그래프를 추천시스템에 어떻게 활용할까? (심화)
- 이번에는 잠재 인수 모형(Latent Factor Model)에 대해 배운다
- 혹시, "넷플릭스"를 사용해본적이 있는가? 사용해보았다면, 넷플릭스가 사용자에게 언제부터 어떻게 미디어 콘텐츠를 '잘' 추천할 수 있게 됐는지 궁금하지 않으가? 이번에는 이와 관련한 대회인 "넷플릭스 챌린지"에 대해 소개한다
- 또, 지난번에 배웠던 협업필터링의 방법 이외에 추천의 새로운 방법, 잠재 인수 모형을 활용한 추천 시스템에 대하여 소개한다
- 특정 차원에서 단어를 벡터 하나로 나타내는 것처럼, 추천시스템에서의 사용자와 아이템도 벡터 하나로 표현할 수 있을까?
- 또, 이 벡터를 어떻게 학습시킬까? 이에 대한 해답들을 배운다
Further Readings
Further Questions
- 추천시스템의 성능을 측정하는 metric이 RMSE라는 것은 예상 평점이 높은 상품과 낮은 상품에 동일한 페널티를 부여한다는 것을 뜻합니다. 하지만 실제로 추천시스템에서는 내가 좋아할 것 같은 상품을 추천해주는것, 즉 예상 평점이 높은 상품을 잘 맞추는것이 중요합니다. 이를 고려하여 성능을 측정하기 위해서는 어떻게 해야 할까요?
- 추천 시스템의 성능을 향상시키기 위해서는 어떠한 것을 더 고려할 수 있을까요?
- ans: Recall@k, Precisoin@k, MAP, MRR, NDCG 등의 랭킹 기반 메트릭을 활용
넷플릭스 챌린지 소개
넷플릭스 챌린지 데이터셋
- 넷플릭스 챌린지(Netflix Challenge)에서는 사용자별 영화 평점 데이터 가 사용되었다
- 훈련 데이터(Training Data) 는 2000년부터 2005년까지 수집한
48만명 사용자 의 1만 8천개의 영화 에 대한 1억 개의 평점 으로 구성되어 있다 - 평가 데이터(Test Data) 는 각 사용자의 최신 평점 280만개 로 구성되어 있다
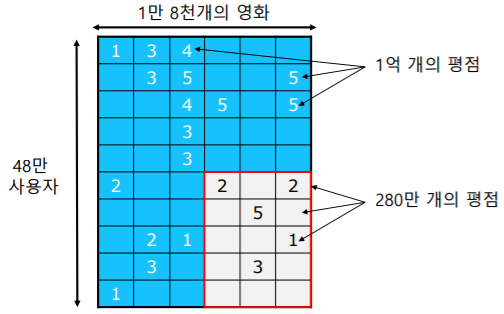
- 훈련 데이터(Training Data) 는 2000년부터 2005년까지 수집한
넷플릭스 챌린지 대회 소개
- 넷플릭스 챌린지의 목표는 추천시스템의 성능을 10%이상 향상시키는 것이었다
- 평균 제곱근 오차 0.9514 을 0.8563 까지 낮출 경우 100만불의 상금을 받는 조건이었다
- 2006년부터 2009년까지 진행되었으며, 2700개의 팀이 참여하였다
- 넷플릭스 챌린지를 통해 추천시스템의 성능이 비약적으로 발전했다

잠재 인수 모형
잠재 인수 모형 개요
- 잠재 인수 모형(Latent Factor Model, uv decomposition) 의 핵심은 사용자와 상품을 벡터로 표현 하는 것이다
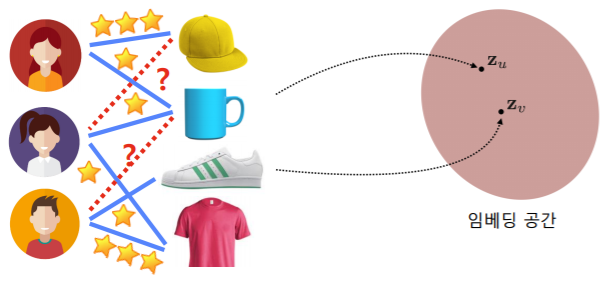
- 사용자와 영화를 임베딩 한 예시:
- 잠재 인수 모형에서는 고정된 인수 대신 효과적인 인수를 학습 하는 것을 목표로 한다
- 즉, 추천을 가장 정확하게 할 수 있는 차원을 찾아서 그 차원으로 구성된 embedding 공간에 영화와 사람들을 배치한다
- 학습한 인수를 잠재 인수(latent factor, embedding 공간의 축) 라 부른다
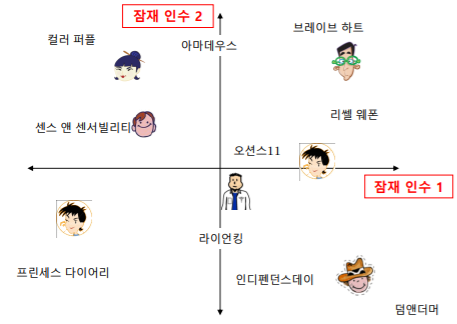
- 잠재 인수 모형에서는 고정된 인수 대신 효과적인 인수를 학습 하는 것을 목표로 한다
손실 함수
-
사용자와 상품을 임베딩하는 기준은 무엇인가?
- 사용자와 상품의 임베딩의 내적(Inner Product)이 평점과 최대한 유사 하도록 하는 것이다
- 사용자 의 임베딩을 (벡터표현), 상품 의 임베딩을 (벡터표현) 라고 하자
- 사용자 의 상품 에 대한 평점을 라고 하자
- 임베딩의 목표는 이 와 유사하도록 하는 것이다
-
행렬 차원에서 살펴보자
- 사용자 수의 열과 상품 수의 행을 가진 평점 행렬을 이라고 하자
- 사용자들의 임베딩, 즉 벡터를 쌓아서 만든 사용자 행렬을 라고 하자
- 영화들의 임베딩, 즉 벡터를 쌓아서 만든 상품 행렬을 라고 하자
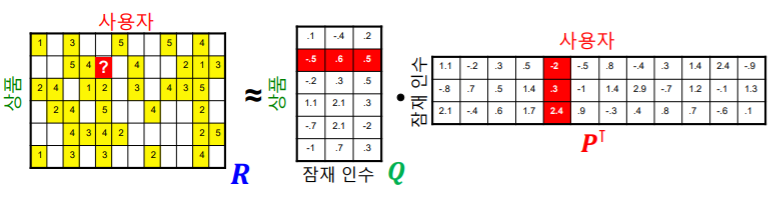
-
잠재 인수 모형은 다음 손실 함수를 최소화하는 와 를 찾는 것을 목표로한다

- 하지만, 위 손실 함수를 사용할 경우 과적합(Overfitting) 이 발생할 수 있다
- 과적합 이란 기계학습 모형이 훈련 데이터의 잡음(Noise)까지 학습하여, 평가 성능은 오히려 감소하는 현상을 의미한다
- 하지만, 위 손실 함수를 사용할 경우 과적합(Overfitting) 이 발생할 수 있다
-
과적합을 방지하기 위하여 정규화 항을 손실 함수에 더해준다

- L2 regularization을 사용한다
- 단순히 오차부분만 최소화 하는 것이 아니라 모형 복잡도도 함께 최소화 한다
- 목형 복잡도를 최소한 한다는것은 와 가 너무 큰 값을 가지지 않는다는 것을 의미한다
- 따라서 전체 loss 함수는 오차도 줄이면서 너무 복잡하지 않은 embedding들을 배우게 된다
- 왜 이 embedding 들이 너무 큰 것을 방지 하는 것 일까?
- embedding 들이 너무 크면 훈련 데이터에 있는 잡음들까지 배울 수 있다
- 하지만 잡음을 배우는것은 새로운 상품과 사용자 쌍에 대하여 예측할 때 아무런 도움이 되지 않는다
- 잡음은 배우지 않고 가장 중요한 부분을 배우도록 와 를 작게끔 만드는 것이다
- 오차와 모형복잡도라는 두 가지를 동시에 최소화 해야하는데 이 과정에서 둘 중에 어느 목표가 얼만큼 더 중요한지를 지정해주는 것이 정규화의 세기(하이퍼파라미터) 이다
- 이 값이 크면 클 수록 모형 복잡도에 더 집중해서 최소화 하는것이고
- 이 값이 작으면 오차에 더 집중해서 최소화 하는것이다
-
정규화는 극단적인, 즉 절댓값이 너무 큰 임베딩을 방지하는 효과가 있다
- 어떤 사용자가 우/하단에 있는 영화를 재밌게 봤다고 해서 이사람이 무조건 '우/하단에 있는 영화만 좋아한다' 라고 판단하는 것이 아니라 '우/하단에 있는 영화를 좋아하는 경향이 있다' 라는 조금 더 보수적이고 신중하게 만드는 효과가 있다
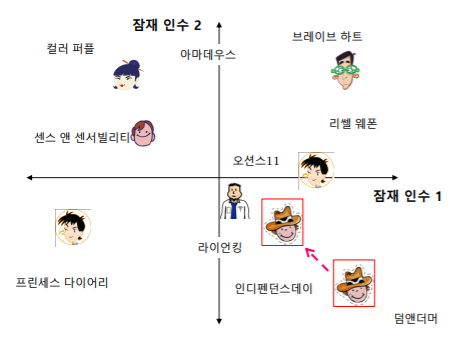
- 어떤 사용자가 우/하단에 있는 영화를 재밌게 봤다고 해서 이사람이 무조건 '우/하단에 있는 영화만 좋아한다' 라고 판단하는 것이 아니라 '우/하단에 있는 영화를 좋아하는 경향이 있다' 라는 조금 더 보수적이고 신중하게 만드는 효과가 있다
최적화
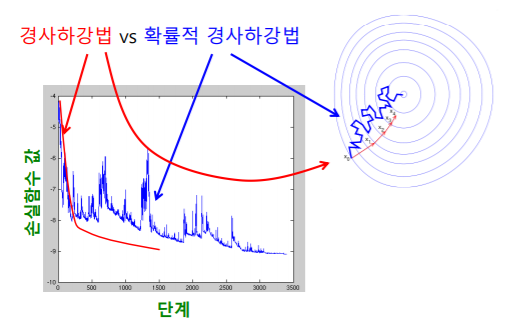
- 손실함수를 최소화하는 와 를 찾기 위해서는 (확률적) 경사하강법을 사용한다
- 경사하강법 은 손실함수를 안정적으로 하지만 느리게 감소시킨다
- 확률적 경사하강법 은 손실함수를 불안정하지만 빠르게 감소시킨다
- 실제로는 확률적 경사하강법 이 더 많이 사용된다
고급 잠재 인수 모형
사용자와 상품의 편향을 고려한 잠재 인수 모형
-
각 사용자의 편향 은 해당 사용자의 평점 평균과 전체 평점 평균의 차 이다
- 나연 이 매긴 평점의 평균이 4.0 개의 별, 다현 이 매긴 평점의 평균이 3.5 개의 별이라고 하자
- 전체 평점 평균 이 3.7 개의 별인 경우, 나연 의 사용자 편향은 4.0 - 3.7 = 0.3 개의 별이다
- 다현 의 사용자 편향은 3.5 - 3.7 = -0.2 개의 별이다
- 즉 나연 은 평균보다 0.3 만큼의 점수를 더 주는 편향이 있고 다현 은 평균보다 -0.2 만큼 더 깐깐하게 점수를 주는 편향이 있다
-
각 상품의 편향 은 해당 상품에 대한 평점 평균과 전체 평점 평균의 차 이다
- 영화 식스센스 에 대한 평점의 평균이 4.5 개의 별, 영화 클레멘타인 이 매긴 평점의 평균이 3.0 개의 별이라고 하자
- 전체 평점 평균이 3.7 개의 별인 경우, 식스센스 의 상품 편향은 4.5 – 3.7 = 0.8 개의 별이다
- 클레멘타인 의 상품 편향은 3.0 - 3.7 = -0.7 개의 별이다
- 즉, 식스센스 는 평균에 비해서 0.8정도 더 긍정적인 평가를 받고 있고 클레멘타인 은 평균에 비해 -0.7 만큼 좀 더 부정적인 평가를 받고 있다
-
개선된 잠재 인수 모형에서는 평점을 전체 평균, 사용자 편향, 상품 편향, 상호작용 으로 분리한다
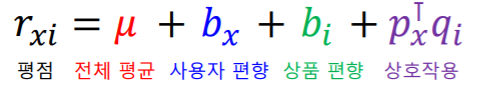
- 즉 전에는 와 의 내적을 통해 평점 자체를 예측할려 했다면
- 지금은 실제 평점에서 전체 평균, 사용자 편향, 상품 편향을 뺀 값을 내적을 통해서 근사하는 것이다
- 즉 전에는 와 의 내적을 통해 평점 자체를 예측할려 했다면

- 개선된 잠재 인수 모형의 손실 함수는 아래와 같다
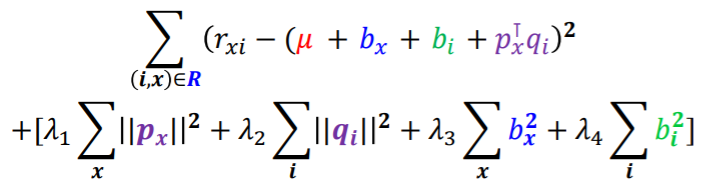
- 전에는 와 만 학습을 했는데 이제는 사용자 편향 , 상품 편향 도 함께 학습한다
- 전체 평균 는 학습하지 않고 그대로 사용한다
- 마찬가지로 overfitting이 발생할 수 있기 때문에 이것을 방지하기 위해서 정규화 즉, regularization term 을 사용한다
- (확률적) 경사하강법을 통해 손실 함수를 최소화하는 잠재 인수와 편향을 찾아낸다
시간적 편향을 고려한 잠재 인수 모형
-
넷플릭스 시스템의 변화로 평균 평점이 크게 상승하는 사건이 있었다
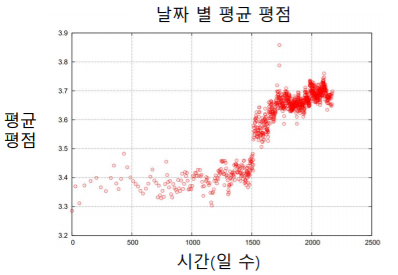
-
영화의 평점은 출시일 이후 시간이 지남에 따라 상승하는 경향을 갖는다
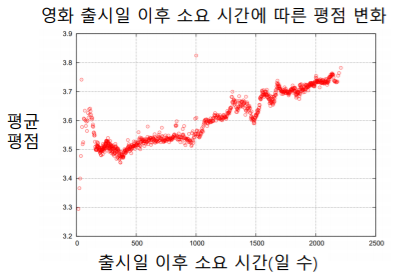
-
개선된 잠재 인수 모형에서는 이러한 시간적 편향을 고려한다
- 구체적으로 사용자 편향과 상품 편향을 시간에 따라 별화할 수 있는 함수로 가정한다


- 구체적으로 사용자 편향과 상품 편향을 시간에 따라 별화할 수 있는 함수로 가정한다

아기개발자