Copyright 2021 The TensorFlow Authors.
Keras 전처리 레이어로 tf.feature_column 마이그레이션하기
모델 교육에는 구조화된 데이터를 처리할 때와 같이 어느 정도의 기능 사전 처리가 일반적으로 수반됩니다. TensorFlow 1의 tf.estimator.Estimator를 훈련할 때 일반적으로 tf.feature_column API를 사용하여 특성 전처리를 수행합니다. TensorFlow 2에서는 Keras 전처리 레이어를 사용하여 직접 이 작업을 수행할 수 있습니다.
이 마이그레이션 가이드는 특성 열과 전처리 레이어를 모두 사용하여 일반적인 특성 변환을 설명한 다음 두 API를 모두 사용하여 완전한 모델을 훈련하는 방법을 보여줍니다.
먼저 필요한 몇 가지를 가져오는 작업으로 시작합니다.
import tensorflow as tf
import tensorflow.compat.v1 as tf1
import math이제 데모를 위해 기능 열을 호출하는 유틸리티 함수를 추가합니다.
def call_feature_columns(feature_columns, inputs):
# This is a convenient way to call a `feature_column` outside of an estimator
# to display its output.
feature_layer = tf1.keras.layers.DenseFeatures(feature_columns)
return feature_layer(inputs)입력 처리하기
Estimator와 함께 특성 열을 사용하려면 모델 입력이 항상 텐서 사전으로 예상되어야 합니다.
input_dict = {
'foo': tf.constant([1]),
'bar': tf.constant([0]),
'baz': tf.constant([-1])
}각 특성 열은 소스 데이터로 인덱싱되는 키로 생성해야 합니다. 모든 특성 열의 출력은 연결되고 Estimator 모델에서 사용됩니다.
columns = [
tf1.feature_column.numeric_column('foo'),
tf1.feature_column.numeric_column('bar'),
tf1.feature_column.numeric_column('baz'),
]
call_feature_columns(columns, input_dict)#WARNING:tensorflow:From <ipython-input-5-f1cd65e50cdf>:2: numeric_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
#Instructions for updating:
#Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
#<tf.Tensor: shape=(1, 3), dtype=float32, numpy=array([[ 0., -1., 1.]], dtype=float32)>Keras에서는 모델 입력이 훨씬 더 유연합니다. tf.keras.Model은 단일 텐서 입력, 텐서 특성 목록 또는 텐서 특성 사전을 처리할 수 있습니다. 모델 생성 시 tf.keras.Input 사전을 전달하여 사전 입력을 처리할 수 있습니다. 입력은 자동으로 연결되지 않으므로 훨씬 더 유연하게 사용할 수 있습니다. 입력을 tf.keras.layers.Concatenate로 연결할 수 있습니다.
inputs = {
'foo': tf.keras.Input(shape=()),
'bar': tf.keras.Input(shape=()),
'baz': tf.keras.Input(shape=()),
}
# Inputs are typically transformed by preprocessing layers before concatenation.
outputs = tf.keras.layers.Concatenate()(inputs.values())
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model(input_dict)#<tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 1., 0., -1.], dtype=float32)>원-핫 인코딩 정수 ID
일반적인 특성 변환은 알려진 범위의 정수 입력을 원-핫 인코딩하는 것입니다. 다음은 특성 열을 사용하는 예제입니다.
categorical_col = tf1.feature_column.categorical_column_with_identity(
'type', num_buckets=3)
indicator_col = tf1.feature_column.indicator_column(categorical_col)
call_feature_columns(indicator_col, {'type': [0, 1, 2]})WARNING:tensorflow:From <ipython-input-7-48ad1e18ba4a>:1: categorical_column_with_identity (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
WARNING:tensorflow:From <ipython-input-7-48ad1e18ba4a>:3: indicator_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]], dtype=float32)>Keras 전처리 레이어를 사용하면 이러한 열을 output_mode가 'one_hot'으로 설정된 단일 tf.keras.layers.CategoryEncoding 레이어로 대체할 수 있습니다.
one_hot_layer = tf.keras.layers.CategoryEncoding(
num_tokens=3, output_mode='one_hot')
one_hot_layer([0, 1, 2])<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]], dtype=float32)>참고: 대형 원-핫 인코딩을 수행하는 경우 출력의 희소 표현을 사용하는 것이 훨씬 더 효율적입니다. sparse=True를 CategoryEncoding 레이어에 전달하면 레이어의 출력이 tf.sparse.SparseTensor가 되어 tf.keras.layers.Dense 레이어에 대한 입력으로 효율적으로 처리됩니다.
숫자 특성 정규화
특성 열이 있는 연속 부동 소수점 특성을 처리할 때에는 tf.feature_column.numeric_column을 사용해야 합니다. 입력이 이미 정규화되어 있는 경우 이를 Keras로 변환하는 것은 간단합니다. 위와 같이 간단하게 모델에 직접 tf.keras.Input을 사용할 수 있습니다.
numeric_column도 입력을 정규화하는 데 사용할 수 있습니다.
def normalize(x):
mean, variance = (2.0, 1.0)
return (x - mean) / math.sqrt(variance)
numeric_col = tf1.feature_column.numeric_column('col', normalizer_fn=normalize)
call_feature_columns(numeric_col, {'col': tf.constant([[0.], [1.], [2.]])})<tf.Tensor: shape=(3, 1), dtype=float32, numpy=
array([[-2.],
[-1.],
[ 0.]], dtype=float32)>이와 대조적으로 Keras에서는 tf.keras.layers.Normalization을 사용하여 이 정규화를 수행할 수 있습니다.
normalization_layer = tf.keras.layers.Normalization(mean=2.0, variance=1.0)
normalization_layer(tf.constant([[0.], [1.], [2.]]))<tf.Tensor: shape=(3, 1), dtype=float32, numpy=
array([[-2.],
[-1.],
[ 0.]], dtype=float32)>버킷화 및 원-핫 인코딩 숫자 특성
또 다른 연속 부동 소수점 입력의 일반적인 변환은 고정 범위의 정수로 버킷화하는 것입니다.
특성 열에서 tf.feature_column.bucketized_column을 사용하여 이를 수행할 수 있습니다.
numeric_col = tf1.feature_column.numeric_column('col')
bucketized_col = tf1.feature_column.bucketized_column(numeric_col, [1, 4, 5])
call_feature_columns(bucketized_col, {'col': tf.constant([1., 2., 3., 4., 5.])})WARNING:tensorflow:From <ipython-input-11-2a1cc8935562>:2: bucketized_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
<tf.Tensor: shape=(5, 4), dtype=float32, numpy=
array([[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]], dtype=float32)>Keras에서는 tf.keras.layers.Discretization으로 교체할 수 있습니다.
discretization_layer = tf.keras.layers.Discretization(bin_boundaries=[1, 4, 5])
one_hot_layer = tf.keras.layers.CategoryEncoding(
num_tokens=4, output_mode='one_hot')
one_hot_layer(discretization_layer([1., 2., 3., 4., 5.]))<tf.Tensor: shape=(5, 4), dtype=float32, numpy=
array([[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]], dtype=float32)>어휘가 있는 원-핫 인코딩 문자열 데이터
문자열 특성을 처리할 때 문자열을 인덱스로 변환하기 위해 어휘 조회 기능이 필요한 경우가 많습니다. 다음은 특성 열을 사용하여 문자열을 조회한 후 인덱스를 원-핫 인코딩하는 예제입니다.
vocab_col = tf1.feature_column.categorical_column_with_vocabulary_list(
'sizes',
vocabulary_list=['small', 'medium', 'large'],
num_oov_buckets=0)
indicator_col = tf1.feature_column.indicator_column(vocab_col)
call_feature_columns(indicator_col, {'sizes': ['small', 'medium', 'large']})WARNING:tensorflow:From <ipython-input-13-5caf02bb6598>:1: categorical_column_with_vocabulary_list (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]], dtype=float32)>Keras 전처리 레이어를 사용하여 output_mode가 'one_hot'으로 설정된 tf.keras.layers.StringLookup 레이어를 사용합니다.
string_lookup_layer = tf.keras.layers.StringLookup(
vocabulary=['small', 'medium', 'large'],
num_oov_indices=0,
output_mode='one_hot')
string_lookup_layer(['small', 'medium', 'large'])/usr/local/lib/python3.10/dist-packages/numpy/core/numeric.py:2449: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
return bool(asarray(a1 == a2).all())
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]], dtype=float32)>참고: 대형 원-핫 인코딩을 수행하는 경우 출력의 희소 표현을 사용하는 것이 훨씬 더 효율적입니다. sparse=True를 StringLookup 레이어에 전달하면 레이어의 출력이 tf.sparse.SparseTensor가 되어 tf.keras.layers.Dense 레이어에 대한 입력으로 효율적으로 처리됩니다.
어휘가 있는 임베딩 문자열 데이터
어휘가 더 많은 경우 좋은 성능을 위해 임베딩이 필요한 경우가 있습니다. 다음은 특성 열을 사용하여 문자열 특성을 임베딩하는 예제입니다.
vocab_col = tf1.feature_column.categorical_column_with_vocabulary_list(
'col',
vocabulary_list=['small', 'medium', 'large'],
num_oov_buckets=0)
embedding_col = tf1.feature_column.embedding_column(vocab_col, 4)
call_feature_columns(embedding_col, {'col': ['small', 'medium', 'large']})WARNING:tensorflow:From <ipython-input-15-6231e5f02bec>:5: embedding_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
<tf.Tensor: shape=(3, 4), dtype=float32, numpy=
array([[-0.95723647, 0.18642594, -0.06982385, 0.6163995 ],
[-0.43471247, -0.0310566 , 0.22916362, 0.9204661 ],
[ 0.00459263, -0.32064855, -0.49101958, -0.4099362 ]],
dtype=float32)>Keras 전처리 레이어를 사용하면 tf.keras.layers.StringLookup 레이어와 tf.keras.layers.Embedding 레이어를 결합하여 이 작업을 수행할 수 있습니다. StringLookup의 기본 출력은 임베딩에 직접 제공할 수 있는 정수 인덱스입니다.
참고: Embedding 레이어에는 훈련 가능한 매개변수가 포함되어 있습니다. StringLookup 레이어는 모델 내부 또는 외부의 데이터에 적용할 수 있지만 올바르게 훈련하려면 Embedding이 항상 훈련 가능한 Keras 모델의 일부여야 합니다.
string_lookup_layer = tf.keras.layers.StringLookup(
vocabulary=['small', 'medium', 'large'], num_oov_indices=0)
embedding = tf.keras.layers.Embedding(3, 4)
embedding(string_lookup_layer(['small', 'medium', 'large']))<tf.Tensor: shape=(3, 4), dtype=float32, numpy=
array([[-0.0035731 , 0.02621341, -0.02217702, 0.04483309],
[-0.0094329 , 0.03923568, 0.03860174, -0.02602735],
[ 0.02587991, 0.00735518, -0.04258641, 0.04498391]],
dtype=float32)>가중치 범주형 데이터 합산하기
경우에 따라 범주가 발생할 때마다 연관된 가중치가 있는 범주형 데이터를 처리해야 할 수 있습니다. 특성 열에서 이는 tf.feature_column.weighted_categorical_column으로 처리됩니다. indicator_column과 함께 사용하면 범주별로 가중치를 합산하는 효과가 있습니다.
ids = tf.constant([[5, 11, 5, 17, 17]])
weights = tf.constant([[0.5, 1.5, 0.7, 1.8, 0.2]])
categorical_col = tf1.feature_column.categorical_column_with_identity(
'ids', num_buckets=20)
weighted_categorical_col = tf1.feature_column.weighted_categorical_column(
categorical_col, 'weights')
indicator_col = tf1.feature_column.indicator_column(weighted_categorical_col)
call_feature_columns(indicator_col, {'ids': ids, 'weights': weights})WARNING:tensorflow:From <ipython-input-17-ba822641b152>:6: weighted_categorical_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/feature_column/feature_column_v2.py:4271: sparse_merge (from tensorflow.python.ops.sparse_ops) is deprecated and will be removed in a future version.
Instructions for updating:
No similar op available at this time.
<tf.Tensor: shape=(1, 20), dtype=float32, numpy=
array([[0. , 0. , 0. , 0. , 0. , 1.2, 0. , 0. , 0. , 0. , 0. , 1.5, 0. ,
0. , 0. , 0. , 0. , 2. , 0. , 0. ]], dtype=float32)>Keras에서는 output_mode='count'를 사용하여 tf.keras.layers.CategoryEncoding에 count_weights 입력을 전달하여 이 작업을 수행할 수 있습니다.
ids = tf.constant([[5, 11, 5, 17, 17]])
weights = tf.constant([[0.5, 1.5, 0.7, 1.8, 0.2]])
# Using sparse output is more efficient when `num_tokens` is large.
count_layer = tf.keras.layers.CategoryEncoding(
num_tokens=20, output_mode='count', sparse=True)
tf.sparse.to_dense(count_layer(ids, count_weights=weights))<tf.Tensor: shape=(1, 20), dtype=float32, numpy=
array([[0. , 0. , 0. , 0. , 0. , 1.2, 0. , 0. , 0. , 0. , 0. , 1.5, 0. ,
0. , 0. , 0. , 0. , 2. , 0. , 0. ]], dtype=float32)>가중치 범주형 데이터 임베딩하기
가중치 범주형 입력을 임베딩해야 할 수도 있습니다. 특성 열에서 embedding_column은 combiner 인수를 포함합니다. 샘플에 카테고리에 대한 여러 항목이 포함되어 있는 경우 이러한 항목들은 인수 설정(기본적으로 'mean')에 따라 결합됩니다.
ids = tf.constant([[5, 11, 5, 17, 17]])
weights = tf.constant([[0.5, 1.5, 0.7, 1.8, 0.2]])
categorical_col = tf1.feature_column.categorical_column_with_identity(
'ids', num_buckets=20)
weighted_categorical_col = tf1.feature_column.weighted_categorical_column(
categorical_col, 'weights')
embedding_col = tf1.feature_column.embedding_column(
weighted_categorical_col, 4, combiner='mean')
call_feature_columns(embedding_col, {'ids': ids, 'weights': weights})<tf.Tensor: shape=(1, 4), dtype=float32, numpy=
array([[-0.31935272, 0.3310298 , -0.4180704 , 0.03357369]],
dtype=float32)>Keras에는 tf.keras.layers.Embedding에 대한 combiner 옵션이 없지만 tf.keras.layers.Dense를 사용하여 같은 효과를 얻을 수 있습니다. 위의 embedding_column은 단순히 범주의 가중치에 따라 임베딩 벡터를 선형적으로 결합한 것입니다. 처음에는 명확하지 않지만 범주형 입력을 (num_tokens) 크기의 희소 가중치 벡터로 표현하고 (embedding_size, num_tokens) 형상의 Dense 커널을 곱하는 것과 정확히 동일합니다.
ids = tf.constant([[5, 11, 5, 17, 17]])
weights = tf.constant([[0.5, 1.5, 0.7, 1.8, 0.2]])
# For `combiner='mean'`, normalize your weights to sum to 1. Removing this line
# would be equivalent to an `embedding_column` with `combiner='sum'`.
weights = weights / tf.reduce_sum(weights, axis=-1, keepdims=True)
count_layer = tf.keras.layers.CategoryEncoding(
num_tokens=20, output_mode='count', sparse=True)
embedding_layer = tf.keras.layers.Dense(4, use_bias=False)
embedding_layer(count_layer(ids, count_weights=weights))<tf.Tensor: shape=(1, 4), dtype=float32, numpy=
array([[ 0.04260075, -0.03651819, 0.252878 , 0.06211461]],
dtype=float32)>전체 훈련 예제
전체 훈련 워크플로를 표시하려면 먼저 서로 다른 유형의 세 가지 특성을 사용하여 일부 데이터를 준비합니다.
features = {
'type': [0, 1, 1],
'size': ['small', 'small', 'medium'],
'weight': [2.7, 1.8, 1.6],
}
labels = [1, 1, 0]
predict_features = {'type': [0], 'size': ['foo'], 'weight': [-0.7]}TensorFlow 1 및 TensorFlow 2 워크플로 모두에 대한 몇 가지 공통 상수를 정의합니다.
vocab = ['small', 'medium', 'large']
one_hot_dims = 3
embedding_dims = 4
weight_mean = 2.0
weight_variance = 1.0특성 열을 사용하는 경우
특성 열은 생성 시 Estimator에 목록으로 전달되어야 하며 훈련 중에는 암시적으로 호출됩니다.
categorical_col = tf1.feature_column.categorical_column_with_identity(
'type', num_buckets=one_hot_dims)
# Convert index to one-hot; e.g. [2] -> [0,0,1].
indicator_col = tf1.feature_column.indicator_column(categorical_col)
# Convert strings to indices; e.g. ['small'] -> [1].
vocab_col = tf1.feature_column.categorical_column_with_vocabulary_list(
'size', vocabulary_list=vocab, num_oov_buckets=1)
# Embed the indices.
embedding_col = tf1.feature_column.embedding_column(vocab_col, embedding_dims)
normalizer_fn = lambda x: (x - weight_mean) / math.sqrt(weight_variance)
# Normalize the numeric inputs; e.g. [2.0] -> [0.0].
numeric_col = tf1.feature_column.numeric_column(
'weight', normalizer_fn=normalizer_fn)
estimator = tf1.estimator.DNNClassifier(
feature_columns=[indicator_col, embedding_col, numeric_col],
hidden_units=[1])
def _input_fn():
return tf1.data.Dataset.from_tensor_slices((features, labels)).batch(1)
estimator.train(_input_fn)WARNING:tensorflow:From <ipython-input-23-1d218e82a3e4>:17: DNNClassifier.__init__ (from tensorflow_estimator.python.estimator.canned.dnn) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/canned/dnn.py:807: Estimator.__init__ (from tensorflow_estimator.python.estimator.estimator) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/estimator.py:1842: RunConfig.__init__ (from tensorflow_estimator.python.estimator.run_config) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmp_40otnn9
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/training_util.py:396: Variable.initialized_value (from tensorflow.python.ops.variables) is deprecated and will be removed in a future version.
Instructions for updating:
Use Variable.read_value. Variables in 2.X are initialized automatically both in eager and graph (inside tf.defun) contexts.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/canned/dnn.py:446: dnn_logit_fn_builder (from tensorflow_estimator.python.estimator.canned.dnn) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/adagrad.py:138: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/model_fn.py:250: EstimatorSpec.__new__ (from tensorflow_estimator.python.estimator.model_fn) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/estimator.py:1414: NanTensorHook.__init__ (from tensorflow.python.training.basic_session_run_hooks) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/estimator.py:1417: LoggingTensorHook.__init__ (from tensorflow.python.training.basic_session_run_hooks) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/basic_session_run_hooks.py:232: SecondOrStepTimer.__init__ (from tensorflow.python.training.basic_session_run_hooks) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/estimator.py:1454: CheckpointSaverHook.__init__ (from tensorflow.python.training.basic_session_run_hooks) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/monitored_session.py:579: StepCounterHook.__init__ (from tensorflow.python.training.basic_session_run_hooks) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/monitored_session.py:586: SummarySaverHook.__init__ (from tensorflow.python.training.basic_session_run_hooks) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/monitored_session.py:1455: SessionRunArgs.__new__ (from tensorflow.python.training.session_run_hook) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/monitored_session.py:1454: SessionRunContext.__init__ (from tensorflow.python.training.session_run_hook) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/training/monitored_session.py:1474: SessionRunValues.__new__ (from tensorflow.python.training.session_run_hook) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
<tensorflow_estimator.python.estimator.canned.dnn.DNNClassifier at 0x7ff55ada6710>특성 열은 모델에서 추론을 실행할 때 입력 데이터 변환에도 사용됩니다.
def _predict_fn():
return tf1.data.Dataset.from_tensor_slices(predict_features).batch(1)
next(estimator.predict(_predict_fn))WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/canned/head.py:596: ClassificationOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/canned/head.py:1307: RegressionOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow_estimator/python/estimator/canned/head.py:1309: PredictOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
{'logits': array([2.3575892], dtype=float32),
'logistic': array([0.9135356], dtype=float32),
'probabilities': array([0.08646443, 0.9135356 ], dtype=float32),
'class_ids': array([1]),
'classes': array([b'1'], dtype=object),
'all_class_ids': array([0, 1], dtype=int32),
'all_classes': array([b'0', b'1'], dtype=object)}Keras 전처리 레이어를 사용하는 경우
Keras 전처리 레이어는 호출할 수 있는 위치에서 더 유연하게 사용할 수 있습니다. 레이어를 텐서에 직접 적용하거나 tf.data 입력 파이프라인 내에서 사용하거나 훈련 가능한 Keras 모델에 직접 빌드할 수 있습니다.
이 예제에서는 tf.data 입력 파이프라인 내부에 전처리 레이어를 적용합니다. 이를 위해 별도의 tf.keras.Model을 정의하여 입력 특성을 전처리할 수 있습니다. 이 모델은 훈련 가능한 전처리 레이어를 그룹화하는 편리한 방법입니다.
inputs = {
'type': tf.keras.Input(shape=(), dtype='int64'),
'size': tf.keras.Input(shape=(), dtype='string'),
'weight': tf.keras.Input(shape=(), dtype='float32'),
}
# Convert index to one-hot; e.g. [2] -> [0,0,1].
type_output = tf.keras.layers.CategoryEncoding(
one_hot_dims, output_mode='one_hot')(inputs['type'])
# Convert size strings to indices; e.g. ['small'] -> [1].
size_output = tf.keras.layers.StringLookup(vocabulary=vocab)(inputs['size'])
# Normalize the numeric inputs; e.g. [2.0] -> [0.0].
weight_output = tf.keras.layers.Normalization(
axis=None, mean=weight_mean, variance=weight_variance)(inputs['weight'])
outputs = {
'type': type_output,
'size': size_output,
'weight': weight_output,
}
preprocessing_model = tf.keras.Model(inputs, outputs)참고: 레이어 생성 시 어휘 및 정규화 통계를 제공하는 작업 대신 많은 전처리 레이어가 입력 데이터에서 직접 레이어 상태를 학습하는 adapt() 메서드를 제공합니다. 자세한 내용은 전처리 가이드를 참조하세요.
이제 tf.data.Dataset.map 호출 내부에 이 모델을 적용할 수 있습니다. map에 전달된 함수는 자동으로 tf.function으로 변환되며 tf.function 코드 작성할 때 참조하는 일반적인 주의 사항이 적용됩니다(부작용 없음).
# Apply the preprocessing in tf.data.Dataset.map.
dataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(1)
dataset = dataset.map(lambda x, y: (preprocessing_model(x), y),
num_parallel_calls=tf.data.AUTOTUNE)
# Display a preprocessed input sample.
next(dataset.take(1).as_numpy_iterator())({'type': array([[1., 0., 0.]], dtype=float32),
'size': array([1]),
'weight': array([0.70000005], dtype=float32)},
array([1], dtype=int32))다음으로 훈련할 수 있는 레이어가 포함된 별도의 Model을 정의할 수 있습니다. 이 모델에 대한 입력이 이제 전처리된 특성 유형과 형상을 어떻게 반영하는지 확인합니다.
inputs = {
'type': tf.keras.Input(shape=(one_hot_dims,), dtype='float32'),
'size': tf.keras.Input(shape=(), dtype='int64'),
'weight': tf.keras.Input(shape=(), dtype='float32'),
}
# Since the embedding is trainable, it needs to be part of the training model.
embedding = tf.keras.layers.Embedding(len(vocab), embedding_dims)
outputs = tf.keras.layers.Concatenate()([
inputs['type'],
embedding(inputs['size']),
tf.expand_dims(inputs['weight'], -1),
])
outputs = tf.keras.layers.Dense(1)(outputs)
training_model = tf.keras.Model(inputs, outputs)이제 tf.keras.Model.fit을 사용하여 training_model을 훈련할 수 있습니다.
# Train on the preprocessed data.
training_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True))
training_model.fit(dataset)3/3 [==============================] - 1s 7ms/step - loss: 0.9916
<keras.callbacks.History at 0x7ff558309b40>마지막으로, 추론할 때 이러한 개별 단계를 원시 특성 입력을 처리하는 단일 모델로 결합하면 유용할 수 있습니다.
inputs = preprocessing_model.input
outputs = training_model(preprocessing_model(inputs))
inference_model = tf.keras.Model(inputs, outputs)
predict_dataset = tf.data.Dataset.from_tensor_slices(predict_features).batch(1)
inference_model.predict(predict_dataset)1/1 [==============================] - 0s 191ms/step
array([[0.880313]], dtype=float32)이렇게 구성한 모델은 나중에 사용할 수 있도록 SavedModel로 저장할 수 있습니다.
inference_model.save('model')
restored_model = tf.keras.models.load_model('model')
restored_model.predict(predict_dataset)WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model.
WARNING:absl:Found untraced functions such as _update_step_xla while saving (showing 1 of 1). These functions will not be directly callable after loading.
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually.
1/1 [==============================] - 0s 357ms/step
array([[0.880313]], dtype=float32)참고: 전처리 레이어는 훈련할 수 없으므로 tf.data를 사용하여 레이어를 비동기식으로 적용할 수 있습니다. 전처리된 배치를 프리페치하고 가속기를 확보하면 모델의 미분 가능한 부분에 집중할 수 있으므로 성능상 도움이 됩니다(자세한 내용은 tf.data API를 사용하여 성능 향상하기 가이드의 프리페치 섹션 참조). 이 가이드에서 알 수 있듯이 훈련하는 동안 전처리를 분리하고 추론하는 동안 구성하는 것은 이러한 성능 향상을 활용하는 유연한 방법입니다. 그러나 모델이 작거나 전처리 시간을 무시할 수 있는 경우에는 처음부터 전처리를 완전한 모델로 구축하는 것이 더 간단할 수 있습니다. 이렇게 하려면 tf.keras.Input으로 시작하는 단일 모델을 빌드한 다음 전처리 레이어, 훈련 가능한 레이어를 빌드하면 됩니다.
특성 열 동등 표
참고로 다음은 특성 열과 Keras 전처리 레이어 사이의 대략적인 대응 관계를 나타낸 표입니다.
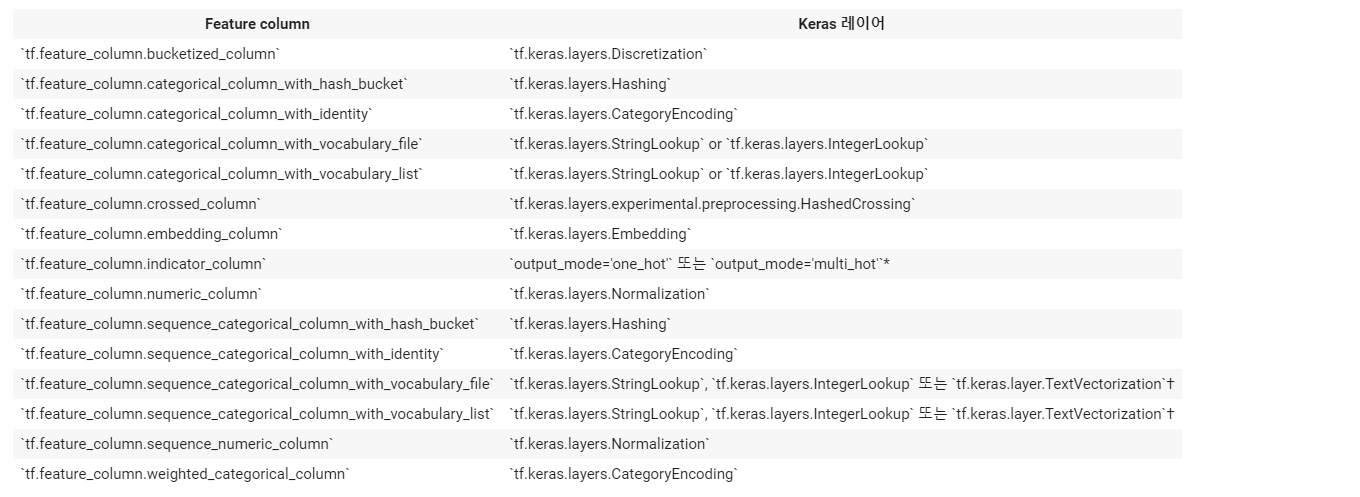
tf.keras.layers.TextVectorization은 자유 형식 텍스트 입력(예: 전체 문장 또는 단락)을 직접 처리할 수 있습니다. 이것은 TensorFlow 1에서 수행하는 범주형 시퀀스 처리에 대한 일대일 대체가 아니지만 애드혹 텍스트 전처리에 대한 편리한 대체를 제공할 수 있습니다.
참고: tf.estimator.LinearClassifier와 같은 선형 Estimator는 embedding_column 또는 indicator_column 없이 직접 범주형 입력(정수 인덱스)을 처리할 수 있습니다. 그러나 정수 인덱스는 tf.keras.layers.Dense 또는 tf.keras.experimental.LinearModel로 직접 전달할 수 없습니다. 이러한 입력은 Dense 또는 LinearModel으로 호출하기 전에 output_mode='count'를 사용하는 tf.layers.CategoryEncoding으로 먼저 인코딩해야 합니다(범주 크기가 큰 경우 sparse=True).
참고: tf.estimator.LinearClassifier와 같은 선형 Estimator는 embedding_column 또는 indicator_column 없이 직접 범주형 입력(정수 인덱스)을 처리할 수 있습니다. 그러나 정수 인덱스는 tf.keras.layers.Dense 또는 tf.keras.experimental.LinearModel로 직접 전달할 수 없습니다. 이러한 입력은 Dense 또는 LinearModel으로 호출하기 전에 output_mode='count'를 사용하는 tf.layers.CategoryEncoding으로 먼저 인코딩해야 합니다(범주 크기가 큰 경우 sparse=True).
다음 단계
- Keras 전처리 레이어에 대한 자세한 정보는 전처리 레이어를 사용하여 작업하기 가이드를 참조하세요.
- 구조화된 데이터에 전처리 레이어를 적용하는 자세한 예제는 Keras 전처리 레이어를 사용하여 구조화된 데이터 분류하기 가이드를 참조하세요.
