[Contents]
1) Optimization
Optimization
- 최적화와 관련된 주요한 용어 와 다양한 Gradient Descent 기법 들을 배운다
- 주요한 용어 : Generalization, Overfitting, Cross-validation 등 다양한 용어가 있다
- 다양한 Gradient Descent 기법 : 기존 SGD(Stochastic gradient descent)를 넘어서 최적화(학습)가 더 잘될 수 있도록 다양한 기법들에 대해 배운다
- 마지막으로, Gradient Descent 기법에 따른 성능의 변화 를 알아보는 실습을 한다
Further Questions
- 올바르게(?) cross-validation을 하기 위해서는 어떤 방법들이 존재할까?
- Time series의 경우 일반적인 k-fold cv 를 사용해도 될까?
Further reading
Important Concepts in Optimization
- Generalization
- Under-fitting vs. over-fitting
- Cross validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging and Boosting
Generalization
- 많은 경우에 일반화 성능을 높이는게 목적
- 일반화 성능(Generalization performance): training error와 test error의 차이
Underfitting vs. Overfitting
- Overfitting : training data에서는 잘 동작하는 반면 test data에서는 잘 동작하지 않는 현상
- Underfitting : 네트워크가 너무 간단하거나 training을 너무 조금 시켜서 training data도 잘 못맞추는 현상
Cross-validation
- model validation technique for assessing how the model will generalize to an independent (test) data set
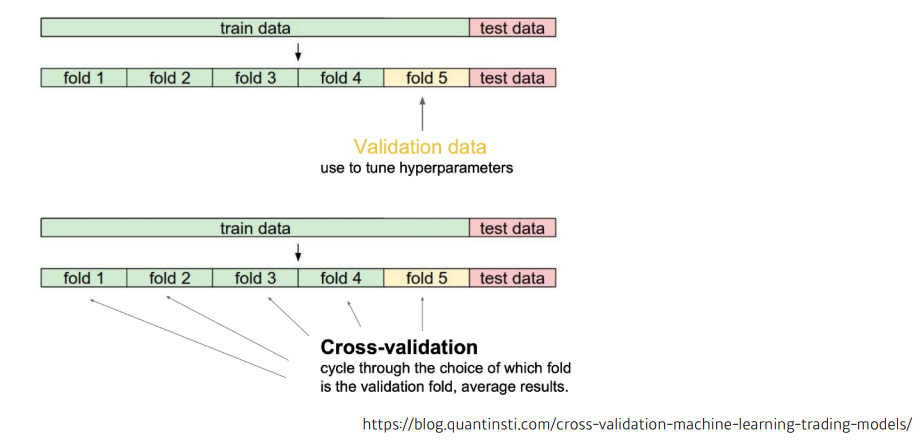
Bias and Variance
- variance : 입력을 넣었을때 출력이 얼마나 일관적으로 나오는지
- high variance : 비슷한 입력이 들어와도 많이 다른 출력. (overfitting 될 가능성이 크다)
- Bias : 비슷한 입력에 대해서 출력이 많이 분산이 되더라도 평균적으로 봤을때 원하고자 하는 target과의 거리
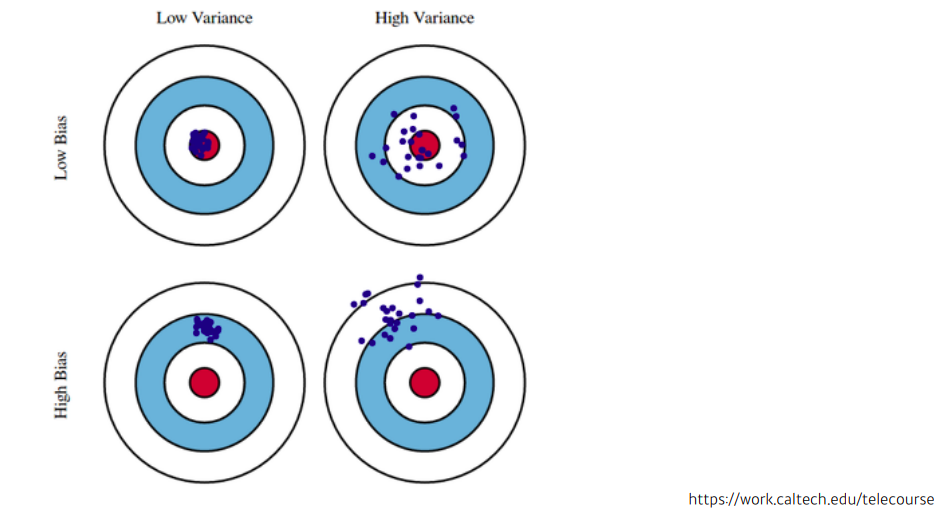
Bias and Variance Tradeoff
-
학습 데이터에 노이즈가 껴있다고 가정했을때 노이즈가 껴있는 target data의 cost를 minimize 하는것은 3가지 component로 이루어져 있어서 3개중에 각각을 minimize 하는것이 아니라 하나가 줄어들면 하나가 커질수 밖에 없다는 tradeoff
-
= = ... = + +
- t : target
- : neural network의 출력 값
- 가정 : t 라는건 true target에 noise가 꼇다는 것
- : cost
- : bias
- : variance
- : noise
- cost를 minimize 한다는건 bias, variance 또는 noise를 minimize하는 3가지 term을 말한다
- 그래서 모델 특성이 bias를 많이 줄이게 되면 variance가 높아질 가능성이 크고 vice versa
- fundamental limitation : 근본적으로 train data에 noise가 껴있을 경우에는 bias와 variance를 둘다 줄이는 것은 얻기가 힘들다
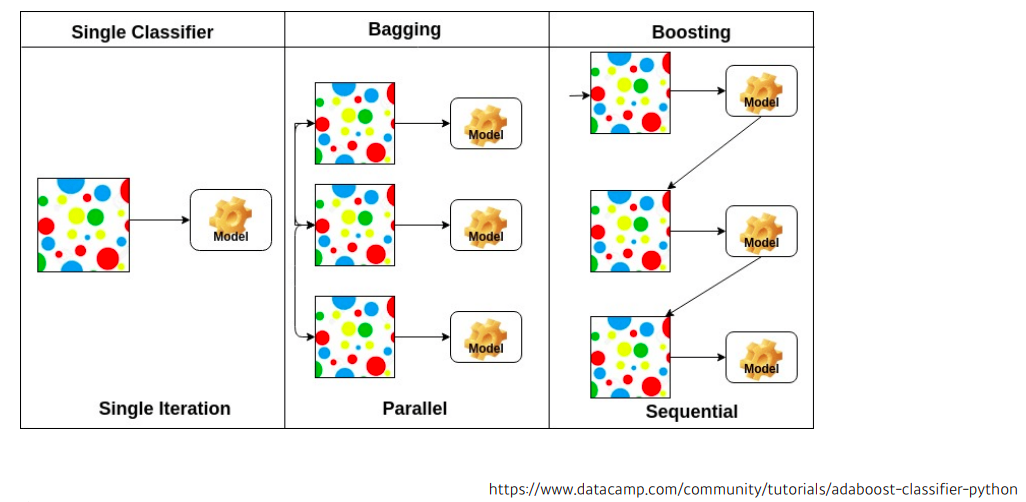
Boostrapping
- any test or metric that uses random sampling w/ replacement
- train data가 고정되어 있을때 그 안에서 subsampling을 하여 train data 여러개를 만들고 각 subsampling된 train data를 통해 여러 모델을 만들어서 무언가를 하겠다는 technique
Bagging vs. Boosting
- Bagging (Bootstrapping aggregating)
- multiple models are being trained with bootstrapping
- Boostrapping을 통해 여러 모델들의 output의 평균을 내 사용하는 technique
- Boosting
- it focuses on those specific training samples that are hard to classify
- a strong model is built by combining weak leaners in sequence where each learner leanrs from the mistakes of the previous weak learner
- 예측을 못하는 데이터에 대해서만 잘 동작하는 모델을 만다는 과정을 반복하여 여러개를 모델(weak learner) 을 만들고 이를 순차적으로 합쳐서 하나의 strong learner를 만든다
Practical Gradient Descent Methods
- Gradient Descent Methods
- SGD (Stochastic Gradient Descent)
- 하나의 sample을 사용하여 gradient를 계산해서 업데이트
- mini-batch gradient descent
- 데이터의 부분(mini-batch)을 사용하여 gradient를 계산해서 업데이트
- batch gradient descent
- 모든 데이터를 사용하여 gradient를 계산해서 업데이트
- SGD (Stochastic Gradient Descent)
Batch-size matters
-
"It has been observed in practice that when using a large batch, there is a degradation in the quality of the model, as measured by its ability to generalize."
-
"We ...present numerical evidence that supports the view that large batch methods tend to converge to sharp minimizers of the training and testing functions. In contrast, small-batch methods consistently converge to flat minimizers ... this is due to the inherent noise in the gradient estimation." - On Large-batch Training for the Deep Learning: Generalization Gap and Sharp Minima, 2017 -
- 큰 batch-size를 활용하게 되면 sharp minimizer 에 도달하는 반면 작은 batch_size를 활용하게 되면 flat minimizer 로 도달한다
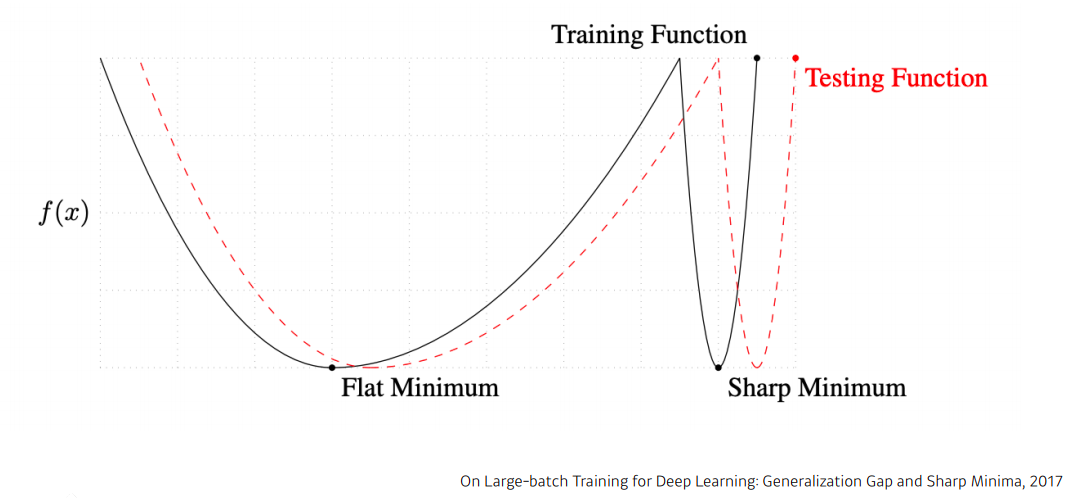
- flat minimum 특징 : training function에서 조금 멀어져도 testing function에서도 적당히 낮은 값이 나온다 즉, train data에서 잘 동작하면 test data 에서도 어느정도 잘 동작한다. generalization performance (일반화 성능) 이 높다
- sharp minimum 특징 : training function에서 local minima에 도달 했어도 testing function에서는 굉장히 높은 값이 나온다 즉, training 단계에서 얻어지는 값들이 test data 기준으로 잘 동작을 못할 수도 있기 때문에 generalization performance가 낮다
- 결론 : batch-size를 줄이게 되면 일반적으로 generalization performance 가 좋아진다
Gradient Descent Methods
1) Stochastic gradient descent
2) Momentum
3) Nesterov accelerated gradient
4) Adagrad
5) Adadelta
6) RMSprop
7) Adam
1) (Stochastic) Gradient descent
- : Learning rate
- : Gradient
- 가장 큰 문제 : learning rate를 잡는것이 어렵다
2) Momentum
- : momentum
- hyper-parameter
- : accumulation
- accumulated gradient : momentum과 현재 gradient를 합침
- 장점 : 한번 흘러가기 시작한 gradient 방향을 어느정도 유지 시켜주기 때문에 gradient가 굉장히 많이 왔다갔다해도 어느정도 잘 학습된 효과를 볼 수 있다
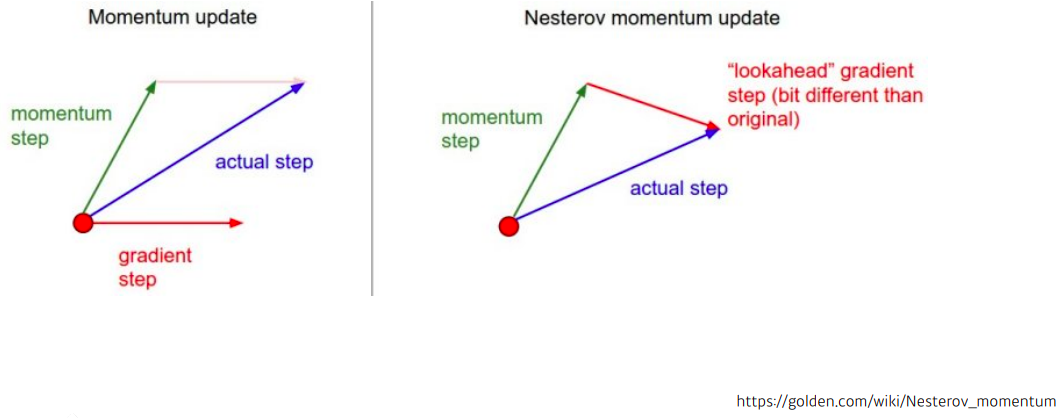
3) Nesterov Accelerated Gradient
- : Lookahead gradient
- 장점 : momentum보다 loca minima에 더 빠르게 도달한다
4) Adagrad
-
- 많이 변한 neural network paramater에 대해서는 더 적게 변화 시키고
- 많이 변하지 않은 neural network parameter에 대해서는 더 많이 변화 시킨다
- : sum of gradient squares, 지금까지 gradient가 얼마나 많이 변했는지를 제곱해서 더한 값
- 역수를 취했기 때문에 지금까지 많이 변한 파라미터는 적게 변화 시키고 많이 변하지 않은 파라미터는 더 많이 변화 시킨다
- : for numerical stability
- 0으로 나누주지 않기 위한 장치
- 가장 큰 문제 :
- 가 계속 커지기 때문에 결국에는 무한대로 가게되면 분모가 무한대이기 때문에 가 업데이트가 안된다
- 뒤로 가면 갈수록 학습이 점점 멈추는 현상이 생긴다
5) Adadelta
-
- Adagrad 가 가지는 large 가 커지는 현상을 최대한 막아준다
- 현재 time step t 가 주어졌을때 이 t를 어느정도 윈도우 사이즈 만큼의 시간에 대한 gradient 제곱의 변화를 본다
- 문제점 :
- 윈도우 사이즈를 100으로 잡게되면 이전 100개 동안의 라는 정보를 들고 있어야한다
- 의 크기를 생각해보면 gradient는 모든 파라미터 하나만 들고 있기 때문에 예를들어 천억개의 파라미터가 있는 모델을 사용하면 자체도 천억개의 파라미터인 거다
- 이를 100개 들고 있다면 GPU가 터져버릴수도 있다
- 이것을 막을수 있는 방법이 exponential moving average이다
- 어떤 값이 있을때 그 값을 와 이전값에 있는 로 곱하고 만큼 더해주게 되면 이 값은 어느정도 time 윈도우 만큼의 값을 저장하고 있다고 볼 수 있다
- 이처럼 exponential moving average를 통해서 를 업데이트 하는것이 Adadelta 이다
- there is no learning rate in Adadelta
- : EMA(exponential moving average) of gradient squares
- : EMA of difference squares
- 실제로 업데이트 할려는 weight에 변화값을 들고 있다
- 많이 사용하지 않음
5) RMSprop
-
- : EMA of gradient squares
- : stepsize(learning rate)
6) Adam
-
- adaptive moment estimation (Adam) leverates both past gradients and squared gradients
- Adam effectively combines momentum with adaptive learning rate approach
- gradient의 크기가 변함에 따라서 adaptive 하게 learning rate을 바꾸는 것과 이전에 gradient 정보에 해당하는 momentum 두개를 합친것이 Adam 이다
- : Momentum
- : EMA of gradient squares
- hyper-parameter
- : momentum을 얼머나 유지시킬지에 대한 장치
- : gradient squares에 대한 EMA 정보
- : learning rate(stepsize)
Regularization
- training data에만 잘 동작하는 것이 아니라 test data에도 잘 동작할 수 있게 하도록 하는 techniuqe
1) Early stopping
2) Parameter norm penalty
3) Data augmentation
4) Noise robustness
5) Label smoothing
6) Dropout
7) Batch nomalization
1) early stopping
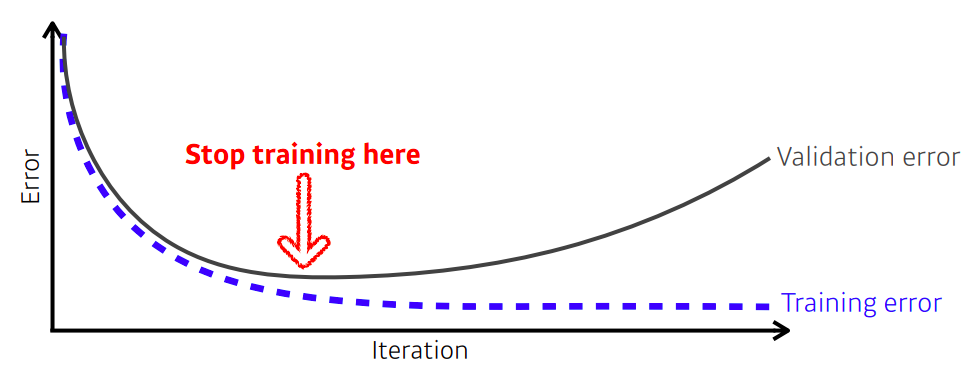
- early stopping을 사용하기 위해선 추가 적인 validation data가 필요하다
2) Parameter norm penalty
- neural network paramater가 너무 커지지 않게 하기 위함

Data Augmentation
- 주어진 데이터를 이용해서 데이터 set을 늘리는 technique
Noise robustness
- add random noises inputs or weights
- input 과 weight에 대해서 노이즈를 중간중간 넣게 되면 네트워크가 test단계에서도 잘 작동한다
label smoothing
- mix-up constructs augmented training examples by mixing both input and output of two randomly selected traning data
- cutmix constructs augmented training examples by mixing with cut and paste and outputs with soft labels of two randomly selcted training data
- 효과 :
- 분류문제에서 이미지들이 살고 있는 공간 속에서 두 개의 클래스를 잘 구분할 수 있는 decision boundary를 찾아 잘 분류하는 것이 목적인데
- decision boundary 를 부드럽게 만들어주는 효과가 있다

Dropout
- in each foward pass, randomly set some neurons to zero
- 효과:
- 각각의 neuron들이 조금 더 robust한 feature를 잡을 수 있다 라고 해석
Batch Normalization
- BN을 적용하고자 하는 layer에 statistics를 정규화 시키는 것이다