모델 기반 추천시스템은 크게 3가지로 분류 할 수 있다.
첫번째, 컨텐츠 기반 필터링에서 주로 사용하는 트리기반의 모델
두번째, 협업 필터링에서 사용하는 행렬 분해 방식의 모델
그리고 세번째, 하이브리드 방식으로 앞선 두 가지 방식을 합친 모델로 구분할 수 있다.
트리 기반의 모델
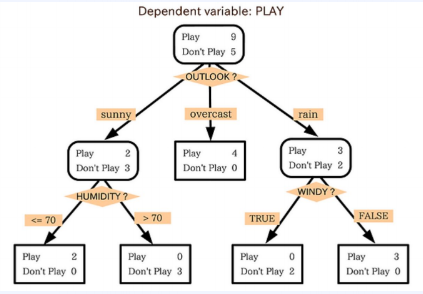
컨텐츠 기반 필터링에서 트리기반의 모델이 주로 사용된다. (랭킹, 분류테스트 등에 많이 사용된다.)
해당 모델은 주어진 입력 피처에 대하여 일련의 결정 규칙을 생성하는 알고리즘이고, 단순한 구조를 띄고 있어 부족한 성능을 가지고 단일 모델로 과적합 가능성이 높지만 직관적이고 설명능력이 좋다는 장점도 지니고 있다.
그렇다면 어떻게 더 효과적인 모델을 만들수 있을까? ensemble
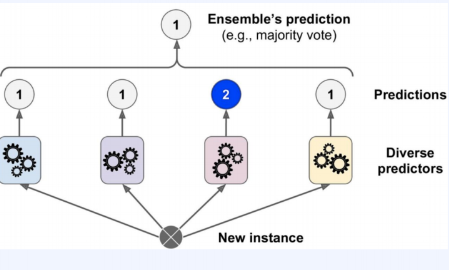
앙상블을 통해 다수의 모델을 구성해 에러를 줄이는 방식을 할 수 있다. 이때 어떻게 다양성을 확보하고, 개별 모델들을 취합할 것인지 고려하는 것이 중요하다.
여러 모델을 조합했을 때, 하나의 강력한 알고리즘 모델보다 더 뛰어난 성능을 발휘할 수 도 있고, 개별적인 알고리즘이 가진 장점을 더하고 단점을 보완할 수 있다는 점이 ensemble의 기본 idea라고 할 수 있다.
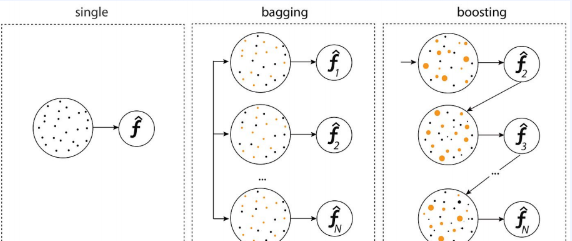
앙상블의 종류에는 배깅(bagging), 부스팅(boosting), 스태킹(stacking)이 있다.
- 배깅(bagging) :Bootstrap Aggregating의 약자, 다르게 샘플링한 데이터로 각각 다른 모델을 학습한다. 전체 학습 데이터에서 랜덤복원추출하여 구성된 데이터셋마다 다른 모델을 학습시킨다.
- 부스팅(Boosting) : 모델을 순차적으로 학습시키며, 이전 모델의 약점을 해결하며 성능을 높인다. 앞선 모델 학습에서 error를 발생시킨 sample에 대해서 가중치를 적용하여 더 학습할 수 있도록 하는 방식이다.
- 스태킹(stacking) : 서로 다른 모델의 출력에서 최종 출력을 만드는 메타모델을 학습시키는 기법이다.
먼저, Bagging 방식을 사용하는 Random Forest에 대해서 알아본다.
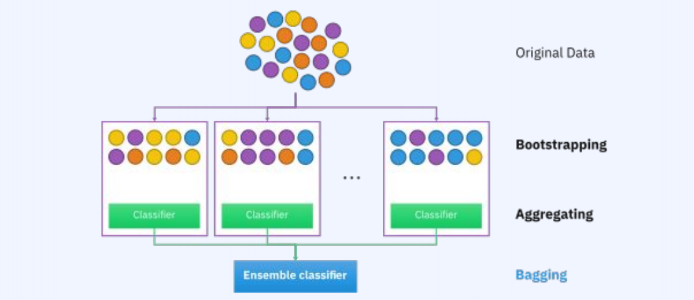
랜덤 포레스트에서는 원본 데이터셋을 복원 추출하여 데이터의 다영성을 확보한다. 그리고 각 데이터셋에 대하여 개별 모델을 학습시키고 결과를 결합한다. 따라서 복원추출한 결과를 종합하는 모델이다.
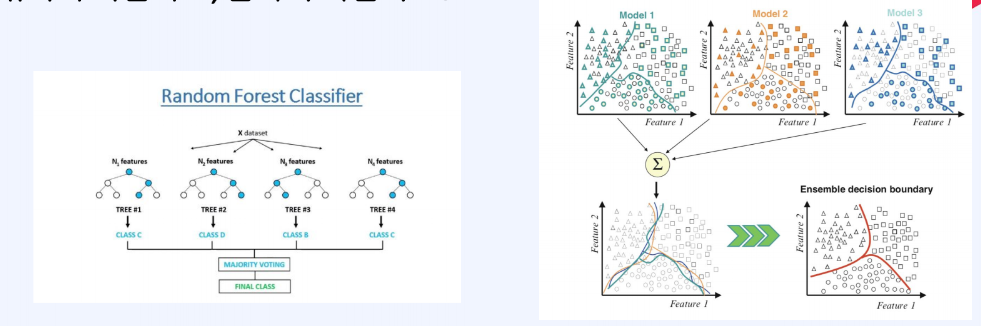
랜덤 포레스트에서의 핵심은 bagging 방식으로 데이터 셋을 추출할 때, 다양성을 확보하는 것이 중요하다. 또한 feature random selection을 통해 각기 다른 접근, 추론을 이끌어내는 logic을 학습할 수 있다는 점에 핵심이 있다.
다양한 모델을 종합하기 때문에, 특정 데이터에 오버피팅 되는 현상을 방지하고 분산을 줄이는 것이 배깅의 목표이다.
두번째, Boosting 방식이다.
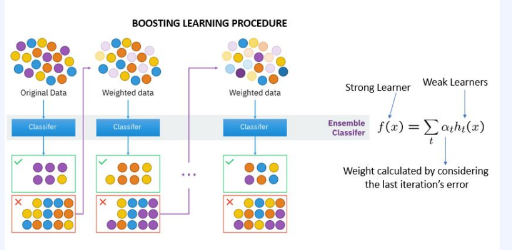
처음에는, weak learner 모델을 사용하여 학습하고, 이전 모델 학습에서 잘 못 맞춘 문제에 집중하도로 유도할 수 있다. 전체 데이터셋에서 이전 모델이 맞추지 못한 데이터 샘플에 대해 가중치를 적용해서 더 학습할 수 있도록 유도하는 것이다. 따라서 이전 모델의 예측 성능에 따라 weighted sampling을 수행하게 된다.
이렇게 해서, 데이터 샘플에 대한 오차를 줄이는 데 boosting의 목표가 있다.
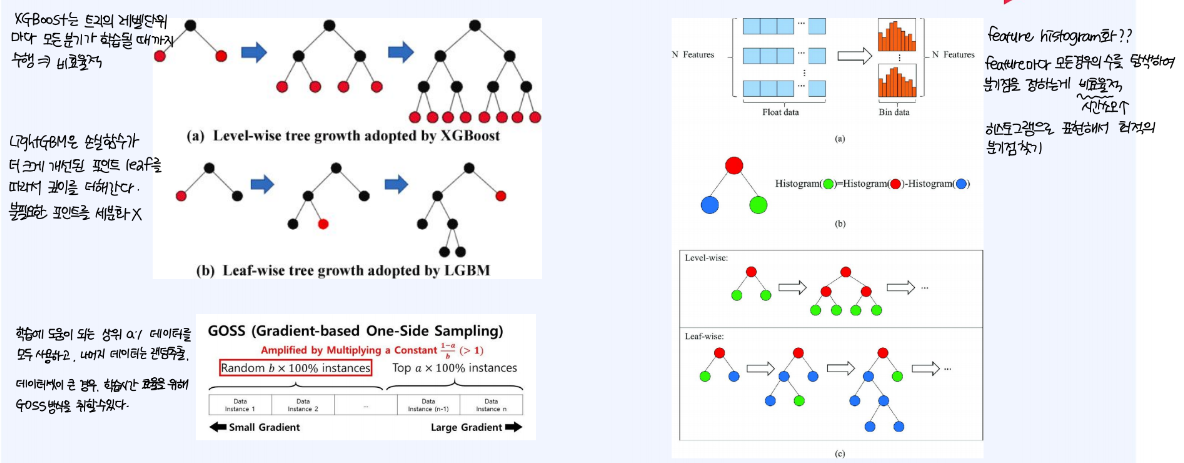
boosting을 사용하는 모델로, LightGBM을 예로 들 수 있다.XGBoost의 경우, 트리의 레벨 단위 마다 모든 분기가 학습될 때까지 수행하기 때문에 연산 속도측면에서 비효율적이다. 그러나 LightGBM은 손실함수가 더 크게 개선되는 포인트 leaf를 따라서 깊이를 더해가기 때문에 불필요한 포인트를 세분화해서 학습을 진행하지 않는다.
Tree기반의 모델에서는 어떤 feature를 통해 분기시켜야 하는가에 대한 고민을 하게 되는데, 이 때, feature histogram화 해서 최적의 분기점을 쉽게 찾는 것이 관건이다.
feature마다 모든 경우의 수를 탐색하여 분기점을 정하는 것은 너무 비효율적이고 시간 소모가 많은 작업이다.
GOSS(Gradient-based One-Side Sampling) 방식을 적용할 수 있다. 이 방식은 학습에 도움이 되는 상위 A% 데이터를 모두 사용하고, 나머지 데이터는 랜덤추출하여 사용하기 때문에, 대규모 데이터셋의 학습에 적용할 수 있는 방식이다.
트리기반의 모델은 딥러닝 방법론과 비교할 수 있을만한 추천 성능을 보이며, 관련한 실무적 연구적 기반 사례가 많다. 또한 feature histogram 화 방식으로 자원 효율적인 학습이 가능하고, 행렬분해 기반 방법론에 비해 모델의 판단을 사람이 해석하기 용이하다. 따라서 XAI(설명가능 인공지능)에 손쉽게 적용할 수 있다.
행렬 분해 알고리즘
추천시스템에서 상호작용 행렬이라는 것이 있다. 각 유저가 아이템에 대해 매긴 평점, 혹은 구매/클릭 여부를 나타낸 행렬이다. 이를 통해 유저의 직간접적 선호를 파악할 수 있다.
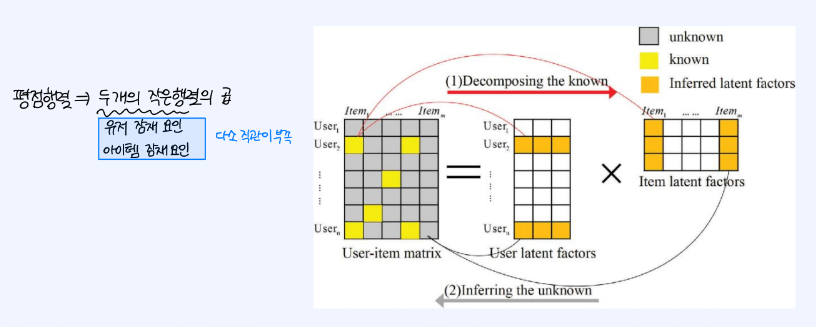
평점(상호작용)행렬이 있다고 할 때 두개의 작은 행렬로 쪼개어, 그들의 으로 유저의 평점을 예측하는 모델을 설계할 때, 상호작용 행렬에서 보다 더 적은 정보의 양을 가지고서도 결과행렬을 만들어 낼 수 있다.
두 개의 작은 행렬은 각각 유저 잠재 요인, 아이템 잠재 요인을 나타내게 된다.

Matrix Factorization 방식으로 표현하면, 원래 행렬의 정보를 저장하지 않더라도 효율적으로 정보를 가질 수 있고, 예측할 때도 필요한 정보만을 가지고 계산하기 때문에 효율적이라 할 수 있다.
이 방식을 통해서는 잠재 패턴을 발견할 수 있는데, 이는 저차원행렬로 매핑하는 과정에서 데이터의 노이즈를 줄이고 압축하는 방향으로 행렬을 저장할 수 있게 된다.
행렬분해 알고리즘을 학습시키는 방법에는 SGD, ALS 등이 있다.
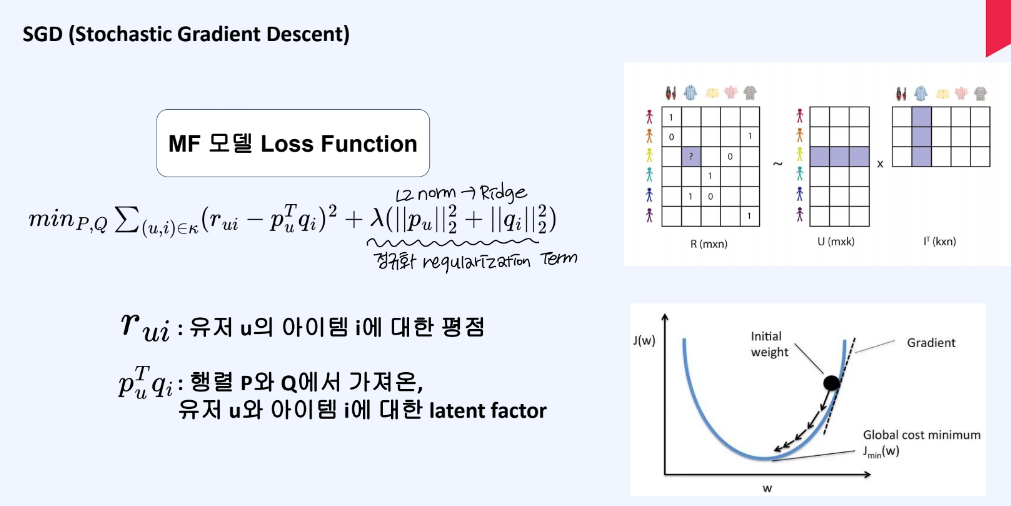
SGD는 확률적 경사 하강법을 의미하며, 실제 유저 u의 아이템i에 대한 평점과 MF 행렬 latent factor 연산 값 사이에 차이를 이용하여 손실함수를 구성한다. 손실함수를 최소화 하는 방향으로 학습을 진행한다.
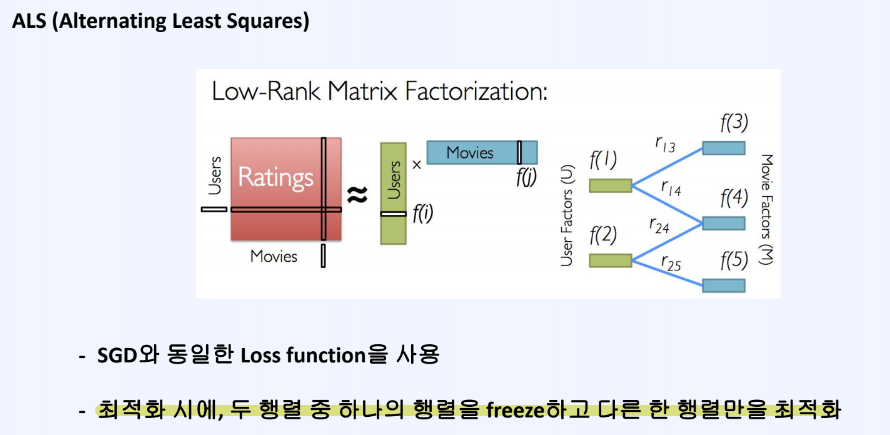
ALS 학습방식은 SGD와 동일하지만, 유저 행렬, 아이템 행렬이 있을 때 하나의 행렬을 고정시키고 다른 한 행렬만 최적화하는 방식을 취한다.
Matrix Factorization 모델은 Latent Factor라고 부르는 의미가 숨어있는 특성을 발견할 수 있어야 한다. 이것이 MF 알고리즘의 핵심적인 요소이며, SVD, NMF 등이 있다.
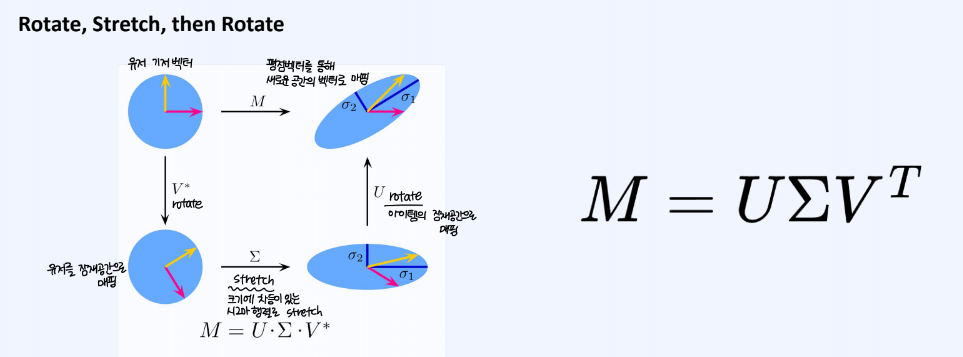
SVD기반의 Matrix Factorizaion에서는 정방이 아닌 m*n 행렬을 u,v라는 직교행렬과 고유값행렬 Sigma로 분해하는 기법이다.
유저 기저벡터가 존재할 때, 유저 데이터를 유저 공간에 벡터로 매핑시키고, 여기서 고유값 행렬로 크기를 조정해준다. 다시 한 번, 아이템 공간에 해당 벡터를 매핑시킬 수 있다.
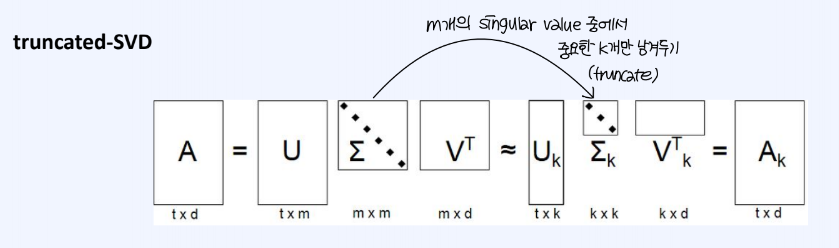
SVD 행렬 분해로 생성된 M개의 singular value 중에서, 가장 중요한 k개의 singluar value만 남김으로써 truncate함.
이 truncate된 행렬로 복원한 기존 행렬의 근사행렬의 원소에는 유저가 평가하지 않은 아이템에 대한 평점의 근사치가 들어가 있다.
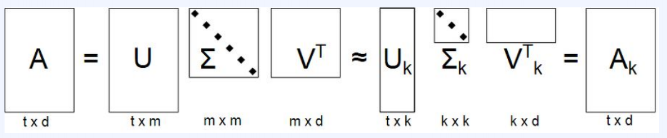
SVD 각 부분은 다음과 같이 해석할 수 있다.
U는 유저의 latent factor, V는 아이템의 latent factor, Sigma는 latent factor의 중요도를 나타내고 있다. Latent Factor는 유저와 아이템의 공통된 특징으로 인간이 해석하기 어려운 형태이기 때문에 latent(잠재적) 이라고 한다.
Factorization Machine
Factorization Machine 은 컨텐츠X협업 필터링 기반의 추천시스템에서 활용할 수 있는 모델이다.
앞서, Matrix Factorization 방식이나 Tree기반의 모델에는 한계가 존재하였다.
MF 모델의 경우, Interaction Matrix의 입력을 받기 때문에, cold-user이거나 matrix 자체가 sparse하면 잘 작동하지 않는 문제점이 있었다.
Tree기반의 모델에서는, Interaction Matrix를 직접적으로 활용할 수 없고, (user, item) pair에 대해서 "잘 맞다 혹은 아니다"를 판단하기 때문에, matrix에서 포착할 수 있는 정보활용에 한계가 있었다.

Factorization Machine을 살펴보면, 사용자-아이템 간의 인터랙션도 사용하고 feature들도 활용하고 있음을 확인할 수 있다.
각 feature들이 최종 예측 값에 미치는 영향을 보는 선형결합 term이 있으며, feature 인터랙션 파트를 의미하는 term을 포함하고 있다.

FM 알고리즘에서 더 나아가, FFM(Field-aware Factorizaton Machine) 알고리즘도 있다. 이는 광고추천 등에 자주 활용되는데, feature마다 하나의 latent vector를 갖는 것이 아니라, feature 내 field 마다 latent vector를 할당하여 더욱 복잡한 feature interaction을 학습할 수 있도록 구성한다.

추천시스템의 평가 방법 - 정확도 지표
추천시스템에서는 맞췄는지 여부 뿐만 아니라, 얼마나 잘 맞추었는지 상대적 순서가 중요하다. 가령 같은 결과가 나왔다하더라도, 10번째로 나왔는지 1번째로 나왔는지는 추천의 성능이 다르다고 할 수 있다. 그러므로 기존 metric(precision, recall, accuracy)를 그대로 쓸 수 없다.
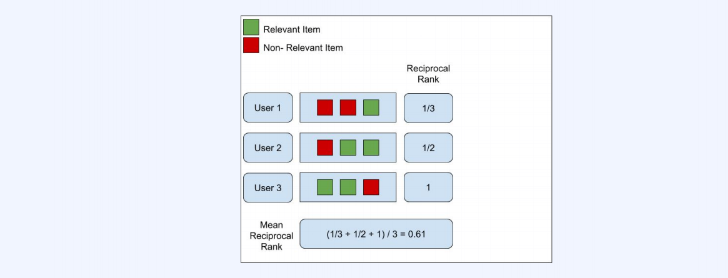
MRR(Mean Reciprocal Rank)
- binary relevance based metric으로 이진적으로 좋은 추천인지 나쁜 추천인지를 가려내는 지표이다.
- 유관 상품이 최초로 등장한 곳은 몇번째 인지 측정하는 지표
- 계산과 해석이 단순하고, 고객이 잘 알고 있는 아이템을 찾고자하는 시스템에서 MRR을 통한 성능 개선을 꾀할 수 있다.
- 그러나 유관 상품이 1개이던 여러 개이던, 동일하게 그 여부만 판단하므로 유관상품의 목록을 원하는 경우에는 좋은 척도가 될 수 없다.
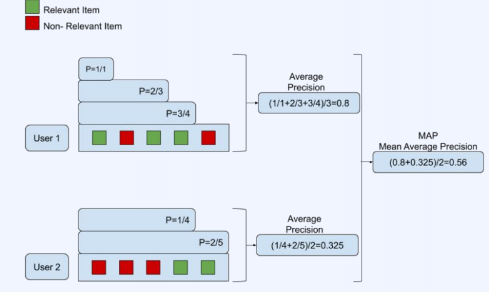
MAP(Mean Average Precision)
- 리스트 내에서 유관상품이 등장할 때마다, precision을 구하고, 이를 내는 방식
- 결과로 생성된 여러 리스트간의 평균을 내서(Mean AP)를 평가하는 방식이다.
- 랭킹이 높은 아이템에 대해서 더 높은 가중치를 부여하기 때문에, 대부분의 추천 시스템에 타당한 처리 방식으로 여겨진다.
- 그러나 평점의 scale이 rating 방식인 경우, 적합하지 않은 방식이다.
NDCG(Normalized Discounted Cumulative Gain)
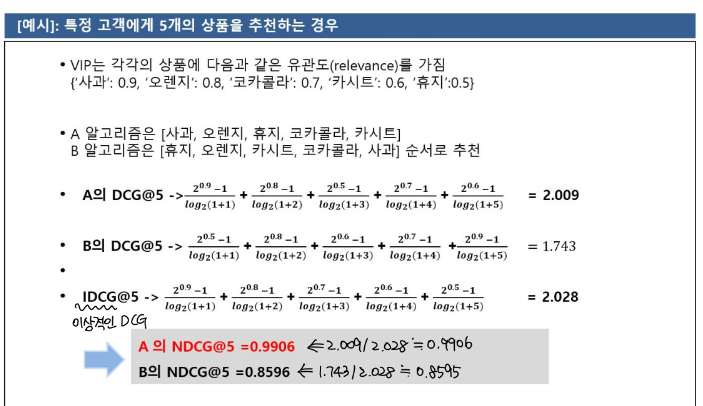

- NDCG는 MAP 방식과 비교해서, 순위 매겨진 품목들의 위치를 평가하는 데 우수하다고 할 수 있다.
- 그러나 cold-user로 인해 IDCG가 0인 경우(상품에 대한 유관도를 매핑할 수 없는 경우)를 직접 따로 다루어 주어야 한다.
추천시스템의 평가 방법 - 기타 평가 지표
- Hit rate(Hit@k) : k개의 추천 결과 중에 마음에 드는 결과가 존재하였는가?
- Diversity : 새로운 아이템을 추천하여 다양성을 확보하였는가?
다양성의 중요도는 서비스의 특성에 따라 달라질 수 있다. - Novelity : 참신성, 얼마나 잘 알려지지 않은 새로운 정보를 제공하였는가?
- Serendipity : 의도적으로 찾지 않았음에도 뭔가 새로운 좋은 것을 발견하는가?
설명가능한 AI, XAI
추천 시스템은 서비스 도메인에 따라 추천 대상이 되는 아이템 특성이 달라지고, 이에 잘 적용되는 알고리즘과 시스템 구조를 적절히 고안되어야 한다.
또한, 다양한 비즈니스 목표가 존재할 수 있다.
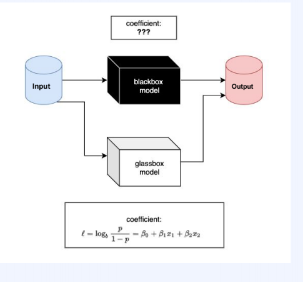
설명가능 인공지능(XAI)는 머신 러닝 모델이 어떻게 의사 결정을 내리는지 인간이 이해할 수 있도록 설명하는 알고리즘이다.
복잡한 인공지능 판단과정을 사람이 이해하기 쉽도록 하고 몯레의 신뢰성과 투명성을 확보하는 것이다.
그림에서, Glassbox 모델은 판단과정이 투명하여 어떤 변수가 중요한지 알수 있고, 추천받은 이유를 사용자에게 제공할 수 있다.
그러나, Blackbox 모델에서는 계산과정이 복잡하여 해석하기 어렵고, 판단로직을 파악하기 어렵지만, 성능도 좋고 패턴을 인식하는 능력이 좋기 때문에 실무적으로 많이 사용하는 모델이다.
그럼에도 불구하고 XAI는 왜 필요한 것일까?
- XAI는 모델을 학습하는 과정에서 발생하는 문제점을 해결할 수 있는 디버깅에 insight를 제공해줄 수 있기 때문이다.
추천 모델이 어떤 feature를 중요하게 생각하는지, 어떤 잘못된 가정이 포함되어 있는지 파악할 수 있게 해준다. 또한, 정답 데이터가 학습 데이터에 섞여 있는지(data leakage)를 파악할 수 있게 해준다. - XAI는 사용자의 신뢰성을 얻을 수 있다.
비즈니스 커뮤니케이션을 하거나, 사용자에게 AI 모델의 추론 근거를 제시함으로써 신뢰성과 서비스 만족을 제공할 수 있다. - 모델의 편향성을 분석할 수 있다.
추천모델의 판단 근거에 편항되거나 민감한 정보가 포함되어 있으면, 추천모델의 공정성 문제가 제기될 수 있다. 모델의 판단을 분석해서, 추천 편향이 있는지 판단해주는 방법론을 XAI가 제시해준다.
