- Black box 모델인 CNN의 내부 동작을 가시화하는 방법들에 대해 설명한다
- CNN의 내부 동작을 확인하기 위해 모델의 결정 이유를 추론해내거나 데이터가 처리되는 과정을 살펴보는 방법들이 있다
- 성능이 낮은 모델을 개선하는 데에도 사용할 수 있음은 물론, 높은 성능에 신뢰도를 더하여 건전한 개발을 도울 수 있다
- 딥러닝 모델의 특성을 더 깊이 알아내기 위해 적용했던 직관들과 결과 예시 사진들을 통해, 알고리즘 자체와 처리된 데이터들의 특성을 파악할 수 있는 능력을 기르는 시간이 되면 좋겠다
- 분명 더 나은 모델을 개발하는 데에 큰 밑거름이 될 거라 믿는다
Further Questions
- 왜 filter visualization에서 주로 첫번째 convolutional layer를 목표로할까요?
- CNN Filter의 경우 첫번째 convolutional layer의 input이 RGB 채널로 이루어진 이유로 직관적인 해석이 가능하고, 그 뒤부터는 사람이 해석하기 어렵다는 특징이 있습니다. 과제 코드로 더 확인해보시면 직접 확인 가능합니다.
- Occlusion map에서 heatmap이 의미하는 바가 무엇인가요?
- 각 픽셀이 결과값에 얼마만큼의 중요도를 갖는지를 나타낸다고 해석할 수 있습니다. 확률값으로 계산하기 때문에 heatmap으로 visualize를 할 수 있습니다.
- Grad-CAM에서 linear combination의 결과를 ReLU layer를 거치는 이유가 무엇인가요?
- 표면적으로는 양수값만을 취해주기 위해 그렇지만, QnA세션 때 @김종하(오태현님_교육조교) 말씀대로, 실험적으로 결정한 사항이기도 합니다.
Visualizing CNN
What is CNN visualization?
- CNN을 시각화 한다는 것
- CNN is a black box

- What is inside CNNs (black box)?
- Why do they perform so well?
- How would they be improved?
- CNN (black box) 이 원하는데로 동작을 하지 않으면 그 원인을 파악하기 위해서 CNN을 시각화 해야한다
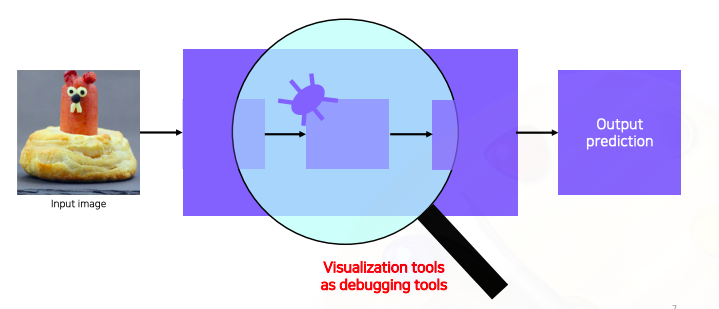
- CNN을 visualize 한다는 것은 debugging tool을 갖는것과 동일하다
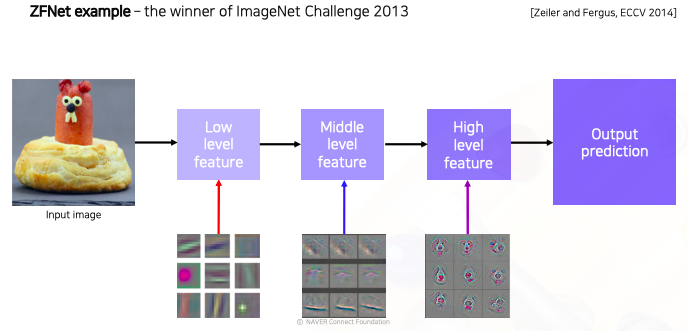
- CNN layer들이 각 위치에 따라서 어떤 지식을 배우는지 convolution의 역연산인 deconvolution을 이용해서 visualization을 시도한 연구가 있었다
- 이 연구를 통해서 낮은 계층에는 좀 더 방향성이 있는 선을 찾는 filter들 또는 동그란 블록을 찾는 기본적인 영상처리 필터들을 찾는것을 확인할 수 있었다
- 중간계층과 더 나아가 높은 계층으로 갈수록 점점 high level에 의미가 있는 표현을 학습했다는 것을 파악할 수 있었다
Vanilla example : filter visualization
-
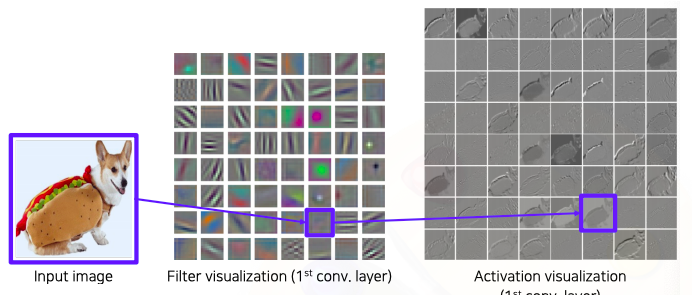
Filter weight visualization
-
가장 간단한 방법으로 필터를 visualization하는 방벙이다
-
위처럼 각 filter를 떼어내보면 각종 영상처리 필터와 같은 color edge detector, 각도 detector, 블록 detector 등 과 같은 다양한 기본적은 operation 들이 학습되었다
-
입력에 convolution을 취한 activation map 도 시각화 할 수 있다
- 여기서는 각 필터마다 처리 결과가 한 채널로 나오기 때문에 흑백으로 표현이 되었다
- 각 필터의 특성마다 어떤 결과는 영상의 45도에 해당하는 결과
- 어떤건 잔 디테일들을 보는 결과
- 다른 필터는 살색이면 더 high response 를 발휘하는 결과들을 확인할 수 있다
-
이렇게 간단한 visualization을 통해서 CNN의 첫 layer가 어떤것을 보고 어떤 행동을 하는것인지를 조금 이해할 수 있다
-
더 뒤쪽 layer을 filter 자체의 차원수가 높아서 visualization 할 수 있는 형태가 아니다
-
그래서 차원수가 높아서 사람이 직관적으로 알아볼수 있는 형태가 나오지 않는다
-
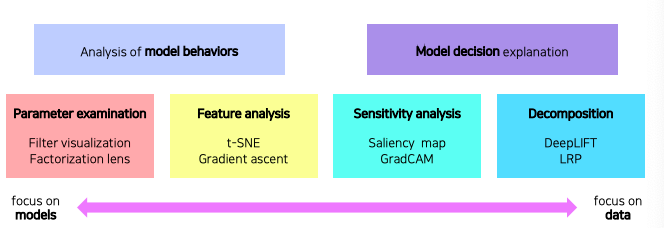
Types of neural network visualization
-
모델 자체를 분석하는데 강점을 둔 방법들과
-
하나의 입력데이터에서 부터 모델이 어떤 결론을 내었을때 어째서 그런 결론이 도달하게 되었는지 출력을 분석하는 방법들도 있다
-
왼쪽으로 갈수록 모델을 이해하기 위한 분석에 가깝고 오른쪽으로 갈수록 데이터 결과를 분석하는데 초점을 맞춘 기준들이다
Analysis of model behaviors
Embedding feature analysis 1
- High level layer를 거쳐서 얻게되는 feature를 분석하는 방법을 살펴보자
- Nearested neighbors (NN) in a feature space - Example

- 좌측에 query image 데이터가 들어오게 되면 query 영상과 유사한 이웃 영상들을 database에서 몇가지를 거리에 따라서 정렬된 형태로 가져온다
- 이걸 통해서 여러가지 해석을 할 수 있는 여지를 주게 된다
- 예를 들어서 의미론 적으로 비슷한 컨셉들이 clustering 되어있다
- 다른 예는 query image가 주어졌을때 심플하게 픽셀별로 비교를 통해서 영상 검색을 할 수 있다
- 이렇게 찾을경우 비슷한 영상이라고 볼 수 없는 영상들도 뽑힐 수 있다
- 이를 통해서 학습된 필터가 물체의 위치 변화에 굉장히 강인하게 대신에 컨셉을 잘 학습했다는 것을 알 수가 있다
- Nearest neighbors in a feature space 가 구체적으로 어떻게 동작되는지 살펴보자
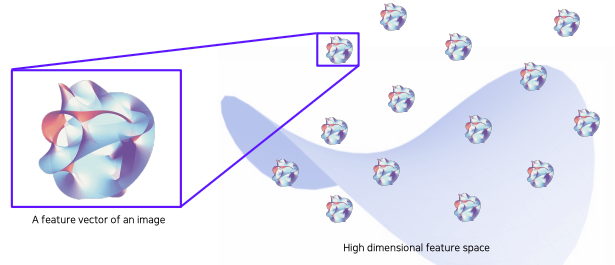
- 위 그림은 우리가 활용할 embedding space 표현이라고 가정하자
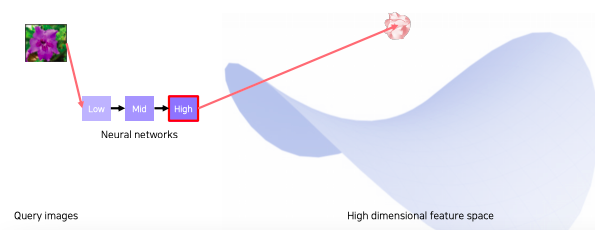
- 실제 구현에서는 미리 학습된 neural network를 준비한다
- query 영상을 넣어주면 특징이 추출이 되고 추출된 특징이 고차원 공간 어딘가에 위치하게 된다
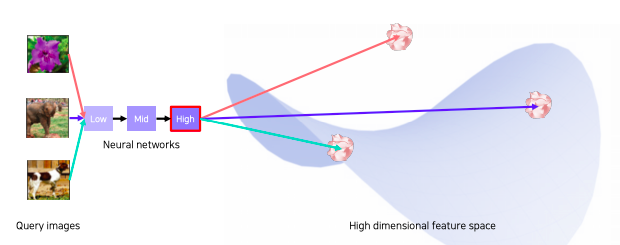
- 영상을 넣을때마다 특징 공간의 각 위치에 특징을 뽑아 놓을 수 있다
- 하나씩 뽑아서 저장할 수 있다
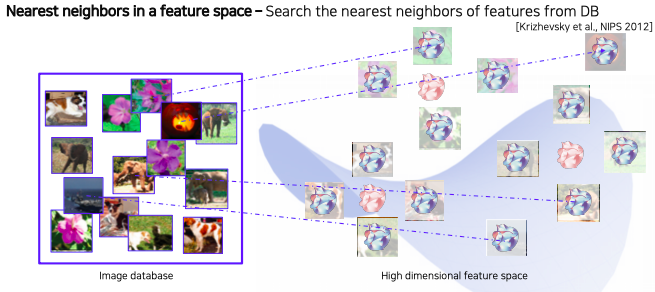
- 모두 뽑아 놓은 데이터의 feature들은 고차원 공간 상에 존재하고 미리 뽑아 놓은 건 db에 저장한다
- db에 저장된 feature들은 다시 원래 영상하고도 association 이 되어있다
- 그래서 각 위치에 특징들은 해당하는 영상들이 존재하는 형태이다
- 그래서 각 위치에 특징들은 해당하는 영상들이 존재하는 형태이다
- Analysis by searched neighbor images
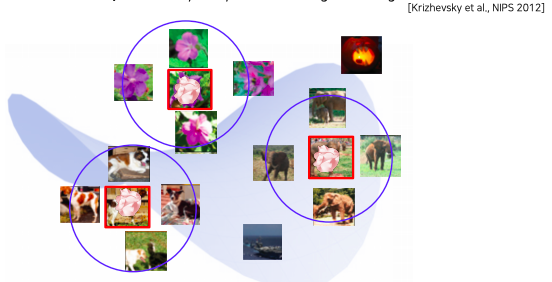
- query image를 넣으면 특징을 뽑아 이 특징과 거리가 가까운 image들을 return해주면 주변예제를 분석한다
- 예제 몇개를 봐서 분석하는 방법을 살펴봤는데
- 검색된 예제를 통해서 분석하는 방법은 전체적인 그림을 파악하기 어려운 단점이 있다
Embedding feature analysis 2
- Dimensinality reduction
- backbone network을 활용해서 특징을 추출하게 되면 고차원 특징 벡터가 나오게 되는데 이것이 너무 고차원이라 해석하기 힘든 문제가 있다
- 이런 문제를 해결하기 위해서 고차원 벡터를 저차원으로 내려서 표현하는 방법 즉, 차원 축소 방법을 통해서 눈으로 쉽게 확인 가능한 분포를 얻어내는 방법을 소개
- t-distributed stochastic neighbor embedding (t-SNE)
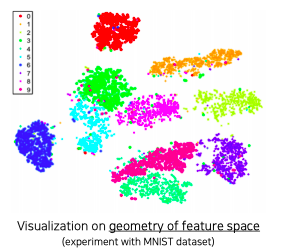
- 각 클래스마다 서로 다른 색으로 표현
- 몇몇 튀는 example들을 제외하곤 전반적으로 비슷한 클래스들 끼리 잘 분포되어 있다
- 이것을 바탕으로 모델이 잘 학습되서 클래스를 잘 구분할 수 있다라는 것을 알 수 있다
- 클래스간의 분포도를 볼 수 있다
Activation investigation 1
-
Layer activation - behaviors of mid - to high-level hidden units
- 중간 layer하고 high layer를 해석하는 다른 클래스의 해석 방법을 살펴보자
- 이 방법들은 layer의 activation을 분석함으로써 모델의 특성을 파악하는 방법

- 위 첫번째 행은 AlexNet에서 Conv5 layer의 138번째 채널의 activation 적당한 값으로 threshoding 후 마스크로 만들어서 영상에 overlay 한 결과이다
- 각 activation의 채널이 Hidden node가 되는데
- 공통적으로 얼굴을 찾는다던지 또는 계단의 난간을 바라보고 있다든지
- 이런 것들을 통해서 각 layer의 hidden node들의 역할을 파악할 수 있다
- CNN은 중간중간 hidden unit들이 각각 간단한 얼굴 detection, 손 detection 등 간단한 다층으로 쌓아서 그것들을 조합해서 물체를 인식한다고 해석할 수 있다
-
Maximally activating patches - Example
- patch 를 뜯어서 사용하는 방법
- 각 layer의 채널에서 하는 역할을 판단하기 위해서 그 hidden node에서 가장 높은 값을 갖는 위치의 금방의 patch를 뜯어 나열한다
- 이를 통해 해당 hidden node들의 역할을 파악할 수 있다

-
Maximally activating patches - patch acquisition
- pick a channel in a certain layer
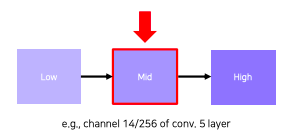
- feed a chunk of images and record each activation value (of the chosen channel)
- crop image patches around maximum activation values

- pick a channel in a certain layer
-
지금까지는 activation을 분석하기 위해서 데이터를 사용했는데
-
이제는 예제 데이터를 사용하지 않고 네트워크가 내재하고 기억하고 있는 이미지가 어떤것인지 분석하는 방법을 소개한다
Activation investigation 3
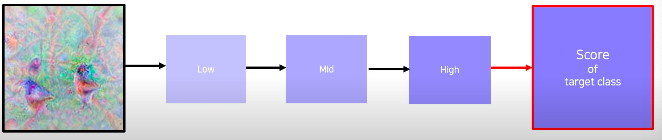
- class visualization - Example
- 각 클래스를 판단할때 이 네트워크는 어떤 모습을 상상하고 있는지 확인하는 방법

- 각 클래스를 판단할때 이 네트워크는 어떤 모습을 상상하고 있는지 확인하는 방법
- 위 그림에서 새 클래스일 경우에는 새 모습들이 추출이 되고
- 강아지 같은 경우에는 강아지 비슷한 형태들을 출력할 뿐만 아니라 강아지 옆에 있는 아이에 모습도 상상하고 있다
- 이를 통해서 이 모델은 새라는 것을 판단하기 위해서 해당 물체만 찾는것이 아니라 주변의 나무 혹은 잎사귀 같은 모습도 찾고 있다고 파악할 수 있고
- 또 다른 해석으로는 학습에 사용된 데이터셋이 조금 가족적인 사진으로 bias가 되어있다라는 우려되는 포인트를 파악할 수 있다
- 강아지만 들어있는 데이터셋을 활용해서 학습한것이 아니란걸 파악
- class visualization - Gradient ascent - 최적화를 통해서 합성 영상을 찾아나가는 과정을 거친다 - 먼저 모델을 학습할때 backpropagation 알고리즘을 통해서 gradient descent를 통해서 목적함수인 loss 들을 최소화하는 과정과 마찬가지로 접근한다 - 합성영상을 만들어주기 위해서 loss를 만들어주고 최적화를 통해서 영상을 합성하게 되는데 loss는 아래와 같이 디자인 한다 - 두 개의 loss를 합성해서 사용한다 - 첫번째 I는 영상입력이고 - 어떤 입력을 주었을때 CNN 모델 $f$ 를 거쳐서 출력되는 하나의 클래스 score를 출력하는 부분만 고려한다 - 이 score를 maximize한다 - generage a synthetic image that triggers maximal class activation  - 이해할수 있는 영상을 유도하기 위해 간단한 loss인 regularization term을 추가한다 
- Gradient Ascent - image synthesis
- Get a prediction score (of the target class) of a dummy image (blank or random initial)
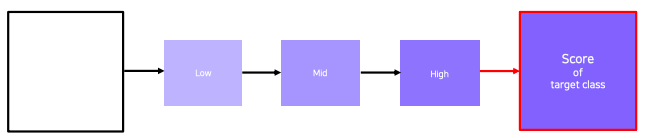
- Backpropagate the gradient maximizing the target class score with respect to the input image
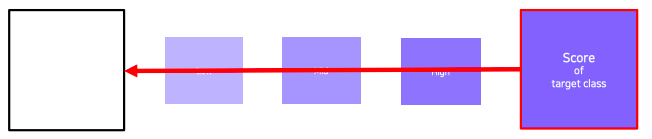
- update the current image

- Get a prediction score (of the target class) of the current image
- Backpropagate the gradient maximizing the target class score with respect to the input image
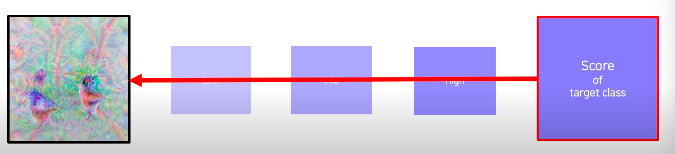
- update the current image

- Get a prediction score (of the target class) of a dummy image (blank or random initial)
- 위 방법은 중간 단계를 분석하는 것이 아니라 결론을 보고 CNN에 대한 해석을 하는 방법이다
- 어떤 입력을 초기에 넣어주냐에 따라서 다양한 결과를 얻을 수 있다
- 그래서 해당 neural network는 하나의 클래스에 대해서 어떤 이미지를 상상하고 있는지는 여러 관점을 거쳐서 다양한 영상들을 만들어 놓고 그 패턴들을 관찰해야한다
- 지금 까지 모델 자체 행동에 대해서 분석하는 방법들을 살펴봤다
- 이번에는 모델이 특정 입력을 받았을때 이 특정 입력을 어떤 각도로 바라보고 있는지 해석하는 방법을 살펴본다
Model decision explanation
Saliency test 1
- 영상이 주어졌을때 그 영상이 제대로 판정되기 위한 각 영역의 중요도를 추출하는 방법
- Occlusion map
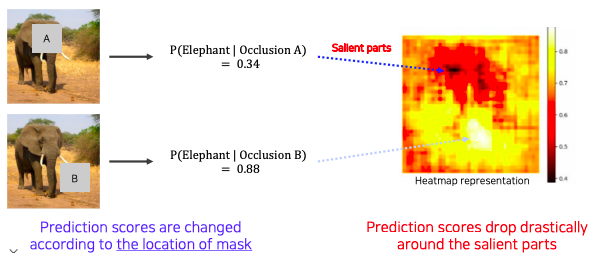
- 우측에는 위치에 따라 변하는 score를 색으로 표현
- 색이 검정색으로 변할수록 물체 검출에 민감한 영역이고
- 반대로 밝아질수록 상관없는 영역이다
Saliency test 2
-
via Backprogation - Example
- 앞서 살펴봤던 gradient ascent를 이용해서 몽환적인 분석 이미지를 생성했던 방법과 유사하다
- 이번에는 random 이미지를 입력으로 넣는것이 아닌
- 특정 이미지를 classification을 해보고 최종 결론이 나온 class에 결정적으로 영향을 미친 부분이 어디인지 heatmap 형태로 나타내는 기법이다

-
via Backpropagation - Derivatives of a class score with respect to input domain
- get a class score of the target source image
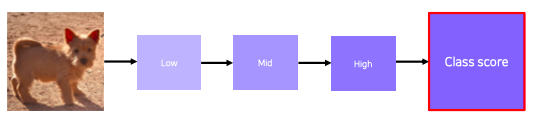
- backpropagate the gradient of the class score with respect to input domain
- visualize the obtained gradient magnitude map (optionally, can be accumulated)
- 얻어진 gradient를 절대값을 취해준다
- 여기서는 절대값 혹은 제곱을 취하는 이유는 gradient의 크기 자체가 중요한 정보 즉, 입력에서 이부분이 많이 바뀌어야 score가 바뀌는 것을 의미하니깐 그 부분이 민감한 영역이다라는 것을 의미 한다 그래서 부호 보다는 절대적인 크기를 중요하게 생각해서 절대값 혹은 제곱을 취해줘서 gradient의 magnitude를 구해서 visualize한다
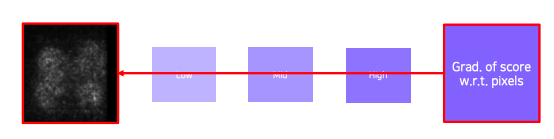
- get a class score of the target source image
-
위 방법은 input 이 들어가서 최종 출력에 대해서 input단에서 어떤 부분이 민감했는지를 찾는 방버으로 볼 수 있다
Backpropagation-based saliency
- Rectified unit (backward pass)
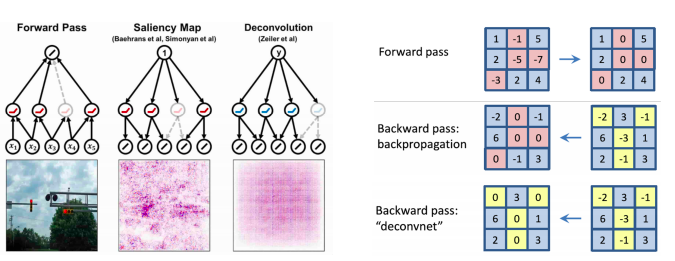
- 일반적으로 CNN에서 Relu가 많이 사용되는 Relu를 사용할때 foward pass 에서 음수가(분홍색으로 표현된 부분)나온 부분을 relu 에 의해서 0으로 마스킹 된다
- 마스킹 패턴을 저장 해뒀다가 backpropagation할때 양수하고 음수가 합쳐진 gradient가 오면 이전에 음수 마스크로 저장되어 있던 패턴 마스크로 마스킹으로 해줘서 backprogation을 한다
- Zelier et al 가 사용한 방법은 forward pass 때의 relu 패턴을 사용하는 것이 아니라 deconvolution된 activation이 반대로 backward로 되면서 내려올때 그때의 activation의 양수와 음수값을 따져서 음수 마스킹을 한다
- backward 연산할 때 gradient 자체에다가 relu를 적용하게 된다
- 이것을 수식으로 표현한 그림:

-
Guided backpropagation
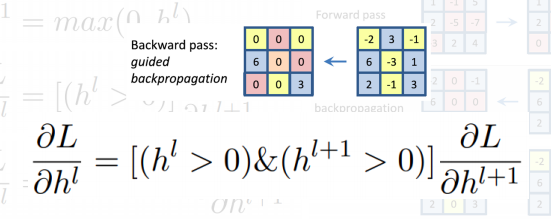
-
foward 에 올라갈때 relu의 패턴도 0으로 만들어주고 반대로 backward할때도 음수값을 으로 만들어 준다
-
Guided backpropagation - comparison

-
backprop 이나 DeConv 방법보다도 굉장히 clear하게 이해가 된다
-
두 마스크를 모두 사용한 것이 forward 할때도 결과에 긍정적인 영향을 미치는 양수들을 참조하고 동시에 backward 할때도 gradient를 통해서 더 강화하는 움직임을 activation들을 고른것이다
-
이 두개의 조건을 만족하는 activation들이 실제적으로 최종 결과를 만들어냈을때 더 깨끗하고 좋은 결과를 만든다고 파악
Class activation mapping
-
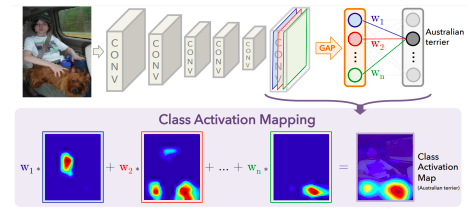
CAM - Example
- visualize which part of image contributes to the final decision

- visualize which part of image contributes to the final decision
-
Global average pooling (GAP) layer instead of the FC layer
- Convolution 파트에 마지막에서 나온 feature map을 FC layer을 바로 통과하지 않고 GAP을 하도록 바꿔준다
- 그 다음에 FC layer 하나만 통과시켜준다
- 그래서 최종적으로 classification하도록 만들어준다
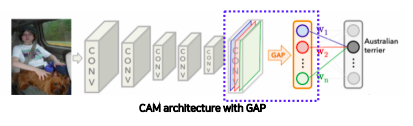
-
Derivation of CAM : Changing the order of the operations
- 먼저 하나의 클래스 에 대해서 score를 구하는 방법은 : 마지막에 FC layer의 weight(클래스에 해당하는 weight와)들과 마지막에 GAP feature로 각각 공간축의 평균값을 내서 하나의 노드로 만든 layer의 feature들의 linear combination으로 만든다
- 여기에서의 채널은 마지막 convolution layer의 채널 수라고 생각하면 된다
- GAP feature를 잘 살펴보면 모든 픽셀에 대해서 convolution feature map을 각 채널마다 평균을 취한거다
-
CAM은 global average pooling을 적용하기 전이기 때문에 아직 공간에 대한 정보가 남아있다
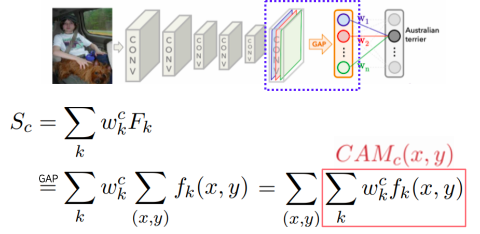
-
by visualizing CAM, we can interpret why the network classified the input to that class
- 어떤 부분을 참조했는지 결과가 눈에 보이는 heatmap형태로 표현된다
-
GAP layer enables localization without supervision
- 어떤 물체의 위치 정보를 주지 않았는데에도 불구하고 단순한 영상 인식기를 학습했는데 위치를 파악할 수 있다
- 이러한 학습 방식 즉, object detection과 같이 좀 더 정교한 task를 좀 더 rough한 영상 인식 task 같은걸로 데이터를 사용해서 간접해결하는 방법을 weakly supervised learning 이라고 부른다
-
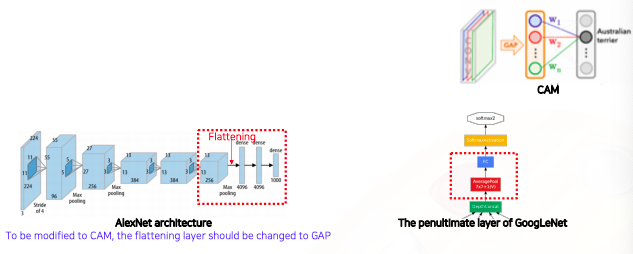
CAM 적용이 가능한 제약으로는 마지막 layer의 구성이 GAP과 FC layer 로 이루어져야 한다는게 단점이다
-
Requires a modification of the network architecture and re-training
- 좌측 AlexNet을 보면 마지막 layer에 flattening이 들어가서 벡터로 만들어주고 fc layer도 여러게가 들어가 있다
- 그래서 이부분에 대한 구조를 바꿔주고 재학습을 해야하는데 그러면 모델 구조가 바뀌었기 때문에 튜닝된 파라미터들과 맞지 않을수 있어서 성능이 떨어질수 있다
- 그래서 CAM을 사용하게 되면 성능이 바뀐다는 단점도 있다
-
ResNet and GoogLeNet already have the GAP layer
-
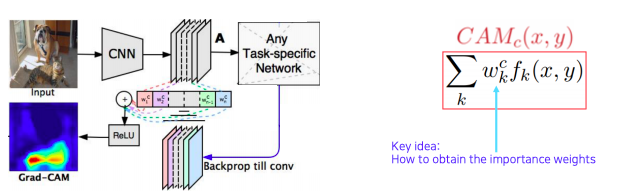
하지만 모든 architecture 가 이렇게 설계되어 있지 않다 그래서 구조를 변경하지 않고 재학습도 필요없이 미리 학습된 네트워크에서 CAM을 뽑을수 있는 방법으로 Grad-CAM 이 제안됬다
-
Grad-CAM - Example
- 입력 데이터를 넣었을때 고양이로 판별할 경우 어디를 보고 고양이로 판별하는지
- 그리고 강아지로 판별할 경우 어디를 보고 강아지로 판별하는지 명확하게 heatmap을 그려줄 수 있다

-
Get the CAM result without modifying and re-training the original network
- 기존 pre-train 된 네트워크를 변경하지 구할 수 있기 때문에 꼭 영상인식 task에 국한될 필요가 없다
- 어떤 task이던지 backbone이 CNN이기만 하면 사용할 수 있다
-
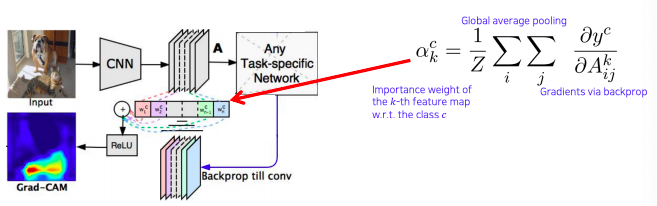
Measure magnitudes of gradients as neuron importance weights
-
이전에 gradient를 backpropagation해서 saliency map을 유도했던 방법을 응용해서 weight를 구한다
- 이전에 saliency map을 backpropagation으로 구하는 방법은 입력 영상까지 backpropagation을 했지만 이번에는 우리가 관심을 가지고 있는 activation map까지만 backpropagation한다
- 그래서 현재 task에서 해석하고 싶은 결과 (클래스에 대한 score) 를 변화 시키는 loss로 부터 backpropagation gradient를 구하게 되고 공간축으로 global average pooling을 적용한다
- 그래서 각 채널에 gradient 성분의 크기를 구하게 된다
- 이 는 activation map을 결합하기 위한 weight로 사용한다
-
With ReLu, we focus on the positive effect only
-
activation map하고 weight 하고 선형 결합을 하는데 CAM과는 다르게 ReLu를 사용해서 양수값만 사용한다
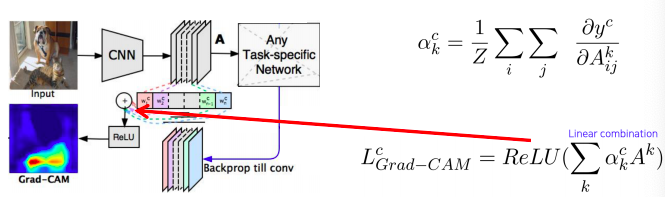
-
Grad-CAM works with any task head
-
딱히 CNN backbone 외에는 필요한 특수한 구조나 요구조건이 없다
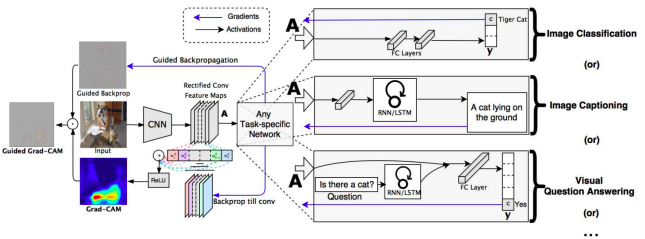
-
SCOUTER - Example

Conclusion
- GAN dissection
- spontaneously emerging interpretable representation during training
- Not only for analysis but also for manipulation applications

