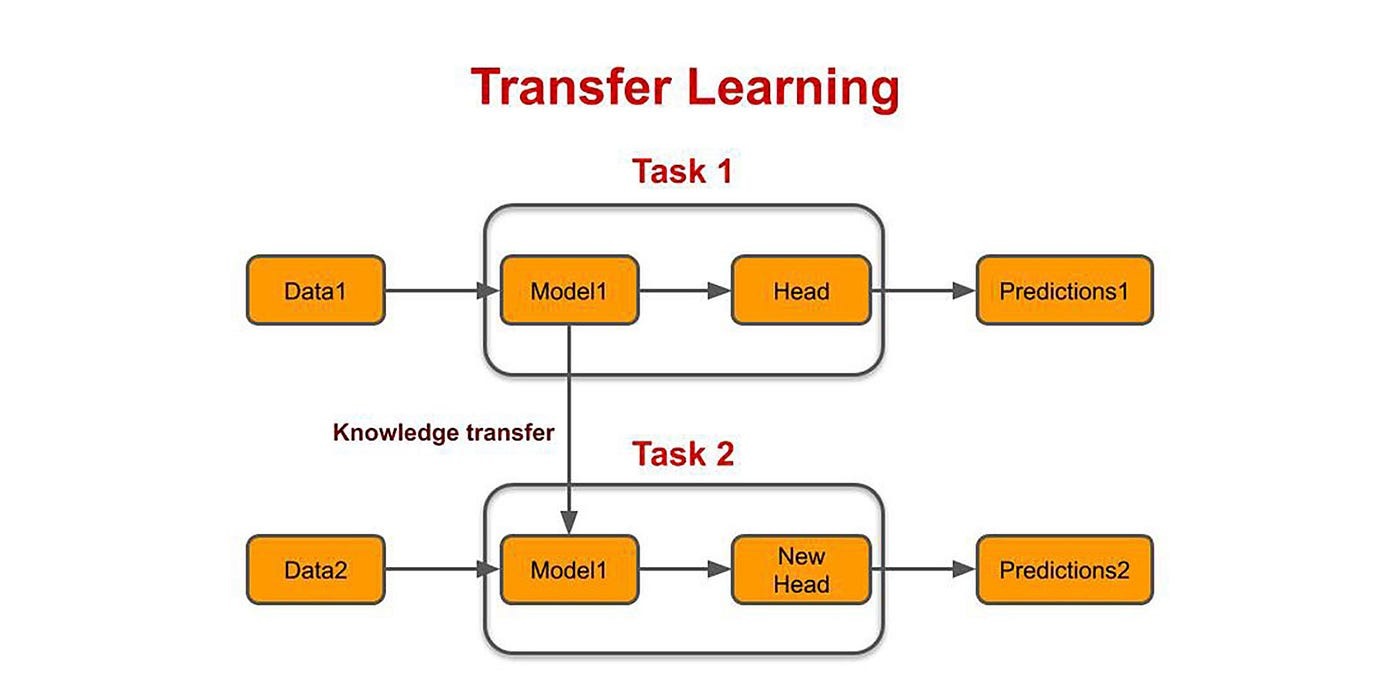 Transfer Learning은 기존에 Pre-trained된 Model을 가져와 사용하고자 하는 학습 데이터를 학습시켜 이용하는 방법이다. 기존에 비슷한 분야의 데이터를 학습한 Model이라면 현재 갖고있는 데이터의 양이 다소 적더라도 좋은 성능을 보여줄 수 있다.
Transfer Learning은 기존에 Pre-trained된 Model을 가져와 사용하고자 하는 학습 데이터를 학습시켜 이용하는 방법이다. 기존에 비슷한 분야의 데이터를 학습한 Model이라면 현재 갖고있는 데이터의 양이 다소 적더라도 좋은 성능을 보여줄 수 있다.
Pre-trained된 Model을 기반으로 최종 Output Layer를 바꾼 후에 이 Layer의 파라미터를 사용하고자 하는 소량의 데이터를 통해 학습시킨다.
Input Layer에 가까운 부분의 파라미터는 학습하지 않는다.
이와 비슷한 개념인 Fine-Tuning은 Transfer Learning의 한 부분으로, Pre-trained된 Model의 파라미터들을 새로운 Task에 맞게 조정하는 과정이다.
그치만 Transfer Learning과 달리, 모든 Layer들의 파라미터가 다시 재학습된다.
다시 FCN 설명으로 돌아와서, VGG16으로부터 Transfer Learning을 사용하는 것을 예시로 들며 설명해보겠다.
VGG16의 마지막 Layer인 Fully Connected Layer를 1 X 1 Size의 Convolutional Layer로 변경하고, 그 후에 Transpose Layer를 통해 입력 이미지와 동일한 사이즈로 Decoding 한다.
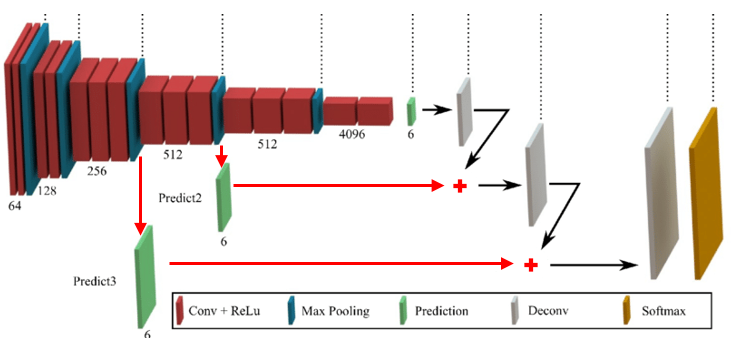 또한 Skip Connection 구조를 추가한다.
또한 Skip Connection 구조를 추가한다.
Skip Connection 구조를 통해 학습 진행 중간중간에 정보를 추출하기 때문에 Convolution, Pooling 연산으로 인해 압축되며 소실되는 중요한 정보를 어느정도 Save 할 수 있다.
U-Net
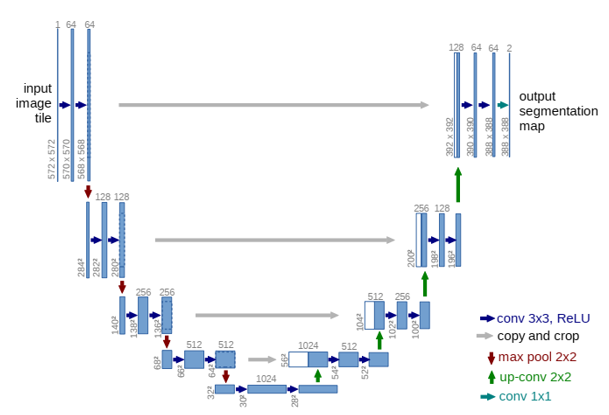 U-Net은 신경망 구조 중간에 Skip Connection을 평행하게 두고 중간을 기준으로 좌우가 대칭하도록 Layer들을 배치하여 U자 형태를 가지는 Network이다.
U-Net은 신경망 구조 중간에 Skip Connection을 평행하게 두고 중간을 기준으로 좌우가 대칭하도록 Layer들을 배치하여 U자 형태를 가지는 Network이다.
입력 이미지가 입력되면, 먼저 여러 Convolution Layer와 Pooling Layer를 통해 이미지의 크기를 점차 줄이면서 특징을 추출한다.
그 후, 축소된 이미지로부터 점진적으로 다시 크기를 복원하는 Decoder를 통해 원래 이미지로 돌아간다. 이때 Skip Connection 구조를 통해 Encoder의 세부 정보를 Decoder에 직접 전달하여 더 나은 분할 결과를 얻을 수 있다.
최종 Output은 각 Pixel에 대해 분할된 Class 레이블을 갖는 Segmentation Map이다.
