
익숙해진 일들
정규 캠프 시작이 2주가 지났다. 이제는 하루 루틴도 익숙해졌고, 매일 하는 SQL 쿼리 작성도 익숙해지고 있다. 다음주부터 배우게될 파이썬이 좀 걱정이긴 하지만, SQL이 익숙해지는데 2주가 걸린 것처럼, 파이썬도 2주 안에 익숙해지도록 노력해봐야겠다.
오늘은 2월의 마지막 날에 있었던 이야기들을 해보려고 한다. 그래봤자 플래너에 가까운 기록이지만.

역시 즐거웠던 쿼리
오늘 푼 쿼리는 총 8개였다. 몇개는 말도 안되게 쉬웠고, 몇개는 쿼리 작성 전까지 5분 이상 끙끙대기도 했다. 그만큼 푸는데 성취감이 있었지만, 사실 정답이 맞는지는 아직 알수 없으므로, 다음주까지는 우쭐대지는 않으려고 한다.
먼저 일일 코드카타로 푼 프로그래머스 문제 5개이다.
SELECT HOUR, COUNT(ANIMAL_ID) COUNT
FROM
(
SELECT ANIMAL_ID, TIME_FORMAT(time(DATETIME), '%H') HOUR
FROM ANIMAL_OUTS
)a
WHERE HOUR BETWEEN 9 AND 20
GROUP BY 1
ORDER BY HOUR입양을 보낸 시간이 9~20시인 친구들을 찾는 문제였다. DATETIME 컬럼은 기존에 연월일 시분초까지 나와있는 DATE 타입이었다. 문제는 정답이 날짜가 아니라 시간을 구하는 것이었기 때문에, 혹시나 하는 마음에 DATE_FORMAT을 TIME_FORMAT으로 작성해보니 원하는 형태가 뽑혀나오는 것이 아닌가? 뒷걸음질치다 쥐를 잡은 격이었지만, 어찌되었든 답을 구했다는 점에서 즐거웠다.
SELECT MCDP_CD '진료과코드', COUNT(YM) '5월예약건수'
FROM
(
SELECT MCDP_CD, DATE_FORMAT(date(APNT_YMD), '%Y-%m') YM
FROM APPOINTMENT
)a
WHERE YM = '2022-05'
GROUP BY MCDP_CD
ORDER BY COUNT(YM) ASC , MCDP_CD ASC문제의 핵심은 DATE 폼을 원하는 형태로 가공하고, 이것에 특정 월로 조건을 거는 것이었다. 특정 월에 예약이 잡힌 건을 진료과별로 산정하는 문제였다. 큰 어려움은 없었다.
SELECT PT_NAME, PT_NO, GEND_CD, AGE,
CASE WHEN TLNO is NULL THEN 'NONE'
ELSE TLNO END TLNO
FROM
(
SELECT *
FROM PATIENT
WHERE AGE <= 12
)a
WHERE GEND_CD = 'W'
ORDER BY AGE DESC, PT_NAME ASC12세 이하의 여자 환자를 구하는 문제였다. 따라서 환자를 이중으로 기준을 걸어 구분했어야 했기에, 먼저 인사이드 뷰 서브쿼리에 12세 이하의 조건을 걸었다. 이후 GEND-CD로 여성 조건을 걸었다. TLNO 컬럼이 비어있을 경우, 전화번호가 없는 'NONE'을 표기하는 것이 조건이었으므로 CASE 구절을 사용했다.
문제를 푸는 과정은 거침이 없었지만, 한가지 배운 점이 있다면, 보통은 내림차수 정렬일 때 DESC를 걸어주고, 오름차수일 때는 굳이 써주지 않았다. 하지만 이번에는 정렬 기준 2개의 기준이 달랐으므로, 앞으로는 오름차순일 때도 ASC를 써주기로 마음 먹었다.
SELECT FLAVOR
FROM FIRST_HALF
ORDER BY TOTAL_ORDER DESC, SHIPMENT_ID ASC언급할 내용은 없다. 그냥 맛별 판매량 순으로 정렬하라는 것이었다. 만약 굳이 어렵게 풀거라면 RANK를 TOTAL_ORDER에 적용해서 진행한 뒤, ORDER_BY에는 SHIPMENT_ID만 쓰면 어땠을까 싶다. 판매량 내림차순 정렬이라면 판매량 순위를 내라는 것과 다름이 없지 않은까?
SELECT car_type, COUNT(car_id) CARS
FROM
(
SELECT *
FROM CAR_RENTAL_COMPANY_CAR
WHERE options LIKE ('%시트%')
)a
GROUP BY car_type
ORDER BY car_type이 문제는 처음 접근할 때 애를 먹었다.
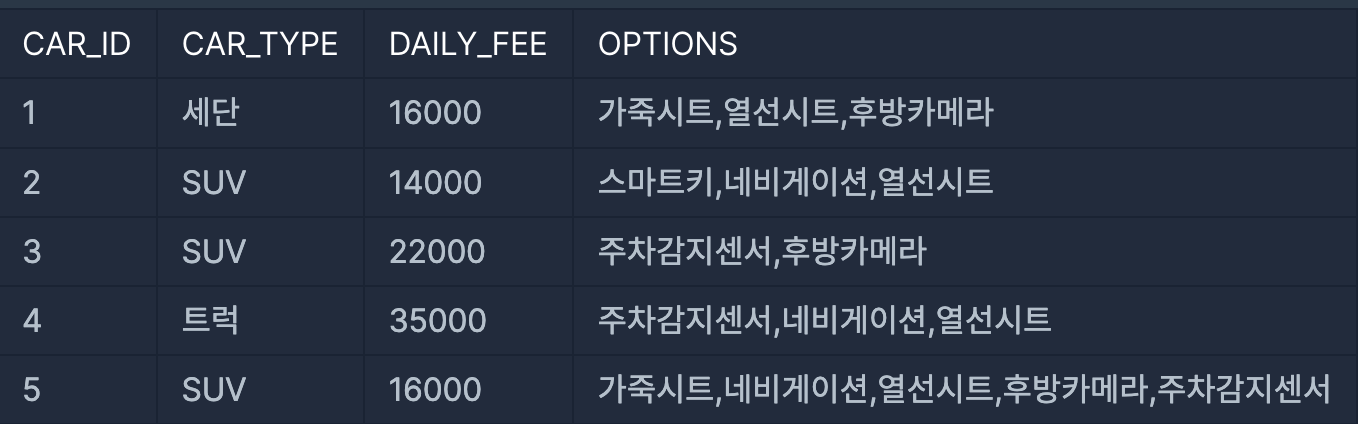
테이블이 이런 식으로 되어있는데, 이 중에서 '통풍시트', '열선시트', '가죽시트' 중 하나라도 갖고 있는 자동차를 차종별로 뽑아내는 문제였다. 문제는 이거다. 이 문제의 경우 우리가 잡아야할 3개의 항목에 공통적으로 '시트'가 들어가있으므로 상관이 없지만, 그렇지 않을 경우 LIKE를 여러번 쓸 필요가 있다.
또한 택스트의 형태도 고민할 필요가 있었다. 그러니까 프로그래밍 상으로 '가죽시트, 열선시트, 후방카메라'라는 하나의 텍스트 덩어리인지, 1번 세단의 OPTION 컬럼에 '가죽시크', '열선시트', '후방카메라'가 각각 객체값으로 들어가있는지도 고려해야 했다. 문제에서는 후자임을 언급해줬지만, 개인적으로는 문제를 풀어보기 전까지는 무슨 말인지 이해를 잘 못했다. 그것만 제외하면 어려울 것 없는 문제였다.
다음부터는 다시 전소현 튜터님이 내주신 문제들로, 조인을 활용한 문제들이다. 따라서 조인의 원리를 이해하는 것이 정말 중요했다. 그것만 이해한다면 다음부터는 쿼리 작성의 번거로움을 빼면 문제는 없었다.
SELECT CASE WHEN p.pay_type is NULL THEN '결제안함'
ELSE '결제함' END gb,
COUNT(u.game_account_id) usercnt
FROM users u left join payment p on u.game_account_id = p.game_account_id
group by gb처음부터 users 테이블과 페이먼트 테이블을 조인할 것을 지시한다. 기준이 되는 컬럼은 game_account_id이므로, 기준으로 묶어준다. 여기서 하나 신경써야할 점, 바로 결제 유저와 비결제 유저의 게임계정을 구분해야 한다는 것이다. 따라서 그룹화는 CASE 구절을 기준으로 잡아야한다.
참고로 payment 테이블의 유저들은 이름에서 유추할 수 있듯, 모두 결제를 한 유저들이다. (따라서 pay_type에는 NULL이 없다) 난 이를 근거로 inner가 아닌 left join을 적용했다. 이것만 제외하면 서브쿼리도 필요없는 쉬운 문제였다.
SELECT game_account_id, actor_cnt, sumamount
FROM
(
SELECT game_account_id, COUNT(DISTINCT game_actor_id) actor_cnt, SUM(pay_amount) sumamount
FROM
(
SELECT u.game_account_id,u.game_actor_id, u.serverno, pay_type, p.pay_amount
FROM users u left join payment p on u.game_account_id = p.game_account_id
WHERE u.serverno > 2 AND p.pay_type = 'CARD'
)a
GROUP BY 1
)b
WHERE actor_cnt >= 2
ORDER BY sumamount DESC 이중 인사이드뷰 서브쿼리를 사용하는 괴랄한 문제였다. 물론 문제 지문만 잘 따라간다면 어려울 것이 없는 문제다. 사실 가장 바깥쪽의 쿼리는 굳이 having을 사용하지 말라고 문제가 명시했기 때문에 쓸 수밖에 없었다. 고로 복잡해보이지만 실제론 단순한 쿼리이다.
3번 문제는 아직 풀지 않았다.
그놈의 A/B 테스트!

A/B 테스트 제대로 이해하기: 1 테스트를 설계할 때 우리의 진짜 질문은?
A/B 테스트. 우리는 이 캠프를 시작하면서부터 A/B 테스트라는 말을 참 많이 들어왔다. 데이터를 기반으로 개선 전략을 기획한 후, 이를 기존 상태와 비교하기 위해 두 비교군 집단으로 나누어 기획안을 적용한 집단과 그렇지 않은 집단 사이의 차이를 관측한 후, 개선이나 종료 같은 액션을 취한다.
늘 이런 건 말은 쉽다. 이거 만약 실험실에서 진행됐다면 완전히 폐쇄된 환경에 똑같은 수의 쥐나 세균으로 진행하면 그만인데, 우리의 실험 대상은 인간이다. 그걸 하는 것도 인간이니, 그 변수가 무한한 셈이다.
그렇다면 A/B 테스트로 우리가 알고 싶은 건 무엇일까? 단순히 A와 B 중에서 한 놈은 무조건 죽는 끔찍한 결과 만을 위해 이 실험을 하는 걸까? 테스트를 하는 목적과 의도를 감안하면, 우리는 말은 안하지만 결과에 무언가를 기대하게 된다.

명확한 비교를 위해 두 비교군 사이의 차이가 크길 '기대'하거나, 두 집단의 조건이 동일한, '공정한' 실험이길 바라기도 하며, 실험의 결과가 우연이나 특별한 결과가 아닌 '보편적인' 결과이길 바라는 것처럼 말이다.
하지만 우리는 기대를 할 것이 아니라, 진짜 질문을 해야 한다. 두 개의 안 중에서 확실하게 효과를 보이는 건 무엇인가? 이게 정말 A,B 의 차이 때문에 도출된 결과인가? 그리고 이건 우연이 아닌가?
그리고 이 질문들의 답을 찾기 위해선, 단순히 하나의 모집단을 하나의 번수를 기준으로 2개의 비교군으로 나누고, 둘 중 더 나은 하나의 방법을 선택하는 것이 A/B 테스트의 전부라는 생각을 버려야 한다. 그보다 더 복잡한 무언가가 있기 때문이다.
A/B 테스트의 아티클은 앞으로 계속 읽을 예정이다.
넌 컴퓨터가 아니다
데이터 리터러시 1~2강
인간은 컴퓨터가 아니다. 이 말은 그러니까, 우리가 죽어라 SQL이나 파이썬을 배운다고 해서, 앞으로 앉아서 9to6까지 그것만 할 것이 아니라는 말이다. 만약 데이터를 분석한다는게 단순히 쿼리나 코드를 줄줄 쓰는 걸로 끝났다면 이걸 국비 캠프까지 들으면서 하고있지 않았을 것이다.
데이터를 왜 분석하는지, 분석해서 뭘 할 건지, 그래서 어떻게 분석할 것인지를 아는 사람이 데이터 분석가다. 이를 해내려면 데이터를 볼 줄 알아야 한다. 이게 지금까지 많이도 얘기했고, 앞으로도 이야기할 데이터 문해력, 혹은 '데이터 리터러시'라는 개념이다.
얕게는 데이터를 읽고, 이해하고, 비판적으로 분석하며, 분석 결과를 타인과의 의사소통에 활용하는 능력이다. 더 깊게 들어가면 데이터 원천과 그로부터의 수집 과정을 이해하고, 이를 다양하게 활용하는 방법을 아는 것이다. 또한 데이터를 통해 핵심지표를 이해하는 것도 포함된다. 결과적으론 데이터를 기반으로 '올바른 질문을 던질 수 있는' 능력을 데이터 리터러시라고 한다고 보아도 무방하다.
분석을 잘한다는 것과는 다른 말이고, 나아가 이건 '틀린' 답에 가깝다. 기억날지 모르겠지만 초반부 아티클에서 우리는 데이터 오류의 다양한 사례를 만나보았다. 그것들이 수집 방법에 문제가 있어서 발생한 걸까?
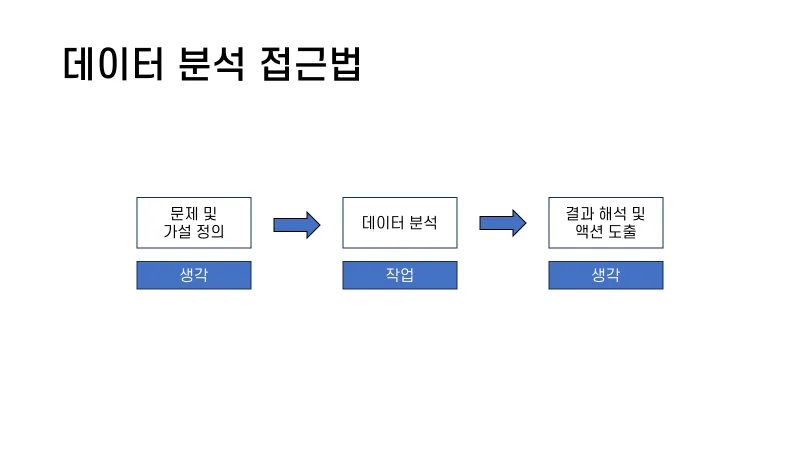
데이터 오류는 애당초 데이터 수집 및 실험 설계 과정에서의 실수, 오류, 무지, 혹은 의도로 발생한다. 문제 및 가설을 정의하는 과정에서 하나가 오링이 난다면, 과정과 결과는 절대 맞게 나올 수가 없다.
따라서 제일 먼저, 지금 우리가 해결해야할 문제가 무엇인지 정의하는 과정을 착실하게 다지는 것은 이후에 데이터를 분석하는 과정에서 필수적이라 할 수 있다.
그렇다면 문제를 정의하는데 중요한 것은 무엇일까? 해결해야 하는 특정 상황이나 현상에 대해 명확하고 구체적으로 설명해야 한다. 해결할 목표가 결정되면 이후 문제를 분석하는 과정을 분석해야 한다.
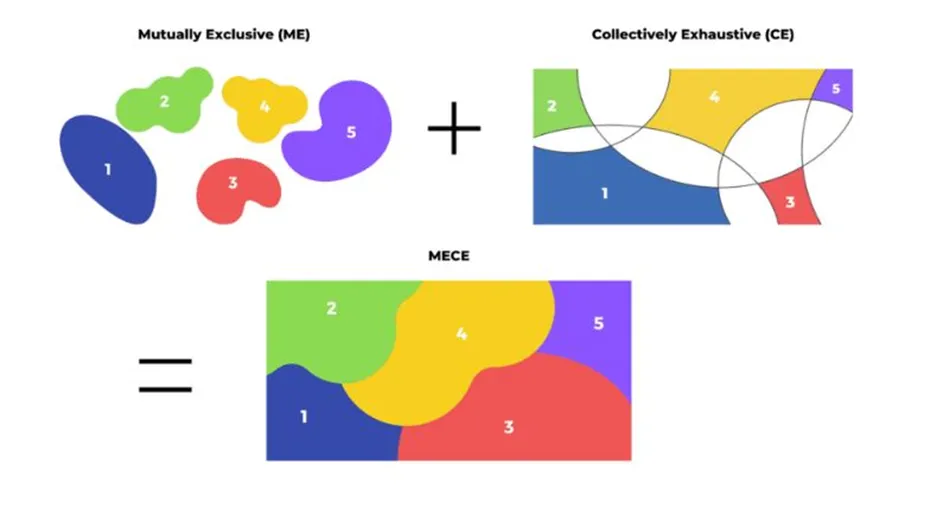
하지만 무턱대고 달려들면 불필요한 시행착오를 겪기 마련이다. 문제를 정의하는 대표적인 방법으론 MECE가 있다. MECE는 Mutually Exclusive, Collectively Exhaustive의 약자로, 각각 상호 배타적, 전체 포괄적이라는 뜻이다. 이는 문제를 상호 베타적인 요소들로 나누고, 이것들이 다시 전체를 이루는, 포괄적인 그림을 그리는 시도라고 설명할 수 있다.
복잡하고 거대한 문제를 잘게 쪼갠 뒤에, 이를 원하는 모양으로 맞춰서 구체적으로 이해하기 쉽고, 측정할 수 있는 형태로 가공하는 것이라 보면 쉽다. 서로 겹칠 수 없는 기준으로 분류되면서도, 그걸 합치면 전체가 되어야 한다. 대표적으로 남자와 여자 같은 간단한 분류부터, 횟수, 금액으로 등급을 나누는 방법까지 다양하다.
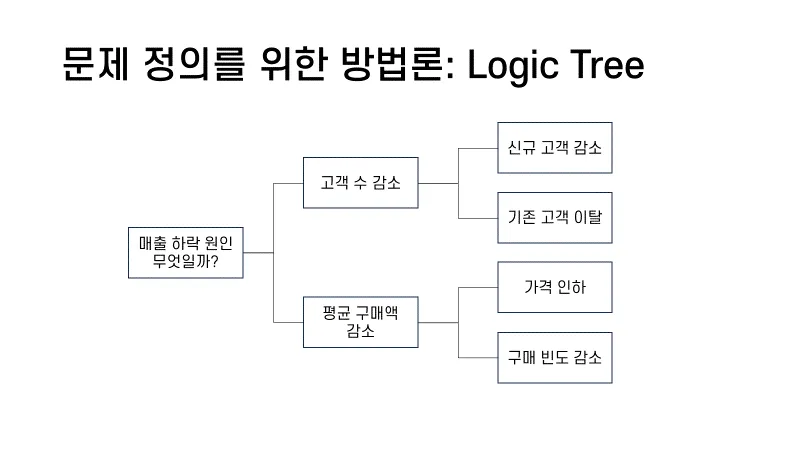
로직 트리(Logic Tree)는 MECE를 기반으로 완성된 그림을 더 작고 관리하기 쉬운 하위 문제로 분해하는 방법론이다. 최상위 문제에서 탑다운으로 하위 문제를 찾아내기 때문에, 도표 형식으로 표현되어 쉽게 파악이 가능하고, 목표의 우선순위를 정하기에도 용이하다.
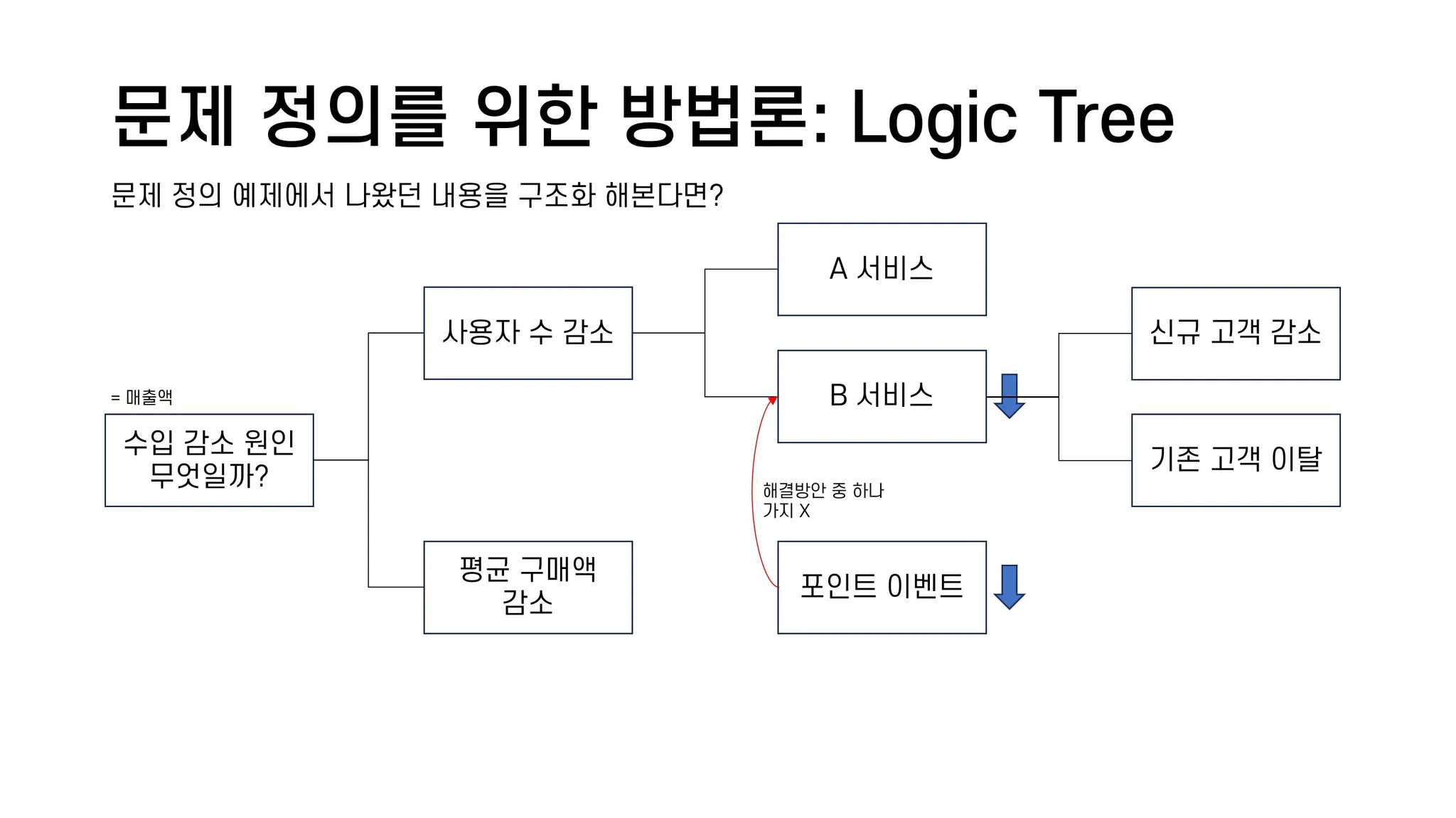
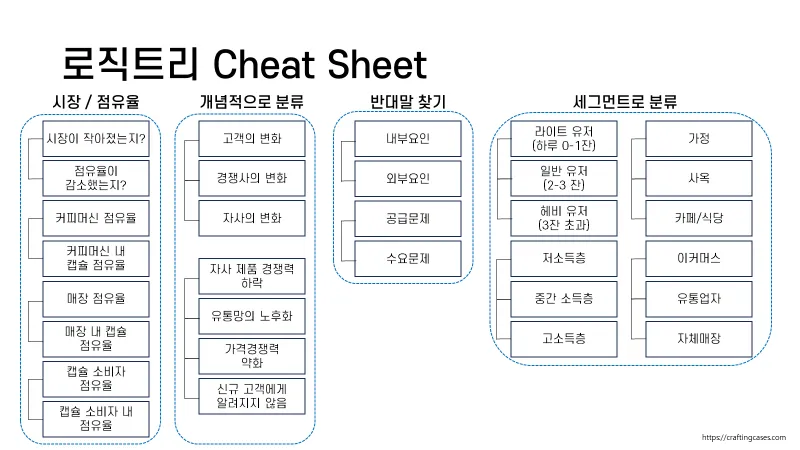
간단하게는 위의 표와 같은 형태에서, 네스카페에서 만든 로직트리인 하단의 체크 시트까지 다양하게 활용이 가능하다.
문제정의가 무엇인지, 그리고 어떻게 하는 건지도 알겠다. 마지막으로 문제를 정의하는 이유에 대해서 다시 한 번 짚고 가자.
문제 정의를 통해 우리는 해결하고자 하는 문제를 명확하게 정의하고, 해결을 위한 데이터 분석의 방향성을 정하며, 그 결과를 정리하고 해석하여, 개선을 위한 새로운 액션 플랜을 수립할 수 있다.
한 문장을 길게 쓰는 건 chill한 글쓰기가 아니니, 더 chill하게 줄여보자.
문제 정의를 통해 우리는 so what?과 why so라는 질문에 답변해야 한다.
문제 정의의 팁에 대해 강의에서는 다음과 같이 설명한다.
- 결과를 공유하고자 하는 사람이 누구인지 정의해보자
- 결과를 통해 원하는 변화가 무엇인지 생각해보자
- 조직에 속해있다면, 조직의 경영자의 관점에서 문제를 보려고 노력하자
- 많은 사람들과 의견을 나눠보자
- 하지만 혼자 오래 고민해보는 시간을 꼭 가지자
진짜 길다
한게 너무 많아서 쓴게 많다. 앞으로는 이렇게 하루에 해야할 루틴을 하나씩 늘려갈 것이고, 그에 따른 TIL 작성도 많아질 것이다. 그래도 최대한 재미있고, 읽기 좋은 글을 써보려고 노력해 볼 생각이다.
