Numpy Tutorial
- 기본적인 Numpy와 matplotlib 사용 방법 정리
import numpy as np
import timeNumpy 속도 테스트
#test speed
def sum_trad():
start = time.time()
X = range(10000000)
Y = range(10000000)
Z = []
for i in range(len(X)):
Z.append(X[i] + Y[i])
return time.time() - start
def sum_numpy():
start = time.time()
X = np.arange(10000000)
Y = np.arange(10000000)
Z=X+Y
return time.time() - start
print ('time sum:',sum_trad(),' time sum numpy:',sum_numpy())#time sum: 1.3253865242004395 time sum numpy: 0.051636457443237305배열 생성
단일 값으로 초기화
# 단일 값으로 초기화된 배열 생성
print(np.full((3, 3), np.inf)) # 무한대를 표현 inf # 정의할수 없는값 nan
print(np.full((3, 3), 10.1))#[[inf inf inf]
# [inf inf inf]
# [inf inf inf]]
#[[10.1 10.1 10.1]
# [10.1 10.1 10.1]
# [10.1 10.1 10.1]]# 배열을 단일 값으로 리셋
arr = np.array([10, 20, 33], float)
print (arr)
print(type(arr)) # np.array
arr.fill(1)
print (arr)#[10. 20. 33.]
#<class 'numpy.ndarray'>
#[1. 1. 1.]랜덤 초기화
# 정수 순열로 초기화된 배열 생성
np.random.permutation(3)
#array([2, 1, 0])# 정규분포로 초기화된 배열 생성
np.random.normal(0,1,5)#array([-0.85362686, -0.07827693, -0.62510155, 0.80359386, -0.95164451])np.random.normal(1,2,10)#array([ 0.89500157, -1.92581063, 3.41644854, 1.73970517, 1.98061209,
# -0.89138701, 1.49300214, -0.11260654, 3.91243981, 2.04128031])# 균등분포로 초기화된 배열 생성
np.random.random(5)#array([0.08184007, 0.82280428, 0.93406556, 0.74876079, 0.55021497])리스트에서 생성
#리스트에서 배열 생성
arr = np.array([2, 6, 5, 9], float)
print (arr)
print (type(arr))#[2. 6. 5. 9.]
#<class 'numpy.ndarray'># 배열에서 리스트로 변환
arr = np.array([1, 2, 3], float)
print (arr.tolist())
print (list(arr))#[1.0, 2.0, 3.0]
#[1.0, 2.0, 3.0]배열 복사
arr = np.array([1, 2, 3], float)
arr1 = arr
arr2 = arr.copy()
arr[0] = 0
print (arr)
print (arr1)
print (arr2)#[0. 2. 3.]
#[0. 2. 3.]
#[1. 2. 3.]단위 행렬
#단위 행렬 생성
print (np.identity(3, dtype=int))
print (np.identity(3))#[[1 0 0]
# [0 1 0]
# [0 0 1]]
#[[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]대각 행렬
#대각 행렬 생성
np.eye(3, k=1, dtype=float)#array([[0., 1., 0.],
# [0., 0., 1.],
# [0., 0., 0.]])영행렬, 1행렬
print (np.zeros(6, dtype=int))
print (np.ones((2,3), dtype=float))#[0 0 0 0 0 0]
#[[1. 1. 1.]
# [1. 1. 1.]]# 주어진 배열과 동일한 차원의 영행렬, 1행렬 생성
arr = np.array([[13, 32, 31], [64, 25, 76]], float)
print(np.zeros_like(arr))
print(np.ones_like(arr))#[[0. 0. 0.]
# [0. 0. 0.]]
#[[1. 1. 1.]
# [1. 1. 1.]]배열 쌓기
x = np.array([2, 3, 4])
y = np.array([3, 4, 5])
print(np.stack((x, y)))
print(np.stack((x, y), axis=-1))
#[[2 3 4]
# [3 4 5]]
#[[2 3]
# [3 4]
# [4 5]]2차원 배열 랜덤 초기화
# 균등분포로 초기화된 2차원 배열 생성
print (np.random.rand(2,3))#[[0.07004629 0.97618379 0.86485161]
# [0.27877679 0.23349779 0.39866576]]배열 관리
배열 읽기/쓰기
arr = np.array([2., 6., 5., 5.])
print(arr[:3])
print(arr[3])
arr[0] = 5.
print(arr)#[2. 6. 5.]
#5.0
#[5. 6. 5. 5.]중복 제거
arr = np.array([2., 6., 5., 5.])
print(np.unique(arr))#[2. 5. 6.]정렬/섞기
# 정렬
print(np.sort(arr))
# 정렬해서 인덱스 배열 생성
print(np.argsort(arr))
# 랜덤하게 섞기
np.random.shuffle(arr)
print(arr)
# 배열 비교
print(np.array_equal(arr,np.array([1,3,2])))
print(np.array_equal(arr,arr))#[2. 5. 5. 6.]
#[0 2 3 1]
#[5. 6. 2. 5.]
#False
#True배열 슬라이싱
# 슬라이싱
matrix = np.array([[ 4., 5., 6.], [2, 3, 6]], float)
# print(matrix)
arr = np.array([
[ 4., 5., 6.],
[ 2., 3., 6.]
], float)
print(arr)
print(arr[0:2, 0])
print(arr[1,:])
print(arr[:,2])
print(arr[-1:,-2:])#[[4. 5. 6.]
# [2. 3. 6.]]
#[4. 2.]1차원 배열로 펴기
# Flattening
arr = np.array([[10, 29, 23], [24, 25, 46]], float)
print(arr)
print(arr.flatten())[[10. 29. 23.]
[24. 25. 46.]]
[10. 29. 23. 24. 25. 46.]배열의 크기와 데이터 타입
# 배열의 모양 확인
print(arr.shape)
# 데이터 타입 확인
print(arr.dtype)
# 데이터 타입 변환
int_arr = matrix.astype(np.int32)
print(int_arr)#(2, 3)
#float64
#[[4 5 6]
# [2 3 6]]# 1차원의 길이
arr = np.array([
[ 4., 5., 6.],
[ 2., 3., 6.]
], float)
print(len(arr))
print(arr.shape)
print(arr.shape[0])#2
#(2, 3)
#2재배열 reshape
# 배열의 재배열
arr = np.array(range(8), float)
print(arr)
arr = arr.reshape((4,2))
print(arr)
print(arr.shape)
#[0. 1. 2. 3. 4. 5. 6. 7.]
#[[0. 1.]
# [2. 3.]
# [4. 5.]
# [6. 7.]]
#(4, 2)전치 행렬
arr = np.array(range(6), float).reshape((2, 3))
print(arr)
print(arr.transpose())#[[0. 1. 2.]
# [3. 4. 5.]]
#[[0. 3.]
# [1. 4.]
# [2. 5.]]# 행렬의 T 속성으로 전치하기
matrix = np.arange(15).reshape((3, 5))
print(matrix)
print(matrix .T)#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]]
#[[ 0 5 10]
# [ 1 6 11]
# [ 2 7 12]
# [ 3 8 13]
# [ 4 9 14]]차원 늘리기
# newaxis로 차원 늘리기
arr = np.array([14, 32, 13], float)
print(arr)
print(arr[:,np.newaxis])
print(arr[:,np.newaxis].shape)
print(arr[np.newaxis,:])
print(arr[np.newaxis,:].shape)#[14. 32. 13.]
#[[14.]
# [32.]
# [13.]]
#(3, 1)
#[[14. 32. 13.]]
#(1, 3)배열 결합
arr1 = np.array([[11, 12], [32, 42]], float)
arr2 = np.array([[54, 26], [27, 28]], float)
print(np.concatenate((arr1,arr2)))
# 1차원 방향으로 결합
print(np.concatenate((arr1,arr2), axis=0))
# 2차원 방향으로 결합
print(np.concatenate((arr1,arr2), axis=1))#[[11. 12.]
# [32. 42.]
# [54. 26.]
# [27. 28.]]
#[[11. 12.]
# [32. 42.]
# [54. 26.]
# [27. 28.]]
#[[11. 12. 54. 26.]
# [32. 42. 27. 28.]]배열 연산
산술연산
#array operations
arr1 = np.array([1,2,3], float)
arr2 = np.array([1,2,3], float)
print(arr1+arr2)
print(arr1-arr2)
print(arr1 * arr2)
print(arr2 / arr1)
print(arr1 % arr2)
print(arr2**arr1)#[2. 4. 6.]
#[0. 0. 0.]
#[1. 4. 9.]
#[1. 1. 1.]
#[0. 0. 0.]
#[ 1. 4. 27.]브로드캐스팅
arr1 = np.zeros((2,2), float)
arr2 = np.array([1., 2.], float)
print(arr1)
print(arr2)
print(arr1 + arr2)#[[0. 0.]
# [0. 0.]]
#[1. 2.]
#[[1. 2.]
# [1. 2.]]# 인덱스 배열로 쿼리
arr1 = np.zeros((2,2), float)
arr2 = np.array([1., 2.], float)
print( arr1 + arr2[np.newaxis,:])
print(arr1 + arr2[:,np.newaxis])#[[1. 2.]
# [1. 2.]]
#[[1. 1.]
#[2. 2.]]배열 쿼리
# 인덱스 배열로 쿼리
arr1 = np.array([1, 4, 5, 9], float)
arr2 = np.array([0, 1, 1, 3, 1, 1, 1], int)
print(arr1[arr2])# [1. 4. 4. 9. 4. 4. 4.]# 다차원 배열 인덱스 배열로 쿼리
arr1 = np.array([[1, 2], [5, 13]], float)
arr2 = np.array([1, 0, 0, 1], int)
arr3 = np.array([1, 1, 0, 1], int)
arr1[arr2,arr3]# array([13., 2., 1., 13.])# take 함수로 쿼리
arr1 = np.array([7, 6, 6, 9], float)
arr2 = np.array([1, 0, 1, 3, 3, 1], int)
arr1.take(arr2)# array([6., 7., 6., 9., 9., 6.])# 차원에 따라 부분집합 선택
arr1 = np.array([[10, 21], [62, 33]], float)
arr2 = np.array([0, 0, 1], int)
# 1차원 방향으로 선택
print(arr1.take(arr2, axis=0))
# 2차원 방향으로 선택
print(arr1.take(arr2, axis=1))#[10. 21.]
#[10. 21.]
# [62. 33.]]
#[[10. 10. 21.]
# [62. 62. 33.]]배열 수정 쿼리
# 인덱스 배열로 쿼리
arr1 = np.zeros((2,2), float)
arr2 = np.array([1., 2.], float)
print(arr1)
print(arr2)
print(arr1 + arr2)
print(arr1 + arr2[np.newaxis,:])
print(arr1 + arr2[:,np.newaxis])#[[0. 0.]
# [0. 0.]]
#[1. 2.]
#[[1. 2.]
# [1. 2.]]
#[[1. 2.]
# [1. 2.]]
#[[1. 1.]
# [2. 2.]]선형대수 연산
행렬곱
#linear algebra operations
X = np.arange(15).reshape((3, 5))
print(X)
print(X.T)
print(np.dot(X.T, X))#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]]
#[[ 0 5 10]
# [ 1 6 11]
# [ 2 7 12]
# [ 3 8 13]
# [ 4 9 14]]
#[[125 140 155 170 185]
# [140 158 176 194 212]
# [155 176 197 218 239]
# [170 194 218 242 266]
# [185 212 239 266 293]]벡터의 외적, 내적, 벡터곱
arr1 = np.array([12, 43, 10], float)
arr2 = np.array([21, 42, 14], float)
print(np.outer(arr1, arr2))
print(np.inner(arr1, arr2))
print(np.cross(arr1, arr2))#[[ 252. 504. 168.]
# [ 903. 1806. 602.]
# [ 210. 420. 140.]]
#2198.0
#[ 182. 42. -399.]행렬식, 역행렬
# 행렬식
matrix = np.array([[74, 22, 10], [92, 31, 17], [21, 22, 12]], float)
print(matrix)
print(np.linalg.det(matrix))
# 역행렬
inv_matrix = np.linalg.inv(matrix)
print(inv_matrix)
print(np.dot(inv_matrix,matrix))
# 고윳값, 고유벡터
vals, vecs = np.linalg.eig(matrix)
print(vals)
print(vecs)#[[74. 22. 10.]
# [92. 31. 17.]
# [21. 22. 12.]]
#-2852.000000000003
#[[ 0.00070126 0.01542777 -0.02244039]
#[ 0.26192146 -0.23772791 0.11851332]
# [-0.48141655 0.4088359 -0.09467041]]
#[[ 1.00000000e+00 1.52655666e-16 2.77555756e-17]
# [-2.05391260e-15 1.00000000e+00 -2.22044605e-16]
# [-6.80011603e-16 9.15933995e-16 1.00000000e+00]]
#[107.99587441 11.33411853 -2.32999294]
#[[-0.57891525 -0.21517959 0.06319955]
# [-0.75804695 0.17632618 -0.58635713]
# [-0.30036971 0.96052424 0.80758352]]통계 함수
arr = np.random.rand(8, 4)
print(arr.mean())
print(np.mean(arr))
print(arr.sum())#0.5893505981525243
#0.5893505981525243
#18.85921914088078Matplotlib Tutorial
import matplotlib.pyplot as plt기본 그래프
# Plot 함수의 리스트가 1개면 y 값으로 간주
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
plt.show()
# Plot 함수의 리스트가 2개면 x값과 y값으로 간주
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
# 가로 세로 축 범위
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro')
plt.axis([0, 6, 0, 20])
plt.show()
스타일 추가
import numpy as np
# evenly sampled time at 200ms intervals
t = np.arange(0., 5., 0.2)
# red dashes, blue squares and green triangles
plt.plot(t, t, 'r--', t, t**2, 'gs', t, t**3, 'b^')
plt.show()
Plotting with keyword strings
data = {'a': np.arange(50),
'c': np.random.randint(0, 50, 50),
'd': np.random.randn(50)}
data['b'] = data['a'] + 10 * np.random.randn(50)
data['d'] = np.abs(data['d']) * 100
plt.scatter('a', 'b', c='c', s='d', data=data)
plt.xlabel('entry a')
plt.ylabel('entry b')
plt.show()
Plotting with categorical variables
names = ['group_a', 'group_b', 'group_c']
values = [1, 10, 100]
plt.figure(figsize=(9, 3))
plt.subplot(131)
plt.bar(names, values)
plt.subplot(132)
plt.scatter(names, values)
plt.subplot(133)
plt.plot(names, values)
plt.suptitle('Categorical Plotting')
plt.show()
Working with multiple figures and axes
def f(t):
return np.exp(-t) * np.cos(2*np.pi*t)
t1 = np.arange(0.0, 5.0, 0.1)
t2 = np.arange(0.0, 5.0, 0.02)
plt.figure()
plt.subplot(211)
plt.plot(t1, f(t1), 'bo', t2, f(t2), 'k')
plt.subplot(212)
plt.plot(t2, np.cos(2*np.pi*t2), 'r--')
plt.show()
분포
mu, sigma = 100, 15
x = mu + sigma * np.random.randn(10000)
# the histogram of the data
n, bins, patches = plt.hist(x, 50, density=1, facecolor='g', alpha=0.75)
plt.xlabel('Smarts')
plt.ylabel('Probability')
plt.title('Histogram of IQ')
plt.text(60, .025, r'$\mu=100,\ \sigma=15$')
plt.axis([40, 160, 0, 0.03])
plt.grid(True)
plt.show()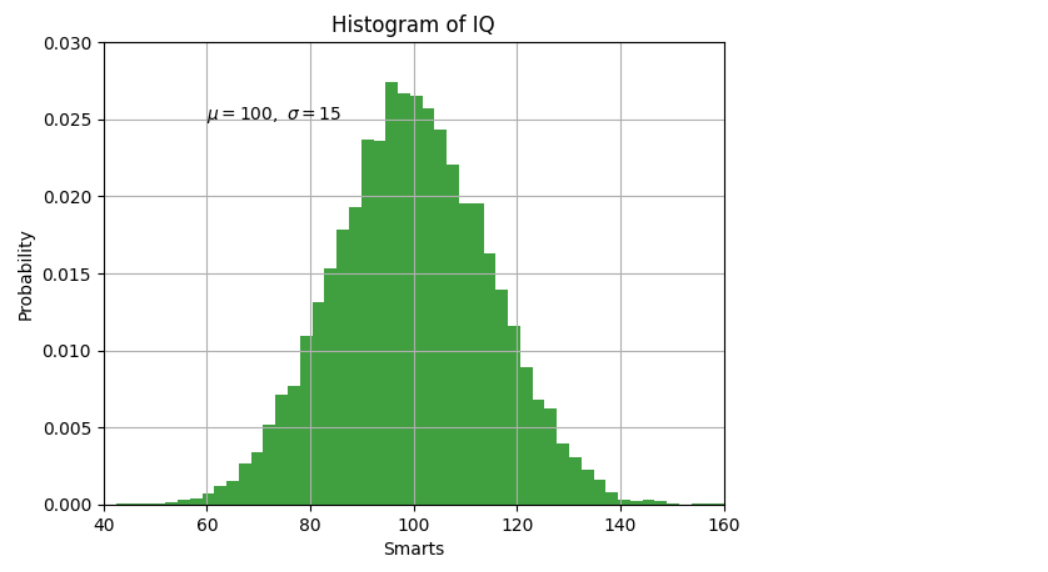
Annotation
ax = plt.subplot(111)
t = np.arange(0.0, 5.0, 0.01)
s = np.cos(2*np.pi*t)
line, = plt.plot(t, s, lw=2)
plt.annotate('local max', xy=(2, 1), xytext=(3, 1.5),
arrowprops=dict(facecolor='black', shrink=0.05),
)
plt.ylim(-2, 2)
plt.show()

AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms