- Image classification은 사진이 주어졌을 때 사진 전체를 카테고리로 분류한다
- 반면 Semantic Segmentation은 사진이 주어졌을 때 사진 내 각 픽셀을 카테고리로 분류하는 task 이다
- 즉, 하나의 사진이 아닌, 사진에 있는 모든 물체들을 분류한다는 것이다
- 여기에서는 먼저 최초의 end-to-end segmentation 모델 FCN을 시작으로 Hypercolumn 모델을 배운다
- 다음으로 segmentation의 breakthrough라고 볼 수 있는 UNet 모델에 대해 공부하고 Pytorch 코드 실습을 한다
- 끝으로 최근까지 좋은 성능을 보이고 있는 DeepLab v3에 대해 배운다
Further Readings
Semantic segmentation
What is semantic segmentation?
- Classify each pixel of an image into a category
- Don’t care about instances. Only care about semantic category

- semantic segmentation은 영상속에 있는 물체의 마스크를 생성한다
- 이때 주의해야 할 특징은
- 같은 클래스지만 서로 다른 물체를 구분하지는 않는다
- 예를 들어 영상속에 자동차가 여러대 있든 사람이 여러명 있든 다 같은 색으로 분류한다
- 같은 클래스이더라도 다른 물체로 구분하는 것은 instance segmentation에서 별도로 다룬다
Where can semantic segmentation be applied to?
- Medical images
- Autonomous driving
- Computational photography
- 컴퓨터를 이용해서 사진을 편집하는 기술들에 적극적으로 활용된다
- etc
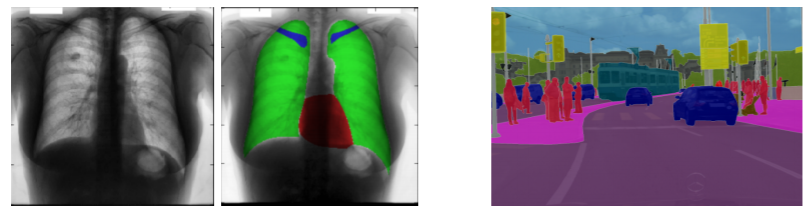
Semantic segmentation architectures
Fully Convolutional Networks (FCN)
-
The first end-to-end architecture for semantic segmentation neural net
- end-to-end : 입력에서 부터 출력까지 모두 미분 가능한, 그래서 입력과 출력 데이터의 pair만 있으면 학습을 통해서 target task를 해결할 수 있는 구조
-
Take an image of an arbitrary size as input, and output a segmentation map of the corresponding size to the input
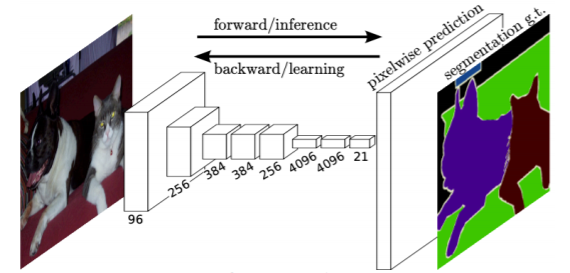
-
AlexNet의 경우는 convolution layer 뒤 쪽에 flattening 파트를 통해 벡터화를 시켜놓는데 이렇게 되면 입력 해상도가 호환되지 않으면 학습된 FC layer를 사용하지 못하는 한계가 있었다
- 왜냐하면 입력 해상도가 바뀌면 convolution layer의 activation map의 dimension이 달라지게 되고 그러면 flattening하면 벡터의 길이가 달라지기 때문에 fc layer하고 호환이 안되는 문제가 생긴다
-
FCN은 위와 같은 문제가 없는 네트워크 디자인이다
- 따라서 특정 해상도의 학습이 되었더라도 테스트 할때 임의의 사이즈의 영상을 입력으로 사용해도 문제없이 바로 작동하는 호환성이 높은 구조이다
-
Fully connected vs Fully convolutional
- Fully connected layer: Output a fixed dimensional vector and discard spatial coordinates
- image classification 마지막 단에 많이 사용되는 layer
- 공간정보를 고려하지 않고 fix dimensional 벡터가 주어지면 또다른 fix dimensional 벡터로 출력을 해주는 layer이다
- 즉 벡터가 주어지면 matrix가 multiplication되서 또다른 fix dimension의 벡터가 나오게 되는 layer이다
- Fully convolutional layer: Output a classification map which has spatial coordinates
- 입력도 activation map(tensor)이고 출력도 activation map 형태로 나온다
- 즉, spatial coordinate를 유지한 상태로 operation이 수행되는 layer이다
- 보통 1x1 convolution으로 구현이 된다
- 그래서 각 위치마다 classification 결과를 출력하는 map 형태로 출력이 정해지게 된다
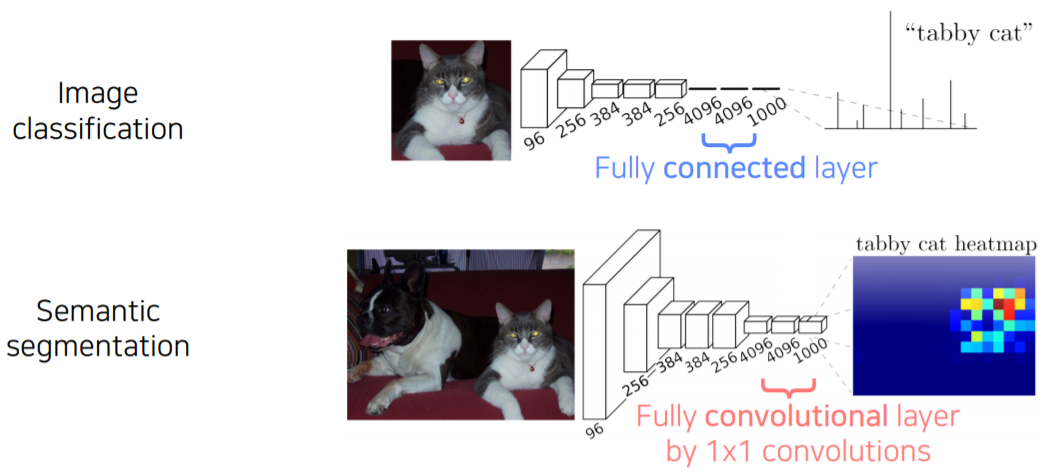
- 기존의 fc layer를 1x1 convolution 으로 구현을 하면 semantic segmentation 네트워크를 쉽게 구현 할 수 있다
- Fully connected layer: Output a fixed dimensional vector and discard spatial coordinates
-
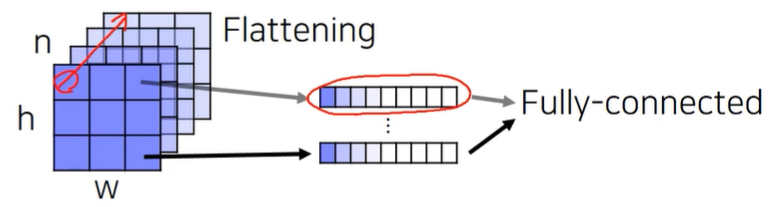
Interpreting fully connected layers as 1x1 convolutions
- A fully connected layer classifies a single feature vector
- 이전 layer에서 activation map이 출력이 되면 flattening을 통해서 긴 벡터 형태로 만들어 주고 fully connected layer의 입력으로 넣어준다
- 이렇게 만들면 영상의 공간정보를 고려하지 않고 하나의 벡터로 섞여 버린다
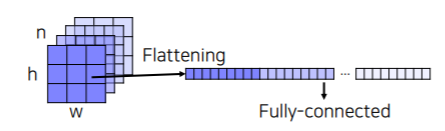
- 각 위치마다 classification을 할 수 있도록 고칠까?
- 각 위치마다 채널축으로 각각의 벡터를 쌓아서 flattening을 한다
- 이렇게 되면 각각에 대해서 입력으로 fully connected layer를 적용할 수 있다
- 1x1 convolution 이 이와 동일한 연산이다
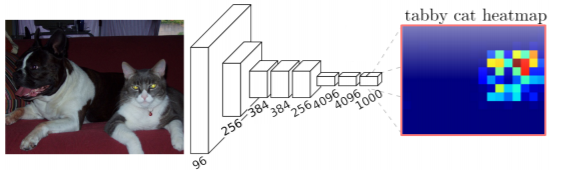
- A 1x1 convolution layer classifies every feature vector of the convolutional feature map
- 채널 축으로 1x1 convolution 커널이 fc layer의 한 weight 컬럼이라고 볼 수 있다
- 그래서 필터 갯수 만큼 통과를 시키면 각각 위치마다 fc layer를 별도로 돌려서 각각의 위치의 결과 값을 채워넣는것과 동일한 결과
- 1x1 convolution operation을 하기 위해선 sliding window 방식으로 weight 공유해서 적용하기 때문에 spatial information이 유지가 된다
- 결론적으로 fully connected layer는 1 x 1 convolutional 해석과 구현이 가능하므로 fc layer를 convolution layer로 대응함으로써 어떤 입력 사이즈도 대응 가능한 fully convolutional neural network를 만들 수 있다
- Limitation: Predicted score map is in a very low-resolution
- Why?
- For having a large receptive field, several spatial pooling layers are deployed
- stride 와 pooling layer로 인해서 최종 activation map의 해상도는 저해상도 인 경우가 많다
- Solution: Enlarge the score map by upsampling!
- A fully connected layer classifies a single feature vector
what is upsampling?
- 작은 activation map을 원래 입력사이즈에 맞춰주기 위해서 upsampling layer을 사용한다
- The size of the input image is reduced to a smaller feature map
- Upsample to the size of input image
- Upsampling is used to resize a small activation map to the size of the input image
- Unpooling
- Transposed convolution
- Upsample and convolution
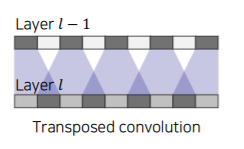
Transposed convolution
- Transposed convolutions work by swapping the forward and backward passes of convolution
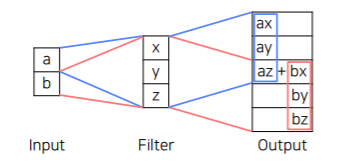
- a,b 두개의 입력이 주어졌을때 transposed convolution은 필터를 scaling한 것을 해당하는 출력위치에 붙여놓는다
Problems with transposed convolution
- Checker board artifacts due to uneven overlaps

- convolution kernel size 와 stride 사이즈 파라미터를 잘 조정해서 중첩이 생기지 않도록 신경써서 튜닝해야한다
Better approaches for upsampling
- Avoid overlap issues in transposed convolution
- Decompose into spatial upsampling and feature convolution
- {Nearest-neighbor(NN), Bilinear} interpolation followed by convolution

- {Nearest-neighbor(NN), Bilinear} interpolation followed by convolution
- transposed convolution은 학습 가능한 upsampling을 하나의 layer로 한방에 처리한것으로 볼 수 있다
- upsampling convolution 같은 경우는 upsampling operation을 두 개로 분리한 것이다
- 간단한 영상 처리 operation으로 많이 쓰이는 interpolation{Nearest-neighbor(NN), Bilinear} 들을 먼저 적용하고 학습 가능한 learnable upsampling 으로 만들어주기 위해서 convolution layer을 적용해준다
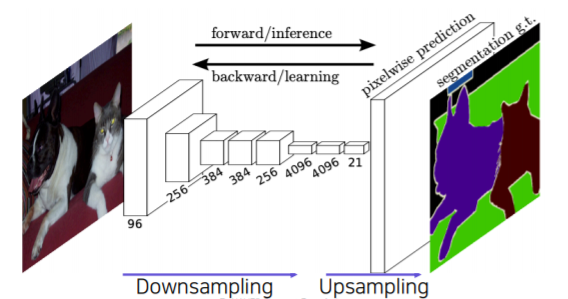
Back to FCN
-
아무리 upsampling을 했다해도 해상도가 이미 줄어든 상태에서 잃어버린 정보를 다시 살리는 일은 쉽지 않다
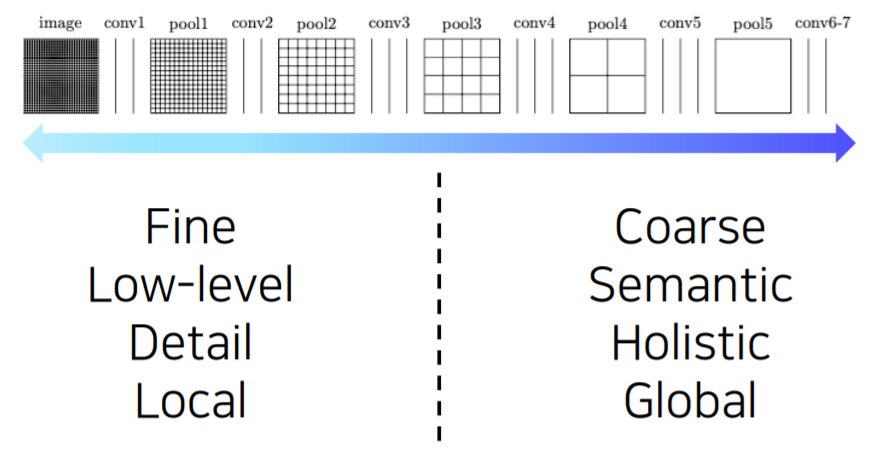
- 그래서 각 layer 별로 activation map에 해상도와 의미를 할펴보면 다음과 같은 경향성이 있다
- 낮은 layer 쪽에서는 receptive field size가 작기 때문에 굉장히 국지적이고 작은 디테일을 보고 작은 차이에도 민감한 경향이 있다
- 높은 layer 쪽에서는 해상도는 낮아지지만 큰 receptive field를 가지고 영상에서 전반이고 의미론적인 정보들을 포함하는 경향을 가지고 있다
- semantic segmentation에 필요한 건 사실 둘 모두 이다
- 왜냐하면 각 픽셀별로 의미를 파악하고 영상 전체를 바라보면서 현재 그 하나의 픽셀이 물체의 안쪽에 해당하는 또는 밖깥쪽에 해당하는지 판별을 해야한다
- 그래서 경계 부분을 디테일하게 파악해야하기 때문에 둘 모두가 다 필요하다
- 그래서 각 layer 별로 activation map에 해상도와 의미를 할펴보면 다음과 같은 경향성이 있다
-
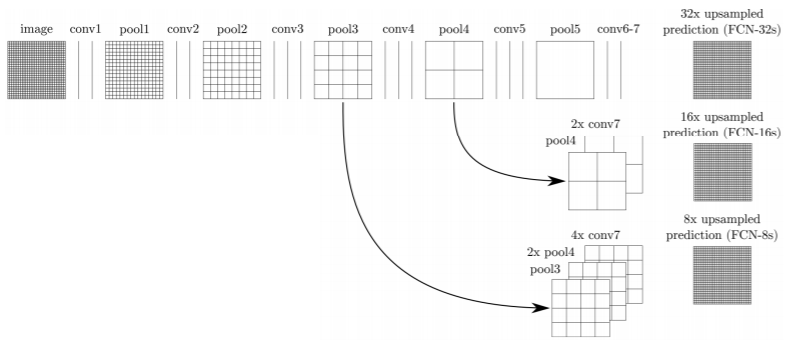
Adding skip connections for enlarging the score map
-
이 두 특징을 모두 확보하기 위해서 다음과 같이 fusion을 한다
- 높은 layer에 있던 activation map 을 upsampling을 통해서 해상도를 크게 올리고 그에 맞춰서 다른 중간층의 activation map을 upsampling을 해서 가져온다
- 이것을 concatenate을 해서 최종 출력을 만들게 된다
-
Integrates activations from lower layers into prediction
-
Preserves higher spatial resolution
-
Captures lower-level semantics at the same time
-
Features of FCN
- Faster
- The end-to-end architecture that does not depend on other hand-crafted components
- Accurate
- Feature representation and classifiers are jointly optimized
- Faster
-
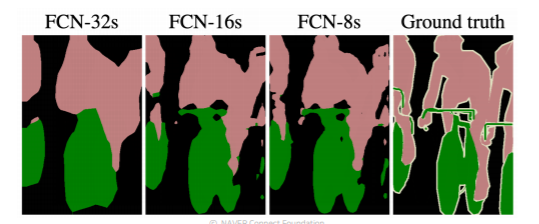
FCN-32s : 맨 마지막 activation map만 사용한 결과
-
FCN-16s : 적당히 다른 중간 단계의 activaton map과 합친 결과
-
FCN-8s : 좀 더 많이 다른 중간 단계의 activation map과 합친 결과
-
정리하면 FCN은 모두 neural network로 구성되어 있기에
- GPU로 병렬처리가 가능하고
- 또한 모델이 전반적으로 해당 task에 학습되기 때문에 더 좋은 성능을 발휘를 하고
- low level feature 와 high level feature 까지 고려한 end-to-end learning task를 통해서 경계선을 잘 따라가는 결과까지 얻을 수 있다
Hypercolumns for object segmentation
- 2015년에 거의 동시에 비슷한 연구가 나왔었다
- hypercolumn 이라는 논문도 FCN와 task, motivation 등 모두 동일한 연구이다
- 다만 강조하는 포인트가 FCN과는 달리 낮은 layer 높은 layer의 feature를 융합해서 쓰는 파트가 가장 강조되는 파트였다
- FCN은 1x1 convolution이랑 fully convolutional layer가 강조 되었다
- Fully convolutional networks
- CNN layers typically use the output of the last layer as feature representation
- Too coarse spatially
- Hypercolumn at a pixel is a stacked vector of all CNN units on that pixel
- FCN과 마찬가지로 낮은 layer와 높은 layer의 특징을 해상도를 맞춰놓고 합쳐서 사용하는 것을 제시
- Fine localized information is extracted from earlier layers
- Coarse semantic information is extracted from latter layers
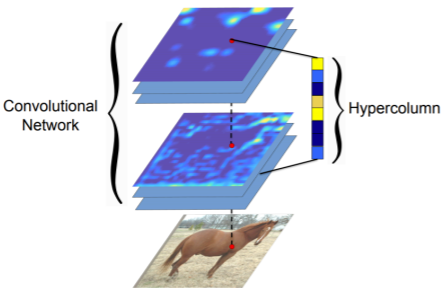
- CNN layers typically use the output of the last layer as feature representation
Hypercolumns' Overall architecture
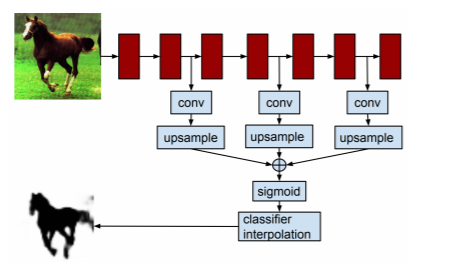
- (Concurrent work) Very similar to FCN
- Difference: Apply to each bounding box
U-Net
- semantic segmentation의 breakthrough는 U-Net에서부터 시작한다
- Built upon 'fully convolutional networks'
- share the same FCN property
- Predict a dense map by concatenating feature maps from contracting path
- similar to skip connections in FCN
- Yield more precise segmentations
- Overall architecture
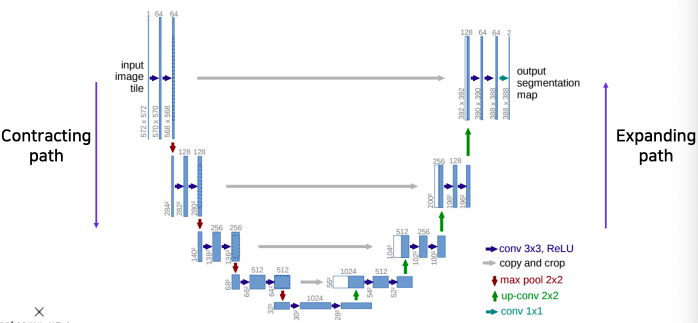
- Contracting path
- 먼저 입력 사진을 몇개의 convolution layer에 통과시키고 (Repeatedly applying 3x3 convolutions)
- pooling을 통해서 receptive field를 크게 확보하기 위해 해상도를 낮추고 채널 수를 늘린다(64 128) (Doubling the number of feature channels)
- 위 과정을 몇차례 반복해서 작은 activation map을 구하고 여기에 사진의 전반적인 정보가 잘 녹아있다라고 가정한다 (being used to capture holistic context)
- Expanding path (decoding이라 불리는 upsampling 부분)
- 한번에 upsampling하는 대신에 점진적으로 단계별로 activation map의 해상도를 올려주고 채널 수를 절반으로 줄인다 (Repeatedly appling 2x2 convolutions and Halving the number of feature channels)
- activation map의 해상도와 채널 수는 contracting path에서 대칭으로 대응되서 오는 layer와 동일하게 맞춰서 낮은 층에 있었던 activation map을 합쳐서 사용할 수 있도록 만들어 준다
- contracting path에서 부터 오는 대칭으로 대응되는 activation map을 concatenate을 통해서 합친다 (Concatenating the corresponding feature maps from the contracting path)
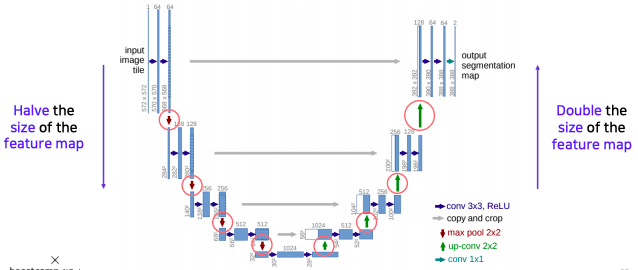
- activation map의 해상도는 contracting path 에서 절반씩 줄고
- 반대로 expanding path에서 두배씩 늘어난다
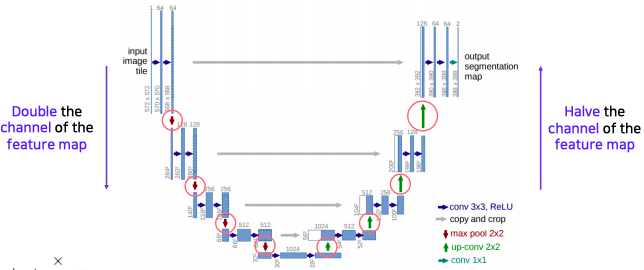
- 채널 수는 두배씩 늘어났다가 절반씩 줄어든다
- 대칭되는 layer들은 activation map들이 concatenate될수 있도록 해상도와 채널이 호환성있는 값을 가지도록 설계
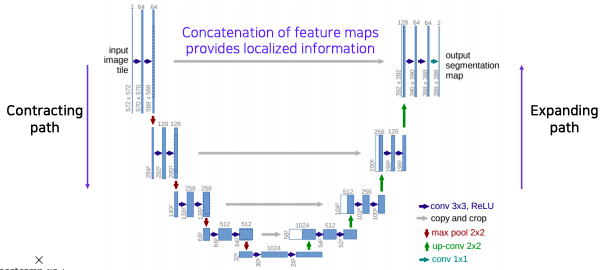
- 낮은 layer에서 전달되는 특징이 localized 정보를 준다
- 공간적으로 높은 해상도와 입력이 약간 바뀌는것 만으로 민감한 정보를 제공하기 때문에 경계선이나 공간적으로 중요한 정보들을 뒤쪽 layer에 바로 전달하는 중요한 역할을 한다
Precautions when using U-Net : What if the spatial size of the feature map is an odd number?
- 각 skip connection을 통해 contracting path의 activation map과 expanding path의 activation map이 concatenation이 되려면 해상도가 맞아야한다
- 하지만 U-Net에서는 downsampling과 upsampling이 굉장히 빈번하게 일어나는 구조이다
- 아래 두개의 예시가 있다
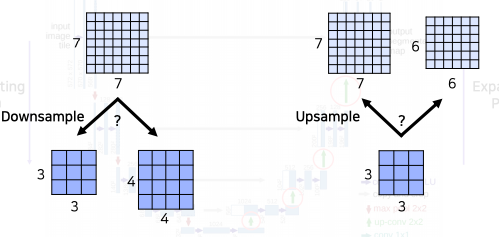
- 왼쪽:
- 7x7 의 feature map을 down sampling 하면 일반적으로 버림이 되서 3x3이 된다
- 오른쪽 :
- 3x3 된 feature map을 다시 두배로 upsampling하게 되면 6x6이 된다
- 원래 입력하고 해상도 차이가 나게된다
- 그렇게 때문에 입력 영상을 넣을때 중간에 어떤 layer에서도 홀수 해상도에 activation map이 나오지 않도록 유의해야한다
Pytorch code for U-Net
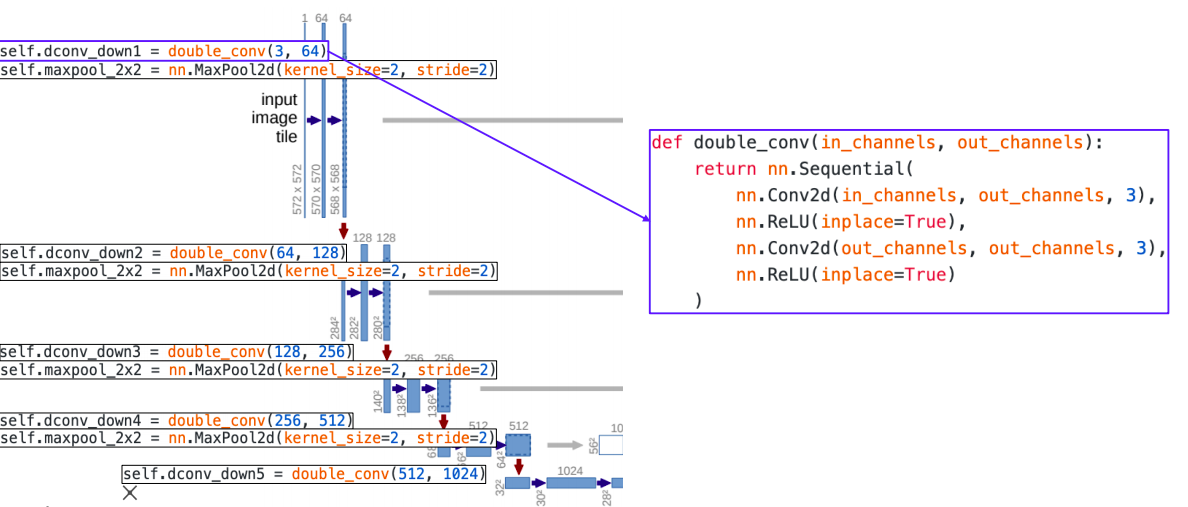
- double_conv는 convolution layer 두개 하고 사이에 relu activation function이 들어가서 두번 반복된 layer를 정의
- 각 contracting path에서는 double_conv 블록 한번과 그 끝에 max pooling을 통해 해상도를 줄이고 채널을 두배 늘린다
- 해상도를 줄일 수 있는 operation :
- max pooling을 통해서 해상도를 줄일 수 있고
- padding을 하지 않았다는 가정하에 convolution layer를 통과할때도 해상도가 줄어든다
- 채널 수 를 늘리는 operation :
- convolution 연산 중 채널 수를 늘려 연산을 해서 채널수를 늘린다
- 해상도를 줄일 수 있는 operation :
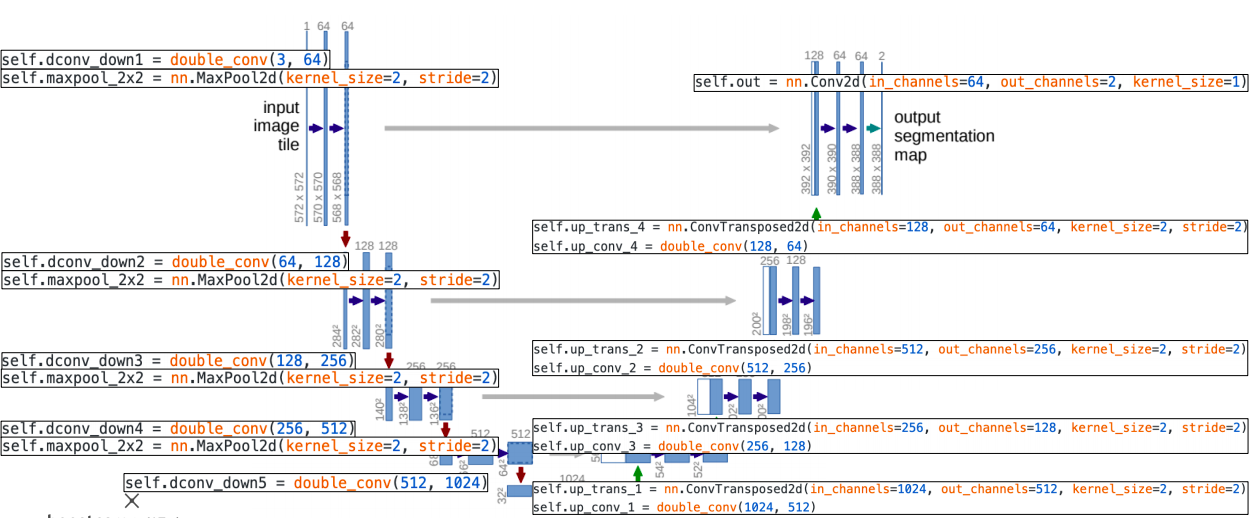
- upsampling을 위해서 transposed convolution이 사용된다(ConvTransposed)
- 하이퍼파라미터를 보면 stride와 kernel_size 가 모두 2 이다
- 그래서 두 칸씩 띄면서 두 칸씩 채워넣는 형태로 upsampling을 하게 된다
- 이렇게 하면 중첩되는 부분이 생기지 않는다
- kernel_size = 2 는 2x2 filter size를 의미한다
DeepLab
-
핵심 2가지
- CRF(conditional random field) 라는 후 처리에 존재
- dilated convolution(Atrous Convolution) 이라 불리는 convolution operation의 사용
-
Conditional Random Field (CRFs)
- 후처리에 사용되는 tool
- CRF post-processes a segmentation map to be refined to follow image boundaries
- 1st row : score map (before softmax) / 2nd row : belief map (after softmax)
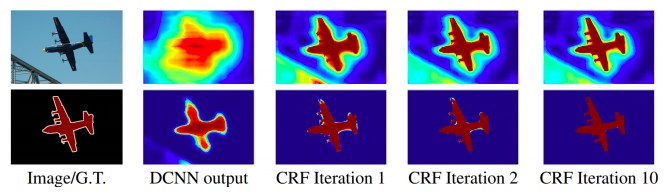
-
Dilated convolution (Atrous Convolution)
- convolution kernel 사이에 dilation factor 만큼 일정 공간을 넣어준다
- 아래 오른쪽 dilation convolution 같은 경우는 weight 사이를 한칸씩 띄어서 실제 convolution kernel 모다 더 넓은 영역을 고려할 수 있게 만들고
- 다만 파라미터 수는 늘어나지 않는다
- 그래서 단순하지만 dilation layer를 몇번 반복 하는 것 만으로 receptive field의 size가 exponential 하게 증가하는 효과를 얻을 수 있다
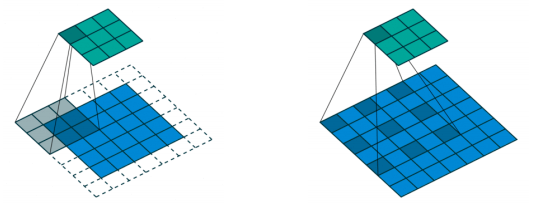
-
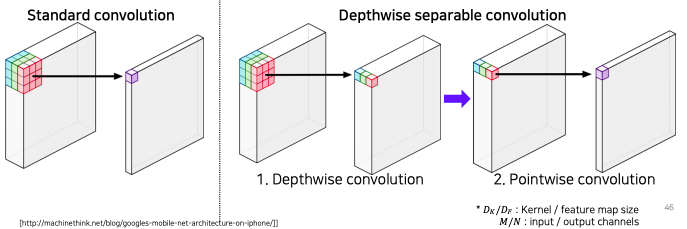
Depthwise separable convolution (proposed by Howard et al.)
- semantic segmentation의 입력 해상도 자체가 워낙 크기 때문에 연산이 오래 걸리는 것을 줄여보기 위해서 dilate convolution을 depthwise seperable convolution과 결합한 Atrous seperable convolution을 재현하여 사용
- 기존 convolution layer는 하나의 activation 값을 얻기 위해서 kernel 전체가 채널 전체에 걸쳐서 내적을 해서 하나의 값을 뽑는다
- depthwise convolution 은 이 절차를 둘로 나눈다
- 첫번째는 각 채널별로 convolution 해서 각 채널별로 activation map 값을 뽑고
- 뽑힌 activation map 값들을 pointwise convolution 즉, 1x1 convolution을 통해서 하나의 값의 출력이 되도록 합쳐준다
- 이렇게 두 개의 process 로 나누면 convolution의 표현력도 어느정도 유지가 되면서 계산량은 획기적으로 줄어든다
- number of parameters:
- Standard Convolution : (총 6승)
- Depthwise separable Convolution : (5승+4승)
- Depthwise separable Convolution이 order가 하나 작기 (5승 < 6승) 때문에 효율적인 계산량을 가진다
Deeplab v3+ 의 전체적인 구조
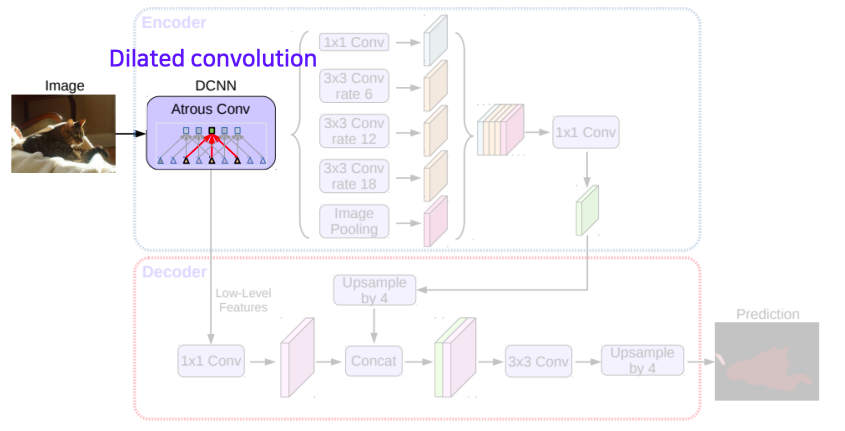
- dilated convolution layer를 통해서 더 큰 receptive field를 가지는 CNN을 적용해서 feature map을 구한다
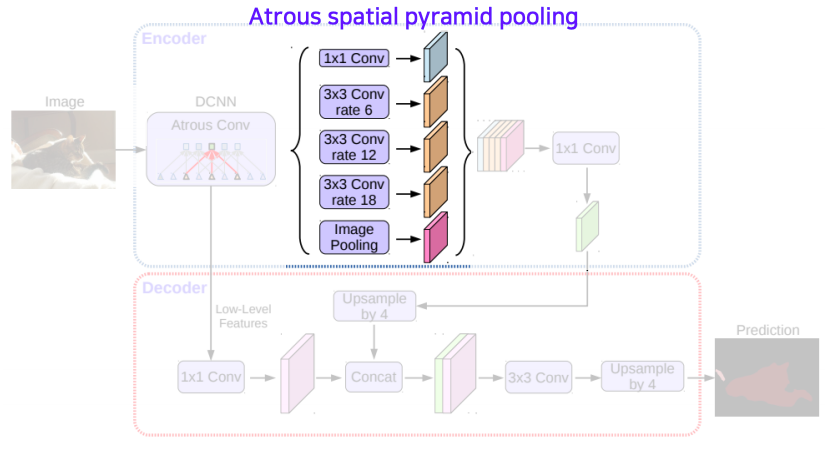
- 영역별로 연관된 주변 물체 또는 배경 정보의 거리가 모두 다르므로 다양한 rate의 dilated convolution을 통해서 multi scale 을 처리할 수 있는 spatial pyramid pooling을 구현
- 이렇게 구해진 feature map들은 하나로 concat 후에 convolution을 통해서 합쳐준다
- 각각의 영상 내에 들어있는 물체가 여러가지 scale을 가질수 있기 때문에 이런 것들을 종합적으로 고려하기 위한 spatial pyramid pooling 이다
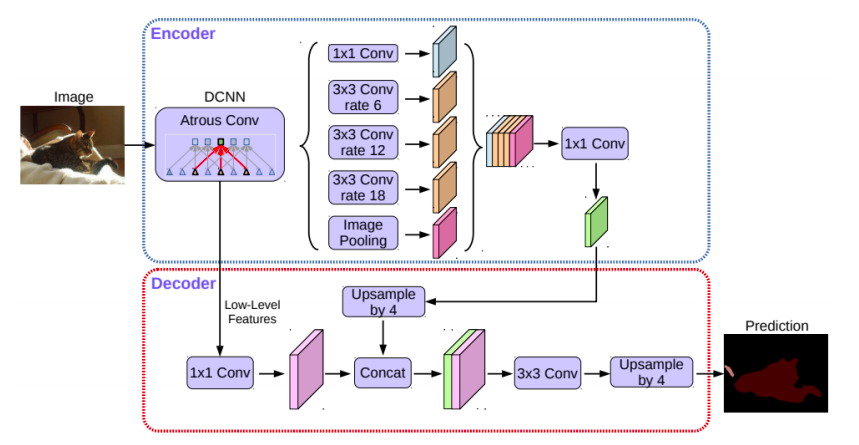
- decoder라고 불리는 stage에서 낮은 레벨에서 온 low level feature 하고 pyramid pooling을 거친 feature를 upsampling한 것과 concat을 통해서 결합해준다
- 이것을 upsampling을 통해서 segmentation map을 최종적으로 추출하는 구조이다
