들어가며
이전까지 컨텐츠기반 필터링과, 협업 필터링에 대해 살펴보았다.
컨텐츠기반 필터링은 유사 상품의 특징을 추출하여 추천을 제시하는 것이고, 협업 필터링은 비슷한 유저들의 선호에 따라, 해당 유저도 이를 선호할 것이라고 예측, 추천하는 방식을 의미한다.
추천 방식에는 메모리 기반 추천방식, 모델 기반 추천 방식 크게 2가지로 분류할 수 있다.
메모리 기반 추천은 이웃 기반 추천 시스템이라고도 하며, 협업필터링, 컨텐츠기반 필터링이 대표적이다. 이러한 방식들은 구현이 간단하고 직관적이지만, interaction 행렬에서 직접 연산을 수행하기 때문에 스케일이 큰 시스템에서는 적절하지 않다. 그리고 단순 유사도를 계산하는 방식이기 때문에 주변 정보를 반영하지 못하는 단점도 있다.
반대로 모델 기반의 추천은 머신러닝모델 기반의 추천이라고 하며, 다량의 데이터로 학습한 모델을 통해 리소스를 효율적으로 추천할 수 있다.
정해진 패턴의 피처를 학습하여 대용량 데이터를 효율적으로 처리할 수 있다. 또한 interaction 외에 유저, 아이템의 피처정보를 유연하게 활용하여 복잡한 패턴을 포착할 수 있고, 높은 성능을 얻을 수 있다.
데이터 기반 모델 학습의 직관
사람의 일(판단)을 기계에게 시켜보자

"누런 색 바탕에, 검은색 점이 3개 있는 이미지를 치와와라고 분류 하자" 라고 했을 때, 단순한 규칙을 설정하게 되면 정확하게 구별되지 않는 문제점이 발생한다.
"강아지 처럼 생긴 동물에 줄무늬가 있으면, 호랑이라고 인식하자"라고 있을 때 쇠창살 그림자가 드리워진 강아지를 호랑이라고 인식하는 오분류 사례가 발생한다.
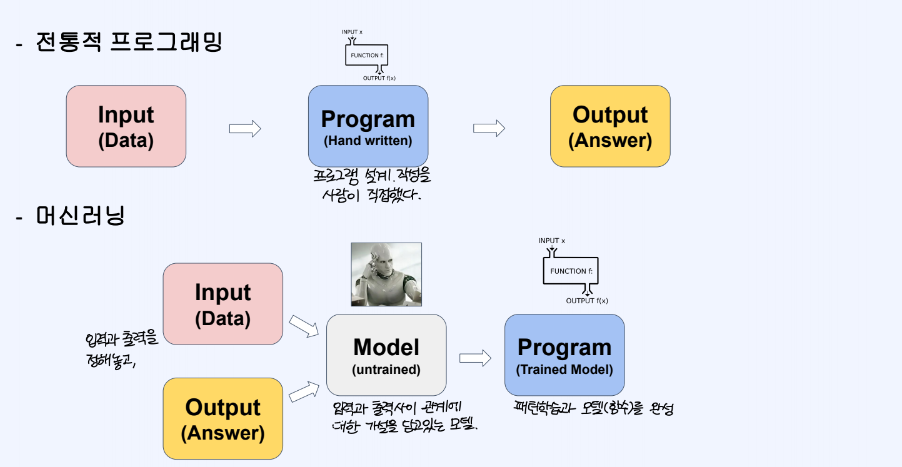
전통적인 프로그래밍은 사람이 프로그램 설계 및 규칙 작성을 수작업으로 하였지만, 머신러닝은 입력과 출력을 정해놓고, 모델이 입력과 출력 사이의 관계에 대한 가설을 담고 있으며 이를 스스로 패턴학습을 통해 추론한다. 따라서 패턴학습과 모델을 알아서 완성할 수 있다.
모델은 데이터 사이의 관계를 학습할 수 있도록, 입출력 데이터 사이의 관계를 설명하는 일종의 가설의 수학적 표현이다.
학습은 데이터와 그 해답으로부터 규칙을 얻어내는 과정이다.
손실함수는 패널티를 어떻게 주고, 어떻게 규칙을 수정할 것인가를 담고 있다.
모델이 학습을 자동으로 일어나게 할 수 있는 요인이 손실함수이다.
손실함수는 모델의 수치값과 실제 값의 차이를 계산하는 함수를 의미하고, 대표적인 손실함수로 RMSE(Root Mean Square Error)가 있다
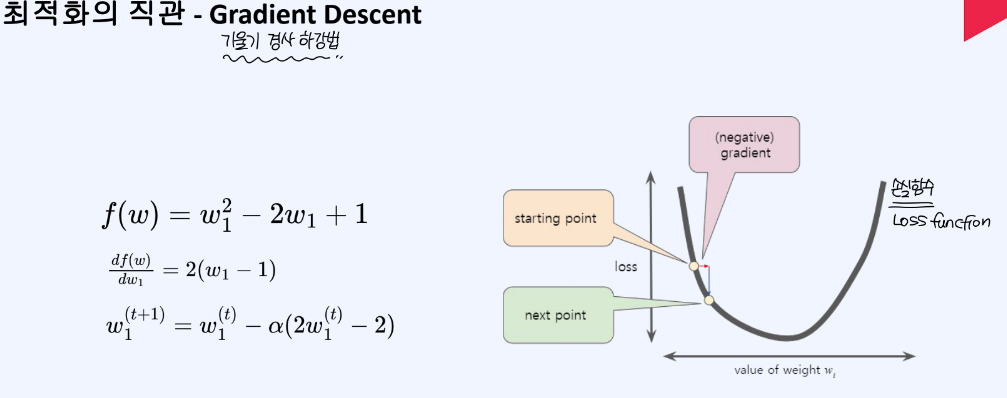
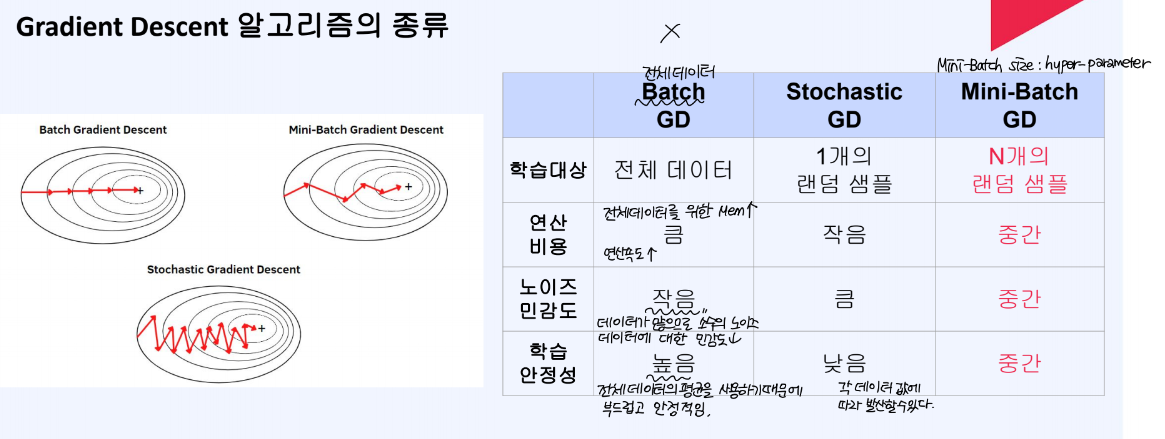
모델은 손실함수 값을 최소화하는 방향으로 학습을 계속해서 진행해나가며, Gradient Descent 방식을 이용하여 손실함수를 최소화할 수 있다.
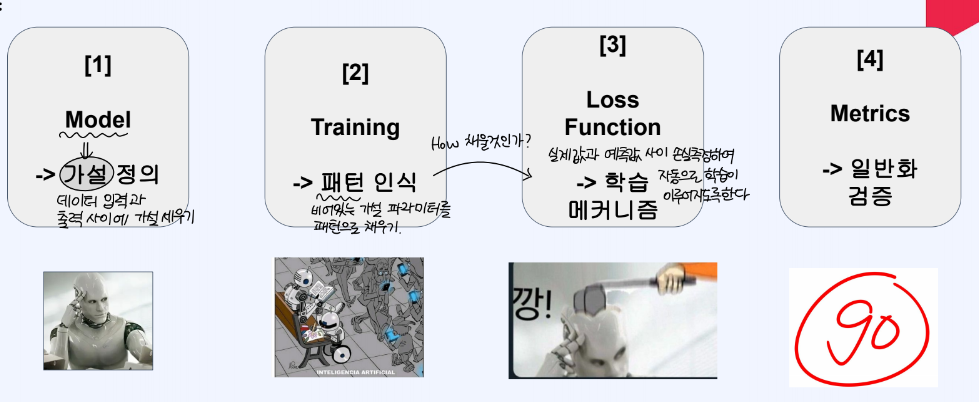
요약하면, 모델은 데이터 입력과 출력 사이의 가설을 세우는 과정
학습은 모델을 통해 비어있는 가설의 파라미터를 패턴으로 채우는 과정이다
손실함수는 실제 값과 예측 값 사이의 손실 계산으로 통해 자동으로 학습이 이루어지도록 한다. 마지막으로 평가를 통해 새로운 데이터에 대한 예측을 평가한다.
머신러닝 모델로 수행할 수 있는 Task는 크게 2가지로 나뉜다.
회귀(Regression)은 연속형 변수 값을 뱉어내는 task
분류(classification)은 범주형 변수를 뱉어내는 task로 대부분의 추천 모델을 분류 task를 해결하는 데 집중되어 있다.
모델을 활용하기 위해서는 데이터를 전처리 하고, EDA를 통해 데이터의 입출력 형태를 분석하고 형태에 적합한 모델을 사용한다.
단순한 선형 모델부터 복잡한 부스팅, 딥러닝 기반 모델까지 다양한 모델이 존재할 수 있다. 모든 문제에 장점을 보이는 killer 모델을 존재하지 않는다. 그러나 대부분 문제에 강점은 보이는 모델을 존재하며, 성능 좋은 모델을 ensemble하여 사용할 수도 있다.
학습을 통해 나온 수치 값과 실제 값 사이 손실을 계산하여 얼마나 패널티를 줄지 결정한다. 이를 토대도 더 나은 모델로 학습되도록 유도하는 기능을 수행한다.
학습을 통해 개선된 모델에 새로운 입력 데이터를 추가하여 적절한 예측을 뱉어내는지 확인한다. 이러한 능력을 "일반화 성능"이라고 한다.
선형 회귀
선형 회귀는 입력 변수와 출력 변수 사이의 선형 관계를 모델링하는 알고리즘이다. 파라미터를 조정하면서 개별 데이터와 모델 사이의 손실이 최소가 되는 함수를 찾는다. 이는 데이터를 가장 잘 설명하는 파라미터를 찾는 것을 목표로 한다.
모델에는 무결하고 완전한 관계를 갖는 물리적 공식이나 직접 설계한 함수 등은 결정적 모형이라 하고, 입력과 출력의 경향성을 나타내며 오차항을 포함하는 모형은 통계적 모형이라고 한다.
Decision Tree
데이터를 규칙으로 구획할 수 있다. 새로운 데이터가 들어왔을 때, 정해진 규칙에 따라 각각의 구획으로 들어가게 되고, 최빈/평균값을 예측 결과로 반환한다.
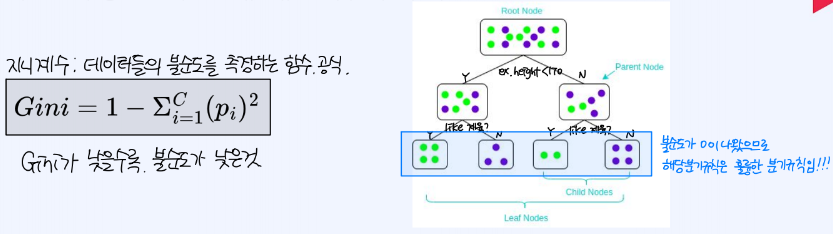
가장 좋은 규칙은 데이터들의 불순도를 측정했을 때, 불순도가 낮은 규칙을 좋은 규칙이라 할 수 있다.
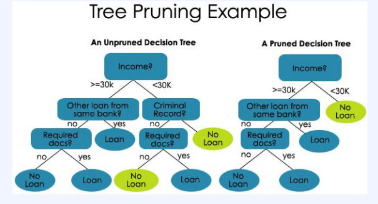
그러나 불순도를 0으로 유도하기 위해, 지나치게 세밀한 분류를 진행하는 것은 데이터 overfitting을 야기할 수 있다. 따라서 pruning 하여 트리의 과도한 성장을 방지하여 일반화 성능을 높일 수도 있다.
손실함수 최적화
대표적인 손실함수로 RMSE와 Cross Entropy가 있다.

cross entropy는 실제 정답 레이블의 분포를 나타내기 위해 필요한 정보량 이외에 추가 entropy를 더한 entropy를 의미한다.
특정확률분포에서 발생하는 사건들을 사건발생확률에 맞게 encoding할 대 필요한 평균적인 정보량을 의미하기도 하며, 불확실성이 높은 드문 사건에 대해서는 많은 정보가 필요하다.
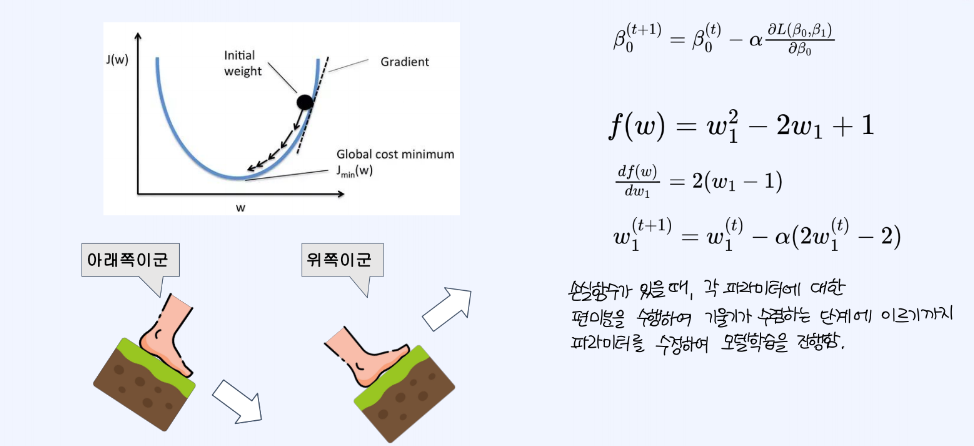
손실함수를 최적화 하기 위해서는, 각 파라미터에 대한 편미분을 수행하여 기울기가 수렴하는 단계에 이르기까지 파라미터를 수정하여 모델학습을 진행한다.
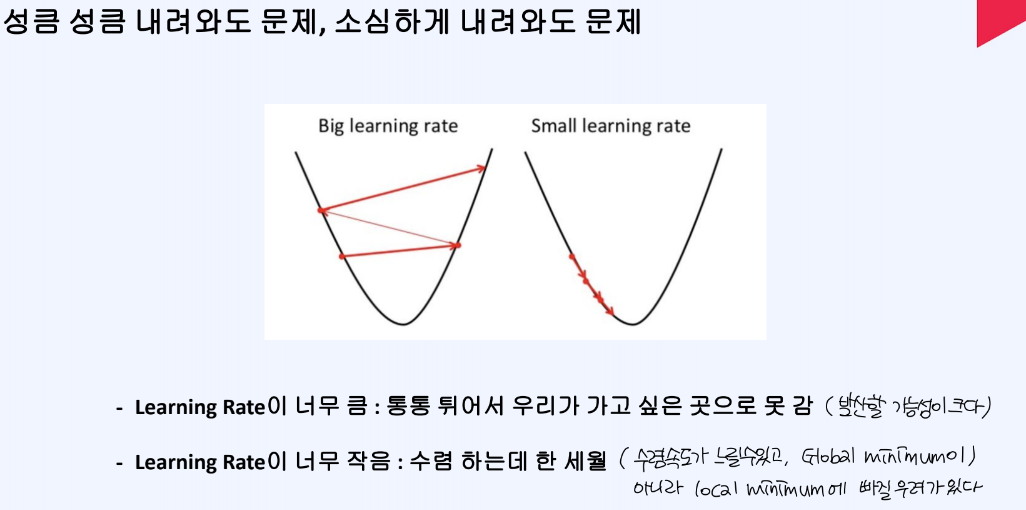
손실함수 최적화를 할 때에, 학습률이 중요하다. 만약 학습률이 너무 크다면 발산할 가능성이 커, minimum에 도달하지 못하는 문제가 발생한다.
또한 학습률이 너무 작다면, 수렴하는 데 오랜시간이 걸리고 Global minimum이 아니라 local minimum에 빠지는 문제점이 발생할 수 있다.
학습 평가 지표
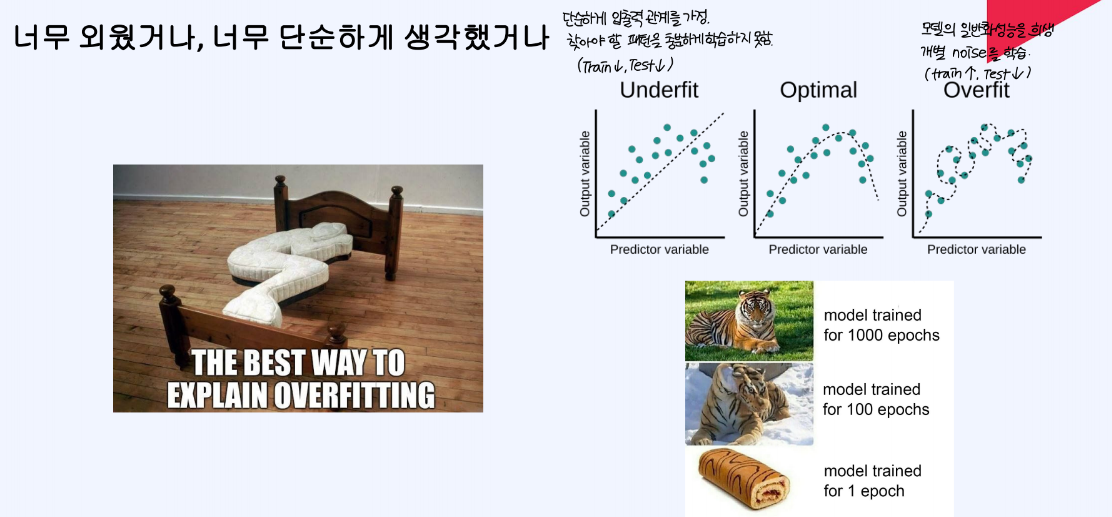
단순하게 입출력 관계를 가정하면 찾아야 할 패턴을 충분하게 학습하지 못하게 된다. 반면, 모델의 일반화 성능을 희생하게 되면 개별 noise를 학습하게 되므로 train 성능은 높아지지만, test 성능은 저하될 수 있다.
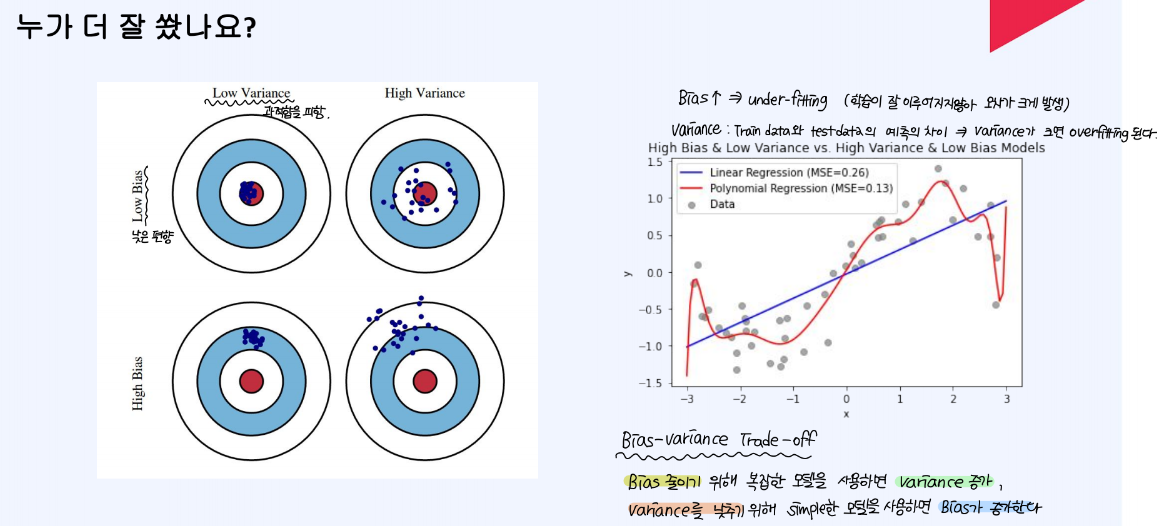
Bias와 variance 사이에는 trade-off 관계가 존재한다. bias를 줄이기 위해 복잡한 모델을 사용하면 variance가 증가하게 되고, variance를 낮추기 위해 simple한 모형을 사용하면 bias가 증가하게 된다.
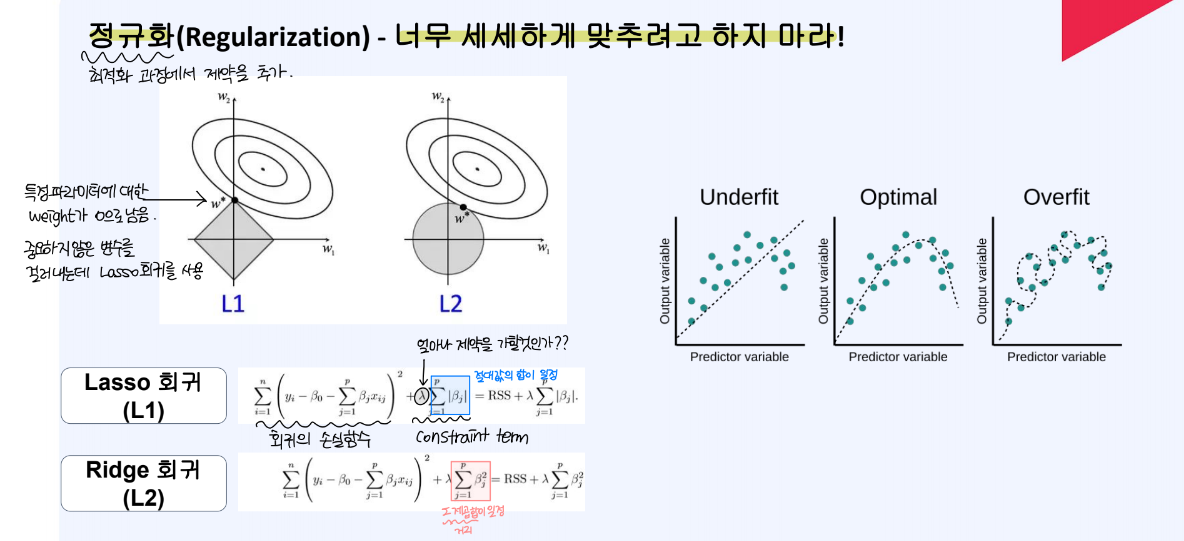
학습 데이터에 대해 세세하게 맞추려고 하면, 과적합되는 문제점이 발생할 수 있다. 이를 위해 최적화 과정에 제약을 추가하는 정규화 과정이 존재한다.
Lasso 규제는 특정 파라미터에 대한 weight가 0으로 남게 된다. 따라서 중요하지 않은 변수를 걸러내는데 Lasso 회귀를 사용할 수 있다.
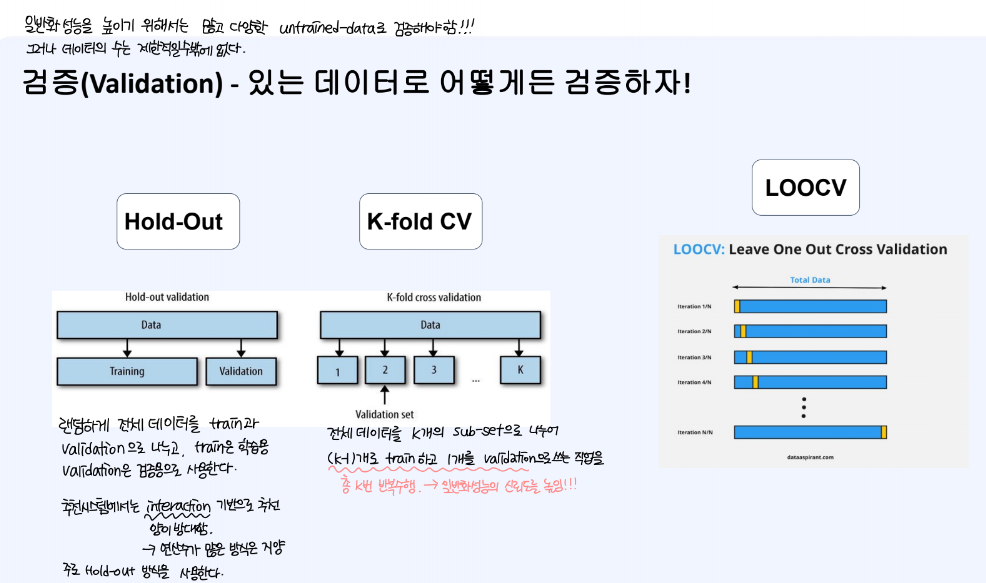
검증은 일반화 성능을 높이기 위해서 많고 다양한 untrained-data로 검증해야 한다. 그러나 데이터의 수는 제한적일 수 밖에 없기 때문에, hold-out, k-fold CV. LOOCV 방식을 활용하여 일반화 성능을 높일 수 있다.
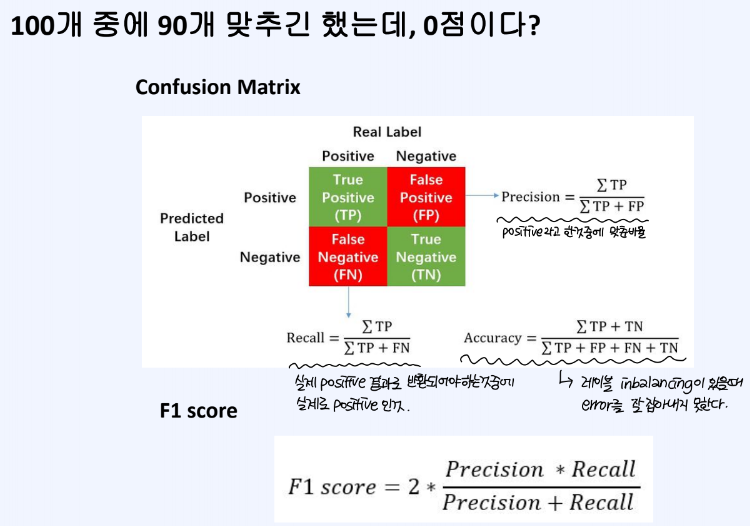
Confusion Matrix 를 통해 확인할 수 있는 대표적인 평가지표로 Accuracy가 존재 한다. 다만, accuracy는 레이블 inbalancing 문제가 있을 때, error를 잘 잡아내지 못하는 단점이 존재한다. 따라서, accuracy 외에 precision, recall, f1-score 등을 활용할 수 있다.
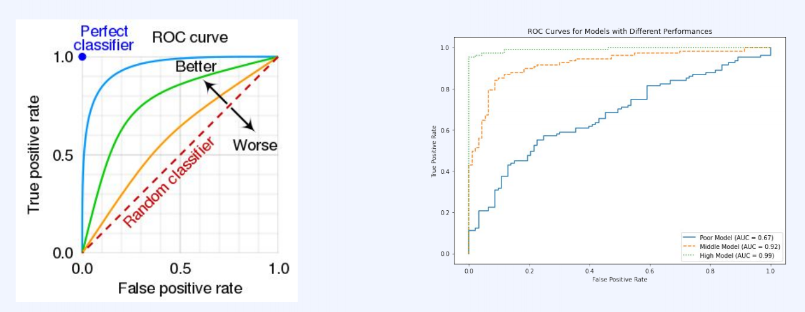
또 다른 평가지표로 AUC 라는 것이 존재하는데, 이는 무작위로 찍은 것보다 얼마나 잘했는지 평가하는 지표이다.
AUC는 ROC curve의 하단부 넓이 비율을 나타내는 값으로, 값이 높을수록 좋다.
ROC는 이진 분류 모델에서 threshol에 따라 값이 변화하느 ㄴ성능 값을 나타내는 곡선이다.
