CNN - Convolution은 무엇인가?
Convolution
- 2D image convolution
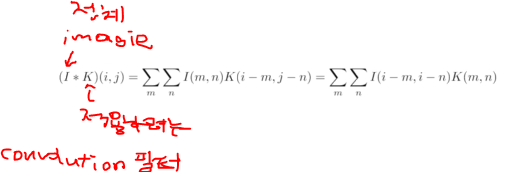
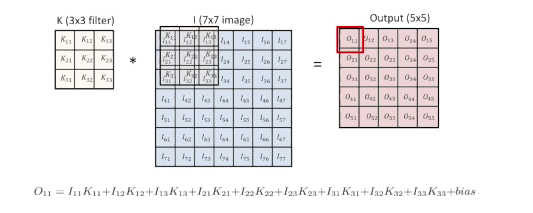
convolution한다는 것은 어떤 의미가 있을까?
- 해당 Convolution 필터 모양은 해당 이미지에서 찍는다고 했는데
즉, 적용하고자 하는 필터의 모양에 따라서 같은 이미지에 대해서 Convolution의 결과가 Blur가 될수 도 있고, emboss, Outline(외곽선만 따는 형태)이 될 수 있다
RGB Image Convolution
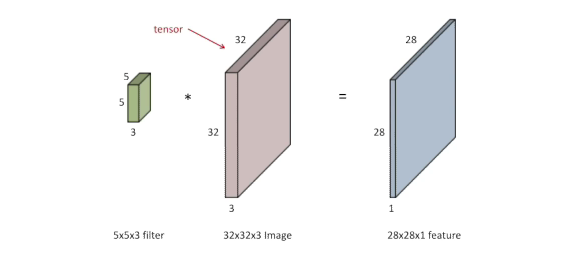
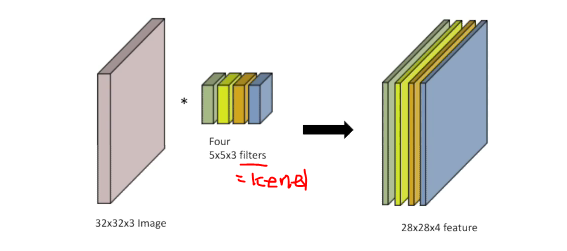
Stack of Convolution
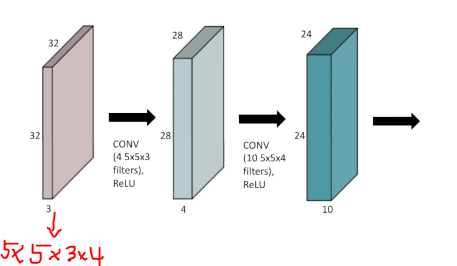
연산하는데 필요한 파라미터 숫자가 중요하다.
계산하는 방법: 필터 사이즈 input 채널 숫자 output 채널 숫자
Convolutional Neural Networks
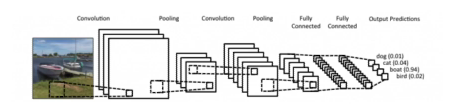
일반적인 CNN 구성
- Convolution layer: 도장을 찍듯이 이미지를 쭉 훑어서 값을 얻어내는 layer
- pooling layer: 2x2 pooling,average pooling, max pooling, etc
- 위 두 layer의 역할 feature extraction
- fully connected layer: 그걸 마지막에 다 합쳐서 내가 원하는 결과값을 만들어주는 layer
- decision making(ex. classfication)
- 요즘은 줄이고 없애는 추세(파라미터 수를 줄이기 위해서)
Stride
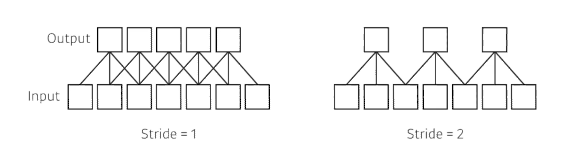
- stride=1 : 내가 가지고 있는 Convolution의 커널을 매 픽셀마다 찍는 것을 말함
- stride=2: 바로 다음 픽셀 찍는게 아니라 그 다음 픽셀을 찍는것
- stride라는 것은 Convolution의 필터를 얼마나 자주, dense하게(또는 sparse하게) 찍을지를 말함
Padding
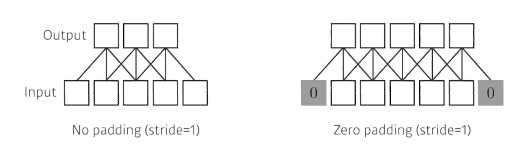
- Padding: 어떤 것을 덧대주는 역할
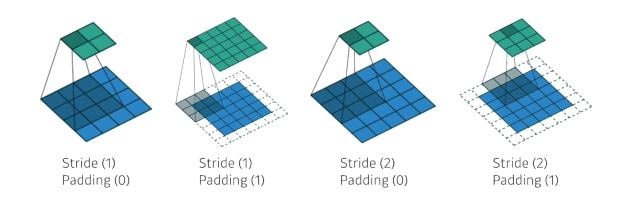
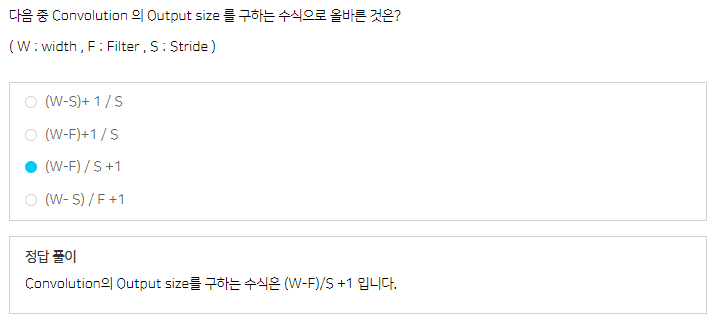
Convolution Arithmetic
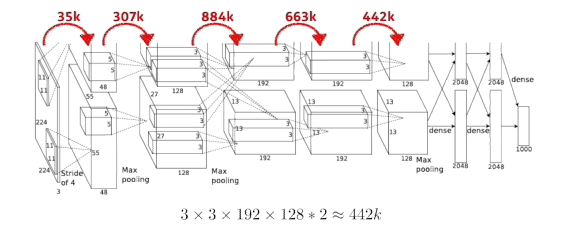
- convolution layer 파라미터 계산
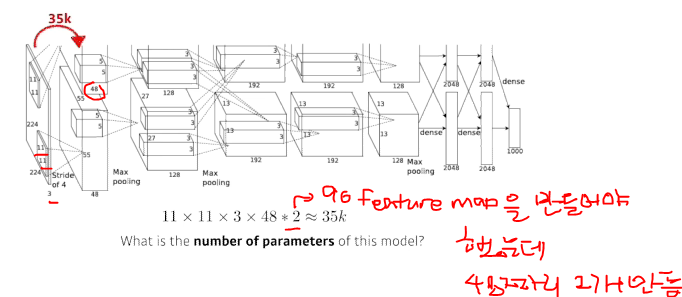
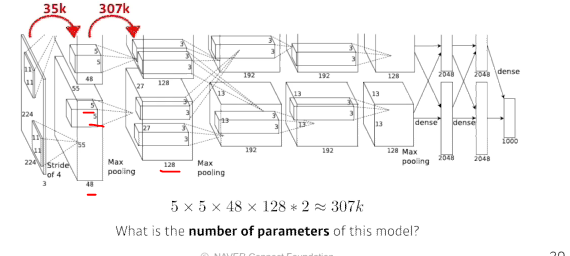
...
- Dense layer(fully connected layer)파라미터 계산
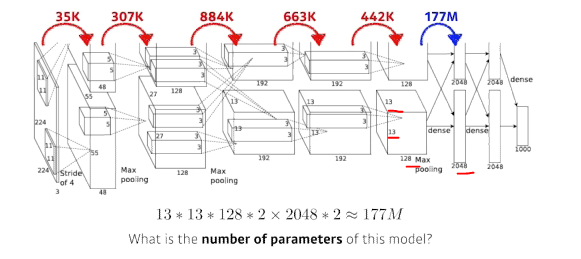
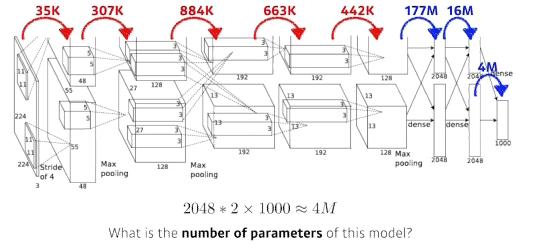
- convolution layer에 비해 1000배나 많다
- why? convolution 오퍼레이터가 각각의 하나의 커널이 모든 위치에 대해서 동일하게 적용되기 때문
- 학습을 잘하기 위해서 파라미터를 줄이는게 중요한기에 요즘은 convolution layer을 깊게 쌓게 fully connected layer은 얇게 쌓는것이 일반적인 트렌드(2020 ver)

1x1 convolution
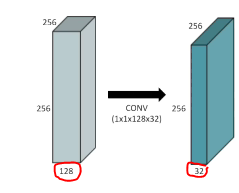
- 이미지에서 영역을 보지 않음(이미지에서 한 픽셀만 봄)
- 왜 할까?
- dimension(channel) reduction
- depth 방향으로 되어있는 채널을 줄임
- 파라미터를 줄이면서 깊이는 깊어짐
- dimension(channel) reduction
- ex)bottlenect architecture
Modern CNN - 1x1 convolution의 중요성
완전 modern하지 않음(2018년도까지)
파라미터의 숫자를 고려하면서 봐야함
AlexNet(2012)
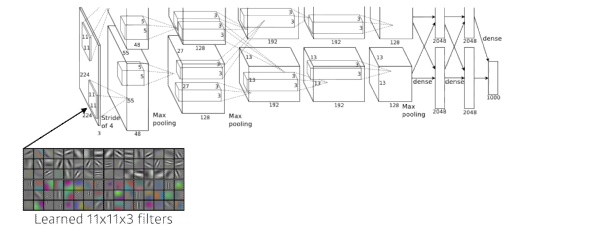

- 입력은 하나인데 네트워크가 2개로 나눠져 있음(GPU를 최대한 활용하는데 네트워크에 파라미터를 가능한대로 넣고 싶어서 2개의 gpu에 따로따로 훈련스킴)
- 11 X 11을 사용하는것은 좋은 선택은 아님(파라미터 수가 커지기 때문에)
- key ideas
- ReLu activation(효과적인 활성함수)
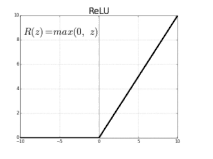
- 선형모델의 성질을 보존
- 경사하강법의 최적화가 쉬움
- 좋은 일반화
- 기울기 소실문제를 극복
- 2 GPU 사용
- Local response normalization(요즘은 잘 안씀), Overlapping pooling
- Data augumentation
- Dropout
- ReLu activation(효과적인 활성함수)
VGGNet(2014)
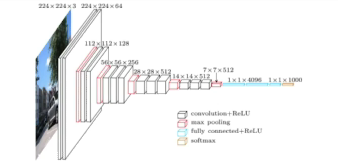
- 3 x 3 convolution 필터만 사용(with stride 1)
- 1x1 convolution for fully connected layer(별로 중요하지 않음)
- Dropout
- VGG16, VGG19
3 x 3 convolution 필터왜 사용했을까?
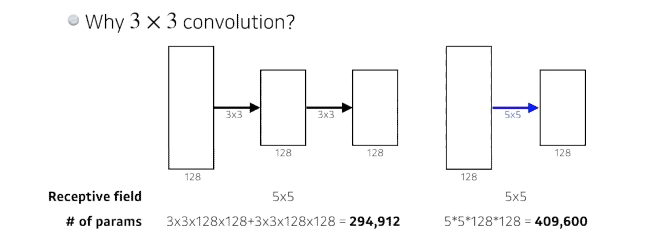
- 3 X 3, 5 X 5, 11x11 점점 커지면서의 이점은 하나의 convolution 필터가 찍었을때 고려되는 인풋의 크기가 커진다는 점(Receptive field)
- Receptive field: 하나의 convolution 피쳐 맵의 값을 얻기 위해서 고려할 수 있는 입력의 스페셜 demension
- 3 x 3을 두번 거쳐지게 되면 5 x 5의 Receptive field가 똑같음
- but, 파라미터 수는 5x5가 더 많다.
- 이런 이유 때문에 최근 논문들은 3x3 또는 5x5를 사용
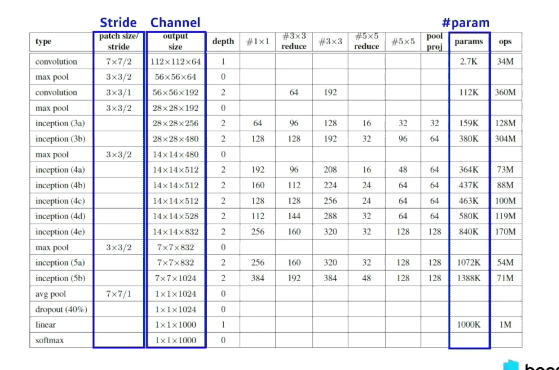
GoogLeNet(2014)
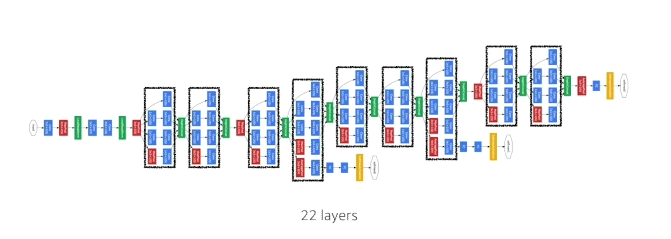
- 비슷해 보이는 구조가 반복되어있고, 이런 구조는 네트워크모양이 네트워크가 있다는 의미로
Networking network라고 한다. - Inception blocks
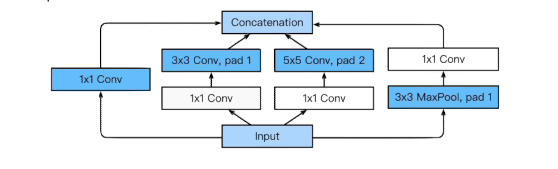
- 하나의 입력이 들어왔을때 여러개로 퍼졌다가 하나로 합쳐짐
- 왜 중요할까?
- 1x1 convolution가 중간에 껴있어서 전체적인 파라미터 수가 줄어듬
- 1x1 convolution가 더 들어가는데 왜 파라미터를 줄어들까?
- 1x1 convolution 채널방향으로 demension을 줄일 수 있음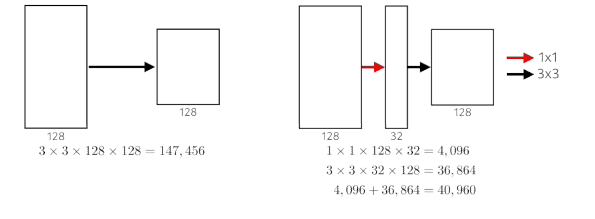

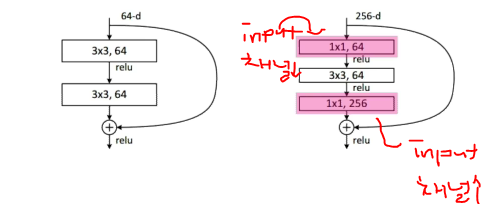
ResNet(2015)
일반적으로 파라미터가 많으면 overfitting이 일어남
- 네트워크가 커짐에 따라서 학습이 안되는 문제가 일어남
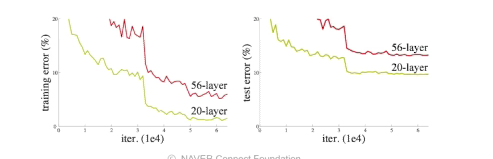
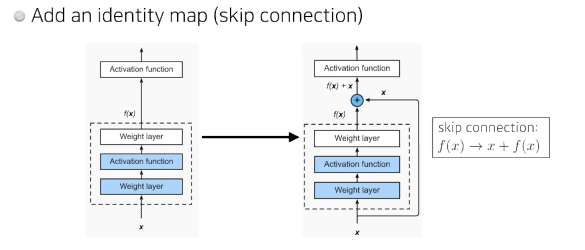
- x를 뉴럴네트워크 출력값 또는 한단짜리 convolution에 더해줌
- 궁극적으로 원하는건 convolution layer가 학습하고자 하는 quantity는 차이만 학습하는것
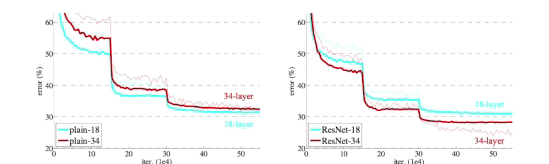
- 네트워크를 deep하게 쌓은게 더 학습이 잘됨
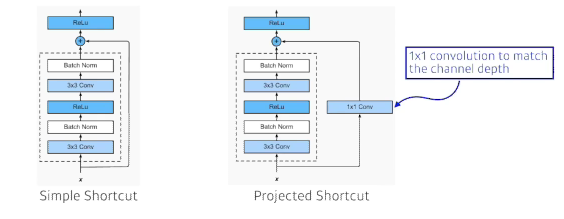
- projected shortcut -> 더할려면 차원이 같아야함
- 차원을 맞춰주기 위해서 1x1 convolution을 활용
- 일반적으로 simple shortcut을 사용
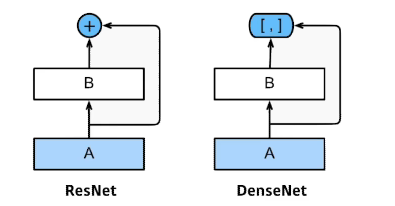
DenseNet
- ResNet처럼 더하지 말고 concatenation
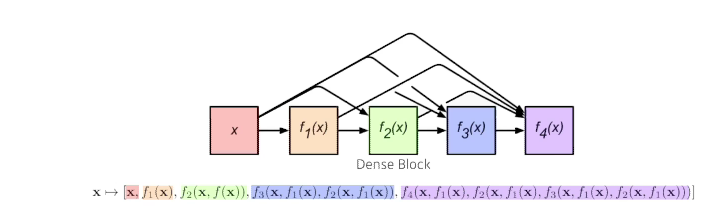
- 문제는 계속 concatenation하게 되면서 채널이 기하급수적으로 커짐
- 이 문제를 해결하기 위해 중간에 한번씩 채널을 줄여줌
- How? 1x1 convolution을 사용
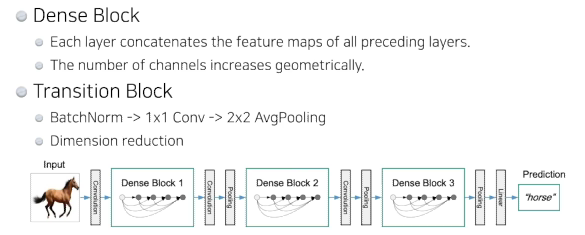

- How? 1x1 convolution을 사용

마루에 미친자