import tensorflow as tf
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
tf.__version__코드를 입력하세요Dataset
- 데이터셋 구성
# Load training and eval data from tf.keras
(train_data, train_labels), (test_data, test_labels) = \
tf.keras.datasets.mnist.load_data()
train_data, valid_data, train_labels, valid_labels = \
train_test_split(train_data, train_labels, test_size=0.1, shuffle=True)
train_data = train_data / 255.
train_data = train_data.reshape(-1, 784)
train_data = train_data.astype(np.float32)
train_labels = train_labels.astype(np.int32)
valid_data = valid_data / 255.
valid_data = valid_data.reshape(-1, 784)
valid_data = valid_data.astype(np.float32)
valid_labels = valid_labels.astype(np.int32)
test_data = test_data / 255.
test_data = test_data.reshape(-1, 784)
test_data = test_data.astype(np.float32)
test_labels = test_labels.astype(np.int32)#Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-#datasets/mnist.npz
#11490434/11490434 [==============================] - 2s 0us/stepOne-hot label 처리
def one_hot_label(image, label):
label = tf.one_hot(label, depth=10)
return image, labelbatch_size = 32
max_epochs = 10
# for train
N = len(train_data)
train_dataset = tf.data.Dataset.from_tensor_slices((train_data, train_labels))
train_dataset = train_dataset.shuffle(buffer_size=10000)
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for valid
valid_dataset = tf.data.Dataset.from_tensor_slices((valid_data, valid_labels))
valid_dataset = valid_dataset.map(one_hot_label)
valid_dataset = valid_dataset.repeat().batch(batch_size=batch_size)
print(valid_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_data, test_labels))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)#<_BatchDataset element_spec=(TensorSpec(shape=(None, 784), dtype=tf.float32, name=None), TensorSpec(shape=(None, 10), dtype=tf.float32, name=None))>
#<_BatchDataset element_spec=(TensorSpec(shape=(None, 784), dtype=tf.float32, name=None), TensorSpec(shape=(None, 10), dtype=tf.float32, name=None))>
#<_BatchDataset element_spec=(TensorSpec(shape=(None, 784), dtype=tf.float32, name=None), TensorSpec(shape=(None, 10), dtype=tf.float32, name=None))>index = 1234
print("label = {}".format(train_labels[index]))
plt.imshow(train_data[index].reshape(28, 28))
plt.colorbar()
#plt.gca().grid(False)
plt.show()
모델 제작
model = tf.keras.models.Sequential()
# Adds a densely-connected layer with 64 units to the model:
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dropout(0.5))
# Add another:
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
# Add a softmax layer with 10 output units:
model.add(layers.Dense(10, activation='softmax'))model.compile(optimizer=tf.keras.optimizers.Adam(1e-5),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])# without training, just inference a model in eager execution:
predictions = model(train_data[0:1], training=False)
print("Predictions: ", predictions.numpy())#Predictions: [[0.1179347 0.08036174 0.06860074 0.10702526 0.09063728 0.10022083
# 0.05997165 0.13735911 0.10306624 0.13482244]]model.summary()#Output
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (1, 256) 200960
dropout_1 (Dropout) (1, 256) 0
dense_5 (Dense) (1, 128) 32896
dense_6 (Dense) (1, 64) 8256
dense_7 (Dense) (1, 10) 650
=================================================================
Total params: 242762 (948.29 KB)
Trainable params: 242762 (948.29 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________Training
# using `numpy type` data
# history = model.fit(train_data, train_labels,
# batch_size=batch_size, epochs=max_epochs,
# validation_split=0.1)
# using `tf.data.Dataset`
history = model.fit(train_dataset, validation_data=valid_dataset, epochs=max_epochs,
validation_steps=len(valid_data) // batch_size,
steps_per_epoch=int(len(train_data) / batch_size))#output
Epoch 1/10
1687/1687 [==============================] - 12s 5ms/step - loss: 1.9734 - accuracy: 0.3595 - val_loss: 1.3606 - val_accuracy: 0.7550
Epoch 2/10
1687/1687 [==============================] - 10s 6ms/step - loss: 1.1520 - accuracy: 0.6922 - val_loss: 0.7329 - val_accuracy: 0.8344
Epoch 3/10
1687/1687 [==============================] - 9s 5ms/step - loss: 0.7796 - accuracy: 0.7774 - val_loss: 0.5335 - val_accuracy: 0.8643
Epoch 4/10
1687/1687 [==============================] - 8s 5ms/step - loss: 0.6258 - accuracy: 0.8179 - val_loss: 0.4461 - val_accuracy: 0.8787
Epoch 5/10
1687/1687 [==============================] - 8s 5ms/step - loss: 0.5415 - accuracy: 0.8418 - val_loss: 0.3978 - val_accuracy: 0.8875
Epoch 6/10
1687/1687 [==============================] - 10s 6ms/step - loss: 0.4906 - accuracy: 0.8550 - val_loss: 0.3640 - val_accuracy: 0.8952
Epoch 7/10
1687/1687 [==============================] - 9s 5ms/step - loss: 0.4504 - accuracy: 0.8667 - val_loss: 0.3401 - val_accuracy: 0.9026
Epoch 8/10
1687/1687 [==============================] - 8s 5ms/step - loss: 0.4217 - accuracy: 0.8751 - val_loss: 0.3196 - val_accuracy: 0.9079
Epoch 9/10
1687/1687 [==============================] - 11s 6ms/step - loss: 0.3961 - accuracy: 0.8824 - val_loss: 0.3037 - val_accuracy: 0.9129
Epoch 10/10
1687/1687 [==============================] - 9s 5ms/step - loss: 0.3748 - accuracy: 0.8902 - val_loss: 0.2906 - val_accuracy: 0.9168history.history.keys()#dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(max_epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Valid Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Valid Loss')
plt.show()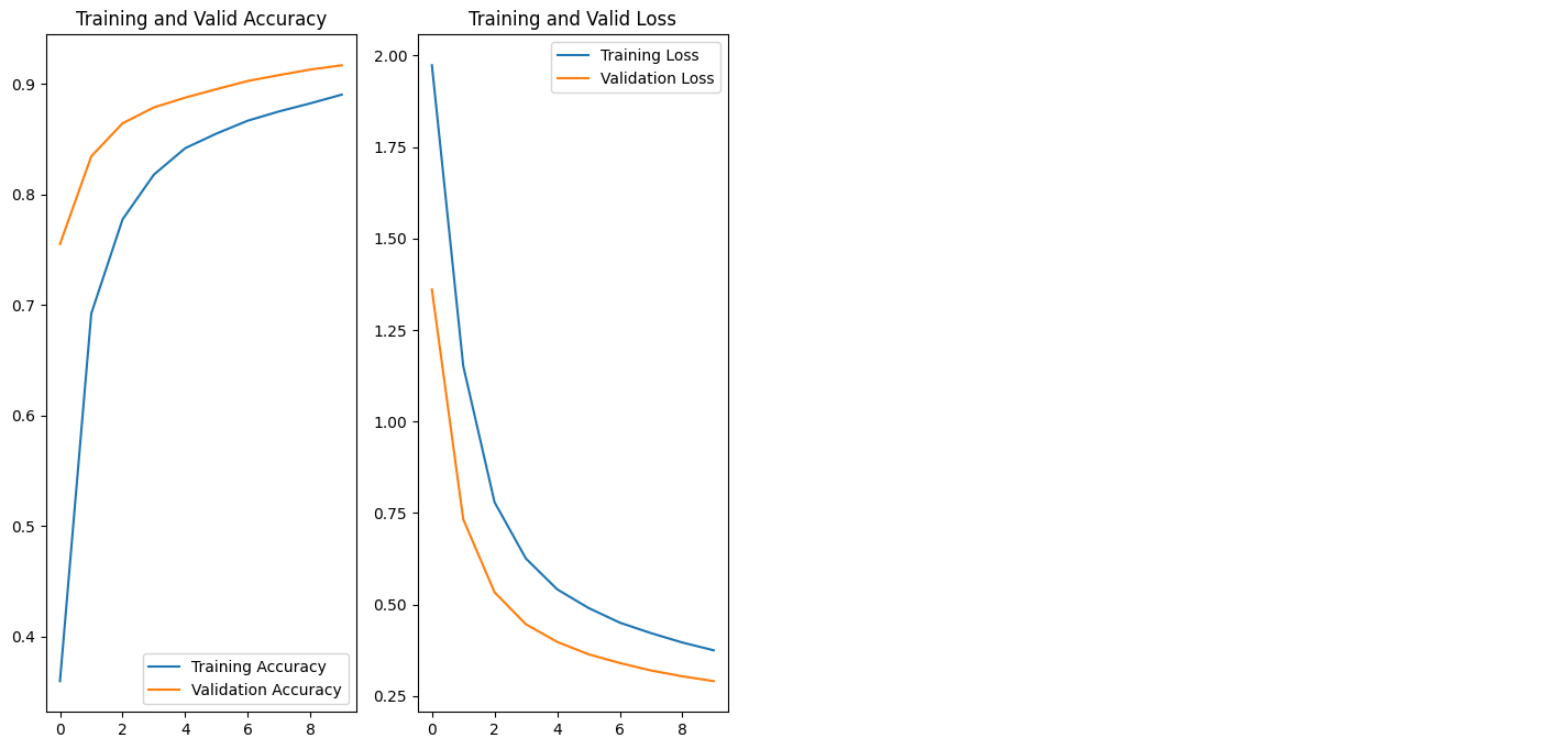
Evaluation
results = model.evaluate(test_dataset)#313/313 [==============================] - 1s 4ms/step - loss: 0.2707 - accuracy: 0.9233# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))#loss value: 0.271
#accuracy value: 92.3300%np.random.seed(219)
test_batch_size = 16
batch_index = np.random.choice(len(test_data), size=test_batch_size, replace=False)
batch_xs = test_data[batch_index]
batch_ys = test_labels[batch_index]
y_pred_ = model(batch_xs, training=False)
fig = plt.figure(figsize=(16, 10))
for i, (px, py) in enumerate(zip(batch_xs, y_pred_)):
p = fig.add_subplot(4, 8, i+1)
if np.argmax(py) == batch_ys[i]:
p.set_title("y_pred: {}".format(np.argmax(py)), color='blue')
else:
p.set_title("y_pred: {}".format(np.argmax(py)), color='red')
p.imshow(px.reshape(28, 28))
p.axis('off')

AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms