Nerual network의 등장 배경
요즘 딥러닝에서 쓰이는 뉴럴 네트워크가 갑자기 생긴 건 아니다.
애초에 사람 뇌처럼 생각하고 학습하는 걸 기계로 흉내 내보자는 시도에서 출발한 거임 .
1. 생물학적 뉴런 모방 -> 인공 뉴런
- 1943년: McCulloch & Pitts가 뇌 뉴런을 수학적으로 모델링한 논문 발표함.
- 기본 개념: 여러 입력이 들어오고, 어떤 임계값을 넘으면 신호를 출력하는 구조.
→ 지금 우리가 쓰는 뉴런 구조도 결국 이 아이디어에서 발전된 거임.
2. 퍼셉트론 (Perceptron)
- 1958년: Rosenblatt이라는 사람이 퍼셉트론 모델 만듦.
- input * weight → sum → 임계값 넘으면 1, 아니면 0 출력
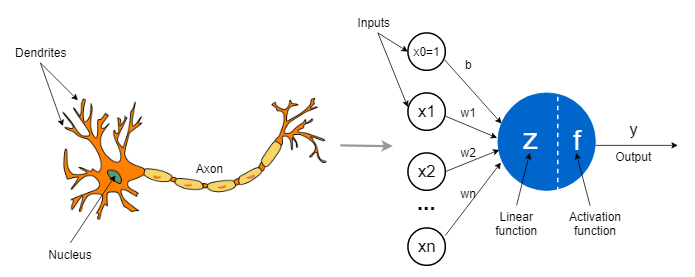
이 모델로 간단한 분류는 가능했지만 XOR 같은 건 못 풀었음.
결국 1970년대에 사람들이 "AI 별 거 없네" 하면서 관심이 식음 → 이른바 AI 겨울.
3. 다층 퍼셉트론 (MLP)
기본 개념
다층 퍼셉트론은 입력에 대해 여러 층을 거치면서 연산을 반복하는 구조임.
각 층에서는 선형 연산 + 비선형 함수 적용을 수행함.
1) 단일 층 (Layer)의 수식
은닉층에서 일어나는 연산:
입력:
가중치:
출력:
- 여기서 는 비선형 활성화 함수 (ReLU, sigmoid 등)
2) 다층 구조 일반화 (L층짜리 MLP)
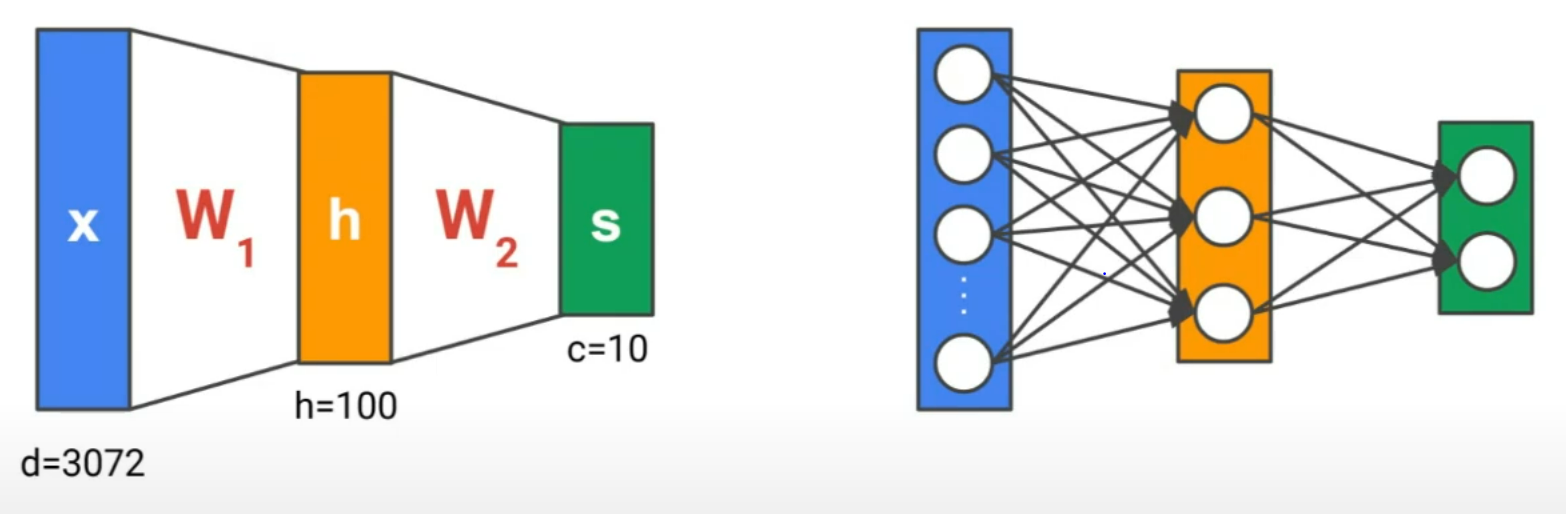
구성 구조
- 입력 x: 차원 d = 3072 (예: 32x32x3 이미지)
- 은닉층 h: 차원 h = 100
- 출력층 s: 차원 c = 10 (예: 클래스 10개 분류)
입력:
첫 번째 가중치 행렬:
두 번째 가중치 행렬:
출력:
3) 선형 MLP의 한계
선형 조합만 쌓으면?
즉, 두 개의 선형 변환을 하나로 합친 것과 같음.
이를 다음과 같이 다시 쓸 수 있음:
결과적으로, 이는 층이 하나인 단일 선형 모델과 구조적으로 동일함.
아무리 선형 변환을 여러 층 쌓아도 비선형성이 없기 때문에
모델의 표현력은 선형 모델을 벗어나지 못함.
그래서 비선형성을 넣어야 함 → 활성화 함수
활성화 함수 를 층 사이에 삽입하면:
- , : 각각의 층에서 쓰이는 비선형 함수 (보통 ReLU)
- 이 구조가 돼야 복잡한 함수 근사 가능 (예: XOR도 해결 가능)
핵심 포인트
- 다층 선형 변환만으로는 여전히 선형임
→ 중간에 비선형 함수(relu, tanh, sigmoid..) 꼭 넣어야 뉴럴 네트워크의 의미가 있다!
4. 역전파 (Backpropagation)
1) 왜 Backpropagation이 필요한가?
딥러닝 모델은 수천~수백만 개의 가중치를 학습해야함.
이 모든 파라미터에 대해 손실 함수을 각각 미분해야 한다면?
너무 많고, 너무 복잡하다.
예를 들어, 다음과 같이 경사하강법을 사용하려면:
모든 파라미터에 대해 다음 미분을 계산해야됨.
이걸 매번 수작업으로 구한다면?
- 계산량이 많고 반복되는 작업이다.
- 실수도 많고 비효율적이다.
그래서 Backpropagation이 등장함
백프로파게이션은 chain rule을 자동화해서
모든 파라미터의 gradient를 한 번의 역전파로 계산하는 알고리즘이다.
오차를 어떻게 뒤로 전달하는가?
딥러닝 모델은 예측한 값과 실제 정답 사이의 오차(loss)를
모든 가중치에 대해서 나눠서 전달해야 한다.
근데 층이 깊어질수록 이게 쉬운 일이 아님…
이때 사용하는 게 바로 Chain Rule이다.
2) Chain Rule이 뭐냐
예를 들어,
이렇게 연결된 연산에서 맨 앞 변수 ( x )에 대해 손실 ( L )을 미분하려면,
즉, 뒤에서부터 gradient가 순차적으로 곱해지면서 전달된다.
이게 백프로파게이션이 작동하는 방식 그 자체임.
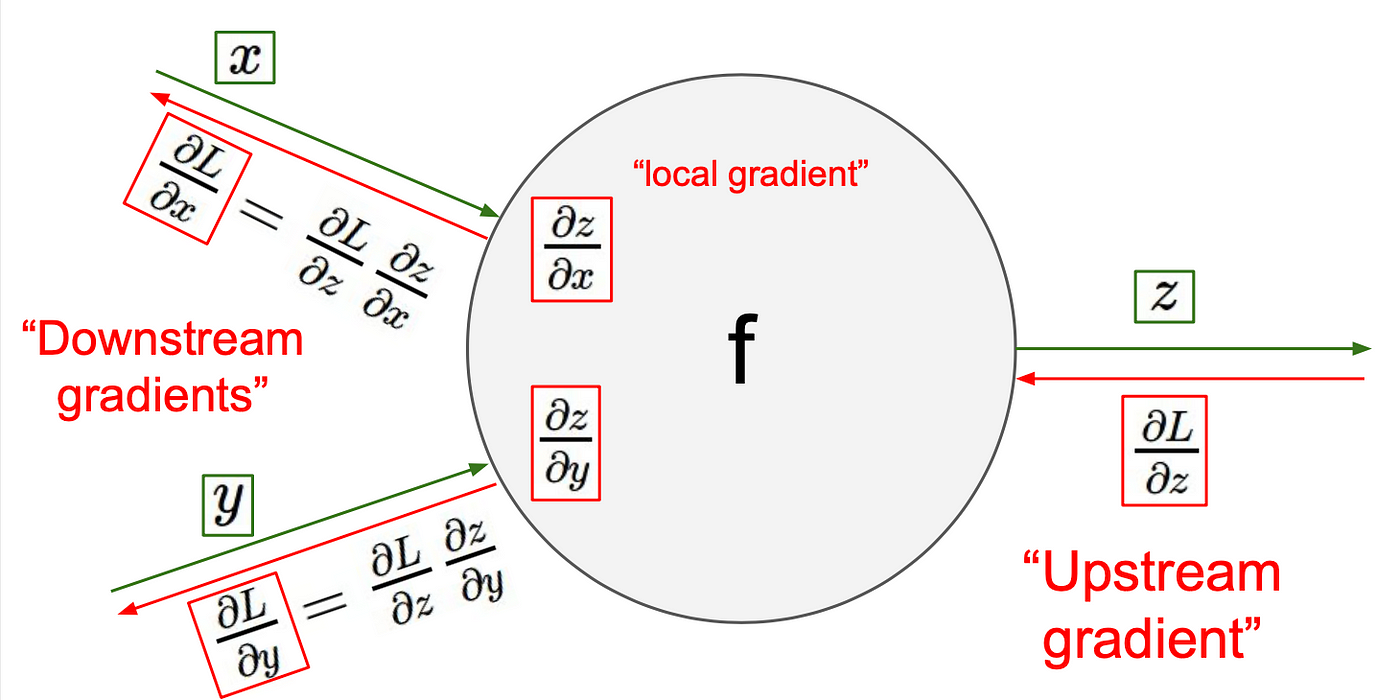
- Upstream Gradient: 뒤쪽에서 오는 오차 → ∂L/∂z
- Local Gradient: 현재 노드에서의 미분값 → ∂z/∂y
- Downstream Gradient: 다음에 넘겨줄 오차 → ∂L/∂y
즉,
Downstream Gradient = Upstream Gradient × Local Gradient
정리
- 각 노드는 자기 위치에서의 미분값(local gradient)만 알면 됨
- 나머지는 뒤에서 온 gradient에 곱해주면 됨
- 그래서 복잡한 미분도 layer마다 나눠서 계산 가능해진다
→ 이게 바로 Backpropagation을 가능하게 만드는 핵심 원리
3) Vector Derivatives – 벡터 미분 정리
백프로파게이션에서 벡터/행렬을 다루다 보면
스칼라 vs 벡터 미분이 헷갈릴 수 있어서 정리해둔다.
1. Scalar → Scalar
x, y 둘 다 스칼라일 때
x가 조금 변하면 y는 얼마나 변하는가?
2. Vector → Scalar
x는 벡터, y는 스칼라일 때
x의 각 성분이 조금 변하면 y는 얼마나 변하는가?
→ 결과는 gradient vector
3. Vector → Vector
x, y 둘 다 벡터일 때
x의 각 성분이 조금 변하면 y의 각 성분은 얼마나 변하는가?
→ 결과는 야코비안 행렬 (Jacobian matrix)
요약
- Scalar → Scalar → 그냥 미분
- Vector → Scalar → gradient (벡터)
- Vector → Vector → Jacobian (행렬)
→ 백프로파게이션은 대부분 Vector → Scalar 구조
→ 자동 미분 구현도 이걸 기반으로 작동
