U-Net
U-Net은 의료영상 분야에서 Image Segmentation을 목적으로 제안된 Convolutional Neural Network 구조이다.
주로 CT나 MRI와 같은 의료 이미지에서 장기나 병변의 윤곽을 정확히 분할하는 데 널리 사용되고 있다.
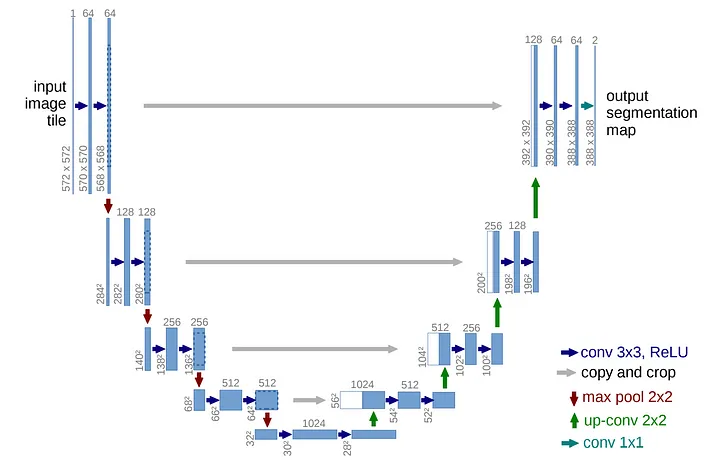 Model의 이름이 U-Net인 이유는 위 그림처럼 Model의 구조가 U자 형태이기 때문이다.
Model의 이름이 U-Net인 이유는 위 그림처럼 Model의 구조가 U자 형태이기 때문이다.
U-Net의 구조
U-Net의 구조는 크게 3부분으로 나눌 수 있다.
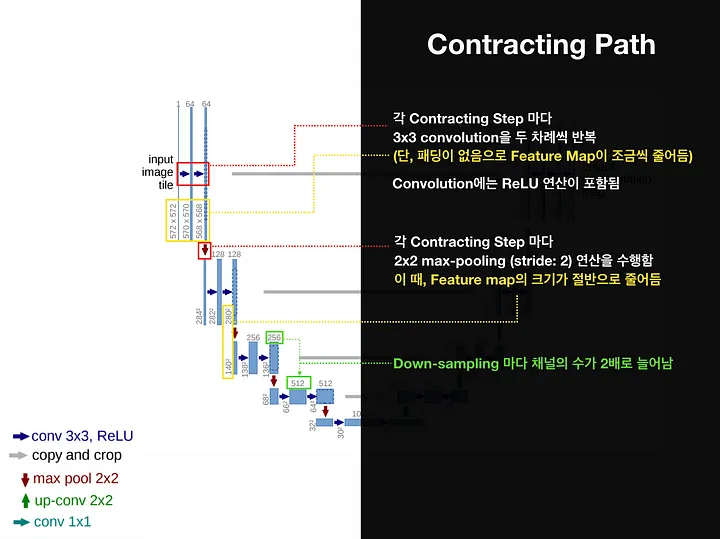
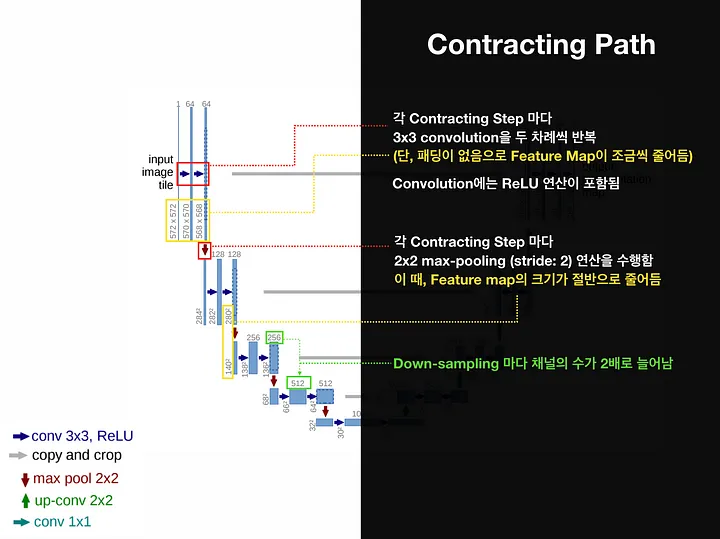
1) 수축 경로(Contraction Path): 입력 이미지에서 점진적으로 넓은 범위의 이미지 픽셀을 보며 의미정보(Context Information)를 추출하는 경로
2) 전환 구간(Bottle Neck): 수축 경로에서 확장 경로로 전환되는 구간
3) 확장 경로(Expanding Path): 의미정보를 픽셀 위치정보와 결합하여 각 픽셀마다 어떤 객체에 속하는지 구분하는 경로
Model의 Input은 이미지의 픽셀별 RGB 데이터이고, Model의 Output은 이미지의 각 픽셀별 객체 구분 정보(Class)이다.
연산과정에서 Padding 연산이 이루어지지 않으므로 Model의 Output Size는 Input Size보다 작다.
수축 경로(Contraction Path)
수축 경로는 주변 픽셀들을 참조하는 범위를 넓혀가며 이미지로부터 의미정보를 추출하는 역할을 한다.
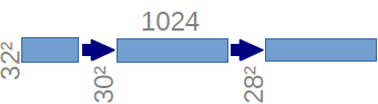
 Downsampling을 할 때 마다 Channel의 수를 2배 증가시키면서 진행한다.
Downsampling을 할 때 마다 Channel의 수를 2배 증가시키면서 진행한다.
활성화 함수는 ReLu를 사용한다.
따라서 아래와 같은 Downsampling 과정을 반복하여 Feature Map을 생성한다.
-
3 X 3 Convolutional Layer + ReLu + BatchNorm (No Padding, Stride = 1)
-
3 X 3 Convolutional Layer + ReLu + BatchNorm (No Padding, Stride = 1)
-
2 X 2 Max-Polling Layer (Stride = 2)
전환 구간(Bottle Neck)
전환 구간은 수축 경로에서 확장 경로로 전환되는 구간이다.
Dropout Layer를 사용하며, 이는 Model을 일반화하고 노이즈에 견고하게 만들어주는 역할을 한다.
아래와 같은 과정을 따른다.
-
3 X 3 Convolutional Layer + ReLu + BatchNorm (No Padding, Stride = 1)
-
3 X 3 Convolutional Layer + ReLu + BatchNorm (No Padding, Stride = 1)
-
Dropout Layer
확장 경로(Expanding Path)
확장 경로는 의미정보를 픽셀 위치정보와 결합하여 각 픽셀마다 어떤 객체에 속하는지 구분하는 역할을 한다.
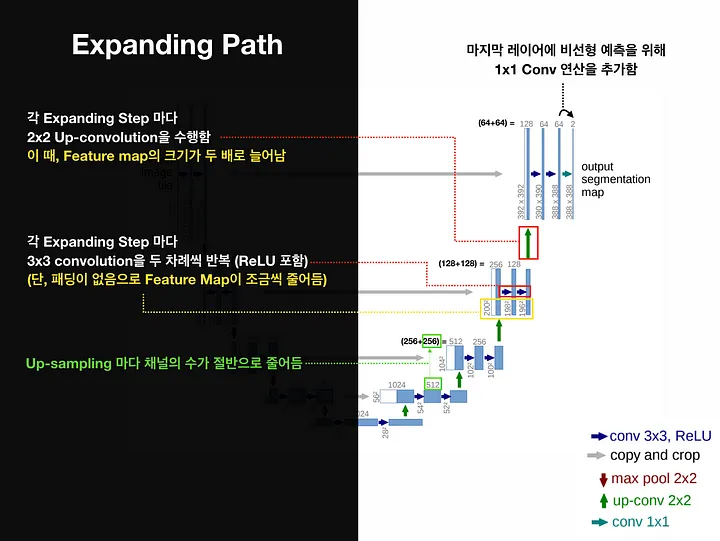 동일한 Level에서 수축경로의 Feature Map과 확장경로의 Feature Map의 크기가 다른 이뉴는 여러번의 Padding이 없는 3 X 3 Convolutional Layer를 지나면서 Feature Map의 크기가 감소했기 때문이다.
동일한 Level에서 수축경로의 Feature Map과 확장경로의 Feature Map의 크기가 다른 이뉴는 여러번의 Padding이 없는 3 X 3 Convolutional Layer를 지나면서 Feature Map의 크기가 감소했기 때문이다.
 마지막 Layer는 Class의 개수만큼 필터를 갖고 있는 1 X 1 Convolutional Layer이다.
마지막 Layer는 Class의 개수만큼 필터를 갖고 있는 1 X 1 Convolutional Layer이다.
활성화 함수는 ReLu를 사용한다.
따라서 아래와 같은 Upsampling 과정을 반복하여 Feature Map을 생성한다.
-
2 X 2 Deconvolutional Layer
-
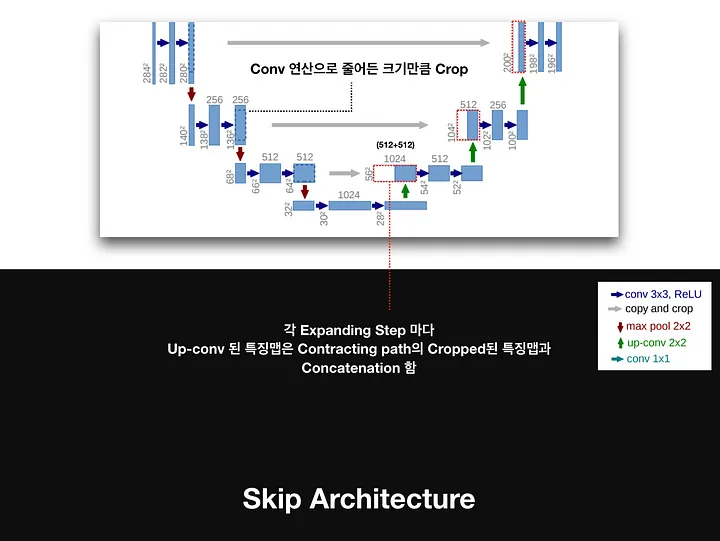
수축 경로에서 동일한 Level의 Feature Map을 추출하고 크기를 맞추기 위하여 Crop한 후, 이전 Layer에서 생성된 Feature Map과 Concatenation(Skip Connection)
-
3 X 3 Convolutional Layer + ReLu + BatchNorm (No Padding, Stride = 1)
-
3 X 3 Convolutional Layer + ReLu + BatchNorm (No Padding, Stride = 1)
학습 방법
U-Net의 논문에서는 다양한 방법들을 통해 Model의 성능을 향상시켰다.
1) Overlap-tile Strategy: 큰 이미지를 겹치는 부분이 있도록 일정크기로 나누고 모델의 Input으로 활용
2) Mirroring Extrapolate: 이미지의 경계 부분을 거울에 반사된 것 처럼 확장하여 Input으로 활용
3) Weight Loss: Model이 객체간 경계를 구분할 수 있도록 Weight Loss를 구성하고 학습
4) Data Augmentation: 적은 데이터로도 잘 학습할 수 있도록 데이터 증강 방법 활용
Overlap-tile Strategy
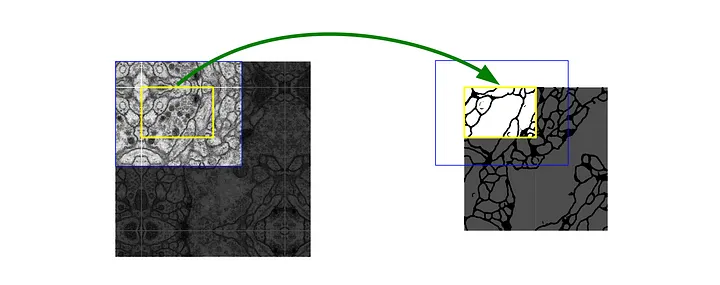 위 그림처럼 이미지를 Tile로 나눠서 입력으로 사용한다. Input과 Output의 이미지 크기가 다르기 때문에 파란색 영역의 이미지를 입력하면 노란색 영역의 Segmentation 결과를 얻는다.
위 그림처럼 이미지를 Tile로 나눠서 입력으로 사용한다. Input과 Output의 이미지 크기가 다르기 때문에 파란색 영역의 이미지를 입력하면 노란색 영역의 Segmentation 결과를 얻는다.
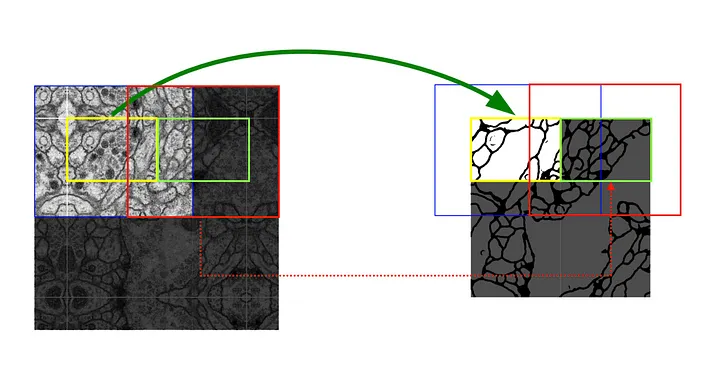 다음 Tile에 대한 Segmentation 결과를 얻기 위해서는 빨간색 영역을 Input으로 사용해야 한다. 즉, 겹치는 부분이 존재하도록 이미지를 자리고 Segmentation 하기 때문에 Overlap-tile 전략이라고 지칭한다.
다음 Tile에 대한 Segmentation 결과를 얻기 위해서는 빨간색 영역을 Input으로 사용해야 한다. 즉, 겹치는 부분이 존재하도록 이미지를 자리고 Segmentation 하기 때문에 Overlap-tile 전략이라고 지칭한다.
Mirroring Extrapolate
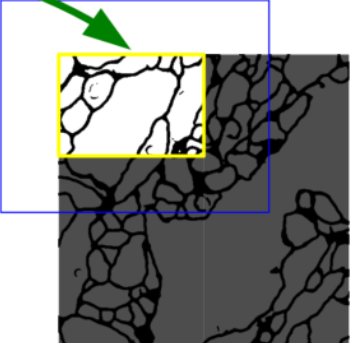 Overlap-tile Strategy 부분에서 설명한 것처럼 파란색 영역의 이미지를 입력하면 노란색 영역의 결과를 얻는다.
Overlap-tile Strategy 부분에서 설명한 것처럼 파란색 영역의 이미지를 입력하면 노란색 영역의 결과를 얻는다.
이때 위 그림처럼 파란색 영역에 빈 공간이 생기게 된다.
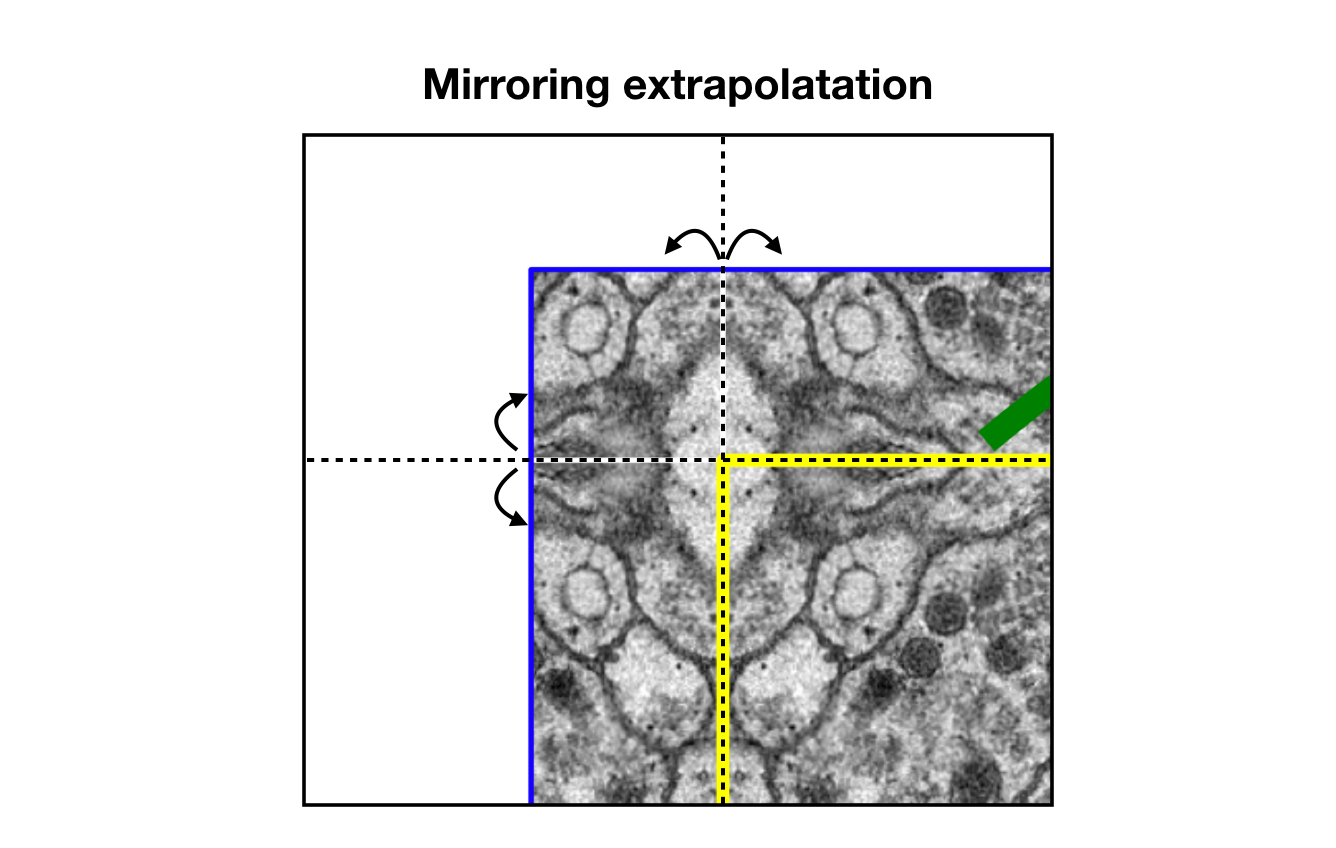 Mirroring Extrapolate는 이 빈 공간을 노란색 영역이 거울에 반사된 형태로 채우는 방법이다.
Mirroring Extrapolate는 이 빈 공간을 노란색 영역이 거울에 반사된 형태로 채우는 방법이다.
Weight Loss
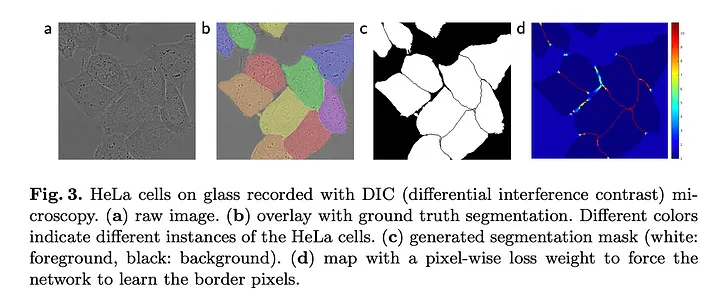 세포 Segmentation과 같은 작업에서 중요한 것은 동일한 클래스의 접촉 개체를 분리하는 것이다.
세포 Segmentation과 같은 작업에서 중요한 것은 동일한 클래스의 접촉 개체를 분리하는 것이다.
그러므로 모델은 위 그림처럼 작은 경계를 잘 분리할 수 있도록 학습되어야 한다.
따라서 U-Net 논문에서는 각 픽셀이 경계와 얼마나 가까운지에 따른 Weight Map을 만들고, 학습할 때 경계에 가까운 픽셀의 Loss를 Weight Map에 비례하게 증가시킴으로써 경계를 잘 학습하도록 설계하였다.
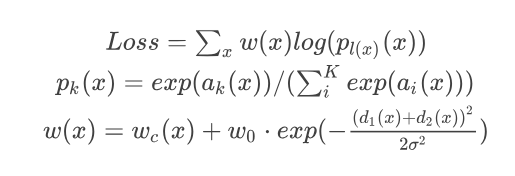
: 픽셀 가 Class k일 값(픽셀 별 모델의 Output)
: 픽셀 가 Class k일 확률(0~1)
: 픽셀 의 실제 Label
: 논문의 Weight hyper-parameter, 논문에서 10으로 설정
σ : 논문의 Weight hyper-parameter, 논문에서 5로 설정
: 픽셀 의 위치로부터 가장 가까운 경계와 거리
: 픽셀 의 위치로부터 두번째로 가까운 경계와 거리
는 픽셀 와의 경계의 거리가 가까우면 큰 값을 갖게 되므로 해당 픽셀의 Loss 비중이 커지게 된다.
그러므로 학습 시에 경계에 해당하는 픽셀을 잘 학습할 수 있게 된다.
Data Augmentation
데이터의 양이 적기 때문에 데이터를 증강하여 Model의 성능을 향상시키고 Noise에 강건하도록 해야 한다.
증강 방법으로는 Rotation, Shift, Gray Value, Elastic Deformation 등이 있다.
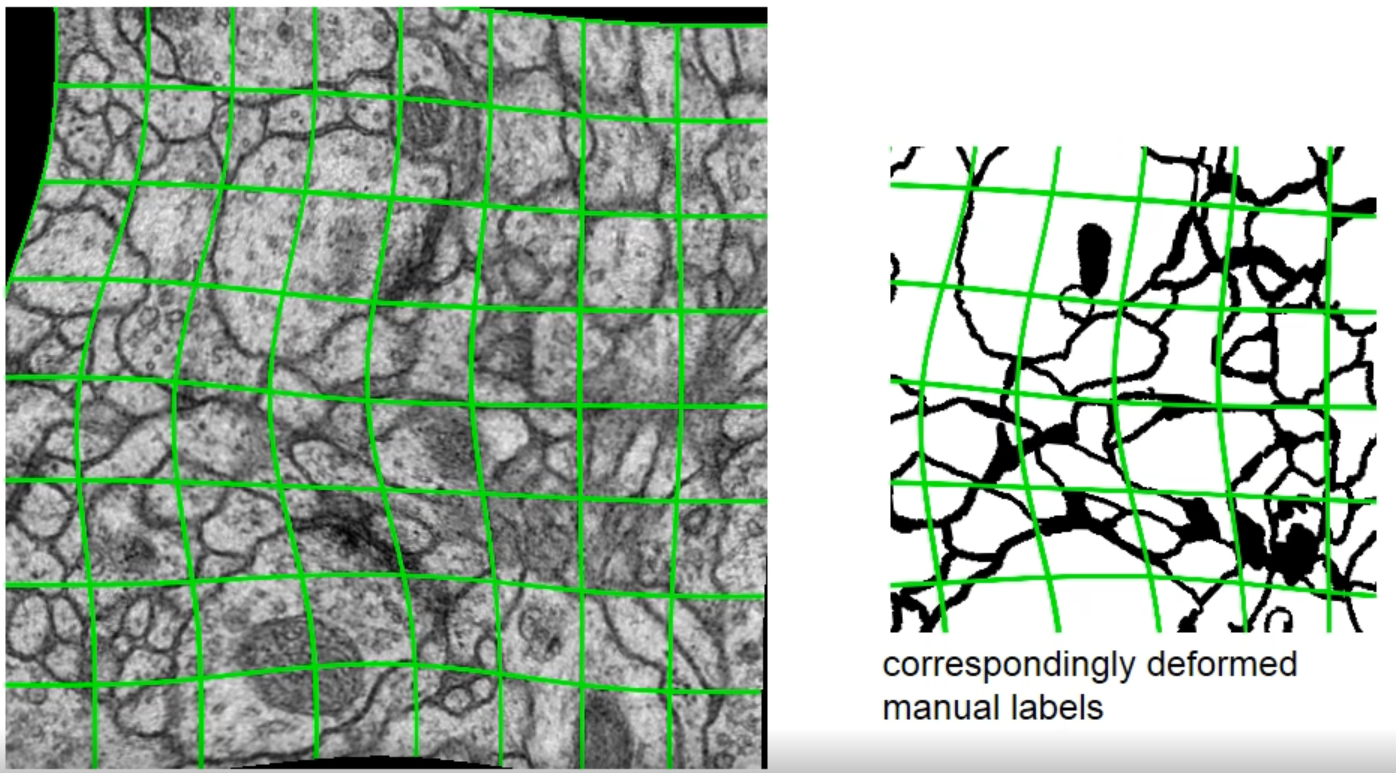 그 중 Elastic Deformation은 픽셀이 랜덤하게 다른 방향이르 뒤틀리도록 변형하는 방식이다.
그 중 Elastic Deformation은 픽셀이 랜덤하게 다른 방향이르 뒤틀리도록 변형하는 방식이다.
Training
해당 논문의 저자들은 Loss function을 픽셀마다 구한 Energy Function의 총합으로 구현하였다.
픽셀의 예측값에 Softmax를 취하고, 여기에 Cross Entropy를 적용하였다.
그리고 Cross Entropy에 픽셀 고유의 Weight를 곱함으로써 픽셀의 Loss값을 계산하였다.
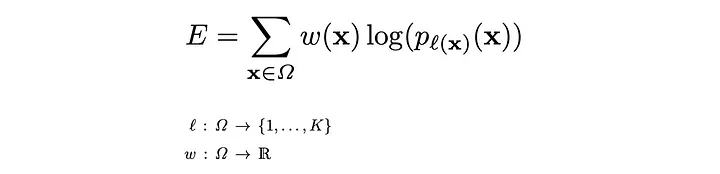
Reference
https://wikidocs.net/148870
https://joungheekim.github.io/2020/09/28/paper-review/
https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a
