
현실은 바보천치
개인적으로는 코드를 작성하는 재능을 수치로 나타낸다면 난 음수일 것이라고 생각한다. 천성이 덤벙거림이 많고, 잔실수를 많이 하기 때문에 쉼표와 마침표, 따옴표 실수로 30분을 날리는 경우가 많기 때문이다. 그러니 포켓몬 시합은 성능이 다가 아니야! 라는 지우의 말처럼, 데이터 분석가는 코드 작성 실력이 다가 아니야! 라고 애처롭게 외치는 것이 때때로 애처롭게 보이는 것도 어쩔 수가 없다.
오늘은 팀 프로젝트에서 새롭게 규정한 VIP 기준, 그리고 그 기준을 바탕으로 한 다양한 소비 패턴 분석의 결과에 대해서 이야기해보고자 한다.

이거 숫자만 좀 바꾸면 돼요
커머스 프로젝트는 대부분 수익성 개선을 목표로 삼는다. 사실 당연하다면 당연한 것인데, 기업의 제1목표는 언제나 이윤 증가이기 때문이다. 우리는 그 방향성을 충성 고객의 소비를 촉진하는 것으로 잡았으며, 여기에 더해 2019년 당시 H&M의 목표였던 성공적인 온라인 커머스로의 전환도 함께 분석했다.
처음 데이터에 대한 탐구적 분석, 즉 EDA를 진행할 당시, 우린 직관적으로 브랜드와의 커뮤니케이션 가능 여부, 그리고 패션 잡지, FN 구독 여부가 충성 고객을 규정하는데 중요한 지표가 될 것이라 믿었다. 하지만 그 둘을 만족하는 고객들이 전체 매출에서 차지하는 비중이 유의미하다고 보기 어려울 정도로 적었기 때문에, 중요 고객을 새롭게 규정하기로 결정했다.
이후 매출 상위 고객들을 비율로 설정하여 중요 고객으로 설정하려 했고, 상위 20%의 고객을 기준으로 했을 때 전체 매출에서 차지하는 비중이 50%를 넘었음을 발견하여 이를 기준으로 삼는 것이 어떤지 논의, 이후 담당 튜터님과 상의를 해봤다. 하지만 느낌과는 다르게, 50% 매출을 차지한다고 해서 20%의 고객이 VIP라고 단정하기는 근거가 부족하며, VIP라고 지칭하기에는 전체 고객의 20%는 범위가 너무 크다는 지적을 받으며 VIP 정의는 다시 미궁에 빠졌다.
그러던 중 H&M에서 1년 간 소비한 금액이 100만 원 이상인 고객들을 VIP로 설정하는 것에 대한 논의가 시작되었다. 하지만 약 100만 명의 고객들 중에서 100만 원 이상을 1년 동안 쓴 사람은 고작 41명이었다. 우리가 A/B 테스트 아티클에서도 보았지만, 분석을 진행할 표본이 이 정도로 작다면 표본 집단 내에서의 경향성은 신뢰도는 근거를 잃는다. 다만 1년 소비 금액을 기준으로 VIP를 설정하는 것은 일리가 있다고 판단하여, 금액을 50만 원으로 줄이자 약 400명 가량이 포착되었다.
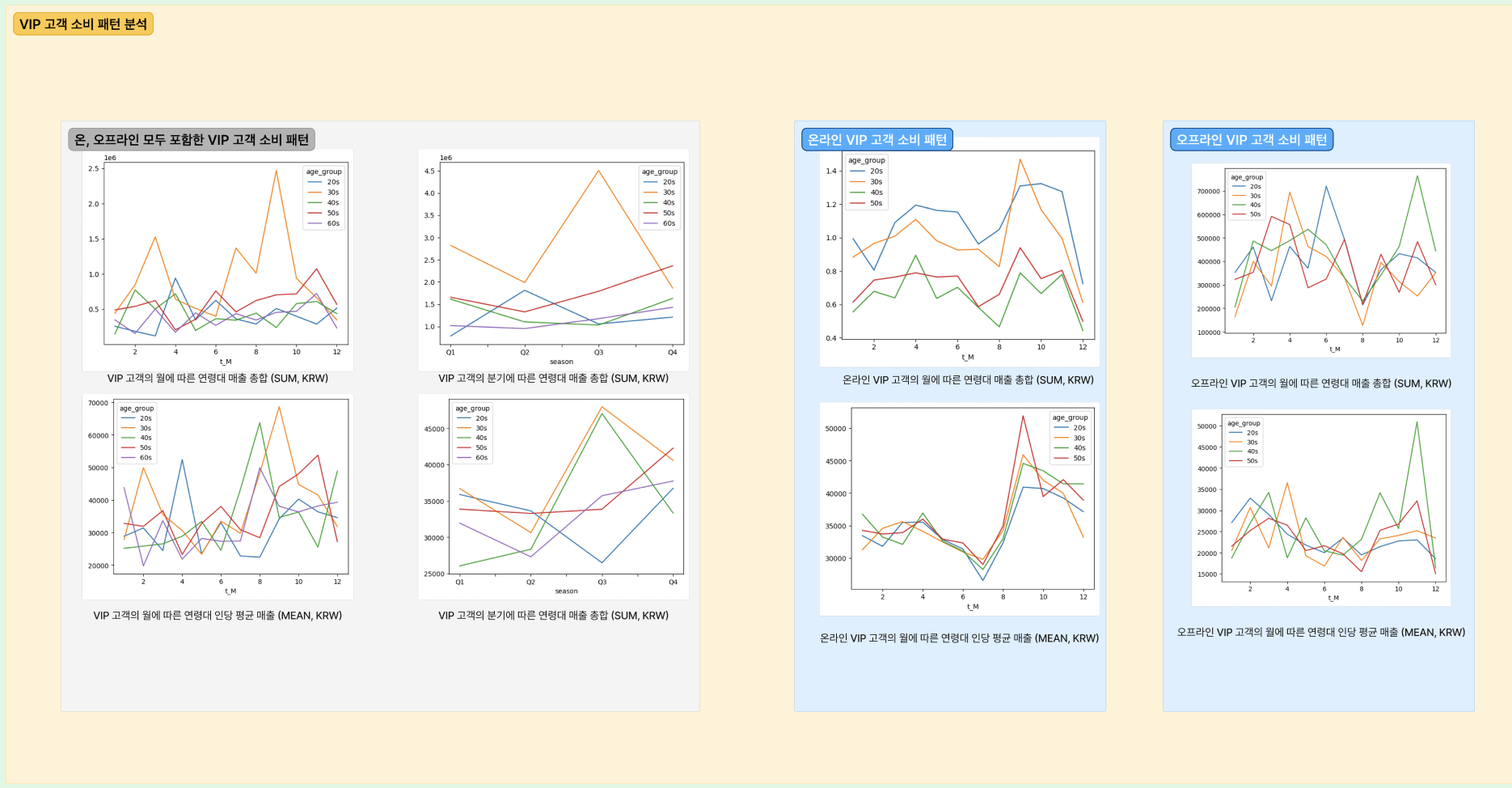
이후 해당 고객들의 온오프라인 전체에서의 소비 패턴을 분석했지만, 보시다시피 사실상 난수치가 나와버렸다. 이 중에서 의미가 있는 지표는 개인적으로는 온라인에서의 VIP 고객의 소비패턴이었는데, 전체 VIP 고객의 대부분이 온라인으로 구매를 했기 때문에, 인당 평균 매출은 확실하게 패턴을 보이고 있으며, 연령별 매출 총합 역시 수치와 패턴이 산만해보이더라도 변곡점들은 서로 유사한 패턴을 보이고 있다.

반드시 매출이 원인이어야만 할까?
다양한 데이터프레임과 그래프들을 살펴보면서 느낀 점은, 특정 기준으로 모집단에서 추출한 표본 집단의 경향을 비롯한 패턴 데이터를 보기 위해선, 명확한 정의 기준 설정과 함께 그 규모 역시 중요하다는 점이었다. 당연한 소리를 하는 것처럼 들릴 수 있지만, 실제로 데이터를 다루어보면서 이 점을 확실히 체감할 수 있었다.
그 수가 적었던 오프라인 VIP 고객의 소비 패턴은 어떤 인사이트를 도출하기엔 난수치가 심했던 반면, 상대적으로 수가 더 많은 온라인 VIP 고객의 수치는 정도의 차이는 있지만 패턴을 엿볼 수 있다.
이 점에서 이커머스로의 성공적인 전환의 필요성을 찾을 수 있었는데, 단순히 매출을 더 올리기 위해서가 아니라, 명확한 데이터를 찾을 수 있다는 점이었다. 특히 오프라인 고객은 인적 사항에서 결측치가 많았던 반면, 개인 정보로 회원 가입을 하여 제품을 구매한 온라인 고객들은 결측치가 상대적으로 적었다는 점도 이를 방증한다. 그 규모와 데이터의 촘촘함은 패턴 분석을 통해 또 다른 액션으로 이어질 수 있는 근거가 된다는 말이다.

이는 전체 고객을 대상으로 한 데이터를 보면 더 분명해진다. 예전 고등학교 때 함수에 극한을 취하면 직선 그래프가 되는 것처럼, 규모가 거대해질 수록 그래프의 등고는 분명해진다. 따라서 등고가 발생하는 시점에 대한 딥다이브 분석을 통해 전략을 강화하거나, 혹은 개선할 수 있는 실마리를 찾을 수 있게 된다.
또한 온라인과 오프라인 소비 방식의 차이도 계산해봐야 한다. 오프라인은 수많은 변수로 인해 소비 패턴이 불확실하다. 조금 추상적으로 접근한다면, 그날 고객의 기분, 날씨에 따라서 소비 여부가 민감하게 결정된다. 반면 온라인은 웹 환경이라는 동일한 조건에서, 웹 디자인과 코드로 짜여진 소비 동선을 통해 계산이 가능한 소비 동선으로 구매가 이루어지기 때문에, 더 미세한 분석도 가능하다는 장점도 놓칠 수 없다.
반성할 점
이번 데이터 분석에서 가장 반성할 점은 작성 코드의 획일성이 아닐까 생각한다. 지나치게 피벗 테이블에 의존했으며, 그로 인해 오히려 조건과 필터링을 거는 코드들이 많아지면서 코드가 산만해졌다. 원천 데이터프레임에서 다양한 조작을 하는 연습이 부족한 것이 원인이라고 개인적으로 생각한다. 원하는 데이터프레임을 만들어 분석을 한다면 생각했던 결과를 뽑아낼 수는 있겠지만, 오히려 그로 인해 내가 사전에 세운 가설에 갖혀버리는, 확증 편향이 발생할 수 있다는 점도 스스로 지적해볼 수 있다.
따라서 조금 더 다채롭게 원천 데이터프레임을 가공할 수 있는 코드 작성 능력을 키우는 것이 앞으로 중요한 과제가 될 것이라고 생각한다.
