
이진 탐색 트리
이진 탐색 트리는 트리를 실제로 사용하기 위해 정의한 구조입니다. 자료구조를 실제로 사용한다는 것은 자료를 저장하고 검색하기 위함을 의미합니다. 이때 특정 기준에 따라서 트리 노드를 정렬하는데 보통 노드의 원소 크기를 기준으로 정렬합니다. 이때 노드의 원소를 우리는 키(key)라고 부르고, 이 값에 따라 탐색 등의 연산을 실행하게 됩니다.
우리는 종종 업 앤 다운 게임을 합니다. 특정 숫자를 부르고 이 숫자보다 특정 숫자가 크면 업, 작으면 다운이라고 말하죠. 이진 탐색 트리의 원리도 같습니다. 특정 원소를 루트 노드로 두고 작으면 왼쪽 크면 오른쪽 가지로 갈라지게 하는 원리를 가지고 있습니다.
이진 탐색 트리를 정의하면 다음과 같습니다.
- 모든 원소는 서로 다른 유일한 키를 가진다.
- 왼쪽 서브 트리의 원소들의 키는 루트 노드의 키보다 작다.
- 오른쪽 서브 트리의 원소들의 키는 루트 노드의 키보다 크다
- 모든 서브 트리들 또한 이진 탐색 트리이다.
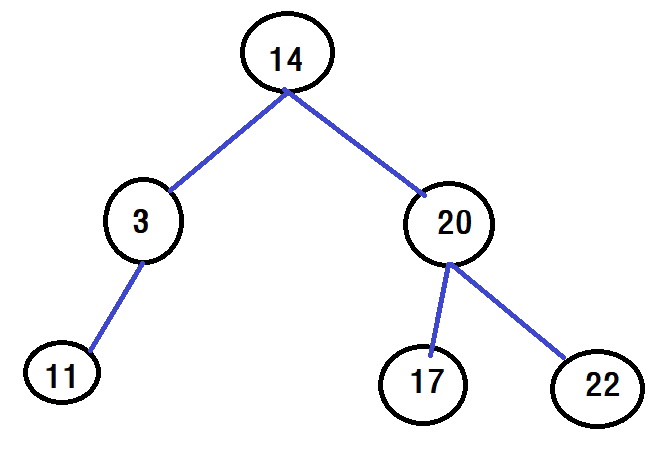
이 정의들을 반드시 기억하시면서 이진 탐색 트리를 구현해보도록 하겠습니다.
이진 탐색 트리 구현
트리 노드 정의
트리 노드는 실제로 활용할 값인 key와 왼쪽 자식 노드, 오른쪽 자식 노드를 가리키는 포인터로 구성됩니다. 용어가 조금 다를 뿐이지 결국 양방향 노드를 사용하겠다는 것 입니다.
typedef struct BinarySearchTreeNode {
int key;
struct binarySearchTreeNode* leftNode;
struct binarySearchTreeNode* rightNode;
} binarySearchTreeNode;노드 삽입
노드를 삽입하는 과정은 간단합니다. 삽입할 노드의 key와 이미있는 트리 노드의 key들을 비교하며 위치를 찾아가는 것이죠. 이때 이진 탐색 트리의 정의에 따라, 작으면 왼쪽, 크면 오른쪽으로 삽입을 진행한다는 것을 반드시 지켜야합니다.
다음은 삽입 연산 구현인데 노드 ptr과 비교해서 x를 삽입하는 삽입 연산입니다.
binarySearchTreeNode* insertNode(binarySearchTreeNode* ptr, int x) {
binarySearchTreeNode* newNode;
if (ptr == NULL) {
//ptr과 같은 값이 없다면 삽입
newNode = (binarySearchTreeNode*)malloc(sizeof(binarySearchTreeNode));
newNode->key = x;
//무조건 마지막 노드이므로 자식 노드는 없습니다.
newNode->leftNode = NULL;
newNode->rightNode = NULL;
return newNode;
}
//삽입 키 x가 ptr보다 작으면 왼쪽 서브 트리로 삽입
else if (x < ptr->key) {
//이때 삽입은 재귀함수를 이용
ptr->leftNode = insertNode(ptr->leftNode, x);
}
//삽입 키 x가 ptr보다 크면 오른쪽 서브 트리로 삽입
else if (x > ptr->key) {
ptr->rightNode = insertNode(ptr->rightNode, x);
}
return ptr;
}삽입 과정인데 재귀함수를 이용해서, 삽입 위치가 아니라면 오른쪽 혹은 왼쪽 서브 트리로 이동한 후 똑같이 삽입 연산을 진행합니다. 그렇게 올바른 위치를 찾을때 까지 재귀로 반복해서 삽입연산을 수행하게 됩니다.
키 값을 통한 탐색
키 값 x를 주고 트리 내에서 탐색을 하는 연산입니다. 삽입과 마찬가지로 x를 루트 노드에서부터 비교해 나가면서 x값이 작으면 왼쪽 서브 트리로, 크다면 오른쪽 서브 트리로 이동해서 일치하는 값을 찾으면 반환합니다. 이때, 모든 노드를 다 돌았을 경우(마지막 자식 노드에 서브 트리가 더이상 존재하지 않아서 다음 주소가 NULL인 경우)에는 탐색을 실패하게 됩니다.
binarySearchTreeNode* searchNode(binarySearchTreeNode* root, int x) {
binarySearchTreeNode* ptr;
ptr = root; //탐색의 시작점은 root노드
while (ptr != NULL) {
if (x < ptr->key) {
ptr = ptr->leftNode;
}
else if (x > ptr->key) {
ptr = ptr->rightNode;
}
else if (x == ptr->key) {
return ptr;
}
}
//만약 while문 내에서 ptr이 반환되지 않는다면 탐색은 실패(찾는 데이터가 트리 내에 없음)
return ptr;
}노드 삭제
이진 탐색 트리에서 삭제 연산은 앞서 본 삽입, 탐색 연산에 비해서 조금 복잡합니다. 삭제 노드가 어떤 상태이냐에 따라서 달라지기 때문이죠. 삭제 연산은 삽입과 마찬가지로 root노드에서 시작해서 key 값과 일치하는 요소를 찾으면 삭제 연산을 진행합니다. 코드가 좀 길기 때문에 몇 부분으로 나누어서 설명 드린 후 전체 코드를 보여드리겠습니다.
우선 삭제를 위해서 key와 일치하는 노드를 찾아야합니다. 그래서 탐색연산을 통해서 탐색을 진행합니다. 이때 ptr이 null이라면 트리 내에 삭제할 노드가 존재하지 않는다는 것이고, 일치하는 키를 찾았다는 것은 노드가 존재해서 삭제 연산을 진행할 차례라는 의미입니다.
parentNode = NULL;
ptr = root;
//ptr은 현재 위치한 노드
while ((ptr != NULL) && (ptr->key != key)) {
parentNode = ptr; //첫 반복시 parentNode는 root노드입니다.
//키 값이 현재 노드 키값보다 작으면 왼쪽으로 진행, 크면 오른쪽으로 진행
if (key < ptr->key) {
ptr = ptr->leftNode;
}
else {
ptr = ptr->key;
}
}
//이때 ptr이 null이라는 것은 삭제할 노드가 트리 내에 존재하지 않는다는 것입니다.
if (ptr == NULL) {
return;
}탐색이 끝났다면 삭제 연산을 진행할 차례인데, 노드의 상황에 따라서 세가지 방법이 있습니다.
삭제할 노드가 단말 노드인 경우
단말 노드, 즉 서브 트리가 0개인 노드를 삭제하는 경우입니다. 이때 부모 노드가 null인 경우가 있는데 이 경우는 트리에 노드가 루트 노드 하나 뿐인 경우를 의미합니다.
if ((ptr->leftNode == NULL) && (ptr->rightNode == NULL)) {
//부모 노드가 null이 아닌 경우
if (parentNode != NULL) {
//삭제 노드가 오른쪽이냐 왼쪽이냐에 따라서 부모 노드의 자식 노드를 null로 만든다
if (parentNode->leftNode == ptr) {
parentNode->leftNode = NULL;
}
else {
parentNode->rightNode = NULL;
}
}
//부모노드가 null인 경우 = 트리에 노드가 하나 뿐인 상태
else {
root = NULL;
}
}삭제할 노드에 자식 노드가 하나 존재할 때
만약 삭제 노드 아래로 자식 노드가 존재한다면 현재 노드를 삭제한 후에 현재 노드의 부모 노드에 현재 노드의 자식 노드를 연결해 주어야합니다.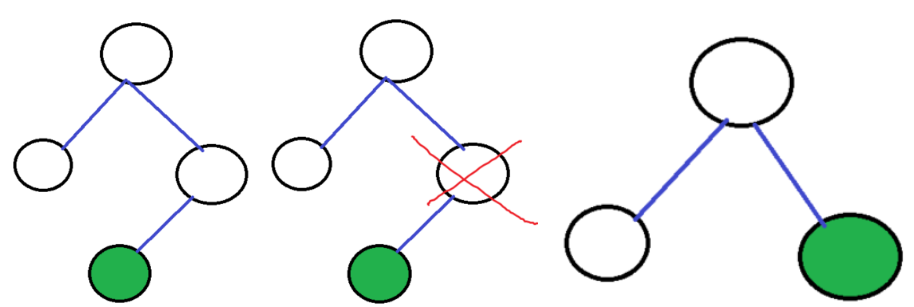
else if ((ptr->leftNode == NULL) || (ptr->rightNode == NULL)) {
//먼저 현재 노드(삭제할 노드)의 왼쪽.오른쪽 자식 노드를 임시 포인터에 저장해두고
if (ptr->leftNode != NULL) {
childNode = ptr->leftNode;
}
else {
childNode = ptr->rightNode;
}
//현재 노드(삭제할 노드)의 부모 노드와 연결해 줍니다.
//이때도 반드시 크기에 따라 왼쪽/오른쪽 규칙이 지켜져야합니다.
if (parentNode != NULL) {
if (parentNode->leftNode == ptr) {
parentNode->leftNode = childNode;
}
else {
parentNode->rightNode = childNode;
}
}
//이 경우는 루트 노드와 자식노드 하나로 이루어진 트리입니다.
//루트 노드를 지웠으니 자식 노드가 루트가 됩니다.
else {
root = childNode;
}
}삭제할 노드의 자식 노드가 2개일 때
마지막 경우는 삭제 대상 노드의 자식 노드가 2개인 경우입니다. 부모 노드에 바로 연결해버리면 좋겠지만, 이진 트리 정의에 따르면 그럴 수 없죠. 그래서 삭제한 노드의 자식 노드들의 키 값에 따라서 맞는 위치를 찾아주고 이어주는 작업이 필요합니다. 여태까지 나온거에 비해 조금 복잡한 구조를 가지고 있습니다. 하지만 잘 보다보면 이 역시도 그렇게 어렵지 않음을 또 느낄수 있습니다.
else {
succParentNode = ptr;
succNode = ptr->leftNode;
//삭제한 노드의 왼쪽 서브트리 중에서 오른쪽 노드가 없는(가장 큰 노드)를 후계자 노드를 찾는 과정
while (succNode->rightNode != NULL) {
succParentNode = succNode;
succNode = ptr->rightNode;
}
//찾아낸 후계자 노드와 삭제할 노드의 부모 노드를 연결합니다.
if (succParentNode->leftNode == succNode) {
succParentNode->leftNode = succNode->leftNode;
}
else {
succParentNode->rightNode = succNode->leftNode;
}
//후계자 노드의 키값을 현재 노드 키값으로 넘기고, 현재 노드를 후계자로 설정한뒤 삭제
ptr->key = succNode->key;
ptr = succNode;
}이때 프로그램상으로 노드를 삭제하고 이어 붙인다는 것이 어렵기 때문에, 현재 노드를 후계자 노드 값으로 바꿔치기하고 후계자 노드를 삭제해서 마치 현재 노드를 삭제한 것 처럼 보여지는 효과를 가집니다. (당연히 삭제도 잘 된 것입니다. 일종의 눈속임)
삭제 연산의 전체 코드는 다음과 같습니다.
void deleteNode(binarySearchTreeNode* root, int key) {
binarySearchTreeNode* parentNode, * ptr, * succNode, * succParentNode, * childNode;
parentNode = NULL;
ptr = root;
while ((ptr != NULL) && (ptr->key != key)) {
parentNode = ptr;
if (key < ptr->key) {
ptr = ptr->leftNode;
}
else {
ptr = ptr->key;
}
}
if (ptr == NULL) {
return;
}
if ((ptr->leftNode == NULL) && (ptr->rightNode == NULL)) {
if (parentNode != NULL) {
if (parentNode->leftNode == ptr) {
parentNode->leftNode = NULL;
}
else {
parentNode->rightNode = NULL;
}
}
else {
root = NULL;
}
}
else if ((ptr->leftNode == NULL) || (ptr->rightNode == NULL)) {
if (ptr->leftNode != NULL) {
childNode = ptr->leftNode;
}
else {
childNode = ptr->rightNode;
}
if (parentNode != NULL) {
if (parentNode->leftNode == ptr) {
parentNode->leftNode = childNode;
}
else {
parentNode->rightNode = childNode;
}
}
else {
root = childNode;
}
}
else {
succParentNode = ptr;
succNode = ptr->leftNode;
while (succNode->rightNode != NULL) {
succParentNode = succNode;
succNode = ptr->rightNode;
}
if (succParentNode->leftNode == succNode) {
succParentNode->leftNode = succNode->leftNode;
}
else {
succParentNode->rightNode = succNode->leftNode;
}
ptr->key = succNode->key;
ptr = succNode;
}
free(ptr);
}이렇게 이진 탐색 트리의 구현이 완료되었습니다. 전체 코드는 GitHub에서 확인하실 수 있습니다.
