[Contents]
1) GPT-2
2) GPT-3
3) ALBERT
4) ELECTRA
5) Light-weight Models
6) Fusing Knowledge Graph into Languages Model
Intro
- GPT-1과 BERT 이후 등장한 다양한 self-supervised pre-training 모델들에 대해 살펴보자
- GPT-1과 BERT 이후 pre-training task, 학습 데이터, self-attention, parameter 수 등에 있어서 여러가지 개선된 모델들이 등장했다
- GPT 시리즈가 2와 3로 이어지면서 일부 데이터셋/task에 대해서는 사람보다 더 뛰어난 작문 능력을 보여주기도 한다
- 이로 인해, model size 만능론이 등장하며 resource가 부족한 많은 연구자들을 슬프게 만들기도 했다
- 다른 연구 방향으로 transformer의 parameter를 조금 더 효율적으로 활용하고 더 나은 architecture/pre-training task를 찾고자 하는 ALBERT와 ELECTRA에 대해서 알아보자
- 두 모델 모두 풍부한 실험과 명확한 motivation으로 많은 연구자들의 관심을 받은 논문이다
- 위에서 설명한 연구방향과는 또 다른 연구 흐름으로 경량화 모델/사전 학습 언어 모델을 보완하기 위한 지식 그래프 integration에 대해 소개한 논문들을 간략하게나마 알아보자
Further Readings
- How to Build OpenAI’s GPT-2: “ The AI That Was Too Dangerous to Release”
- GPT-2
- Illustrated Transformer
- ALBERT: A Lite BERT for Self-supervised Learning of - Language Representations, ICLR’20
- ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators, ICLR’20
- DistillBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, NeurIPS Workshop'19
- TinyBERT: Distilling BERT for Natural Language Understanding, Findings of EMNLP’20
- ERNIE: Enhanced Language Representation with Informative Entities, ACL'19
- KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning, EMNLP'19
GPT-2: Language Models are Unsupervised Multi-task Learners
- GPT-1과 구조의 측면에서는 다를바가 없다
- 다만 transformer 모델의 layer을 더 쌓아서 모델을 키웠다
- 여전히 pre-training task는 language model task이다
- training data는 증가된 사이즈의 데이터를 사용했다
- 주목할점은 데이터셋을 대규모로 사용하는 과정에서 되도록 데이터셋의 퀄리티가 높은, 그래서 데이터로부터 효과적으로 다양한 지식을 배울수 있도록 하는 방식을 유도
- 여러 downstream task가 생성모델이라는 language 생성 task에서의 zero-shot setting으로써 다루어질 수 있다라는 잠재적인 능력도 보여줬다
- zero-shot setting : w/o any parameter or architecture modification
GPT-2: Motivation(decaNLP)
- 전에 나왔던 The Natural Language Decathlon: Multitask Learning as Question Answering
- Byran McCann, Nitish Shirish Keskar, Caiming Xiong, Richard Socher
- 이 논문에서 착안
- 이논문의 핵심은 주어진 문장이 긍정인지 부정인지 예측하는 task와 주어진 문장과 대응하는 대화 시스템에서의 문장을 생성하기 위해서 나와야하는 문장을 생성하는 task,
- 이 두개의 task는 딥러닝 모델 관점에서 보면 서로 모델 구조가 상이하다
- output의 형태가 다르다
- 그렇지만 이 논문에서는 모든 종류으 자연어 처리에 관한 task들이 질의응답으로 다 바뀔수있다라는, 그래서 다양한 task를 통합해서 학습을한 연구사례다
- 예를들어 긍/부정을 예측하는 task에대한 질의응답으로 입력 question은 'Do you think this sentence is positive or negative?'이 될수 있을것이다
- 요약의 task의 경우에는 주어진 문단에 대해서 마지막에 'What is the summarization of the paragraph above?' 가 될수 있다
- 번역 task의 경우 'What is the translated sentence in Korean?' 가 될수 있다
- 이렇게 질문들을 던지면 뒤에나올 질문에 대한 답은 자연어가 생성되는 형태로써 해당하는 답으로 예측 한다
- 이렇게 다양한 task들을 자연어 생성 형태의 output을 가지는 질의응답형태로 통합할수 있다는 가능성을 보여준 연구사례이다
GPT-2: Datasets
- 많은 데이터셋을 사용했지만 높은 수준의 글을 선별적 고르는 방법
- 지식을 효과적으로 배울수 있도록 Reddit이라는 커뮤니티 웹사이트에서 선별한다
- 사용자들이 질문을 달면 다양한 사용자들이 토론형태로 reply하는 방식의 사이트이다
- 질문에 대한 답글들 중 많은 사용자들로 부터 추천받을 글을 수집한다
- 또한 추천을 많이 받은 답글 중 외부 링크를 포함하는 경우 해당 외부링크에 대한 답을 수집한다
- Preprocess
- BERT에서 사용된 word piece와 비슷하게 Byte Pair Encoding(BPE) 라는 subword 레벨에서의 word embedding을 도출해주고 역시 해당 사전을 구축해줄수 있는 알고리즘을 사용했다
GPT-2: Datasets
- 세부적인 모델의 차이점을 제안된 transformer 모델의 self-attention 블락과 비교해보자
- layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network
- additional layer normalization was added after the final self-attention block
- scaled the weights of residual layer at initialization by a factor of where is the number of residual layer
- 각 layer들을 random initialization을 할때 layer 가 위로 가면 갈수록 layer의 인덱스에 비례해서 혹은 반비례해서 initialization 값을 더 작은 값으로 만들어준다
- 이는 layer가 위로 가면 갈수록 거기에 쓰이는 선형변환에 해당하는 값들이 점점더 0에 가까워지도록, 그래서 위쪽에 있는 layer가 하는 역할이 더 줄어들수 있도록 모델을 구성했다
GPT-2: Question Answering
- 모든 task들은 다 질의응답 형태로 바뀔수 있다라는 사실에 입각해서 진행했던 실험중 하나는
- 주어지는 대화형의 질의응답 데이터가 있을때 이 task를 수행하기 위해서는 해당 학습데이터로(label이 존재하는) fine-tuning하는 과정을 일반적으로는 거치게 되지만
- 여기서는 zero-shot learning setting에서 답을 맞추는 task를 수행함에 있어서 conversation을 전부 주고나서 바로 다음에 나올 답을 예측하도록하는 즉, 학습데이터를 하나도 사용하지 않고 task에 바로 예측을 수행했을때 성능이 얼마나 나오는가를 실험해봤다
- 그랬더니 55% 정도의 score가 나왔다
- downstream task를 위한 데이터를 가지고 학습을 한 후에 즉, fine-tuning을 한 후 달성한 성능보다는 못미치지만, 어느정도는 충분히 가능성을 보였다는 사례가있다
GPT-2: Summarization Task
- 요약에 해당하는 task를 수행하기 위해서도 zero-shot learning setting 수행할수 있다
- 이 경우 주어진 글을 전부 주고 GPT-2 가 하는 역할이 다음단어들을 순차적을 생성하는 역할을 하기 때문에 마지막에 TL;DL (Too long, didn't read)이라는 단어를 준다
- 그렇다면 학습데이터의 많은 글들 중에 TL;DL이 나오면 앞쪽에 있었던 글을 한줄 요약하는 형태로 문서가 형성되있는 경우가 많았기 때문에 패턴을 통해서 TL;DL을 바로 다음 단어로 붙임으로써 요약이라는 task를 fine-tuning을 사용하지 않고도 요약을 수행할수 있게됬다

GPT-3: Language Models are Few-Shot Learners
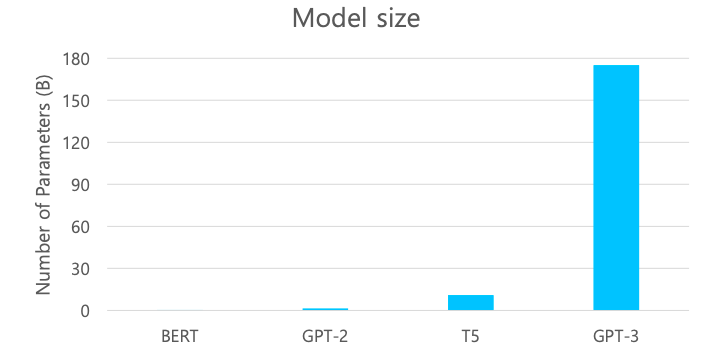
- GPT-2를 개선한 방향은 모델 구조 측면보단 기존의 GPT-2의 모델 사이즈(파라미터 숫자들)에 비해서 비교할수 없을정도로 훨씬 더 많은 파라미터 수를 가지도록 transformer의 self-attention 블락을 많이 쌓은것이다
- 더 많은 데이터와 더 큰 batch size를 통해 학습을 진행했더니 성능이 더 좋아진다는 결론을 내게된 모델이다
- 175 billion parameters
- 96 Attention layers, Batch size of 3.2M
- GPT-2에서의 zero-shot learning setting에서의 가능성을 보여준것을 놀라운 수준으로 끌어올렸다
- prompt: the prefix given to the model
- Zero-shot : predict the answer given only a natural language description of the task
- 거대한 텍스트 데이터로 기학습된 모델을 활용하여 fine-tuning을 하지 않은 상태에서 downstream task를 수행하는 방법
- One-shot : See a single example of the task in addition to the task description
- Few-shot : See a few examples of the task

- Zero-shot performance improves steadily with model size
- Few-shot performance increases more rapidly
- 결론은 큰 모델을 사용할수록 이 모델의 동적인 적응 능력이 훨씬 더 띄어나다

ALBERT: A Lite BERT for Self-supervised Learning of Langauge Representations
- 앞서 설명한 여러 pre-training 모델들은 대규모 메모리 요구량과 많은 학습이 필요로하는 모델 파라미터를 가지는 형태로 점점 더 발전을 해왔다
- 이를 위해서 더 많은 GPU 메모리가 필요로하고
- 거대한 모델을 학습하는데 더 많은 학습데이터와 더 많은 학습 시간이 필요하다
- ALBERT라는 모델에서는 기존의 거대한 BERT모델을 성능에 큰 하락없이, 오히려 성능이 더 좋아지는, 형태를 유지하면서도 모델 사이즈를 훨씬 더 줄여서 학습 시간을 빠르게 만들어주는 모델이다
- Factorized Embedding Parameterization
- Cross-layer Parameter Sharing
- 추가적으로 새로 변형된 형태의 문장 레벨의 self-supervised learning의 pre-training task를 제안했다
- Sentence Order Prediction
Factorized Embedding Parameterization
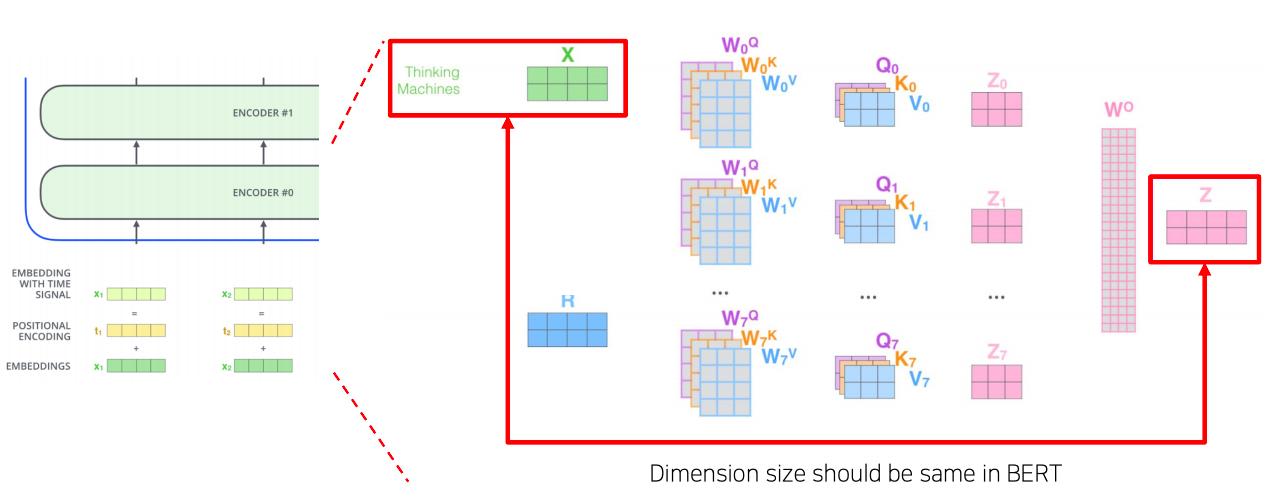
- self-attention block을 계속적으로 쌓아나가면서 만들어지는 전체적인 BERT나 GPT의 모델을 볼때
- residual connection이 있기 때문에 입력에 주어지는 word embedding의 embedding vector의 dimension 수가 첫번째 self-attention 블럭에 들어갈때도 같은 dimension이 유지가 되고
- 다음에는 residual connection 존재하기 때문에 다음 layer의 self-attention의 블럭에서도 같은 dimension이 이어져 결국 끝까지 동일한 dimension 이 유지된다
- 따라서 dimension이 너무 작으면 정보를 담을수 있는 공간이 적어지게 단점이 있을수 있고
- 반면 dimension이 너무 크면 그만큼 모델 사이즈도 커지고 필요로하는 연산량도 증가한다
- 그런대 생각을 해보면 self-attention 블럭을 쌓아나가면서 점점 더 high-level의 유의미한 정보들을 추출해나가는 과정이 딥러닝에서의 layer를 쌓는 과정이라 볼수 있다
- 첫번째 layer에서 contextual 관례의 정보를 고려하지 않고 각 단어별로 독립적으로 상수 형태의 벡터로 주어지는 embedding layer가 있을때
- embedding layer에서의 단어가 가지는 정보는 위에서 전체 문장을 고려해서 각 단어들을 encoding을 해서 정보를 저장해야하는 그때의 hidden state vector들에 비해서는 상대적으로 훨씬 더 적은 정보만을 저장하는 크기로도 충분하다
- 그래서 ALBERT모델에서는 embedding layer에 dimension을 줄이는 추가적인 기법을 제시했다
- V = Vocabulary size
- H = Hidden-state dimension
- E = Word embedding dimension
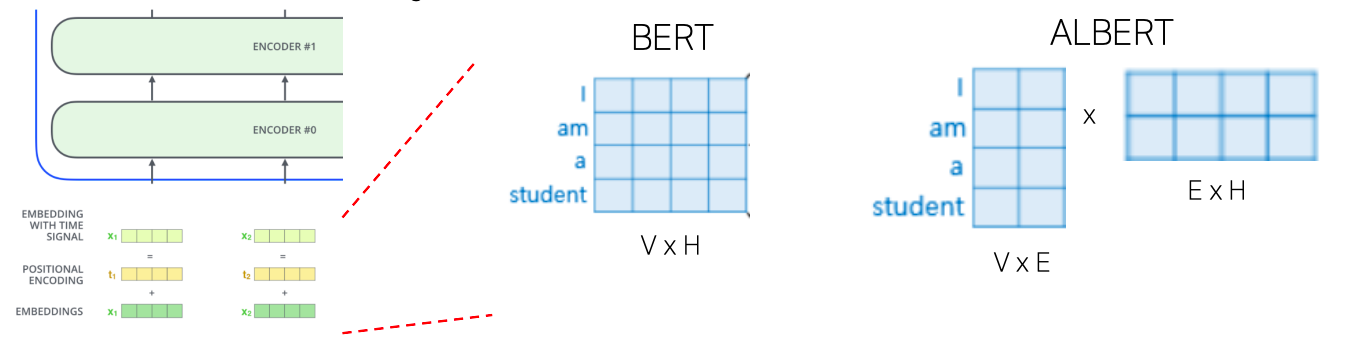
- 차원 축소하는 부분이 embedding vector 값을 내오는데서만 사용하고 attention 모듈의 입력값을 들어가는 부분이랑은 별개다
- 즉, embedding vector 값을 만드는데 hidden state vector와 같은 차원의 수 만큼의 계산을 할 필요가 없어서 애초에 embedding vector 를 반환하는 부분의 계산량만 줄이는 목적이다
- 위쪽에서 계속적으로 나타나는 self-attention 블럭의 hidden state vector의 dimension이 여전히 주어진 입력베턱의 dimension의 사이즈와 동일해야하는 만큼 첫번째 self-attention 블럭에서도 같은 차원의 입력벡터를 받아야한다
- 그렇게 때문에 word embedding vector도 같은 차원이였어야 하는데
- 위 그림을 예시로 들면 각 단어별로 더 적은 차원수인 2차원 벡터만을 가지는 word embedding을 구성했다라고 하는 경우
- 입력이 2차원 벡터로 주어지기 때문에 4차원 벡터를 입력으로 받는, 그래서 residual connection이 다 성립하는 첫번째 self-attention 블럭에 입력 벡터를 만들어주기 위해서 추가적으로 layer() 하나를 더 두고
- 그 layer()는 단어별로 구성되는 2차원 word embedding 벡터를 원래 차원인 4차원으로 늘려준다
- 이 기법을 matrix factorization 기법이라 부르는데
- 이 기법을 통해서 4차원의 word embedding vector 를 2차원의 word embedding vector와 2차원의 word embedding vector에 공통적으로 적용되는 선형변환 matrix 하나가 있다
- 이러한 방식으로 전체적인 파라미터 수를 줄여준다
- 이렇게 하면 실제로 차원수나 여러 계산량이 줄어들수 있는지 살펴보자

- 500개의 각각의 단어들을 모두 100 dimension 벡터로 정의하는데 필요로하는 파라미터는 가 되는 반면
- 100차원을 15차원으로 줄이게되면 필요로하는 파라미터의 갯수는 가 된다
- 이런 방식으로 훨씬 더 적은 파라미터의 수를 학습에 사용하여 계산량을 줄일수 있다
- 여기서 self-attention 블럭 각각이 가지는 실제 학습을 해야하는 파라미터들이 무엇인가를 생각해보면
- 하나의 self-attention 블럭에서 학습해야하는 파라미터는 query, key, value각각의 벡터역할을 하도록 적용되는 선형변환 행렬들이다
- Multi-head를 사용하기 때문에 head수가 가령 8개인 경우는 이러한 선형변환 행렬이 8세트가 있게 된다
- 이를통해 얻어진 attention weighted된 value 벡터들을 각각 얻은 후 각 head별로 나온 이 벡터들을 모두 concat한 후 추가적으로 다시 원래 hidden state vector로 dimension을 줄여주는 output layer로서의 또 다른 추가적인 선형변환 행렬이 있다
- 결국은 학습의 주체는 각 head별로 존재하는 선형변환 matrix와 각 이를 통해 얻어진 output vector를 concat한 후 원래 hiddent state vector로 dimension을 줄여주는 선형변환을 해주는 matrix가 학습에 필요로하는 matrix가 된다
- self-attenion 블럭이 쌓아지면 이러한 행렬들이 self-attention 블럭 별로 존재하게 된다
- 그리고 당연히 두번째 self-attention 블럭은 첫번째 self-attention 블럭과는 별개의 parameter 세트를 가지게 된다
ALBERT: Cross-layer parameter sharing
- shared-FFN : only sharing feed-forward network parameters across layers
- shared-attention : Only sharing attention parameters across layers
- All-shared: share both of them
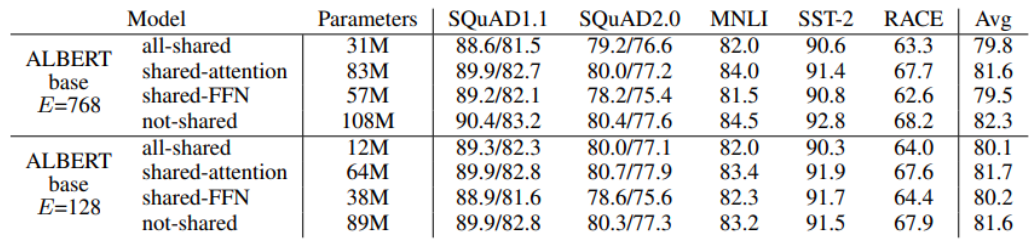
- 두 가지 모두를 share한 경우의 모델이 파라미터 수는 당연히 가장 적다
- 하지만 성능에 있어서는 share 되지 않던 original ALBERT 모델에 비해서 성능이 떨어진다
Albert: Sentence Order Prediction
- Next Sentence Prediction pre-training tasks in BERT is too easy
- predict the ordering of two consecutive segments of text
- 두 문장의 순서를 바꿔 역방향으로된 순서인지 정방향으로된 순서인지 예측하는 binary classification
- Negative samples the same two consecutive segments but with their order swapped
- Negative samples :
- 원래는 next sentence에 해당하지 않는 예제를 학습데이터로 만들기 위해서 두 가지 방법을 택했다
- 랜덤하게 골라진 서로 다른 두 문서에서 추출된 두개의 문장을 [SEP]토큰을 통해 concat 후 next sentence가 아니다 라고 학습 시킨다
- 하지만 이 경우에 두 문서간의 내용이 겹치지 않을 가능성이 높다
- 별개의 두 문서에서 추출될 두 문장 간에는 내용이 굉장히 상이할수 있게 된다
- 즉, 두 문장간의 겹치는 단어들이 거의 존재하지 않을수 있다
- 이경우 next sentence 가 아니라 라고 예측하기 굉장히 쉬운 형태가 될수 있다
- 랜덤하게 골라진 서로 다른 두 문서에서 추출된 두개의 문장을 [SEP]토큰을 통해 concat 후 next sentence가 아니다 라고 학습 시킨다
- 같은 문장에서 인접한 두 문장을 추출할 경우
- 유사한 단어들이 두 분장 간의 많이 나타나기 때문에 두 문장간의 자연스러운 논리적인 흐름
- 즉, 미묘한 고차원적인 추론 과정을 통해서 이 task를 풀어야 되는것이 아니라
- 단순히 내용적으로 볼때 겹치는 단어가 많이 있나 없나로 굉장히 심플하게 task가 풀린다
- 그래서 결국엔 너무 쉬운 task를 BERT를 통해서 pre-training 과정에서 학습을 하게되면 이를 통해 얻게되는 혹은 학습하게 되는 지식이 많이 없는 결과가 나온다
- 이 부분을 주목해서 ALBERT에서의 Sentence Order Prediction task는
- 동일 문서에서 뽑힌 인접한 두 문장을 사용하여 단어의 overlap 측면에서는 정방향이나 역방향으로의 순서간의 차이가 없는
- 그렇기 때문에 논리적인 흐름을 주의깊게 파악해야 이 task를 풀수있는 형태로 pre-training task를 제안했다
- 이를 통해 성능향상을 얻을수 있게 되었다
- 원래는 next sentence에 해당하지 않는 예제를 학습데이터로 만들기 위해서 두 가지 방법을 택했다
- Negative samples :
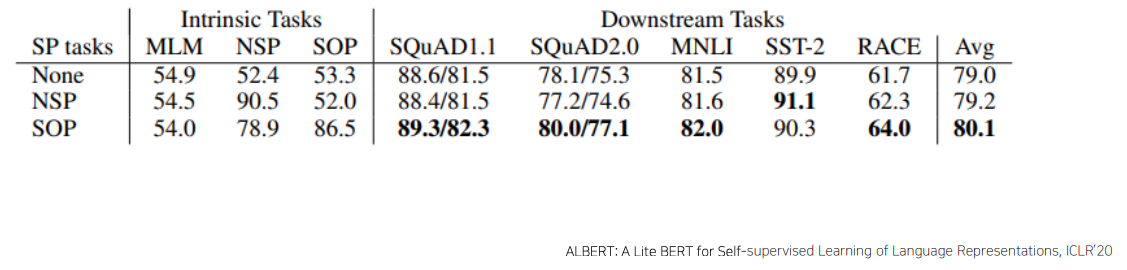
ALBERT: GLUE Results
- 다양한 자연어 처리 task에 대해서 ALBERT 모델이 전체적으로 가장 좋은 성능을 내느것을 볼 수 있다
- ALBERT 에서도 모델사이즈나 필요로하는 파라미터 수를 변환해서 더 큰 모델을 사용했을때 더 좋은 성능을 보인다는것을 알수 있다
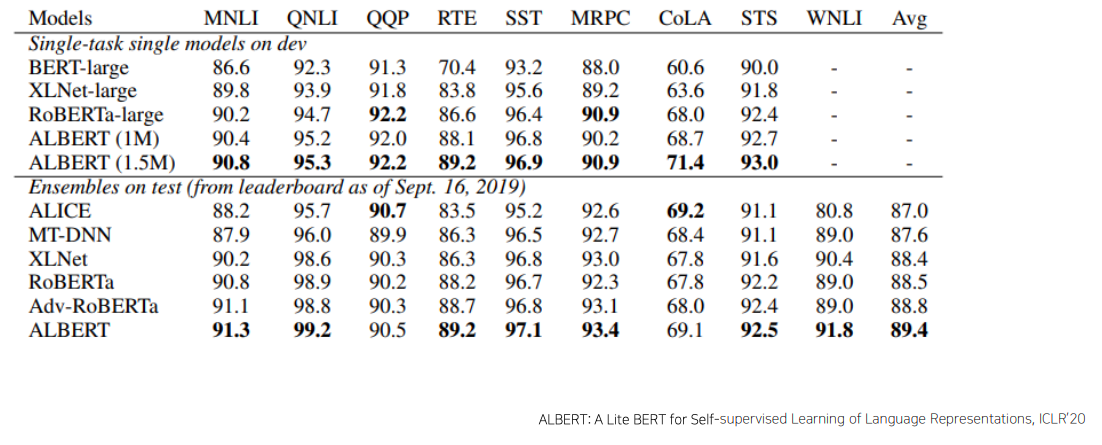
- ALBERT 에서도 모델사이즈나 필요로하는 파라미터 수를 변환해서 더 큰 모델을 사용했을때 더 좋은 성능을 보인다는것을 알수 있다
ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- GPT, BERT와는 다른형태로 pre-training을 수행하는 모델이다
- BERT에서 사용한 Masked Language Modeling 혹은 GPT계열에서 사용한 다음 단어를 예측하는 standard 한 language modeling task에서 한발 더 나아가서
- langauge modeling을 통해 단어를 복원해주는 모델(Generator) 하나 더 둔다
- 그리고 이 모델이 masked language modeling을 수행하는 경우 주어진 문장에서 일부단어를 [MASK]단어로 치환하고 이를 다시 예측한 단어로 복원했을때 생성된 문장에서 각각의 단어가 대체된 단어인지 혹은 원래부터 있었던 단어였는지를 단어별로 예측하는 형태의 구분자(Discriminator)라는 두번째 모델를 별도의 둔 형태가 ELECTRA모델의 핵심적인 특징이 된다
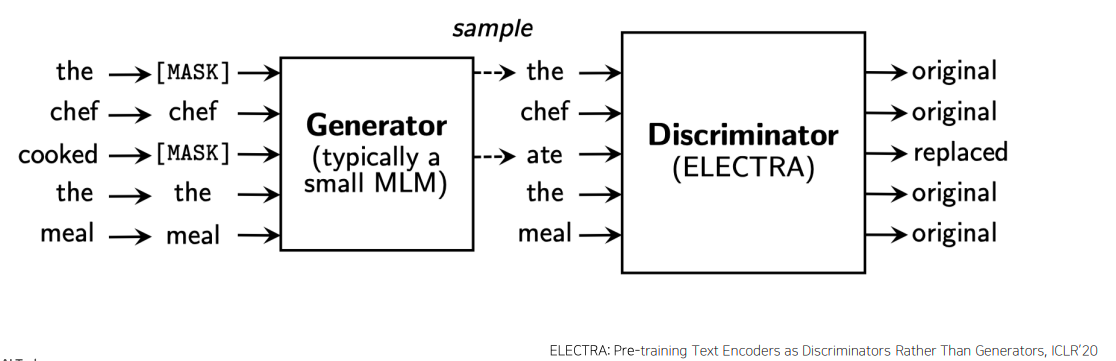
- Generator는 BERT모델로 생각할 수 있다
- Masked Langauge Modeling을 통해서 기존 학습데이터에서 일부 단어를 [MASK]토큰으로 대체한 것을 입력으로 받아서 [MASK]된 부분을 다시 복원한 문장을 다시 입력으로 받는 두번째 모델이 존재한다
- Discriminator 또한 기존에 BERT나 GPT모델과 비슷하게 transformer에서 제안된 self-attention 블럭을 쌓은 형태의 모델이다
- 이모델에서는 각 단어별로 예측은 하는데
- 이 예측은 binary classification으로써 이 단어가 원래 있었던 단어다 혹은 이 단어는 어색한 부분이 있기 때문에 replaced된 단어라는 예측하는 모델이 된다
- 두 가지 모델이 서로 적대적관계 (Adversarial Learning)의 형태로 학습이 진행된다
- 이러한 모델은 대표적으로 Generative Adversarial Network(GAN)이다
- GAN 모델에서 사용된 아이디어를 착안해서 자연어 처리에서 pre-training 모델을 제안한것이다
- 이 과정을 반복적으로 수행함으로써 discriminator를 점점 고도화 시킬수 있게 된다
- 최종적으로 이러한 방식으로 모델 학습을 진행한 후에는 pre-trained된 모델로써
- Generator 부분에 해당하는 masked language modeling을 담당하는 부분을 pre-training 모델로 사용하는것이 아닌
- Discriminator 모델을 실제 다양한 다른 main downstream task들에 fine-tuning에 형태로 사용하는 pre-trained된 모델로 사용하게 된다
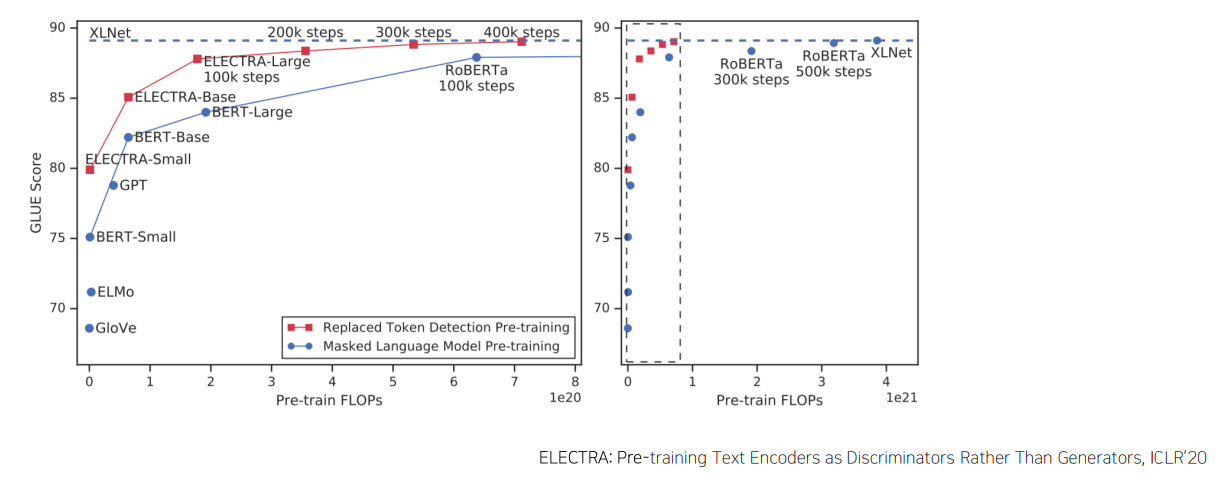
ELECTRA: Replaced token detection pre-training VS Masked Language Model pre-training
- Outperforms MLM-based methods such as BERT given the same model size, data, and compute
- pre-training 하는데 사용되는 학습에 필요한 계산량을 기준으로 본다면 계산량이 더 많아질수록 모델의 성능이 올라간다
- ELECTRA 모델의 경우 같은 계산량에 비해 더 좋은 성능을 보여준다
Light-weight Models
- pre-trained된 모델을 다양한 방식으로 고도화하는 연구들이 존재한다
- 한 방향으로써는 모델의 경량화라는 부분이 존재한다
- 경량화 모델은 기존의 BERT, GPT, ELECTRA등의 모델들이 self-attention 블록을 많이 쌓음으로써 더 좋은 성능을내는
- 그렇지만 이러한 모델을 pre-training하는데 많은 GPU resource와 학습 시간 및 계산량이 필요했던
- 그래서 이것이 모델들을 실제 다양한 연구나 현업에 활용하는데 걸림돌이 되었다면
- 비대해진 모델을 좀 더 적은 layer 혹은 parameter 수를 가지는 형태의 경량화된 모델로 발전시키는 연구가 된다
- 경량화 모델의 연구 추세는 기존의 큰 사이즈 모델이 가지던 성능을 최대한 유지하면서도 모델의 크기와 계산속도를 줄이는것에 초점이 맞춰져있다
- 경량화된 모델은 cloud server나 고성능의 GPU resource를 사용하지 않고서도, 휴대폰 등 소형 device에서도 이러한 모델을 load해서 더 적은양의 전력 소모량으로 빠르게 계산을 수행하고자 할 때 주로 사용된다
- 모델을 경량화하는 방식은 다양하게 존재하지만 여기서는 Distillation 기법을 사용한 두 개의 모델을 소개한다
- DistillBERT (NeurlPS 2019 Workshop)
- teacher, student model이 존재하는데
- teacher model은 student model을 가르치는 역할을 한다
- student model은 teacher model에 비해서는 layer수나 파라미터 측면에서 더 작은 경량화된 형태의 모델로 설계되어서
- 훨씬 더 큰사이즈의 모델인 teacher model이 내는 output이나 패턴을 잘 모사할수 있도록 학습을 진행한다
- TinyBERT (Findings of EMNLP 2020)
- 마찬가지로 teacher, student model이 있다
- distillBERT와는 달리 target distribution을 모사해서 이를 ground truth로써 softmax를 적용해서 teacher모델을 닮도록 student모델을 학습하도록하는 방식뿐만 아니라
- embedding layer 그리고 각 self-attention 블록이 가지는 등의 attention matrix 그리고 결과로 나오는 hidden state vector들 까지도 유사해지도록
- 즉, 중간결과 까지도 student model이 닮도록하는 형태로 Mean squared error(MSE) loss를 통해 학습을 진행한다
- 일반적으로 student model의 hidden state vector가 기존 techer model의 hidden state vector의 차원 수 보다 작을수 있기 때문에 차원이 달라지므로써 student model 벡터가 teacher model 벡터와 유사해지도록 학습하는 것이 어려울수 있다
- 그래서 이 논문에서는 서로 차원이 다른 hidden state vector를 최대한 유사해지도록 하고자하는 loss 적용하기 위해 teacher student의 hidden state vector가 더 적은 수의 벡터로 차원이 변환되는 형태의 학습가능한 fully connected layer 하나를 더 두어서 dimension간의 mismatch를 해결한다
- TinyBERT의 핵심은 가장 최종 output 즉, vocab size만큼의 softmax output으로 나오는 예측값만 똑같아 지도록 학습할 뿐만 아니라 중간 결과물들도 teacher와 student model들 간의 최대한 유사해지도록 학습을 한다
- DistillBERT (NeurlPS 2019 Workshop)
Fusing Knowledge Graph into Language Model
- 최신연구 흐름은 기존의 pre-training 모델과 지식그래프 혹은 knowledge graph라고 불리는 외부적인 정보를 잘 결합하는 형태의 연구방향이다
- BERT라는 모델이 등장한 이후에 이 모델이 언어적 특성을 잘 이해하고 있는지 아닌지 에대한 부분이 어떤것이지를 분석하는 연구들이 많이 진행됬다
- 결론적을 BERT는 주어진 문장이 있을때 혹은 보다 더 긴 글이 있을때 문맥을 잘 파악하고 각 단어들간의 유사도 및 관계를 잘 파악하긴 하지만
- 주어져 있는 문장에 포함되있지 않은 추가적인 정보가 필요한 경우에는 그 정보를 효과적으로 활용하는 능력은 잘 보이지 못한다
- 예를들어 주어진 문장에서 '땅을 팠다' 라는 문장이 주어져 있는데, 앞뒤 문맥을 보는데 '꽃을 심기 위해서 땅을 팠다' 라는 문장이 있다라고 생각을하고
- 또 다른 문장의 경우 '집을 짓기 위해서 땅을 팠다' 라는 문장이 주어져 있다고 생각해보자
- 그랬을때 question answering task를 예로 들었을때 '땅을 무슨 도구로 팠을까?' 를 질문으로 한다면
- 앞서 나온 문장에서는 땅을 무엇으로 팠는지에 대한 도구의 정보는 나타나있지 않는다
- 사람의 경우 이러한 질문에 답을 아는 이유는 주어진 문장에서 담고있는 정보뿐만 아니라 기본적으로 가지고 있는 외부지식들이 자연어 처리할때 중요한 요소가 된다
- 그래서 외부지식들이 전통 인공지능 분야에서 knowledge graph라는 형태로 표현이 된다
- 이 경우는 '땅' 이라는 개체와 '파다' 라는 행동 개체, 이 두가지의 개체를 이어주는 관계로써 '부삽', '포크레인' 등의 도구가 있을수 있다
- 세상에 존재하는 다양한 개념과 개체들을 잘 정의하고 이들간의 관계를 잘 정형화해서 만들어둔것이 knowledge graph이다
- BERT의 약점을 보안하고자 language modeling 혹은 pre-training 모델과 knowledge graph를 잘 결합해서 외부지식이 필요한 경우에도 다양한 task의 성능을 높이는 연구가 있다

아기개발자