Pandas는 무엇인가요?
- 데이터 분석 및 가공에 사용되는 파이썬 라이브러리입니다
from google.colab import drive
drive.mount('/content/drive')Mounted at /content/driveimport pandas as pd
data_frame = pd.read_csv('/content/drive/MyDrive/Lecture/삼성 디스플레이/1주차/1_python_basic_examples/data/friend_list.csv')
data_frame.head()
데이터프레임은 무엇인가요?
- 가로축과 세로축이 있는 엑셀과 유사한 데이터구조입니다. 가로축은 로우(행), 세로축은 컬럼(열)이라고 합니다.
# 데이터프레임이 가지고 있는 함수의 예제입니다.
data_frame.head()
시리즈는 무엇인가요?
- 데이터프레임의 컬럼(행)은 모두 시리즈입니다. 위의 예제는 3개의 시리즈로 구성된 데이터프레임입니다.
type(data_frame.job)# pandas.core.series.Series# 시리즈의 함수 예제입니다.
data_frame.job = data_frame.job.str.upper()
data_frame.head()
- 시리즈는 단순히 파이썬 리스트를 간직한 오브젝트입니다.
- 리스트를 파라미터로 주면 바로 시리즈가 생성됩니다.
- 시리즈는 데이터 가공 및 분석이 파이썬 리스트보다 훨씬 쉽습니다.
s1 = pd.core.series.Series(['one', 'two', 'three'])
s2 = pd.core.series.Series([1, 2, 3])pd.DataFrame(data=dict(word=s1, num=s2)
왜 Pandas를 쓰나요?
- 엑셀과 상당히 유사합니다, 데이터의 수정/가공 및 분석이 용이합니다.
- 데이터 가공을 위한 수많은 함수를 지원합니다.
- Numpy 기반으로 데이터 처리가 상당히 빠릅니다.
파일을 데이터프레임으로 불러오기
- 데이터프레임 (dataframe)은 2차원 자료구조입니다. 로우와 컬럼으로 엑셀 형식과 유사합니다.
- 기본적으로 csv 포맷을 지원하지만, 구분자로 컬럼이 구분되어 있는 데이터는 모두 지원합니다.
read_csv함수로 파일을 데이터프레임으로 호출할 수 있습니다.
df = pd.read_csv('/content/drive/MyDrive/Lecture/삼성 디스플레이/1주차/1_python_basic_examples/data/friend_list.csv')df
- 아래는 csv 파일이 아닌 파일을 호출하는 예제입니다.
- 파일명은 txt이지만, 쉼표로 컬럼이 구분되어 있는 파일입니다.
df = pd.read_csv('/content/drive/MyDrive/Lecture/삼성 디스플레이/1주차/1_python_basic_examples/data/friend_list.txt')df.head()
- 만약 파일의 컬럼들이 쉼표로 구분되어 있지 않을 경우라도, delimiter 파라미터에 구분자를 지정해줘서
- 컬럼을 제대로 나줘줄 수 있습니다. 아래는 탭으로 컬럼이 구분된 경우의 예제입니다.
df = pd.read_csv('/content/drive/MyDrive/Lecture/삼성 디스플레이/1주차/1_python_basic_examples/data/friend_list_tab.txt', delimiter = "\t")df.head()
- 만약 파일에 데이터 헤더가 없을 경우, header = None으로 지정해줘서,
- 첫번째 데이터가 데이터 헤더로 들어가는 것을 방지해줘야합니다.
df = pd.read_csv('/content/drive/MyDrive/Lecture/삼성 디스플레이/1주차/1_python_basic/data/friend_list_no_head.csv', header = None)df.head()
- 헤더가 없는 데이터를 데이터프레임으로 호출했을 경우,
- 아래와 같이 데이터프레임 생성 후에, 컬럼 헤더를 지정해주실 수 있습니다.
df.columns = ['name', 'age', 'job']df.head()
- 또한, 파일을 데이터프레임으로 호출하는 동시에, 헤더를 아래와 같이 지정해주실 수도 있습니다.
df = pd.read_csv('/content/drive/MyDrive/Lecture/삼성 디스플레이/1주차/1_python_basic/data/friend_list_no_head.csv', header = None, names=['name', 'age', 'job'])df.head()
데이터프레임을 파이썬 코드로 생성하기
딕셔너리로 데이터프레임 생성하기
- 파이썬의 기본 자료구조로 데이터프레임 생성이 가능합니다.
- 아래의 예제는 딕셔너리로 데이터프레임을 생성하는 예제입니다.
friend_dict_list = [{'name': 'Jone', 'age': 20, 'job': 'student'},
{'name': 'Jenny', 'age': 30, 'job': 'developer'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list)df.head()
- 데이터프레임 생성 시, 컬럼의 순서가 뒤바뀔 수 있습니다.
- 아래와 같이 컬럼을 원하시는 순서로 지정하실 수 있습니다.
df = df[['name', 'age', 'job']]df.head()
OrderedDict로 데이터프레임 생성하기
- OrderedDict 자료구조로 데이터프레임을 생성하면, 컬럼의 순서가 뒤바뀌지 않습니다.
from collections import OrderedDictfriend_ordered_dict = OrderedDict([ ('name', ['John', 'Jenny', 'Nate']),
('age', [20, 30, 30]),
('job', ['student', 'developer', 'teacher']) ] )
df = pd.DataFrame.from_dict(friend_ordered_dict)df.head()
list로 데이터프레임 생성하기
- 리스트로 데이터프레임을 생성하는 예제입니다.
friend_list = [ ['John', 20, 'student'],['Jenny', 30, 'developer'],['Nate', 30, 'teacher'] ]
column_name = ['name', 'age', 'job']
df = pd.DataFrame.from_records(friend_list, columns=column_name)df.head()
friend_list = [
['name',['John', 'Jenny', 'Nate']],
['age',[20,30,30]],
['job',['student', 'developer', 'teacher']]
]
df = pd.DataFrame.from_dict(friend_list)df.head()
파일로 데이터프레임을 저장하기
- 아래는 데이터프레임을 헤더와 함께 저장하는 예제입니다.
friend_list = [
['name',['John', 'Jenny', 'nate']],
['age',[20,30,30]],
['job',['student', 'developer', 'teacher']]
]
df = pd.DataFrame.from_dict(friend_list)df.head()
- to_csv 함수를 사용하여 파일로 저장하실 수 있습니다.
df.to_csv('friend_list_from_df.csv')- 아래는 헤더가 없는 데이터프레임의 예제입니다.
friend_list = [ ['John', 20, 'student'],['Jenny', 30, 'developer'],['Nate', 30, 'teacher'] ]
df = pd.DataFrame.from_records(friend_list)df.head()
- to_csv 함수로 파일로 저장하실 수 있습니다.
df.to_csv('friend_list_from_df.csv')- 사실 파일의 확장자명은 원하시는대로 주셔도 무방합니다.
df.to_csv('friend_list_from_df.txt')- 기본적으로, 헤더와 인덱스값은 주시지 않아도, 기본적으로 True로 설정되어 있습니다.
df.to_csv('friend_list_from_df.csv', header = True, index = True)- header = False 는 컬럼 이름을 파일에 저장하지 않겠다라는 의미입니다. 예제에서 0,1,2가 헤더에 저장되지 않습니다.
- index = False 는 로우 인덱스를 파일에 저장하지 않겠다라는 의미입니다. 예제에서 0,1,2가 로우 인덱스에 저장되지 않습니다.
df.to_csv('friend_list_from_df.csv', header = False, index = False)- 헤더 정보를 원하실 경우, header 키워드로 컬럼 이름을 파일에 저장하실 수 있습니다.
df.to_csv('friend_list_from_df.csv', header = ['name', 'age', 'job'])- 아래는 None 값이 있는 데이터프레임의 예제입니다.
friend_list = [
['name',['John', None, 'nate']],
['age',[20,None,30]],
['job',['student', 'developer', 'teacher']]
]
df = pd.DataFrame.from_dict(friend_list)df.head()
df.to_csv('friend_list_from_df.csv')- na_rep 을 사용하시면 None 을 원하시는 값으로 쉽게 변경하실 수 있습니다.
df.to_csv('friend_list_from_df.csv', na_rep = '-')로우 선택하기
인덱스로 로우 선택하기
friend_list = [
['name',['John', 'Jenny', 'Nate']],
['age',[20,30,30]],
['job',['student', 'developer', 'teacher']]
]
# 데이터를 변환하여 적절한 형태로 만듦
data = {'name': friend_list[0][1], 'age': friend_list[1][1], 'job': friend_list[2][1]}
# 데이터프레임 생성
df = pd.DataFrame(data)
#df = pd.DataFrame.from_dict(friend_list)df.head()
- 아래는 로우 인덱스를 사용하여 로우1부터 3까지 순차적으로 선택하는 예제입니다.
df[1:3]

- 아래는 순차적이지 않은 로우를 선택하는 예제입니다.
```python
df.loc[[0,2]]
df.head()
컬럼값에 따른 로우 선택하기
- 마치 데이터베이스에 쿼리를 전달하듯, 특정한 컬럼값을 충족하는 로우만 선택하실 수 있습니다.
df['age'] > 25
df_filtered = df[df['age'] > 25]df_filtered
df_filtered = df.query('age>25')df_filtered
df_filtered = df[(df.age >25) & (df.name == 'Nate')]df_filtered
df
컬럼 필터하기
인덱스로 필터하기
friend_list = [ ['John', 20, 'student'],['Jenny', 30, 'developer'],['Nate', 30, 'teacher'] ]
df = pd.DataFrame.from_records(friend_list)
df
모든 로우를 보여주되, 컬럼은 0부터 1까지만 출력하는 예제입니다.
df.iloc[:, 0:2]
모든 로우를 보여주되, 컬럼 0와 2만 출력하는 예제입니다.
df.iloc[:,[0,2]]
df
컬럼 이름으로 필터하기
# you can create column header for no header data at once
df = pd.read_csv('/content/drive/MyDrive/Lecture/삼성 디스플레이/1주차/1_python_basic/data/friend_list_no_head.csv', header = None, names=['name', 'age', 'job'])
df
df_filtered = df[['name', 'age']]
df_filtered
df.filter(items=['age', 'job'])
df
원하는 글자를 가진 로우를 보여줍니다.
# select columns containing 'a'
df.filter(like='a',axis=1)
정규식으로 필터도 가능합니다.
# select columns using regex
df.filter(regex='b$',axis=1)
로우 드롭하기
로우 인덱스로 로우를 드롭할 수 있습니다.
friend_dict_list = [{'age': 20, 'job': 'student'},
{'age': 30, 'job': 'developer'},
{'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list, index = ['John', 'Jenny', 'Nate'])df.head()
드롭된 결과는 데이터프레임에 저장되지 않습니다. 저장하고 싶으실 경우, 결과를 데이터프레임에 따로 저장하셔야 합니다
df.drop(['John', 'Nate'])
df
드롭된 결과를 데이터프레임에 저장하는 예제입니다.
df = df.drop(['John', 'Nate'])df
드롭된 결과를 바로 데이터프레임에 저장하는 방법
inplace 키워드를 사용하시면, 따로 저장할 필요없이, 드롭된 결과가 데이터프레임에 반영됩니다.
friend_dict_list = [{'age': 20, 'job': 'student'},
{'age': 30, 'job': 'developer'},
{'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list, index = ['John', 'Jenny', 'Nate'])df.drop(['John', 'Nate'], inplace = True)df
로우 인덱스로 드롭하기
friend_dict_list = [{'name': 'Jone', 'age': 20, 'job': 'student'},
{'name': 'Jenny', 'age': 30, 'job': 'developer'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list)df
로우 인덱스로 드롭하는 예제입니다.
df = df.drop(df.index[[0,2]])df
컬럼값으로 로우 드롭하기
friend_dict_list = [{'name': 'Jone', 'age': 20, 'job': 'student'},
{'name': 'Jenny', 'age': 30, 'job': 'developer'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list)
df
df = df[df.age != 30]df
컬럼 드롭하기
friend_dict_list = [{'name': 'Jone', 'age': 20, 'job': 'student'},
{'name': 'Jenny', 'age': 30, 'job': 'developer'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list)
df
df = df.drop('age', axis=1)df
컬럼 추가 또는 변경하기
friend_dict_list = [{'name': 'Jone', 'age': 15, 'job': 'student'},
{'name': 'Jenny', 'age': 30, 'job': 'developer'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list, columns = ['name', 'age', 'job'])
df
아래와 같은 방법으로 새로운 컬럼을 기본값과 함께 추가하실 수 있습니다.
df['salary'] = 0df
기존 컬럼값을 가지고 새로운 컬럼을 생성하는 예제입니다.
friend_dict_list = [{'name': 'Jone', 'age': 15, 'job': 'student'},
{'name': 'Jenny', 'age': 30, 'job': 'developer'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(friend_dict_list, columns = ['name', 'age', 'job'])
df
넘파이를 사용하셔서, 한줄에 새로운 컬럼값을 생성하실 수도 있습니다.
import numpy as np
df['salary'] = np.where(df['job'] != 'student' , 'yes', 'no')df
friend_dict_list = [{'name': 'John', 'midterm': 95, 'final': 85},
{'name': 'Jenny', 'midterm': 85, 'final': 80},
{'name': 'Nate', 'midterm': 10, 'final': 30}]
df = pd.DataFrame(friend_dict_list, columns = ['name', 'midterm', 'final'])
df
아래는 기존에 있는 두 컬럼값을 더해서 새로운 컬럼을 만드는 예제입니다.
df['total'] = df['midterm'] + df['final']df
기존의 컬럼을 사용하여 새로운 컬럼을 만드는 예제입니다.
df['average'] = df['total'] / 2df
아래와 같이, 리스트에 조건별 값을 담아서, 새로운 컬럼으로 추가시킬 수 있습니다
grades = []
for row in df['average']:
if row >= 90:
grades.append('A')
elif row >= 80:
grades.append('B')
elif row >= 70:
grades.append('C')
else:
grades.append('F')
df['grade'] = gradesdf
apply 함수 사용 예제입니다.
apply를 사용하시면, 깔끔하게 컬럼의 값을 변경하는 코드를 구현하실 수 있습니다.
def pass_or_fail(row):
print(row)
if row != "F":
return 'Pass'
else:
return 'Fail'df.grade = df.grade.apply(pass_or_fail)df
apply를 사용해서 연월일의 정보에서 연도만 빼보는 예제입니다.
date_list = [{'yyyy-mm-dd': '2000-06-27'},
{'yyyy-mm-dd': '2002-09-24'},
{'yyyy-mm-dd': '2005-12-20'}]
df = pd.DataFrame(date_list, columns = ['yyyy-mm-dd'])
df
def extract_year(row):
return row.split('-')[0]df['year'] = df['yyyy-mm-dd'].apply(extract_year)df
apply 함수에 파라미터 전달하기
키워드 파라미터를 사용하시면, apply가 적용된 함수에 파라미터를 전달하실 수 있습니다.
def extract_year(year, current_year):
return current_year - int(year)df['age'] = df['year'].apply(extract_year, current_year=2018)
df
apply 함수에 한 개 이상의 파라미터 전달하기
키워드 파라미터를 추가해주시면, 원하시는만큼의 파라미터를 함수에 전달 가능합니다.
def get_introduce(age, prefix, suffix):
return prefix + str(age) + suffixdf['introduce'] = df['age'].apply(get_introduce, prefix="I am ", suffix=" years old")
df
apply 함수에 여러개의 컬럼을 동시에 전달하기
axis=1이라는 키워드 파라미터를 apply 함수에 전달해주면, 모든 컬럼을 지정된 함수에서 사용 가능합니다.
def get_introduce2(row):
return "I was born in "+str(row.year)+" my age is "+str(row.age)
df.introduce = df.apply(get_introduce2, axis=1)df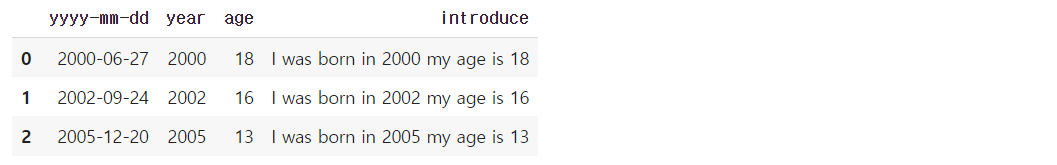
Map 함수로 컬럼 추가 및 변경하기
파라미터로 함수를 전달하면 apply 함수와 동일하게 컬럼값을 추가 및 변경할 수 있습니다.
def extract_year(row):
return row.split('-')[0]
date_list = [{'yyyy-mm-dd': '2000-06-27'},
{'yyyy-mm-dd': '2002-09-24'},
{'yyyy-mm-dd': '2005-12-20'}]
df = pd.DataFrame(date_list, columns = ['yyyy-mm-dd'])
df
df['year'] = df['yyyy-mm-dd'].map(extract_year)
df
파라미터로 딕셔너리를 전달하면 컬럼값을 쉽게 원하는 값으로 변경 가능합니다.
기존의 컬럼값은 딕셔너리의 key로 사용되고, 해당되는 value의 값으로 컬럼값이 변경됩니다.
job_list = [{'age': 20, 'job': 'student'},
{'age': 30, 'job': 'developer'},
{'age': 30, 'job': 'teacher'}]
df = pd.DataFrame(job_list)
df
df.job = df.job.map({"student":1,"developer":2,"teacher":3})
df
Applymap
데이터프레임 전체의 각각의 값을 한번에 변경시키실 때 사용하시면 좋습니다.
x_y = [{'x': 5.5, 'y': -5.6},
{'x': -5.2, 'y': 5.5},
{'x': -1.6, 'y': -4.5}]
df = pd.DataFrame(x_y)
df
df = df.applymap(np.around)
df
데이터프레임에 로우 추가하기
friend_dict_list = [{'name': 'John', 'midterm': 95, 'final': 85},
{'name': 'Jenny', 'midterm': 85, 'final': 80},
{'name': 'Nate', 'midterm': 10, 'final': 30}]
df = pd.DataFrame(friend_dict_list, columns = ['name', 'midterm', 'final'])
df
df2 = pd.DataFrame([['Ben', 50,50]], columns = ['name', 'midterm', 'final'])df2.head()
df.append(df2, ignore_index=True)
Group by
데이터에서 정보를 취하기 위해서 그룹별로 묶는 방법에 대해 알아보겠습니다.
student_list = [{'name': 'John', 'major': "Computer Science", 'sex': "male"},
{'name': 'Nate', 'major': "Computer Science", 'sex': "male"},
{'name': 'Abraham', 'major': "Physics", 'sex': "male"},
{'name': 'Brian', 'major': "Psychology", 'sex': "male"},
{'name': 'Janny', 'major': "Economics", 'sex': "female"},
{'name': 'Yuna', 'major': "Economics", 'sex': "female"},
{'name': 'Jeniffer', 'major': "Computer Science", 'sex': "female"},
{'name': 'Edward', 'major': "Computer Science", 'sex': "male"},
{'name': 'Zara', 'major': "Psychology", 'sex': "female"},
{'name': 'Wendy', 'major': "Economics", 'sex': "female"},
{'name': 'Sera', 'major': "Psychology", 'sex': "female"}
]
df = pd.DataFrame(student_list, columns = ['name', 'major', 'sex'])
df
groupby_major = df.groupby('major')df.groupby('major')['name']#<pandas.core.groupby.generic.SeriesGroupBy object at 0x7f31f524a0b0>groupby_major.groups#{'Computer Science': [0, 1, 6, 7], 'Economics': [4, 5, 9], 'Physics': [2], 'Psychology': [3, 8, 10]}here we can see, computer science has mostly man, while economic has mostly woman students
for name, group in groupby_major:
print(name + ": " + str(len(group)))
print(group)
print()Computer Science: 4
name major sex
0 John Computer Science male
1 Nate Computer Science male
6 Jeniffer Computer Science female
7 Edward Computer Science male
Economics: 3
name major sex
4 Janny Economics female
5 Yuna Economics female
9 Wendy Economics female
Physics: 1
name major sex
2 Abraham Physics male
Psychology: 3
name major sex
3 Brian Psychology male
8 Zara Psychology female
10 Sera Psychology female
그룹 객체를 다시 데이터프레임으로 생성하는 예제입니다.
df_major_cnt = pd.DataFrame({'count' : groupby_major.size()}).reset_index()
df_major_cnt
groupby_sex = df.groupby('sex')아래의 출력을 통해, 이 학교의 남녀 성비가 균등하다는 정보를 알 수 있습니다.
for name, group in groupby_sex:
print(name + ": " + str(len(group)))
print(group)
print()female: 6
name major sex
4 Janny Economics female
5 Yuna Economics female
6 Jeniffer Computer Science female
8 Zara Psychology female
9 Wendy Economics female
10 Sera Psychology female
male: 5
name major sex
0 John Computer Science male
1 Nate Computer Science male
2 Abraham Physics male
3 Brian Psychology male
7 Edward Computer Science maledf_sex_cnt = pd.DataFrame({'count' : groupby_sex.size()}).reset_index()
df_sex_cnt
중복 데이터 드롭하기
중복된 데이터 드롭하는 방법에 대해 알아보겠습니다.
student_list = [{'name': 'John', 'major': "Computer Science", 'sex': "male"},
{'name': 'Nate', 'major': "Computer Science", 'sex': "male"},
{'name': 'Abraham', 'major': "Physics", 'sex': "male"},
{'name': 'Brian', 'major': "Psychology", 'sex': "male"},
{'name': 'Janny', 'major': "Economics", 'sex': "female"},
{'name': 'Yuna', 'major': "Economics", 'sex': "female"},
{'name': 'Jeniffer', 'major': "Computer Science", 'sex': "female"},
{'name': 'Edward', 'major': "Computer Science", 'sex': "male"},
{'name': 'Zara', 'major': "Psychology", 'sex': "female"},
{'name': 'Wendy', 'major': "Economics", 'sex': "female"},
{'name': 'Sera', 'major': "Psychology", 'sex': "female"},
{'name': 'John', 'major': "Computer Science", 'sex': "male"},
]
df = pd.DataFrame(student_list, columns = ['name', 'major', 'sex'])
df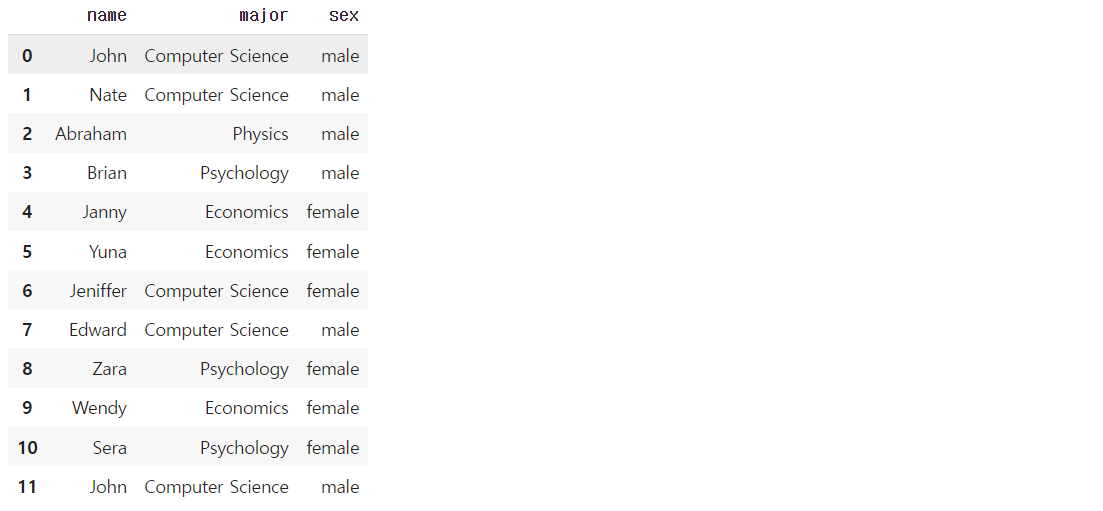
중복된 데이터 확인 하기
df.duplicated()0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 True
dtype: booldrop_duplicates 함수로 중복 데이터를 삭제하는 예제입니다
df = df.drop_duplicates()df
student_list = [{'name': 'John', 'major': "Computer Science", 'sex': "male"},
{'name': 'Nate', 'major': "Computer Science", 'sex': "male"},
{'name': 'Abraham', 'major': "Physics", 'sex': "male"},
{'name': 'Brian', 'major': "Psychology", 'sex': "male"},
{'name': 'Janny', 'major': "Economics", 'sex': "female"},
{'name': 'Yuna', 'major': "Economics", 'sex': "female"},
{'name': 'Jeniffer', 'major': "Computer Science", 'sex': "female"},
{'name': 'Edward', 'major': "Computer Science", 'sex': "male"},
{'name': 'Zara', 'major': "Psychology", 'sex': "female"},
{'name': 'Wendy', 'major': "Economics", 'sex': "female"},
{'name': 'Nate', 'major': None, 'sex': "male"},
{'name': 'John', 'major': "Computer Science", 'sex': None},
]
df = pd.DataFrame(student_list, columns = ['name', 'major', 'sex'])
df
name 컬럼이 똑같을 경우, 중복된 데이터라고 표시하라는 예제입니다.
df.duplicated(['name'])0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 True
11 True
dtype: boolkeep 값을 first 또는 last라고 값을 줘서 중복된 값 중, 어느값을 살릴 지 결정하실 수 있습니다.
기본적으로 first로 설정되어 있습니다.
df.drop_duplicates(['name'], keep='last')
df
None 처리 하기
school_id_list = [{'name': 'John', 'job': "teacher", 'age': 40},
{'name': 'Nate', 'job': "teacher", 'age': 35},
{'name': 'Yuna', 'job': "teacher", 'age': 37},
{'name': 'Abraham', 'job': "student", 'age': 10},
{'name': 'Brian', 'job': "student", 'age': 12},
{'name': 'Janny', 'job': "student", 'age': 11},
{'name': 'Nate', 'job': "teacher", 'age': None},
{'name': 'John', 'job': "student", 'age': None}
]
df = pd.DataFrame(school_id_list, columns = ['name', 'job', 'age'])
df
Null 또는 NaN 확인하기
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8 entries, 0 to 7
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 8 non-null object
1 job 8 non-null object
2 age 6 non-null float64
dtypes: float64(1), object(2)
memory usage: 320.0+ bytesdf.isna()
df.isnull()
Null 또는 NaN 값 변경하기
아래는 Null을 0으로 설정하는 예제입니다.
tmp = df
tmp["age"] = tmp["age"].fillna(0)
tmp
0으로 설정하기 보다는 선생님의 중간 나이, 학생의 중간 나이로, 각각의 직업군에 맞게 Null값을 변경해줍니다.
# fill missing age with median age for each group (teacher, student)
df["age"].fillna(df.groupby("job")["age"].transform("median"), inplace=True)df
Unique
컬럼에 여러 값이 있을 때, 중복 없이 어떤 값들이 있는 지 확인하는 방법입니다.
job_list = [{'name': 'John', 'job': "teacher"},
{'name': 'Nate', 'job': "teacher"},
{'name': 'Fred', 'job': "teacher"},
{'name': 'Abraham', 'job': "student"},
{'name': 'Brian', 'job': "student"},
{'name': 'Janny', 'job': "developer"},
{'name': 'Nate', 'job': "teacher"},
{'name': 'Obrian', 'job': "dentist"},
{'name': 'Yuna', 'job': "teacher"},
{'name': 'Rob', 'job': "lawyer"},
{'name': 'Brian', 'job': "student"},
{'name': 'Matt', 'job': "student"},
{'name': 'Wendy', 'job': "banker"},
{'name': 'Edward', 'job': "teacher"},
{'name': 'Ian', 'job': "teacher"},
{'name': 'Chris', 'job': "banker"},
{'name': 'Philip', 'job': "lawyer"},
{'name': 'Janny', 'job': "basketball player"},
{'name': 'Gwen', 'job': "teacher"},
{'name': 'Jessy', 'job': "student"}
]
df = pd.DataFrame(job_list, columns = ['name', 'job'])컬럼(시리즈)의 unique() 함수를 사용하여, 중복 없이, 컬럼에 있는 모든 값들을 출력할 수 있습니다.
print( df.job.unique() )['teacher' 'student' 'developer' 'dentist' 'lawyer' 'banker'
'basketball player']각 유니크한 값별로 몇개의 데이터가 속하는 지 value_counts() 함수로 확인할 수 있습니다.
df.job.value_counts()teacher 8
student 5
lawyer 2
banker 2
developer 1
dentist 1
basketball player 1
Name: job, dtype: int64두개의 데이터프레임 합치기
l1 = [{'name': 'John', 'job': "teacher"},
{'name': 'Nate', 'job': "student"},
{'name': 'Fred', 'job': "developer"}]
l2 = [{'name': 'Ed', 'job': "dentist"},
{'name': 'Jack', 'job': "farmer"},
{'name': 'Ted', 'job': "designer"}]
df1 = pd.DataFrame(l1, columns = ['name', 'job'])
df2 = pd.DataFrame(l2, columns = ['name', 'job'])pd.concat
두번째 데이터프레임을 첫번째 데이터프레임의 새로운 로우(행)로 합칩니다.
frames = [df1, df2]
result = pd.concat(frames, ignore_index=True)result
df.append
두번째 데이터프레임을 첫번째 데이터프레임의 새로운 로우(행)로 합칩니다.
l1 = [{'name': 'John', 'job': "teacher"},
{'name': 'Nate', 'job': "student"},
{'name': 'Fred', 'job': "developer"}]
l2 = [{'name': 'Ed', 'job': "dentist"},
{'name': 'Jack', 'job': "farmer"},
{'name': 'Ted', 'job': "designer"}]
df1 = pd.DataFrame(l1, columns = ['name', 'job'])
df2 = pd.DataFrame(l2, columns = ['name', 'job'])
result = df1.append(df2, ignore_index=True)<ipython-input-151-3327dac28767>:11: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
result = df1.append(df2, ignore_index=True)result
pd.concat
두번째 데이터프레임을 첫번째 데이터프레임의 새로운 컬럼(열)으로 합칩니다.
l1 = [{'name': 'John', 'job': "teacher"},
{'name': 'Nate', 'job': "student"},
{'name': 'Jack', 'job': "developer"}]
l2 = [{'age': 25, 'country': "U.S"},
{'age': 30, 'country': "U.K"},
{'age': 45, 'country': "Korea"}]
df1 = pd.DataFrame(l1, columns = ['name', 'job'])
df2 = pd.DataFrame(l2, columns = ['age', 'country'])
result = pd.concat([df1, df2], axis=1, ignore_index=True)result
두개의 리스트를 묶어서 데이터프레임으로 생성하기
label = [1,2,3,4,5]
prediction = [1,2,2,5,5]
comparison = pd.DataFrame(
{'label': label,
'prediction': prediction
})
comparison
