[Contents]
1) 그래프란 무엇이고 왜 중요할까?
2) 실제 그래프는 어떻게 생겼을까?
그래프란 무엇이고 왜 중요할까?
- 그래프 이론, 그래프 관련 필수 개념들을 소개
- 그래프는 다양한 복잡계(Complex Network)를 분석할 수 있는 언어이다
- 그래프를 통해서 다양한 문제들에 접근하기 전에 정점, 간선, 방향성, 가중치 등 그래프 이론에서 사용하는 개념들에 대해서 배워본다
- 각 정의들을 명확하게 이해하자
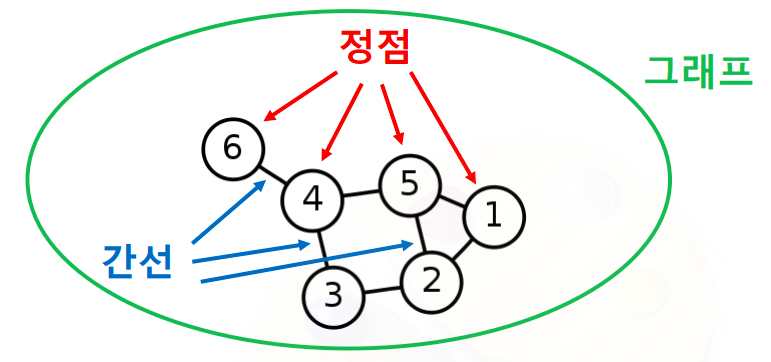
- 그래프는(graph)는 정점 집합과 간선 집합으로 이루어진 수학적 구조이다
- 정점 : 점 혹은 원으로 그린다
- 간선 : 두 개의 정점을 연결하는 선
- 모든 점점 쌍이 반드시 간선으로 직접 연결되는 것은 아니다
- 아래 예시를 보면 3과 6은 간선으로 직접 연결되어 있지 않다
- 정점들과 간선들로 이루어진 전체 시스템을 그래프라고 부른다
- 그래프는 네트워크 라고도 불린다
- 정점(vertex)은 노드(node)로 간선은 엣지(edge) 혹은 링크(link)로도 불린다
그래프가 왜 중요할까?
- 우리 주변에는 많은 복잡계(complex system)가 있다
- 사회 는 70억 인구로 구성된 복잡계이다
- 통신 시스템 은 전자 장치로 구성된 복잡계이다
- 그 밖에도, 정보 와 지식, 뇌, 신체 역시 복잡계로 생각할 수 있다
- 이런 여러가지 복잡계가 가진 공통적인 특성은 무엇일까?
- 구성 요소간의 복잡한 상호작용이다
- 사회라는 복잡계도 70억인구가 서로 독립적으로 살아가는 것이 아니라 서로 상호작용을한다
- 전자장치들도 서로 wifi혹은 여러가지 인터넷 연결을 통해 서로와 상호작용을한다
- 이러한 상호작용이 복잡계를 복잡하게 만든다
- 구성 요소간의 복잡한 상호작용이다
- 이런 복잡계를 어떻게 표현할까?
- 정답은 그래프(graph) 이다!
- 그래프는 복잡계를 효과적으로 표현하고 분석하기 위한 언어 이다
- 그래프가 복잡계를 어떻게 표현하는지에 관한 예시:
- 예1) facebook, linkedin, line, kakaotalk 같은 소셭 네트워크이다

- 이런 소셜 네트워크에 사용자들 혹은 계정들을 그래프에 정점이라 생각할수 있다
- 그리고 두 계정사이의 친구관계가 있는 경우엔 간선으로 연결하고 친구관계를 맺지 않은 경우에는 간선으로 연결하지 않는다
- 이런식으로 온라인 소셜 네트워크들을 자연스럽게 그래프로 표현할수 있다
- 예1) facebook, linkedin, line, kakaotalk 같은 소셭 네트워크이다
- 수많은 예시들이 있다

정리
- 복잡계를 복잡하게 만드는 것은 복잡계를 구성하는 요소들 간의 상호작용이다
- 상호작용을 표한하기 위한 수단으로 그래프가 널리 사용된다
- 복잡계를 이용하고, 복잡계에 대한 정확한 예측을 하기 위해서는 복잡계 이면에 있는 그래프에 대한 이해가 반드시 필요하다
- 그래프 왜 공부해야할까?
- 그래프를 공부함으로써 복잡계가 등장하는 수많은 분야에 활용할 수 있다
- 전산학, 물리학, 생물학, 화학, 사회과학 등이 그 예시이다
그래프 관련 인공지능 문제
- 정점 분류(node classification) 문제
- 정점이 여러 유형을 가진 경우, 각 정점의 유형을 추측하는 문제이다
- 트위터에서의 공유(retweet) 관계를 분석하여, 각 사용자의 정치적 성향을 알 수 있다
- 단백질의 상호작용을 분석하여 단백질의 역할을 알아낼 수 있다
- 연결 예측(link prediction) 문제
- 거시적 관점과 미시적 관점에서 살펴볼수 있다
- 거시적 관점에서 연결 예측 문제는 주어진 그래프가 어떻게 성장할지를 예측하는 문제이다
- 페이스북 소셜 네트워크는 어떻게 진화할까?
- 점점더 성장할까 혹은 점점더 줄어들까를 예측하는 문제가 연결 예측 문제라 생각할수 있다
- 페이스북 소셜 네트워크는 어떻게 진화할까?
- 미시적 관점에서의 연결 예측 문제는 각 정점이 앞으로 어떤 정점과 연결되지를 예측하는 문제이다
- 추천 문제와도 밀접하게 연관되있다
- 많은 추천 시스템들이 추천할때 각 사용자가 앞으로 어떤 물건을 구매할지를 예측해서 예측을 토대로 추천하는 시스템
- 추천에는 사용자가 어떤 물건을 살지 예측할 뿐만 아니라 어떤 물건을 구매해야 만족도가 높을까 등 여러가지 복잡한 요소가 있다
- 추천 문제와도 밀접하게 연관되있다
- 군집 분석(community detection) 문제
- 서로 밀접하게 연결된 정점들의 집합 즉, 군집을 찾아내는 문제이다
- 많은 그래프에서 군집들은 의미있는 구조를 나타내는 경우가 많이 있다
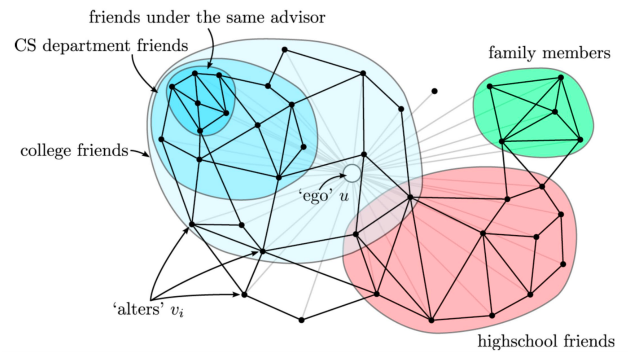
- 위 그림에서 연결 관계로부터 사회적 무리(social circle)을 찾아낼 수 있다
- 랭킹(ranking) 및 정보 검색(information retrieval) 문제
- 웹(web) 이라는 거대한 그래프로부터 어떻게 중요한 웹페이지를 찾아낼 수 있을까?
- 웹이라는 것을 거대한 그래프로 표현하고 웹페이지들간의 연결관계 분석을 통해 중요하고 관련성있는 웹페이지들을 찾아낸다
- 웹(web) 이라는 거대한 그래프로부터 어떻게 중요한 웹페이지를 찾아낼 수 있을까?
- __정보 전포(information cascading) 및 바이럴 마케팅(viral marketing) 문제
- 소셜 네트워크를 통해 많은 정보들이 전파된다
- 어떻게 해야 정보가 멀리 그리고 많은 사람들에게 퍼져나가게 할 수 있을지에 대한 문제
그래프의 유형 및 분류
- 그래프를 다양한 기준을 통해 유형을 분류할 수 있다
| 방향이 없는 그래프(undirected graph) | 방향이 있는 그래프(directed graph) |
|---|---|
| 간선에 방향이 없는 그래프(두 정점이 같은 위치를 자치하고 있는 경우) | 간선에 방향이 있는 그래프(주체와 대상이 분리될 수 있는 경우) |
| 협업 관계 그래프 | 인용 그래프 |
| 페이스북 친구 그래프 | 트위터 팔로우 그래프 |
 |  |
| 가중치가 없는 그래프(unweighted graph) | 가중치가 있는 그래프(weighted graph) |
|---|---|
| 간선에 가중치가 없는 그래프 | 간선에 가중치가 있는 그래프(간선에 숫자들이 부여되는 경우) |
| 웹 그래프 | 전화 그래프(전화를 두 사람이 몇번 주고받았는지 표현 가능) |
| 페이스북 친구 그래프 | 유사독 그래프 |
|  |
| 동종 그래프(unpartite graph) | 이종 그래프(bipartite graph) |
|---|---|
| 동종 그래프는 단일 종류의 장점 을 가진다 | 이종 그래프는 두 종류의 정점을 가진다 (다른 종류의 정점 사이에만 간선이 연결된다) |
| 웹 그래프 | 영화 출연 그래프(배우, 영화) |
| 페이스북 친구 그래프 | 전자 상거래 구매내역(사용자, 상품) |
 | 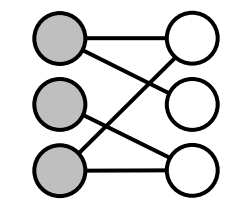 |
- 전자 상거래 구매 내역은 어던 유형의 그래프일까?
- 방향성이 없고, 가중치가 있는 이종 그래프
- 사람이 상품을 구매하는 것이기 때문에 방향성을 부여할수 있다
- 하지만 어차피 모든 구매라는 것이 사용자로 부터 상품으로 이어가는것 이기 때문에 방향성을 굳이 표시를 했을때 복잡도가 높아지는것에 비해서 얻는 추가적인 정보가 없기 때문에 단순하게 방향성이 없는 그래프로 표현을 하는것이다

그래프 관련 필수 기초 개념
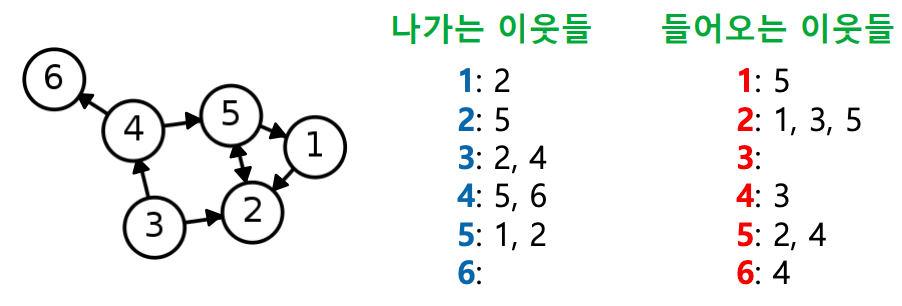
- 보통 정점들의 집합을 , 간선들의 집합을 , 그래프를 로 적는다
- 정점의 이웃(neighbor)은 그 정점과 연결된 다른 정점을 의미한다
- 정점 의 이웃들의 집합을 보통 혹은 로 적는다
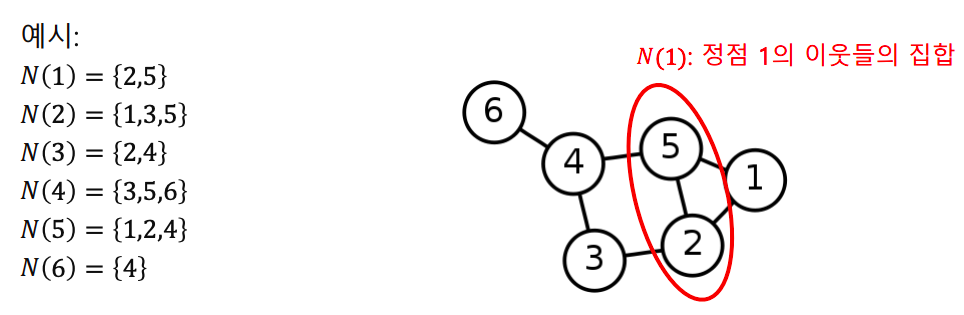
- 방향성이 있는 그래프에서는 나가는 이웃과 들어오는 이웃을 구분한다
- 정점 에서 간선이 나가는 이웃(out-neighbor)의 집합을 보통 로 적는다
- 정점 에서 간선이 들어오는 이웃(in-neighbor)의 집합을 보통 로 적는다

그래프의 표현 및 저장
- 간선 리스트(edge list): 그래프를 간선들이 리스트로 저장
- 각 간선은 해당 간선이 연결하는 두 정점들의 순서쌍(pair)으로 저장된다

- 방향성이 있는 경우에는 (출발점, 도착점) 순서로 저장된다
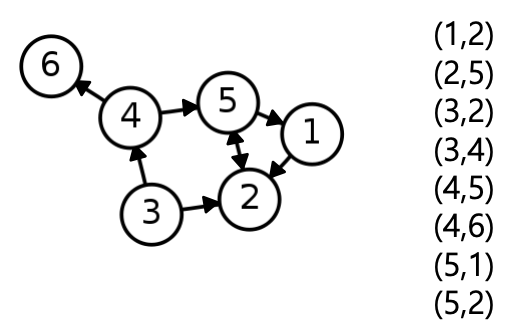
- 인접 리스트(adjacent list) : 방향성이 없는 경우:
- 각 정점의 이웃들을 리스트로 저장
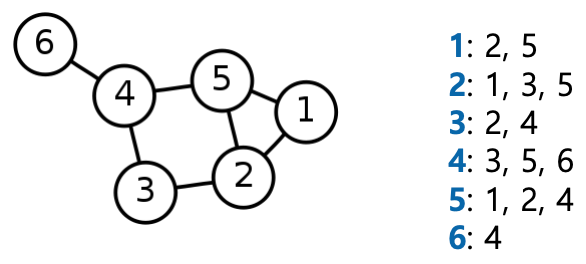
- 인접 리스트(adjacent list) : 방향성이 있는 경우:
- 각 정점의 나가는 이웃들과 들어오는 이웃들을 각각 리스트로 저장
-
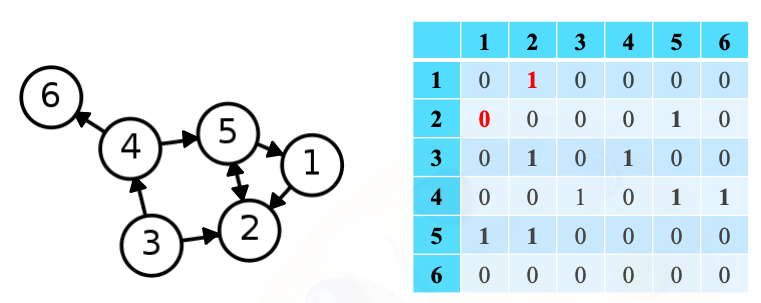
인접 행렬(adjacency matrix) : 방향성이 없는 경우
- 정점 수 정점 수 크기의 행렬
- 정점 와 사이에 간선이 있는 경우, 행렬의 행 열 (그리고 행 열) 원소가 1
- 정점 와 사이에 간선이 없는 경우, 행렬의 행 열 (그리고 행 열) 원소가 0
- 위 정의에 따라서 이 행렬은 대각행렬인 것을 볼수 있다
-
인접 행렬(adjacency matrix) : 방향성이 있는 경우
- 정점 수 정점 수 크기의 행렬
- 정점 와 사이에 간선이 있는 경우, 행렬의 행 열 원소가 1
- 정점 와 사이에 간선이 없는 경우, 행렬의 행 열 원소가 0

NetworkX를 이용하여 그래프를 표현하고 저장하기
#그래프를 인접 리스트로 저장
nx.to_dict_of_lists(G)
# 그래프를 간선 리스트로 저장
nx.to_edgelist(G)
# 그래프를 인접 행렬(일바 행렬)로 저장
nx.to_numpy_array(G)
# 그래프를 인접 행렬(희소 행렬)로 저장
nx.to_scipy_sparse_matrix(G)- 일반 행렬 은 전체 원소를 저장하므로 정점 수의 제복에 비례하는 저장 공간을 사용
- 희소 행렬 은 0이 아닌 원소만을 저장하므로 간선의 수에 비례하는 저장 공간을 사용
- 예시) 정점의 수가 10만, 간선의 수가 100만이라면
- 정점의 수의 제곱(100억) >> 간선의 수 (100만)
- 희소행렬이 항상 좋은 것은 아니다
- 행렬의 대부분의 원소가 0이 아닌 경우에는 일반행렬을 사용할 경우 속도가 훨씬 빠르다
실제 그래프는 어떻게 생겼을까?
- 실제 그래프의 다양한 패턴들을 배운다
- 실제 그래프는 다양한 복잡계의 정보를 담고 있다
- 예를 들어서, 페이스북 네트워크에서 사람을 정점으로 나타내고, 사람들의 친구 관계를 간선으로 나타낼 수 있다
- 이러한 실제 그래프들은 랜덤으로 생성한 그래프 모델들과 다른 패턴들을 보이고, 우리는 실제 그래프의 패턴들을 이용해서 효과적으로 그래프를 분석할 수 있다
- 이번에는 실제 그래프와 랜덤 그래프를 간단하게 알아보고, 작은 세상 효과, 연결성의 두터운 꼬리 분포, 군집 구조 등 실제 그래프의 다양한 패턴들을 배운다
- 실제 그래프가 가진 다양한 패턴들에 집중하자
Further Reading
실제 그래프 vs 랜덤 그래프
- 실제 그래프(real graph)란 다양한 복잡계로 부터 얻어진 그래프를 의미한다
- 소셜 네트워크, 정자상가러래 구매 내역, 인터넷, 웹, 뇌, 단백질 상호작용, 지식 그래프 등
- 여기서는 MSN 메신저 그래프를 실제 그래프의 예시로 사용한다
- MSN 메신저 그래프
- 1억 8천만 정점(사용자)
- 13억 간선(메시지를 주고받은 관계)
- MSN 메신저 그래프
- 랜덤 그래프(random graph)는 확률적 과정을 통해 생성한 그래프를 의미한다
- 여기서는 에르되스(Erdos)와 레니(Renyi)가 제안한 랜덤 그래프 모델을 사용한다
- 에르되스-레니 랜덤 그래프(Erdos-Renyi Random graph)
- 임의의 두 정점 사이에 간선이 존재하는지 여부는 동일한 확률 분포에 의해 결정된다
- 에르되스-레니 랜덤그래프 는
- 개의 정점을 가진다
- 임의의 두 개의 정점 사이에 간선이 존재할 확률은 이다
- 정점 간의 연결은 서로 독립젹(independent)이다
- 즉, 정점 1번과 2번이 연결됬다는 사실이 1번과 3번 사이에 간선이 존재할 확률에 영향을 미치치 안흔다
- Quiz. 에 의해 생성될 수 있는 그래프와 각각의 확률은?
- Answer:
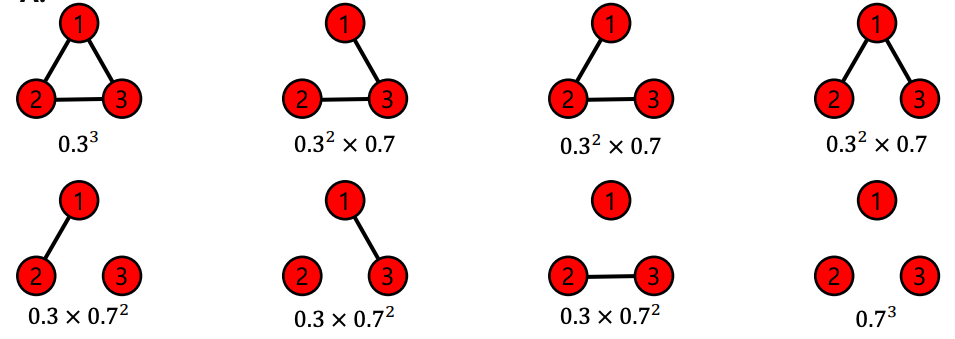
- Answer:
작은 세상 효과
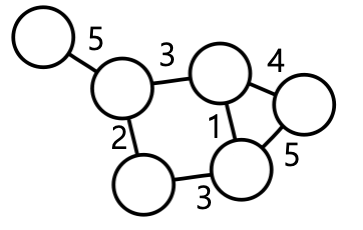
- 필수 개념: 경로, 거리 및 지름
- 정점 와 의 사이의 경로(path) 는 아래 조건을 만족하는 정점들의 순열(sequence)이다
- 에서 시작해서 에서 끝나야 한다
- 순열에서 연속된 정점은 간선으로 연결되어 있어야 한다

- 위 그림에서 정점 1과 8사이의 경로 예시:
- 1,4,6,8
- 1,3,4,6,8
- 1,4,3,4,6,8
- 정점 1과 8 사이의 경로가 아닌 순열의 예시:
- 1,6,8
- 1,3,4,5,6,8
- 경로의 길이는 해당 경로 상에 놓이는 간선의 수로 정의된다
- 경로 1,4,6,8의 길이는 3이다
- 경로 1,3,4,6,8의 길이는 4이다
- 경로 1,4,3,4,6,8의 길이는 5이다
- 정점 와 의 사이의 거리(distance) 는 와 사이의 최단 경로의 길이다
- 예: 위 그림에서
- 정점 1과 8사이의 최단 경로(shorted path)는 1,4,6,8 이다
- 해당 경로의 길이는 3이다
- 따라서 정점 1과 8사이의 거리는 3이다
- 예: 위 그림에서
- 그래프의 지름(diameter) 은 정점 간 거리의 최댓값이다
- 예: 위 그림에서
- 그래프에서의 지름은 4이다
- 이는 정점 2와 8사이의 최단 경로의 거리와 같다
- 예: 위 그림에서
- 정점 와 의 사이의 경로(path) 는 아래 조건을 만족하는 정점들의 순열(sequence)이다
- 작은 세상 효과(small-world effect)
- 실제 그래프의 임의의 두 정점 사이의 거리가 작다는 사실을 작은 세상 효과라 부른다
- 한국에서는 '사동의 팔촌'이 먼 관계를 나타내는 표현으로 사용된다
- 즉, 아무리 먼 관계도 결국은 사돈의 팔촌(10촌 관계)이다
- 작은 세상 효과는 높은 확률로 랜덤 그래프에도 존재한다
- 모든 사람이 100명의 지인이 있다고 가정해보자
- 다섯 단계를 거치면 최대 100억(= )명의 사람과 면결될 수 있다
- 단, 실제로는 지인이 중복되기 때문에 100억 명보다는 적은 사람일 것이다
- 하지만 여전히 많은 사람과 연결될 가능성이 높다
- 하지만 모든 그래프에서 작은 세상 효과가 존재하는 것은 아니다
- 체인(chain), 사이클(cycle), 격자(grid) 그래프에서는 작은 세상 효과가 존재하지 않는다
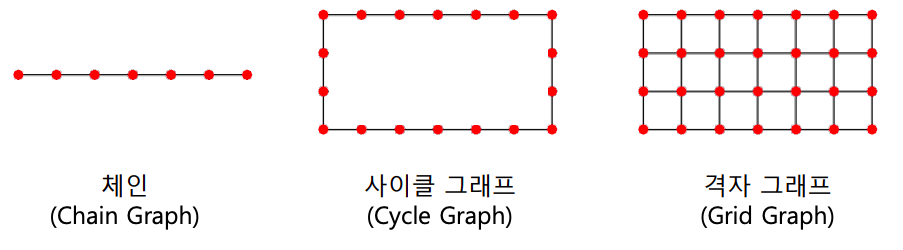
- 즉, 체인, 사이클, 격자 그래프에서는 서로 거리가 먼 정점들이 존재하고, 이 거리는 그래프의 크기가 커짐에 따라서 함께 커지게 된다
- 체인(chain), 사이클(cycle), 격자(grid) 그래프에서는 작은 세상 효과가 존재하지 않는다
연결성의 두터운 꼬리 분표
- 필수 개념: 연결성
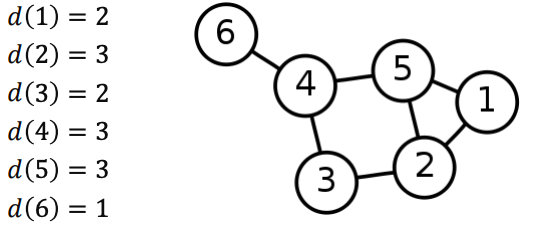
- 정점의 연결성(degree) 은 그 정점과 연결된 간선의 수를 의미한다
- 정점 의 연결성 은 해당 정점의 이웃들의 수와 같다
- 보통 정점 의 연결성은 혹은 로 적는다
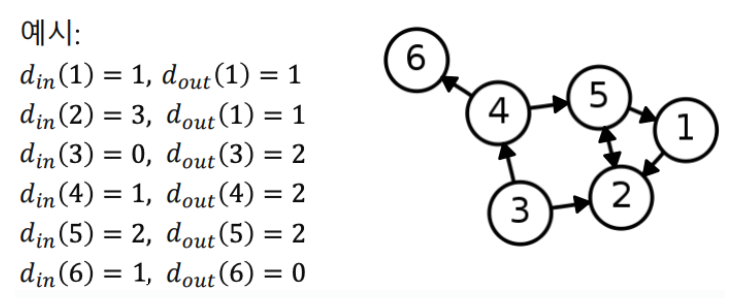
- 정점의 나가는 연결성(out degree)은 그 정점에서 나가는 간선의 수를 의미한다
- 보통 정점 의 나가는 연결성은 혹은 으로 표시한다
- 정점의 들어오는 연결성(in degree)은 그 정점으로 들어오는 간선의 수를 의미한다
- 보통 정점 의 들어오는 연결성은 혹은 으로 표시한다
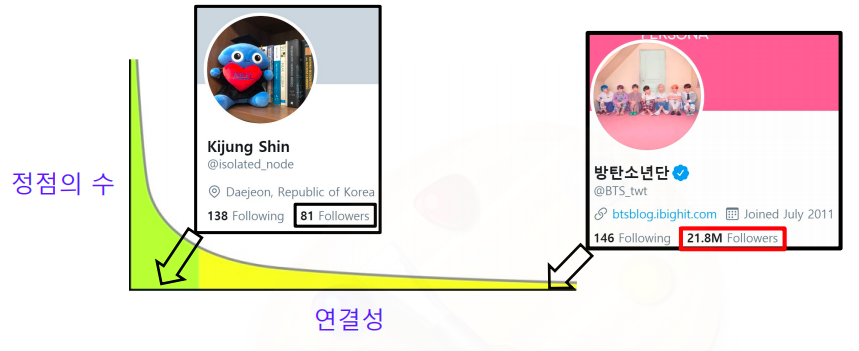
- 실제 그래프의 연결성 분포는 두터운 꼬리(heavy tail) 를 갖는다
- 즉, 연결성이 매우 높은 허브(hub) 정점이 존재함을 의미한다
- 위 그래프는 각 연셜성에 따른 정점의 수를 나타내는 그래프이다
- 연결성이 낮은 정점이 많고 높은 정점이 적어서 그래프 꼬리가 길어지는 형태
- 위 그림에서 트위터의 들어오는 연결성 즉, 팔로워 수를 비교해보자
- Kijung Shin의 팔로워 수는 81명 뿐이지만
- 방탄 소년단의 팔로워 수는 21.8M명 인걸 볼수 있다
- Kijung Shin과 방탄 소년단의 키도 물론 차이가 나지만 방탄소년단이 Kijung Shin보다 100만배 더 키가 크지는 않다
- 하지만 연결성 분포는 정규분포가 아닌 두터운 꼬리 분포를 갖기 때문에 이렇게 극단적인 차이가 발생할 수 있다
- 즉, 연결성이 매우 높은 허브(hub) 정점이 존재함을 의미한다
- 반면, 랜덤 그래프의 연결성 분포는 높은 확률로 정규 분포 와 유사하다
- 이 경우, 연경성이 매우 높은 허브(hub) 정점이 존재할 가능성은 0에 가깝다
- 정규 분포와 유사한 예시로는 키의 분포가 있다
- 키가 10 미터를 넘는 극단적인 예외는 존재하지 않는다

- 정리하면 실제 그래프는 연결성이 두터운 꼬리 분포를 가지고 허브 정점들이 존재할 가능성이 높다
- 반면, 랜덤 그래프의 연결성은 꼬리가 얇아서 보이지 않고, 연결성이 높은 허브 정점이 존재할 확률이 극히 낮다
거대 연결 요소
- 필수 개념 : 연결요소
- 연결 요소(connected component) 는 다음 두 조건들을 만족하는 정점들의 집합을 의미한다
- 연결 요소에 속하는 정점들은 경로로 연결될 수 있다
- 위의 조건을 만족하면서 정점을 추가할 수 없다
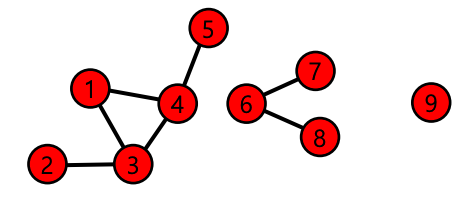
- 예: 아래 그래프에는 3개의 연결 요소가 존재한다
- {1,2,3,4,5}, {6,7,8}, {9}
- 이 연결요소들은 첫번째 조건을 만족한다, 즉 하나의 연결 요소에서 임의로 두개의 정점을 골랐을때, 두 개의 정점은 경로를 통해 연결된다
- {1,2,3,4}는 조건 (2)를 위배한다. 1번 조건을 만족하면서 5번이라는 새로운 정점을 추가할수 있기 때문에 두 번째 조건을 만족하지 않는다. 따라서 {1,2,3,4}는 연결요소가 아니다
- {6,7,8,9}는 조건 (1)를 위배한다
- 실제 그래프에는 거대 연결 요소(Giant Connected Component) 가 존재한다
- 거대 연결 요소는 대다수의 정점을 포함한다
- MSN 메신저 그래프에는 99.9%의 정점이 하나의 거대 연결 요소에 포함된다
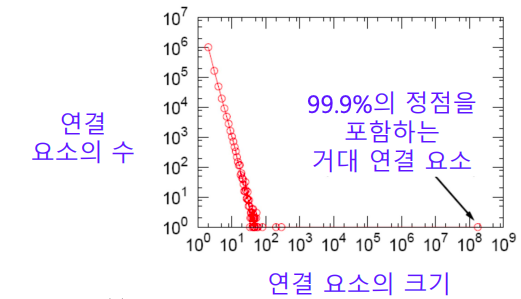
- 연결 요소들의 크기의 분포를 나타낸 그래프
- 랜덤 그래프에도 높은 확률로 거대 연결 요소(Giant Connected Component) 가 존재한다
- 단, 정점들의 평균 연결성이 1보다 충분히 커야한다
- 자세한 이유는 Random Graph Theory 를 촘고하자
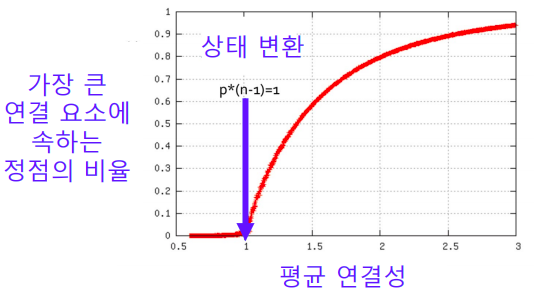
- 위 그래프는 평균 연결성이 변화함에 따라서 가장 큰 연결요소에 속하는 정점의 비율이 어떻게 변화하는지를 보여주고 있다
- 평균연결성이 1에 도달하는 순간 거대 연결요소가 등장하기 시작하고
- 평균연결성이 증가함에 따라 그 크기가 점점 더 커진다
- 평균 연결성이 3정도 됬을때 거대 연결요소가 대부분의 정점을 포함하는것을 확인할 수 있다
군집 구조
- 필수 개념: 군집 구조 및 군집 계수
_ 군집(Community) 이란 다음 조건들을 만족하는 정점들의 집합니다- 집합에 속하는 정점 사이에는 많은 간선이 존재한다
- 집합에 속하는 정점과 그러히 않은 정점 사이에는 적은 수의 간선이 존재한다
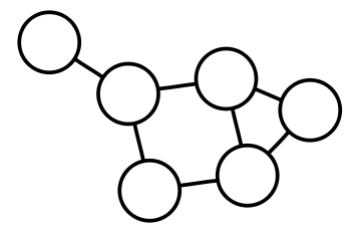
- 수학적으로 엄밀한 정의는 아니지만 아래의 예시를 보면 쉽게 군집들을 발견할 수 있다
- 예시 그래프에는 11 개의 군집이 있는 것으로 보인다
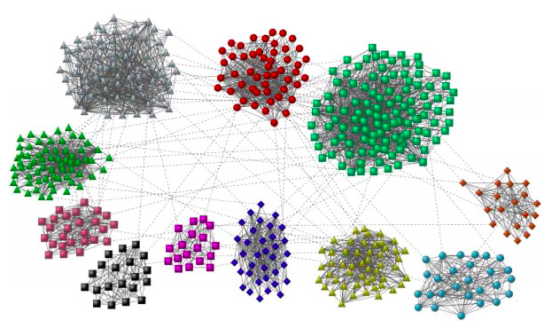
필수 개념: 지역적 군집 계수
- 지역적 군집 계수(local clustering coefficient) 는 한 정점에서 군집의 형성 정도를 측정한다
- 정점 의 지역적 군집 계수는 정점 의 이웃 쌍 중 간선으로 직접 연결된 것의 비율을 의미한다
- 정점 의 지역적 군집 계수를 로 표현한다
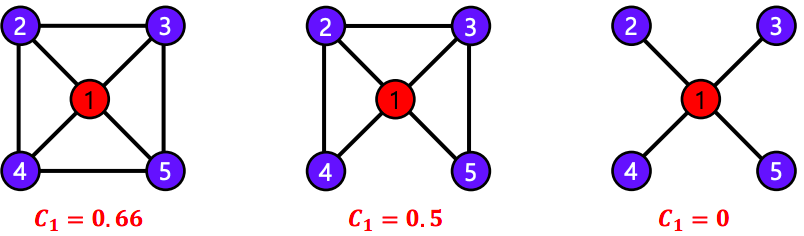
- 예시 그래프를 살펴보자
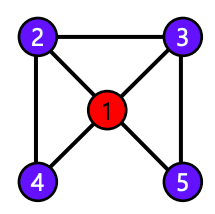
- 정점 1의 이웃은 4개이며, 총 6개의 이웃 쌍((2,3), (2,4), (2,5), (3,4), (3,5), (4,5))이 존재한다
- 그 중 3개의 쌍이 간선으로 직접 연결 되어 있다
- 따라서 정점 1의 지역적 군집 계수는, 이다
- 더 많은 예시:
- 지역적 군집 계수 가 군집 이랑 어떻게 연결되는 것일까?
- 정점 의 지역적 군집 계수가 매우 높다고 하자
- 즉, 정점 의 이웃들도 높은 확률로 서로 간선으로 직접 연결되어 있다
- 정점 와 그 이웃들은 높은 확률로 군집 을 형성한다
- 즉, 각 정점의 지역적 군집 계수가 높을수록 그 정점이 군집에 속할 확률이 높다
- 전역 군집 계수(global clustering coefficient)는 전체 그래프에서 군집의 형성 정도를 측정한다
- 그래프 G의 전역 군집 계수는 각 정점에서의 지역적 군집 계수의 평균이다
- 단, 연결성이 0이여서 지역적 군집 계수가 정의되지 않는 정점으로 제외한다
- 실제 그래프에서는 군진 계수가 높다 즉, 많은 군집이 존재한다
- 여러가지 이유가 있을 수 있다
- 동질성(Homophily) : 서로 유사한 정점끼리 간선으로 연결될 가능성이 높다
- 같은 동네 사는 같은 나이의 아이들이 친구가 되는 경우가 이 예시이다
- 전이성(Transitivity) : 공통 이웃이 있는 경우, 공통 이웃이 매개 역할을 해줄 수 있다
- 친구를 서로에게 소개해주는 경우가 이 예시이다
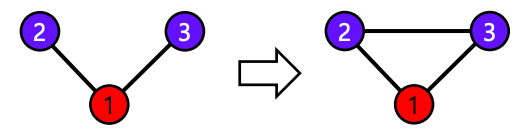
- 친구를 서로에게 소개해주는 경우가 이 예시이다
- 동질성(Homophily) : 서로 유사한 정점끼리 간선으로 연결될 가능성이 높다
- 여러가지 이유가 있을 수 있다
- 반면 랜덤 그래프에서는 지역적 혹은 전역 군집 계수 가 높지 않다
- 구체적으로 랜덤 그래프 에서의 군집 계수는 이다
- 랜덤 그래프에서의 간선 연결이 독립적인 것을 고려하면 당연한 결과이다
- 즉, 공통 이웃의 존재 여부가 간선 연결 확률에 영향을 미치지 않기 때문에 전이성이 없다
- 또한 마찬가지의 이유고 동질성도 없다
- 따라서 전이성과 동질성이 없기 때문에 군집을 형성할 확률이 랜덤 그래프에서는 매우 낮다

아기개발자