- 영상 내에 존재하는 객체를 인식하는 방법은 픽셀 마다의 클래스를 분류하는 segmentation 뿐만 아니라 물체 하나하나마다 bounding box 단위의 예측도 있다
- 이러한 task를 object detection이라고 하며 자율주행, CCTV 등 다양한 분야에 활용되고 있다
- Object detection을 위한 모델은 크게 one-stage detector와 two-stage detector로 구분할 수 있는데 시대의 흐름을 따라 각각의 모델들의 발전사를 소개한다
Further Questions
- Focal loss는 object detection에만 사용될 수 있을까요?
- Focal loss는 object detection 뿐만 아니라 classification task에도 자주 활용되고 있습니다. 결국 cross entropy를 확장하여 class imbalance가 심한 경우를 대비한 추가 parameter가 존재하는 loss이기 때문에 기존에 cross entropy를 활용하는 많은 task에 쓰일 수 있습니다.
- CornerNet/CenterNet은 어떤 형식으로 네트워크가 구성되어 있을까요?
- 결국 object detection을 통해 얻고자 하는 bounding box는 left top and right bottom의 2가지 점으로 얻어낼 수 있고 CornetNet은 이러한 방식으로 detection task를 풀고자 하였습니다. 또한 bounding box는 center point와 물체의 크기의 조합으로도 표현될 수 있으며 CenterNet은 이와 같은 방식으로 해결하고자 한 시도입니다.
Object detection
What is object detection?
- Fundamental image recognition tasks
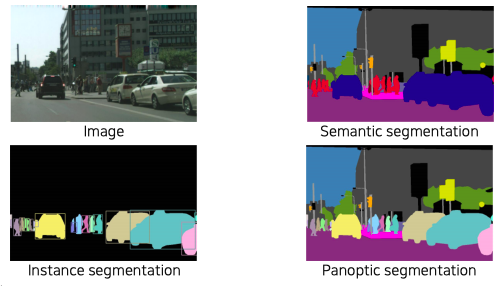
- Semantic segmentation에서 부터 더 advanced 한 instance, panoptic segmentation으로 가기 위해선 개체 단위를 구분할 수 있는 object detection을 알아야 한다
- semantic segmentation과 instance, panoptic segmentation과의 가장 큰 차이점은 같은 사람 또는 자동차라는 클래스라도 개체가 다르면 구분이 가능한지 아닌지의 여부이다 즉, instance를 구분하는지에 대한 여부이다
- instance, panoptic segmentation은 이 개체들을 따로따로 segmentation이 가능하기 때문에 기술들이기 때문에 이를 기반을 훨씬 유용한 정보제공이 가능한 fundamental한 기술이다
- panoptic segmentation 은 instance segmentation을 포함한 더 큰 기술이라고 볼 수 있다
- 이런 개체들을 구분하는 요소 기술이 object detection이다
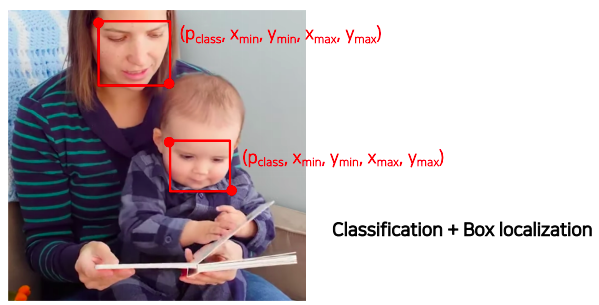
- object detection 은 classification 문제와 bounding box 를 동시에 추정하는 문제라고 볼 수 있다
- 특정 object들을 bounding box 형태로 위치를 측정하고 해당 박스내에 물체의 카테코리까지 인식하는 문제이다
What are the applications of object detection?
-
Autonomous driving

-
Optical Character Recognition (OCR)
- 글자인식

- 글자인식
Two-stage detector
Traditional methods - hand-crafted techniques
-
Gradient-based detector (e.g., HOG)
- 영상의 경계선을 기반으로 모델링을 통해 object를 찾는다

- 영상의 경계선을 기반으로 모델링을 통해 object를 찾는다
-
selective search
- 사람이나 특정 물체 뿐만 아니라 다양한 물체 후보들에 대해서 영역을 특정해서 제안해주는 방법
- 즉, bounding box 를 제안해준다
- 영상을 비슷한 색끼리 잘게 분할 해준다 (over-segmentation)
- 잘게 분할된 영역들을 다시 비슷한 영역끼리 합쳐준다 (iteratively merging similar regions)
- 비슷한다는 정의: 색감, gradient의 특징 혹은 분포 등 이러한 기준을 먼저 정의해야한다 - 합쳐준 결과값에서 큰 segmentation들을 포함하는 bounding box를 추출해서 물체의 후보군으로 사용하는 알고리즘이다 (extracting candidate boxes from all remaining segmentations)
- 사람이나 특정 물체 뿐만 아니라 다양한 물체 후보들에 대해서 영역을 특정해서 제안해주는 방법

R-CNN
- Directly leverage image classification networks for object detection
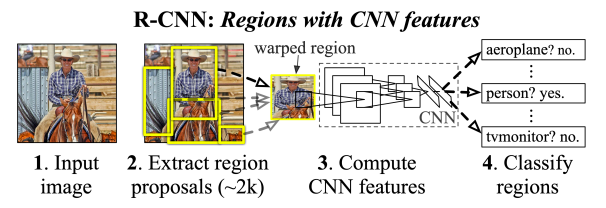
- 기존의 image classification 을 최대한 활용하기 위해 위와 같이 간단하게 설계되었다
- 첫번째로는 영상에 selective search로 region proposal를 먼저 구한다
- 각 region proposal을 image classification convolution neural network에 input에 적절한 size로 warping 해준다
- 기존에 미리 training과 fine-tuning 되있는 CNN에다가 적절한 size로 warping된 입력을 넣어줘서 카테코리를 classification 하게끔 만든다
- 맨 마지막에 classifier는 간단한 고전적인 SVM 방식을 써서 object detection 을 한다
- 단점으로는 각각의 region proposals 하나하나 모델에 넣어서 processing을 해야하기 때문에 속도가 굉장히 느리고
- region proposals은 별도의 selective search 같은 hand design 된 알고리즘을 사용하기 때문에 학습을 통해서 성능향상의 한계가 있다
Fast R-CNN
- Recycle a pre-compute feature for multiple object detection
- 매번 region proposals 마다 warping 해서 CNN에 독립적으로 입력해서 결과를 뽑는 느린 방식을 개선하고자 만들었다
- 핵심은 영상 전체에 대한 feature 를 한번에 추출하고 이를 재활용해서 여러 object들을 detection할 수 있게 사용한다
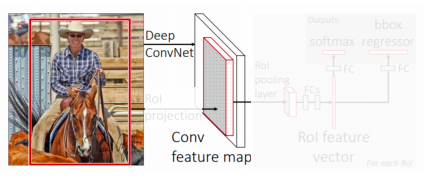
- Conv. feature map from the original image
- CNN에서 convolution layer까지 미리 feature map을 뽑아 놓는다
- fully convolutional 한 구조의 네트워크는 입력 사이즈와 상관없이 feature map을 추출 할 수 있다
- 그래서 입력 사이즈를 warping하지 않아도 괜찮다
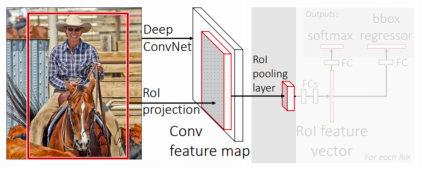
- ROI feature extraction from the feature map through ROI pooling
- 한번 뽑아 놓은 feature를 여러번 재활용 하기 위해 제안된 layer이다
- ROI는 region of interest 라고 해서 region proposal이 제시한 물체의 후보 위치들을 의미한다
- 이렇게 bounding box가 주어지게 되면 ROI에 해당하는 feature 만을 추출하여 일정 사이즈로 resampling한다
- fixed dimension을 가질 수 있도록 resampling한다
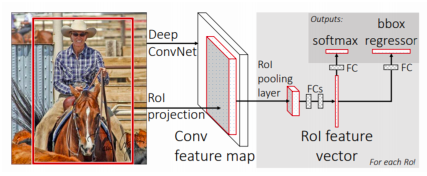
- Class and box prediction for each RoI
- Class와 더 정밀한 bounded box의 위치를 추정하기 위해서 bounding box regression을 수행하고 classification 을 수행한다
- 여기서 사용된 것은 fc layer 들로 각각 task 를 해결했다
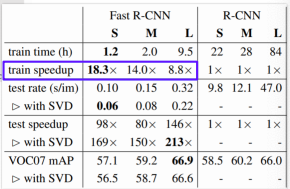
- feature 만 재활용 했는데 기존의 R-CNN에 비해 최대 18배가 더 빠른 속도를 얻을 수 있다
- 그러나 여전히 region proposal 은 selective search와 같은 별도의 알고리즘을 사용하는 단점이 있다
- 그래서 데이터만으로 성능을 높이는데는 한계가 있다
- 손으로 디자인한 알고리즘의 성능을 올릴 수 있는 한계
Faster R-CNN
- 최초의 End-to-end object detection by neural region proposal
- region proposal을 neural network 기반으로 대체
- IoU

- 두 영역의 overlap을 측정하는 기준을 제공하는 metric
- IoU의 수치가 높을수록 두 영역이 잘 matched 됬다 라고 볼수 있다
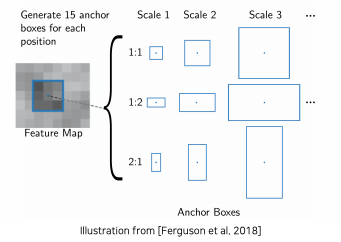
- faster R-CNN에 새로 등장한 부분이 바로 region proposal이라는 개념인데 이 부분을 어떤 아이디어로 구현 했는지 Anchor box를 통해 알아보자
- anchor box는 각 위치에서 발생할거 같은 box들을 미리 rough한 후보군들을 정해놓는다
- 비율과 스케일이 다른 영역을 각 위치마다 미리 정해놓고 사용한다
- Anchor boxes
- A set of pre-defined bounding boxes
- 학습 데이터의 bounded box와 어떻게 loss를 적용할지를 결정하는 기준
- IoU with GT > 0.7 positive sample
- IoU with GT < 0.3 negative sample
- Faster R-CNN에서는 서로 다른 스케일 3개와 서로 다른 비율 3개 그래서 총 9개의 anchor box를 사용했다
- 이는 가변적인 파라미터이다

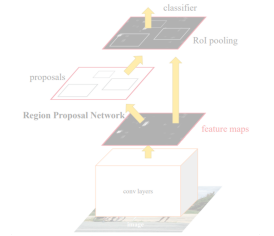
- Time-consuming selective search Region Proposal Network(RPN)
- 가장 핵심적인 변화는 selective search와 같은 3rd party의 region proposal 알고리즘 대신에 region proposal network라고 불리는 모듈을 제안해서 대체
- Fast R-CNN에서와 마찬가지로 영상 하나에서부터 공유되는 feature map을 미리 뽑아 놓는다
- RPN에서 region proposal을 여러개 제안하고
- 이 region proposal을 이용해서 마찬가지고 RoI pooling을 수행

- feature map관점에서 fully convolution 하게 sliding window방식으로 매 위치마다 k 개의 anchor box를 고려한다
- 미리 정해놓은 k개의 anchor box를 고려할때 각 위치에서 256 - dimension에 feature vector하나를 추출하고 2k개의 object인지 아닌지를 판별하는 2k개의 classification score를 뱉어낸다
- 2k : object 영역인지 object 영역이 아닌지 각각의 anchor box에 대해서 구별을 하는 형태로 classification score가 나온다
- 그리고 k개의 bounded box의 정교한 위치 regession하는 4k개의 regression output이 출력된다
- 4k : bounded box하나를 정의하기 위해서 너비 하고 높이 정보가 필요하기 때문에 4 dimension이다
- test 할때는 RPN 에서는 일정 objectiveness score이상 나오는 경우도 많고 또 엄밀한 threshold를 정하기가 어려워서 엄청 많이 중복되고 겹쳐지는 bounding box 들이 생성되게 된다
- RPN는 정말 regional propose를 많이 해준다
- 하지만 이것을 효과적으로 필터링 해주고 screening해주는 방법으로 NMS 알고리즘을 사용한다
- 그래서 이를 통해 그럴듯한 object bounded box만 남겨 놓고 RPN에서 허수로 제안한것들은 제거하는 알고리즘 이다
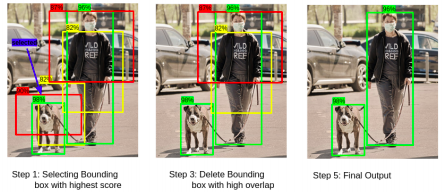
- Non-Maximum Suppresion (NMS)
- step 1: Select the box with the highest objectiveness score
- step 2: compare IoU of this box with other boxes
- step 3: Remove the bounding boxes with IoU >= 50%
- step 4: move to the next highest objective socre
- step 5: repeat steps 2-4
Summary of the R-CNN family
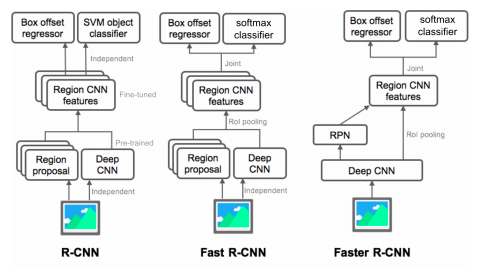
- R-CNN
- region proposal을 별도의 알고리즘을 사용
- CNN 부분도 target task에 대해서 학습하지 않고 미리 pretrain 되있다
- 마지막 부분만 간단한 classifier를 통해서 fine-tuning을 한다
- Fast R-CNN
- 미분 가능한 region pooling 이라는 모듈을 통해서 하나의 feature로 부터 여러개의 물체를 탐지 가능하도록 만들어서 CNN 부분을 학습 가능하도록 만든다
- 그러나 여전히 region proposal 이 학습 가능한 모듈이 아니라는 단점
- Faster R-CNN
- Region proposal 부분도 학습 가능한 RPN 이라는 네트워크 구조로 만들어서 전체 process 가 end-to-end 학습 가능하도록 설계
- joint loss가 backpropagation을 통해 RPN과 Feature 둘다 학습이 되서 target task 에 orient된 feature를 학습할수 있는 첫번째 구조이다
Single-stage detector
Comparison with two-stage detectors
- One-stage vs two-stage
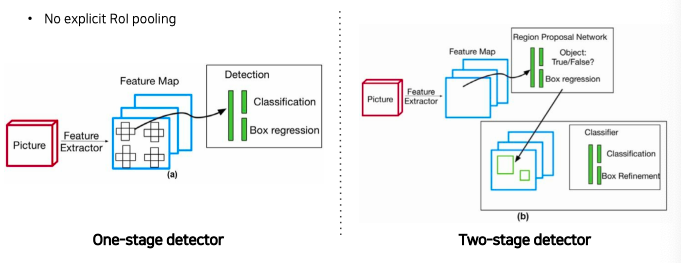
You only look once (YOLO)
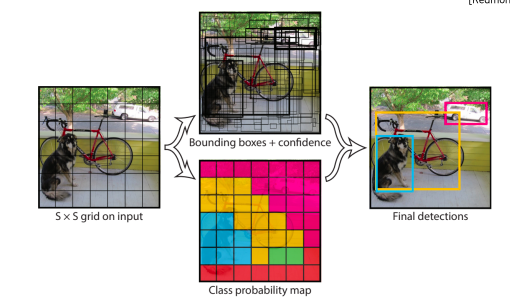
- one-stage(single stage) detector
- 정확도를 조금 포기하더라도 속도를 확보하여 real-time detection이 가능하도록 설계하는 것이 목적
- region proposal을 기반으로한 RoI pooling을 사용하지 않고 곧바로 box regression과 classification을 하기때문에 구조가 단순하고 빠른 수행시간을 보여준다
- input 이미지를 S x S grid로 나누고 각 grid에 대해서 B개의 박스 즉 4개의 좌표하고 confidence score를 예측한다
- 그거에 따른 각 위치에서의 class score를 따로 예측한다
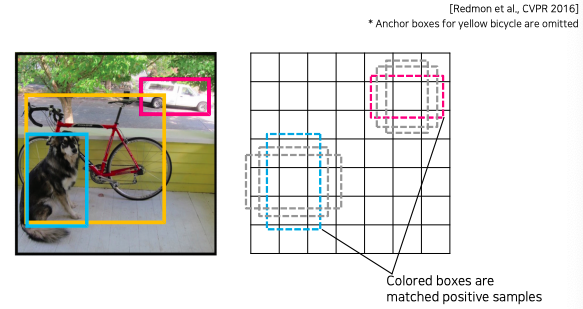
- 이전에 봤던 anchor box 와 유사한 개념이다
- 유사하게 미리 각 위치의 bounded box의 형태로 B개를 정해놓는다
- 정해진 것들에 대해서 정교한 박스로 regression을 해주는 부분도 포함되있다
- 최종 결과는 NMS 알고리즘을 통해서 정의된 bounded box만 출력한다
- 학습 시킬때도 이전에 Fast R-CNN에서 사용했던 방식과 동일하다
- ground truth 와 매치된 anchor box들을 positive으로 간주하고 학습 레이블을 positive 으로 걸어준다
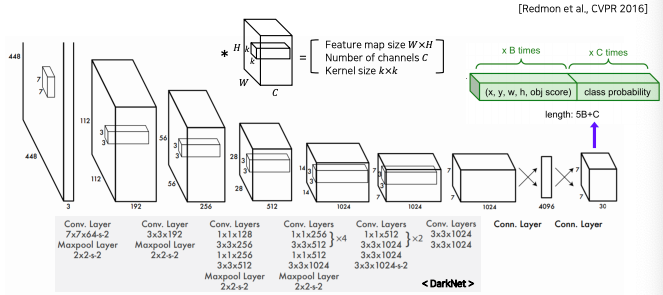
- 일반 CNN 구성과 매우 동일하다
- Conv 마지막 layer로 7x7이 나온다
- 최종적으로 7x7 해상도에 30채널의 결과가 나온다
- 30 채널인 이유
- bounded box의 anchor를 2개를 사용한 case이고 (즉, B는 2 이다)
- class는 20개의 object class를 고려했다
- 그렇다면 length 는 5(2) + 20 = 30 이된다
- 각 위치마다 30 dimension 짜리 결과가 나온다
- grid는 SxS로 나눈다고 했는데 여기서 S가 7이 된다
- 이 S는 convolution layer에 의해서 마지막 layer의 해상도로 결정이 된다

- Faster R-CNN 보다 훨씬 빠르다
- Yolo : 21 frame/sec
- Faster R-CNN : 7 frame/sec
- 하지만 조금 낮은 성능을 보인다
- Yolo : 66.4 mAP
- Faster R-CNN :: 73.2 mAP
Single Shot MultiBox Detector (SSD)
- Yolo는 맨 마지막 layer에서만 prediction하기 때문에 localization 정확도가 조금 떨어지는 결과를 볼 수 있다
- 이를 보안하기 위해서 SSD가 나왔다
- SSD는 multi-scale object를 더 잘 처리 하기 위해서 중간 feature map을 각 해상도에 적절한 bounded box들을 출력할 수 있도록 multi-scale 구조를 만들었다
- 각 feature map마다 해상도에 적절한 bounded box의 크기에 대한 결과들을 예측할 수 있도록 만들었다
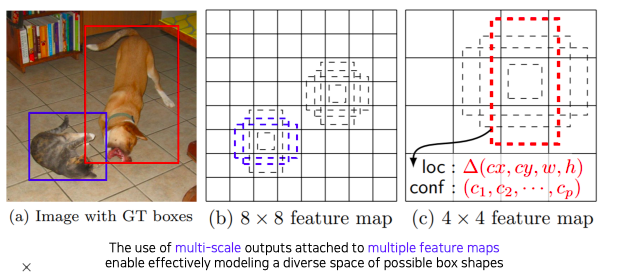
- Architecture
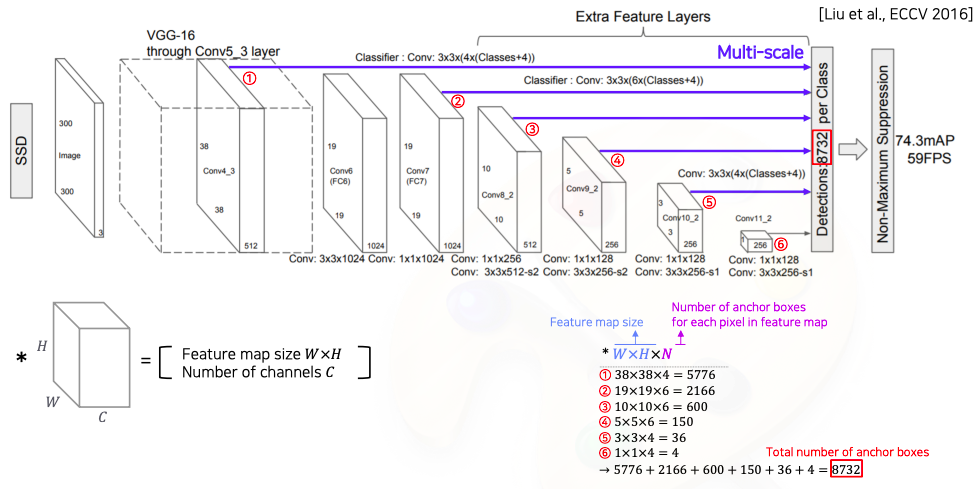
- VGG를 backbone으로 사용해서 Conv4 블록에 중간 feature map 출력에서 부터 최종 결과들을 출력하게끔 classifier가 붙어있다
- 각 scale 마다 object detection 결과를 출력하도록 설정해서 다양한 scale에 object 에 대해서 더 잘 대응할수 있도록 설계
- 여기서도 마찬가지로 하나의 anchor box에서 class 수와 함께 4개의 coordinate 정보를 출력 해야하기 때문에 class개수 + 4가 된다
- 최종적으로 8732 라는 숫자는
- 각 layer에서 parsing된 detection bounded box 들의 총합
- 즉, 각 feature map마다 몇개의 anchor box가 각 위치마다 존재하는지를 계산해서
- 각 layer의 결과를 더해주면 anchor box들의 숫자가 나온다
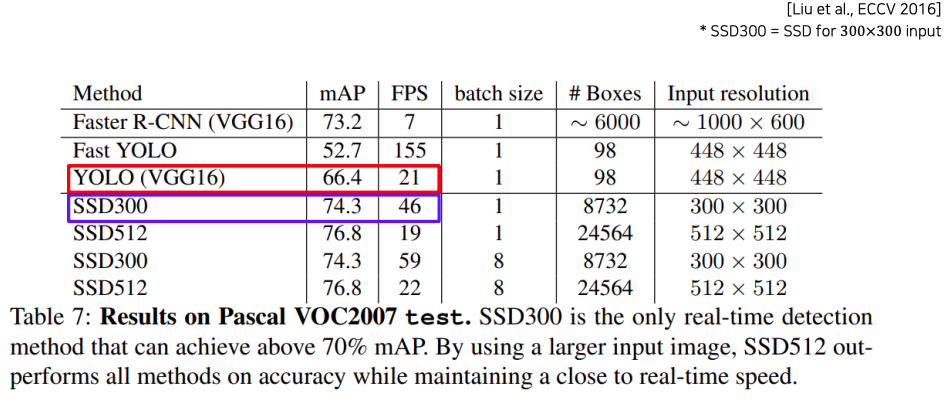
- Yolo 보다 훨씬 더 높은 성능과 더 빠른 속도를 보여준다
Two-stage detector vs one-stage detector
Focal Loss
- single stage 방법들은 RoI pooling이 없다보니깐 모든 영역에서의 loss가 계산되고 일정 gradient가 발생하게 된다
- 이것이 왜 문제인제 살펴보자
- 일반적인 영상에는 background 영역이 더 넓고 실제 물체는 일부분을 차지하고 있기 때문에 심지어 detection 문제에서는 이 물체가 적당한 크기의 bounded box하나로만 취급이 된다
- 그래서 postive sample은 엄청 적은 반면에 배경에서 오는 물체가 아닌 부분들은 유용한 정보도 없으면서 엄청나게 많은 영역과 갯수로 class imbalance 문제를 발생 시킨다
- class imbalance problem
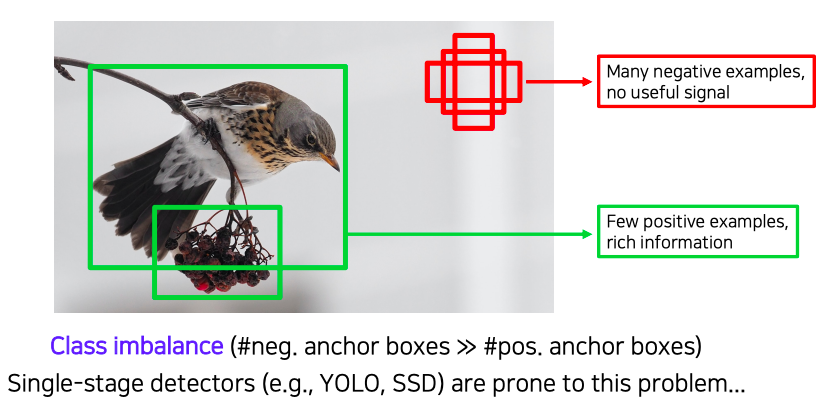
- 모든 single stage detector들이 이러한 문제들을 가지고 있다
- class imbalance 문제를 해결하기 위해서 focal loss가 제안 되었다
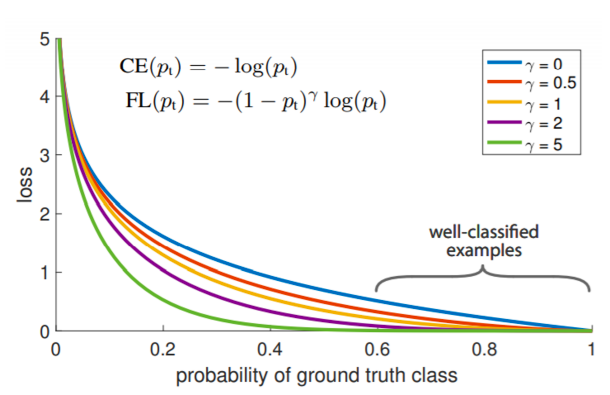
- focal loss는 cross entropy의 확장이라고 볼 수 있다
- 앞에 term에 붙는다
- 라는 파라미터가 있고 에 따라서 function의 shape을 정해준다
- 위 그림에서 파란색 선이 cross entropy 이다
- true class에 대한 score가 높게 나와서 정답을 잘 맞추게 되는 영역을 보게 되면 낮은 loss값을 반환하고 맞추지 못하게 되면 큰 loss 값을 반영하는 표준적인 loss라고 볼 수 있다
- focal loss는 여기서 한발 더 나아가서 앞에 확률 term을 붙여준다
- 잘 맞춘 애들은 더 loss 를 낮게 만들고
- 반대로 맞추지 못하면 더 sharp한 loss를 주는것이다
- 에 따라서 휘는 각도가 확 바뀐다
- 오답일때는 가 큰 경우에 더 작은 loss를 갖는대
- loss의 절대값이 중요한것이 아니라 네트워크를 학습시킬때 gradient를 사용하기 때문에
- gradient를 생각했을때 가 클수록 굉장히 sharp 한 값으로 학습을 한다
- 그렇기 때문에 정답에 가까워지는 gradient는 0에 가까워지고 sharp 한 gradient들이 발생하는 부분이 큰 영향을 끼친다
RetinaNet
- one-stage network
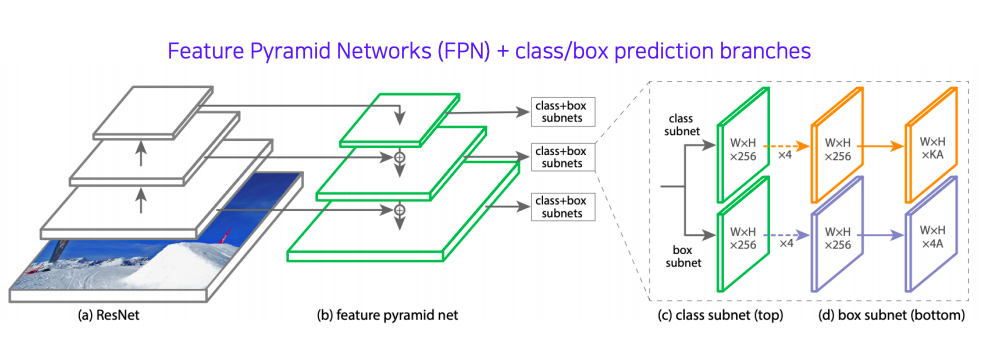
- 이전에 배웠던 U-Net가 유사하다
- U-Net과 달리 concat이 아닌 더하기 연산으로 fusion이 되고
- class head와 box head가 따로 구성되서 classification과 box regression을 dense하게 각 위치마다 수행한다
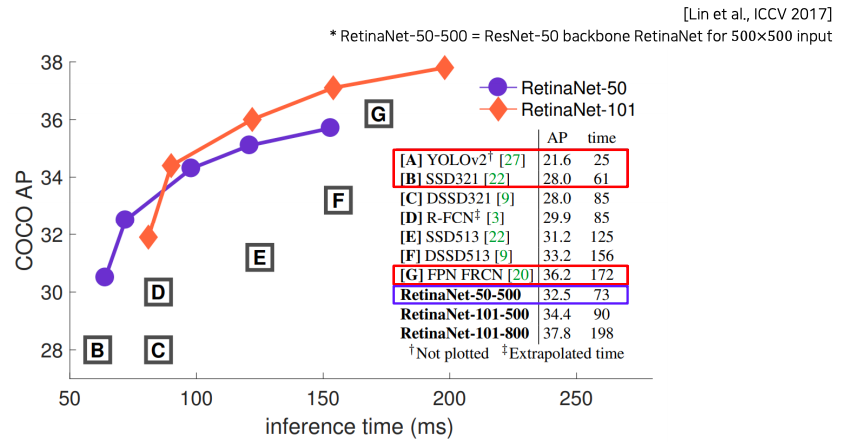
- SSD와 비슷한 속도를 가지고 더 좋은 성능을 보인다
Detection with Transformer
DETR

- transformer를 object detection에 적용한 사례이다
- 기본적으로 CNN의 feature와 각 위치의 multi-dimension으로 표현한 encoding을 쌍으로 해서 입력 토큰을 만들어 준다
- encoding으로 추출된 특징들을 decoder에 넣어준다
- object query를 활용해서 transformer 에게 질의를 한다
- query 는 학습된 position encoding이라고 볼 수 있다
Further Reading
- detecting objects as points
- object detection의 또 다른 trend 로는 detection bounded box를 bounded box regression 하지 말고 다른 형태의 데이터 구조로 탐지가 가능한지에 대한 연구가 진행되고 있다
- 최근엔 박스 대신에 물체의 중심 점을 대신 찾는다던지
- 왼쪽 위와 오른쪽 아래의 양끝점을 찾는것으로 더 효율적인 계산을 하는 등 다양한 방법을 연구중이다

Reference
- Object detection
- Kirillov et al.,Panoptic Segmentation, CVPR 2019
- Two-stage detector (R-CNN Family)
- Dalal et al.,Histograms of Oriented Gradients for Human Detection, CVPR 2005
- Uijlings et al., Selective Search for Object Recognition, IJCV 2013
- Girshick et al., Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, CVPR 2014
- Girshick et al., Fast R-CNN, ICCV 2015
- Ferguson et al., Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning, Smart and Sustainable Manufacturing Systems 2018
- Ren et al., Faster R-CNN: Towards Real-Time Object detection with Region Proposal Networks, NeurIPS 2015
- Single-stage detector
- Ndonhong et al., Wellbore Schematics to Structured Data Using Artificial Intelligence Tools, Offshore Technology Conference 2019
- Redmon et al., You Only Look Once: Unified, Real-Time Object detection, CVPR 2016
- Liu et al., SSD: Single Shot MultiBox Detector, ECCV 2016

아기개발자