[Contents]
1) GPT-1
2) BERT
- 자연어 처리 분야에 한 획을 그은 GPT-1과 BERT를 설명
- GPT-1과 BERT는 Transfer Learning, Self-supervised Learning, Transformer를 사용했다는 공통점이 있다
- 세가지의 강력한 무기를 이용해 대용량의 text를 학습한 모델을 target task에 적용해 거의 모든 기존 자연어처리 task를 압도하는 성능을 보여주었다
- 세 가지의 키워드를 통해 두 모델을 자세히 알아보자
- Transformer를 사용해서 Self-supervised learning이라는 task를 통해 pre-training, fine-tuning의 형태로 NLP에 많은 성능의 task를 올린 GPT-1, BERT 를 알아보자
Further Reading
- GPT-1
- BERT : Pre-training of deep bidirectional transformers for language understanding, NAACL’19
- SQuAD: Stanford Question Answering Dataset
- SWAG: A Large-scale Adversarial Dataset for Grounded Commonsense Inference
Further Question
- BERT의 Masked Language Model의 단점은 무엇이 있을까요? 사람이 실제로 언어를 배우는 방식과의 차이를 생각해보며 떠올려봅시다
Recent Trends
- Transformer 에서 제안된 self-attention 블록은 범용적인 sequence encoder, decoder로써 최근 자연처리의 다양한 분야에서 좋은 성능을 내고있다
- 심지어 다른 분야에서도 transformer 및 self-attention 기반 모델이 활발히 사용되고 있다
- Transformer는 self-attention 블록을 대략 6개정도만 쌓아서 사용했다면,
- 최근에 모델의 발전 동향은 transformer에서 제시된 self-attention 블록을 모델 구조자체의 변화는 없이 더 많이 쌓아서 이를 대규모 학습데이터를 통해서 학습할수 있는 self-supervised learning framework으로 학습한 후
- 이를 다양한 task에 transfer learning 형태로 fine tuning 을 하는 형태에서 좋은 성능을 내고 있다
- self-attention모델은 추천시스템, 신약개발, 영상처리 분야 까지도 확장폭을 넓혀가고 있다
- 그렇지만 transformer에 self-attention기반 모델들도 자연어 생성 이라는 task에서 단어를 sos 토큰부터 시작해서 왼쪽에서 단어를 하나씩 생성한다는 greedy decoding framework에서 벗어나지는 못하고 있는 한계점을 가지고 있다
GPT-1
- 자연어 생성에서의 좋은 성능을 보여주고 있다
- GPT-1 의 특징
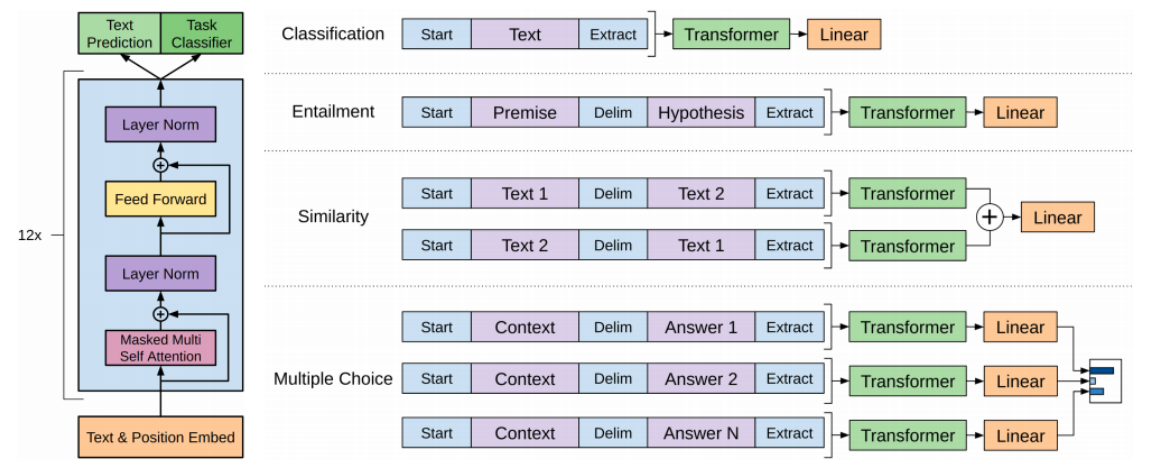
- 다양한 special 토큰을 제안해서 심플한 task 뿐만 아니라 다양한 자연어 처리에서의 많은 task들을 동시에 커버할수 있는 통합된 모델을 제안했다
- It introduces special tokens to achieve effective transfer learning during fine-tuning
- It does not need to use additional task-specific architectures on top of transferred
- 다양한 special 토큰을 제안해서 심플한 task 뿐만 아니라 다양한 자연어 처리에서의 많은 task들을 동시에 커버할수 있는 통합된 모델을 제안했다
- GPT-1의 모델구조와 모델이 학습되는 방식:
- 주어진 text sequence에 positional embedding 을 더한 후 self-attention 블럭을 총 12개를 쌓은 형태의 모델
- text prediction이라는 task는 첫단어 부터 다음 단어를 순차적으로 예측하는 language modeling task를 수행하는 것이다
- 따라서 입력과 출력 sequence가 별도로 있는것이 아니라 가령 영어 데이터로 이루어진 수많은 웹 페이지를 다운받아 그 데이터를 가지고 추출된 문장들을 12개의 self-attention 블락으로 이루어진 GPT-1모델이 학습한다
- 별도에 어떤 label이 필요로하지 않는 데이터, self-supervised learning라고 부르는 framework
- 이와 동시에 GPT-1은 language modeling task, self-supervised learning framework을 통해 대규모 데이터로 기학습된 layer를 이용해서 다수의 문장이 존재하는 경우 등 다양한 task에도 모델의 큰 변형없이 활용될수 있도록 학습에 framework을 제시했다
- 감정분석(sentiment classification)
- start 토큰과 주어진 문장을 넣고 eos에 해당하는 토큰을 extract 토큰이라는 특별한 역할을하는 토큰으로 바꾼 후
- 주어진 문장을 encoding을 한 후 최종적으로 나온 extract 토큰에 해당하는 encoding vector를 최종 output layer의 입력벡터로 줌으로써 문장이 긍정인지 부정인지 분류하는 task로 학습을 하게 된다
- 주어진 문장이 있을때 transformer 모델을 통해 단어별로 encoding을 한 후 extract 토큰 만을 linear transformation 통해서 긍/부정에 대한 output을 예측하는 task 로 다음 단어 예측하는 task와 동시에 갑정분석을 위한 label된 데이터를 동시에 학습할 수 있다
- entailment task
- 예) '어제 존이 결혼했다' 라는문장과 '어제 최소한 한명을 결혼했다' 라는 문장이 주어지는 경우
- 첫번째 문장이 참이면 두 번째 문장도 당연히 참이여야하는 논리적인 내포관계가 있다
- 이런 task에서는 다수에 문장을 입력으로 받아서 예측을 수행해야 되고
- 이런 경우를 대비하기 위해 GPT-1 모델에서는 두개의 문장을 단순하게 하나의 sequence로 만들되 start 토큰을 넣고 문장사이에는 또다른 특수문자 Delim(delimiter) 토큰을 추가하고 마지막에 extract 토큰을 추가한다
- 그 후 encoding과정을 통해서 얻어진 단어별 encoding vector 에서 extract 토큰에 해당하는 벡터를 최종적인 output layer에 통과시키고 이것이 실제로 논리적으로 내포관계인지 모순관계인지에 대한 분류 task를 수행하게 된다
- similarity task
- 두 문장간의 유사도를 측정하는 task
- Multiple Choice
- extract 토큰
- 마지막 문장에 추가한 토큰일 뿐이였지만 문장을 잘 이해하고 문장이 긍정인지 부정인지
- 혹은 두 문장간의 관계를 잘 이해해서 두 문장의 논리 관계를 예측하기 위해 필요한 정보가
- self-attention을 통한 encoding과정 중에 extract 토큰이 query로 사용되어서 task에 필요로하는 여러 정보들을
- 주어진 입력문장들로 부터 적절하게 정보를 추출한다
- 감정분석(sentiment classification)
- 다음단어를 예측하는 task와 더불어 일부 label이 되어져있는 소량의 특정 task를 위한 데이터가 있는 경우
- 이러한 데이터를 통합적으로 다 학습한 GPT-1 모델을 기타 제3의 다른 task에 transfer learning 형태로 활용할때는 다음과 같은 방식으로 동작한다
- 예) 전에는 긍/부정 예측을 하는 형태의 output도 산출해내고 supervision을 했고 이번에는 이 모델을 통해서 주제분류 task를 하고자 한다
- 주제분류 task는 downstream task로써 기존의 긍/부정을 예측하는 task 와는 다르기 때문에 output layer로써의 원래 가지던 긍/부정 예측을 위한 그리고 다음 단어 예측을 위한 output layer는 떼어내버리고
- 그 전단계에서 나오는 transformer에서의 output 인 단어별 encoding vector 들을 사용해서 주제분류 task를 위한 추가적인 layer를 붙이고 random initialization을 한후
- 기 학습된(pre-learned) transformer encoder와 주제분류 task를 위한 추가적인 layer 하나를 덧붙이고
- 주제분류 task를 하기위한 학습데이터를 통해 전체 네트워크를 학습하는 과정을 거치게 된다
- 정리하자면,
- 마지막 layer는 random initialization을 통해 시작이 되기 때문에 학습이 충분히 되어야 하지만
- 이전에 있는 이미 기학습된 layer에서는 learning rate을 상대적으로 작게 설정함으로써 큰 변화가 일어나지 않도록
- 그래서 기존에 task를 통해서 배우던 여러지식들을 충분히 잘 담고있으면서
- 그 정보를 사용자가 원하는 task에 활용할수 있는 형태로 pre-training 및 메인 task를 위한 fine-tuning 과정이 일어나게 된다
- pre-trained된 다양한 task로 부터 유용한 지식을 얻을수 있는 요소는 어디서 오는지에 대해 살펴보면
- GPT-1에서 필요로하는 language modeling(다음단어 예측 task)이라는 pre-training 당시에 쓰던 task는 별도에 어떤 label이 필요로하지 않는 데이터이기 때문에 굉장히 많은 양의 데이터를 통해서 모델을 학습할수 있다
- 하지만 main task (분서분류, 감정분석 등)의 경우는 해당하는 label이 일일이 부여되어 있어야하는 데이터여야 하고 그 데이터는 상대적으로 소량의 데이터만이 존재하기 때문에
- 앞서 pre-training 단계에서 대규모 데이터를 통해 별도의 label이 필요로하지 않는, 그래서 self-supervised learning라고 부르는 framework을 통해 대규모 데이터로부터 얻을수 있는 지식을 main task에 전이학습 형태로 지식을 활용해서 성능을 올려주는 양상으로 pre-training 및 transfer learning이 일어난다
Experimental Results
- 이러한 방식으로 pre-training된 GPT-1 모델을 다양한 task에 fine-tuning 해을때 나타나는 결과:
- 기존에 각 task별로 존재하던, 그 task만을 위해 customized된 모델
- 그 task만을 위해 label된 상대적으로 소량의 데이터만으로 학습한 모델의 정확도보다 일반적으로 더 높은 성능을 내준다
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- GPT와 마찬가지로 language modeling이라는 task로써 문장에 있는 일부 단어를 맞추도록하는 task로써 pre-training을 수행한 모델이다
- 그렇지만 pre-training task 즉, 다음단어를 예측하는 등의 simple한 self-supervised learning을 transformer 모델 이전의 LSTM기반의 encoder로 pre-training한 접근법도 존재했다 (ELMo)
- transformer모델로 LSTM encoder를 모두 대체한 그러한 모델들이 비슷한 단어를 맞추는 pre-training task에서도 더 많은 양의 지식을 배울수 있는 형태로 모델이 고도화 됬다
BERT: Masked Language Model
- Motivation
- GPT-1의 경우 전후 문맥을 보지 못하고 앞쪽의 있는 문맥만을 보고 다음단어를 예측해야 하는 한계점이 존재했다
- 하지만 문장을 이해하기 위해서는 앞쪽뿐만 아니라 뒤쪽도 봐야 문맥을 이해할수 있다
- 이러한 motivation에서 나온것이 masked langauge model이라하는 BERT에서의 pre-training 모델이다
Pre-training Tasks in BERT
- Masked Language Model (MLM)
- 이 경우에는 문장 sequence가 주어졌을때 각각의 단어의 대해 일정한 확률로 각 단어를 [MASK] 라는 단어로 치환한다
- 치환된 [MASK] 를 무엇인지 맞추도록 하는 형태로 모델의 학습이 진행된다
- 몇 %의 단어를 [MASK] 단어로 치환해서 맞추도록 할지에 대한 % 값이 사전에 결정해줘야하는 hyper-parameter에 해당된다
- 15% 에 해당하는 단어를 비율로 해서 [MASK] 치환하게 된다
- [MASK]로 치환하는 비율을 15%보다 더 높이게 되면 주어진 문장에서 너무 많은 부분을 [MASK]로 처리를 한 경우에 해당하는 각각의 자리에 단어를 맞추기에 충분한 정보가 제공되지 않는 문제가 발생
- [MASK]로 치환하는 비율을 15%보다 더 낮게 설정하면 주어진 문장에서 너무 적은 부분을 [MASK]로 치환해서 transformer 모델이 남은 단어들을 전부 encoding을 하는 과정이 시간적으로, 그리고 학습의 과정에서도 많은 계산이 필요로 한다
- 학습의 효율 및 속도가 떨어진다

- BERT에서 찾은 적절한 비율은 15%가 된다
- 하지만 15% 의 단어를 맞추도록 했을때 해당 단어들을 100%다 [MASK]단어로 치환했을 경우 부작용이 생길수 있다
- 첫번째 부작용:
- pre-training당시에 주어진 문장에서 평균적으로 15% 단어가 [MASK]라는 단어로 치환이 되어있는 상황에 익숙해진 모델이 나올것이다
- 이 모델을 문서의 주제분류 task를 수행한다거나 다른 downstream task를 수행할때는 [MASK]라는 토큰은 더이상 등장하지 않게 된다
- 그러면 이런 경우 pre-training당시 주어진 입력데이터의 양상이나 패턴이 실제 downstream task를 수행할때 주어지는 입력문장과는 다른 특성을 보일수 있고
- 이런 상이한 차이점이 학습을 방해하거나 transfer learning의 효과를 최대한 올리는데 문제가 될 수 있다
- 해결책:
- [MASK]로 치환하기로 하는 15%의 단어들 내에서도 서로다른 형태로 단어들을 변경한다
- 15%의 단어들에서 80%의 단어는 실제 [MASK] 라는 특수한 토큰으로 치환한 후 해당단어를 맞추도록 하고
- 15%의 단어들에서 10%의 단어는 랜던한 단어로 바꾸게 된다
- 랜덤 단어를 원래 단어로 복원해줄수 있도록하는 형태로 문제의 난이도를 높여준것으로 생각하면 된다
- 15%의 단어들에서 나머지 10%의 단어는 바꾸지 않고 원래 단어로 둔다
- 동일해야 한다라고 소신있게 예측을 할수있는 형태의 학습이라고 생각하면 된다
Pre-training Tasks in BERT: Next Sentence Prediction
- 위에서 설명한 [MASK]된 단어를 맞추는 pre-training task이외에 GPT에서도 있었던 문장 레벨에서의 task도 대응하기 위한 pre-training 기법도 제안됬다 (Next Sentence Prediction)
- 주어진 하나의 글에서 두 개의 문장을 뽑느다
- 두 문장을 연속적으로 이어주고 그 문장사이와 끝에는 [SEP] 토큰을 추가한다
- 동시에 다수의 문장 레벨에서의 예측 task를 수행하는 역할을 담당하는 [CLS]토큰을 문장앞에 추가한다
- 이는 GPT에서 extract 토큰이 다수 문장의 마지막에 등장하고 extract 토큰을 통해서 문장 혹은 다수 문장 레벨의 예측 task을 수행할수 있도록 한 토큰에 해당된다
- 별도의 문장 레벨에서의 label이 필요로하는 task가 아닌 여전히 입력 데이터 만으로 예측을 수행할수 있는 task를 학습시키기 위해 주어진 두 개의 문장이 연속적인 순서로 나와야하는 문장인지
- 혹은 두 문장은 전혀 연속적인 문장으로써 나올수 없는 문장인지를 예측하는 binary classification을 수행하는 task를 추가했다

- 주어진 글에서 [MASK]자리에 해당하는 토큰에서는, 해당하는 encoding vector를 가지고 [MASK]자리에 있어야하는 단어를 예측을 수행하게 되고
- [CLS] 잘에 해당하는 토큰에서는, 여기에 해당하는 encoding vector를 가지고 output layer 하나를 두어서 binary classification을 수행하도록 한다
BERT Summary
-
Model Architecture
- transformer 에서 제안된 self-attention 블록을 그대로 사용
- 두가지 버전으로 학습된 모델을 제안
- BERT BASE:
- self-attention 븍록을 총 12개
- A(각 layer별로 정의되있는 Attention head의 숫자)=12
- H(각 self-attention블록에서 같게 유지하는 encoding 벡터의 차원수) = 768
- BERT LARGE: self-attention 블록을 총 24개
- self-attention 븍록을 총 24개
- A(각 layer별로 정의되있는 Attention head의 숫자)=16
- H(각 self-attention블록에서 같게 유지하는 encoding 벡터의 차원수) = 1028
- BERT BASE:
-
Input Representation
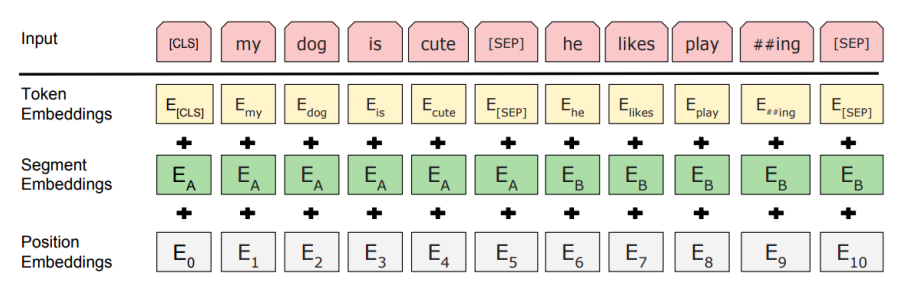
- 추가적으로 BERT에서는 입력 sequence를 넣어줄때 단어별로의 embedding vector를 사용하는것이 아니라 단어를 더 잘게 쪼개서 각각의 sequence의 단위를 subword라 불리는 단위로 embedding을 하고
- 이것을 입력벡터로 넣어주는 방식
- Learned positional embedding
- transformer에서 제안된 사전에 미리 특정한 방식을 통해 정의된 sine, cosine 과 특정 주기들을 써서 추출된 position에 해당된 embedding vector를 사용했다면
- 이것 조차 마치 word2vec에서 embedding matrix를 학습하듯이 이부분도 random initialization에 의해서 전체적인 모델학습 과정을 통해 end-to-end로 각 position에 더해주어야하는 embedding vector도 학습에 의해서 최적화된 값으로 도출한다
- 따라서 BERT에서는 positional embedding 자체도 학습에 의해서 결정된다
- [CLS] - classification token
- Packed sentence embedding [SEP]
- Segment embedding
- BERT를 학습할때 일반적으로 단어별 [MASK]된 단어를 예측하는 task와 주어진 두 문장으로 이루어진 한 sequence가 연속된 문장인지를 분류하는 문장 레벨에서의 task가 있다
- 이 경우 두 개의 문장을 연속으로 [SEP]토큰으로 구별해서 넣는경우
- 각각의 해당하는 word embedding 벡터에 position embedding이 추가적으로 더해지는데
- 그렇지만 두번째 문장의 속한 단어다 라는 정보를 더 분리해서 넣어줘야할 필요성이 생긴다
- 이러한 요소를 보안하기 위해 position embedding은 순차적으로 부여하고
- 첫번째 문장과 두번째 문장 즉, 문장레벨에서의 postion을 반영한 형태의 segment vector가 추가됬다
-
Pre-training Tasks
- Masked Language Modeling
- Next Sentence Prediction(NSP)
Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding
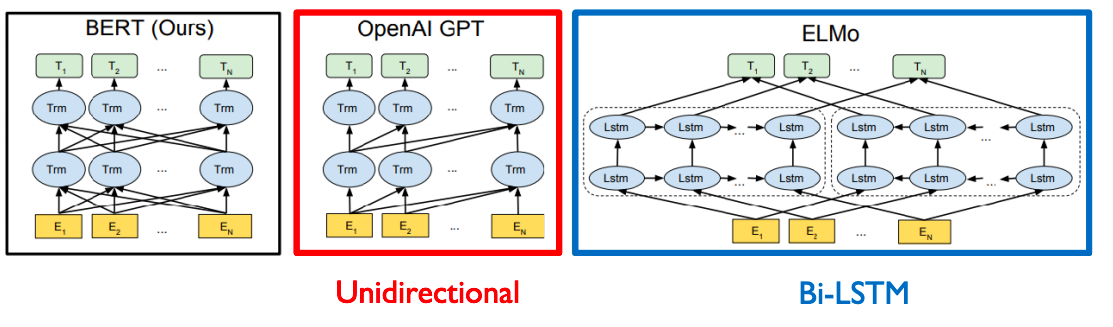
- high-level의 도식화된 그림에서 BERT와 GPT간의 차이점을 더 살펴보자
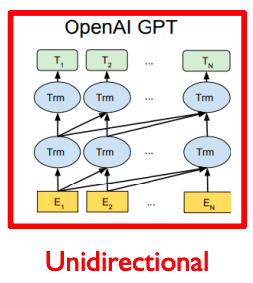
- GPT의 경우 주어진 sequence를 encoding할때 다음 단어를 예측하는 task를 수행해야하기 때문에 특정한 time step에서 다음에 나타나는 단어에 접근을 허용하면 안된다
- 마치 transformer에서 decoder에서의 self-attention이 Masked 형태의 self-attention으로 사용됬었던거 처럼
- 그래서 위에 그림에서 GPT 모델을 보면 각각의 특정한 time step에서는 항상 자기자신을 포함해서 왼쪽에 있는 정보들에 의해서만 영향을 받는다
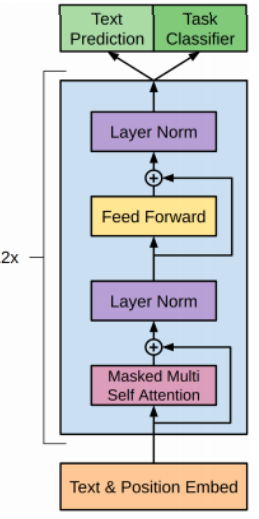
- 그렇기 때문에 GPT에서 sequence encoding을 하기위한 attention블록은, transformer에서 decoder부분에서 사용되던 Masked self-attention을 사용하게 된다
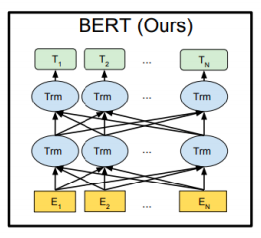
- Bert의 경우 [MASK]로 치환된 토큰들을 예측하게 되고 그래서 [MASK]단어를 포함하여 전체 주어진 모든 단어들의 접근을 허용하게 한다
- 그렇게 때문에 transformer에서 encoder에서 사용한 self-attention 모듈을 사용하게 된다
BERT: Fine-tuning Process
- 다음으로는 pre-training의 task인 Masked Language Modeling과 Next Sentence Prediction task를 여러가지 다양한 downstream에 fine-tuning 하는 형태의 모델구조를 살펴보자
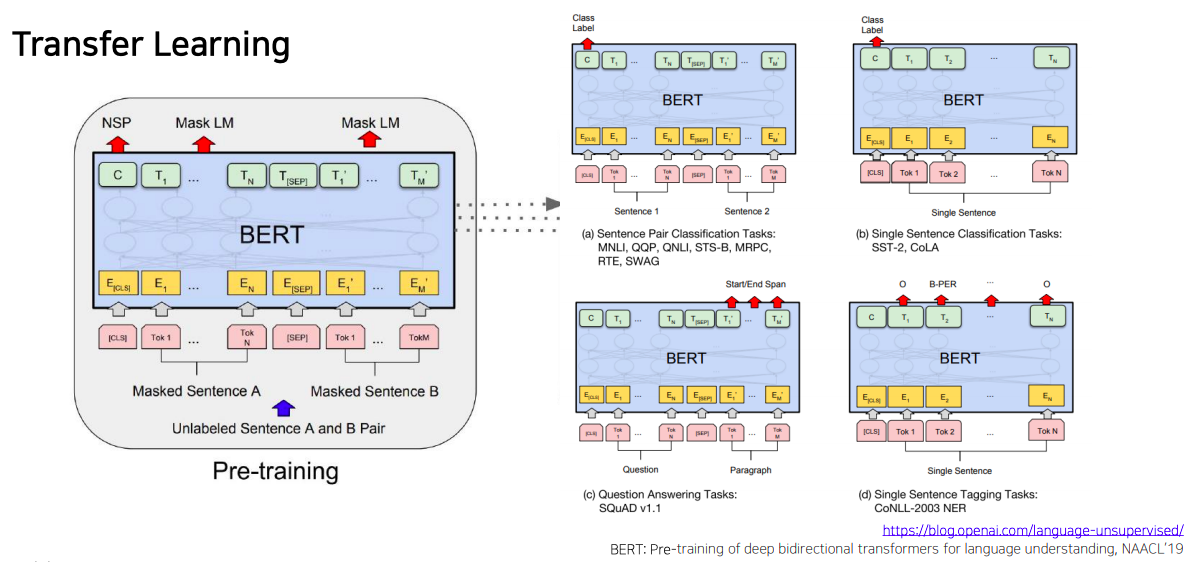
- sentence pair에 대해서 classification(논리적 내포 혹은 모순관계 예측)
- 두 개의 문장을 하나의 sequence로 그렇지만 [SEP]토큰으로 구별지은 후 BERT를 통해 encoding후 각각의 단어들에 대한 encoding 벡터를 얻었다면 [CLS]토큰에 해당하는 encoding vector를 output layer에 입력으로 주어서 다수 문장에 대한 예측을 수행할수 있다
- Single Sentence Classification Task
- 입력으로 한번에 하나씩이기 때문에 문장을 하나만 주고 [CLS]토큰의 encoding output을 최종 output에 넣어주어서 classification을 수행
BERT vs GPT-1
- GPT-1 과 BERT간의 세부적인 차이점
| BERT | GPT | |
|---|---|---|
| Training-data size | trained on the BookCorpus and Wikipedia(2,500M words) | trained on BookCorpus(800M words |
| Training special tokens during training | learns [SEP],[CLS], and sentence A/B embedding(segment embedding) during pre-training | |
| Batch size | 128,000 words | 32,000 words |
| Task-specific fine-tuning | chooses a task-specific fine-tuning learning rate | uses the same learning rate of for all fine-tuning experiments |
- 일반적으로 더 큰 batch size를 사용할 경우에 최종 모델성능이 더 좋아지고 학습도 안정화가 되는 현상이 나타난다
- 이는 gradient descent 알고리즘을 수행할때 일부의 데이터 만으로 도출된 gradient로 매번 update할지 아니면 더 많은 양의 데이터를 바탕으로 종합적으로 나온 평균 gradient를 바탕으로 학습을 할지에 따라 더 많은 숫자의 데이터를 사용해서 한번 단위에 업데이트를 수행할때가 더 학습이 안정적이고 성능이 좋다는 사실이 알려져있다
- 그렇지만 Batch size를 키우기 위해서는 한번에 load해와야 하는 입력 데이터 뿐만아니라 forward propagation backpropagation 상에서 필요한 메모리도 이에 비례해서 증가하기 때문에 더 많이 GPU 메모리, 그에 따른 고성능의 GPU가 필요로 하게 된다
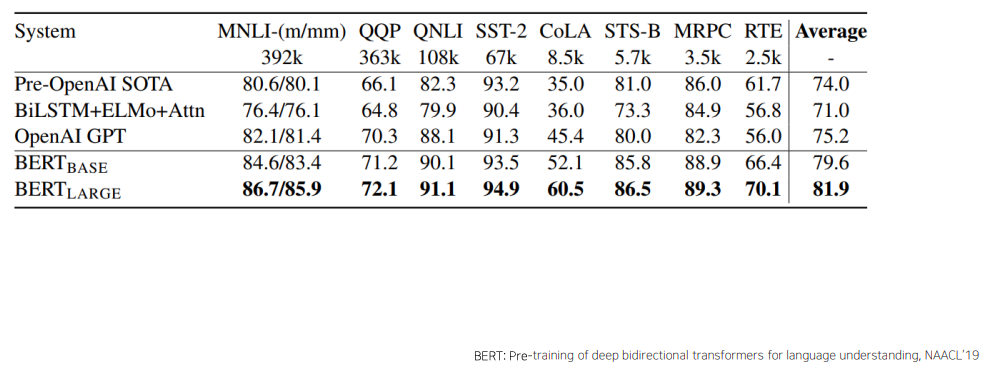
BERT: GLUE Benchmark Results
- BERT도 위에서 설명한 제3의 다른 task에 transfer learning 형태로 활용할때의 GPT-1 방식과 동일하다
- BERT 도 다양한 자연어 처리 task에 fine-tuning 형태로 적용했을때, 기존의 여러 알고리즘에 비해 일관적으로 더 좋은 성능을 냈다
- 여러 task를 다 모아둔 dataset을 GLUE data 라고 부른다
Machine Reading Comprehension(MRC), Question Answering task
- BERT의 fine-tuning을 통해 높은 성능을 얻을수 있는 대표적인 task로써 machine reading comprehension task를 살펴보자

- 기계의 독해에 기반한 즉, 주어진 지문이 있을때 지문을 잘 이해하고, 질문에서 필요한 정보를 잘 추출해서 해당 정보를 예측해내는 task를 기계 독해기반의 질의응답이라 한다
- 기계독해 기반의 quesion answering을 BERT라는 모델을 통해 푸는 과정을 간단히 살펴보자
- BERT의 입력으로써 주어진 지문과 답을 필요하는 입력을 두개의 서로다른 문장인것 처럼 [SEP] 토큰을 통해 concat을 해서 하나의 sequence로 만들어서 encoding이 진행된다
- 각각의 지문상에서의 단어별로의 word encoding vector가 나올것이고
- 그러면 그 벡터들에서 정답이 해당될 법한 위치(위치는 지문상에서의 특정한 문구로 정답이 주어진다)를 예측하도록 모델을 수행
- 지문에서 답에 해당하는 문구가 시작하는 위치를 예측하기 위해 각 단어별로 최종 encoding vector가 output으로 나왔을때 이를 공통된 output layer를 통해서 scalar값을 뽑아 결과값을 얻게 된다
- output layer에 속해있는 fully connected layer의 파라미터가 random initialization에서 부터 fine-tuning되는 대상에 해당하는 파라미터가 된다
- scalar 값을 각 단어별로 얻은 후에는 단어상에서 여러 단어들중에 답에 해당하는 문구가 어느 단어에서 시작하는지를 먼저 예측한다
- 예를들어 단어가 총 124개의 단어가 있다하면 해당하는 scalar값이 총 124개가 있을것이고 여기에 softmax를 통과시켜 softmax의 ground truth 로써 답의 첫번째 단어에 해당하는 logit값이 100%에 가까워지도록 softmax loss 를 통해서 모델을 학습한다
- 그다음에는 모델이 끝나는 시점도 예측해야한다
- starting word에 대한position을 예측하는 output layer로써의 fully connected layer를 하나 둠과 동시에 또 다른 fully connected layer를 두 번째 버전으로 만들어 ending word에 대한 position을 예측하도록 한다
- SQuAD 2.0 버전에서는 주어진 지문에서 question에 대한 답이 없는 경우의 합습데이터도 포함되어있다
- 이 경우의 BERT 모델을 사용할때는 [CLS]토큰을 통해 답이 있는 없는지를 예측하고 답이 있는것으로 예측 결과가 나온 경우 위에서 설명한 starting 및 ending position을 예측하는 output layer를 구동함으로써 답에 해당하는 문구를 예측한다
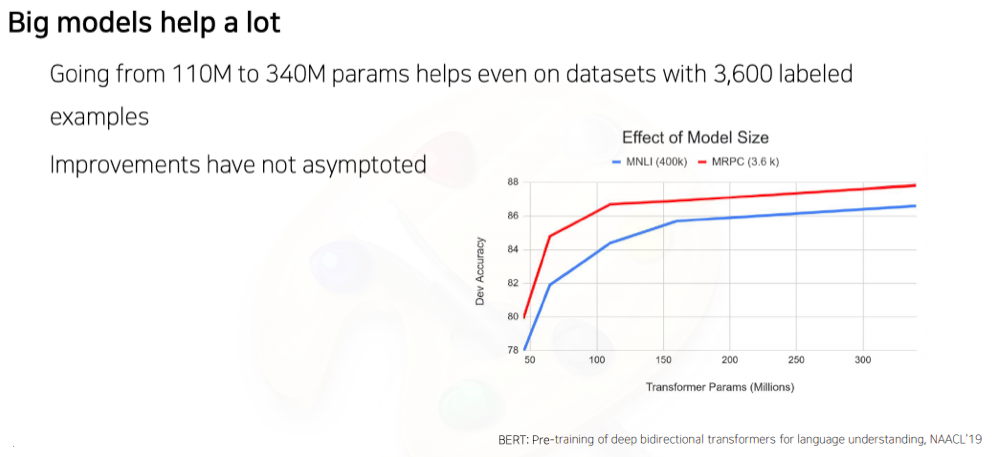
BERT: Ablation Study
- BERT에서 제안한 모델 사이즈가 있을때 그 모델의 layer를 깊게 쌓고 각 layer별 파라미터를 늘리는 방식으로 학습을 진행하면 여러 downstream task의 성능들이 더 좋아진다
- 이는 모델 사이즈를 GPU resource가 허락 가능한 만큼 키웠을때도 개선이 끝을 모르고 올라가는 형태 결과를 보여주었다
- 결론적으로 이 논문에서 시사하는 바는
- 모델 사이즈를 키울수 있다면 pre-training을 통한 여러 다양한 downstream task에 적용했을때 성능이 점점더 오를수 있다

아기개발자
잘 읽고갑니다. 너무 멋집니다.