딥러닝
1.Neural Networks and Backpropagation
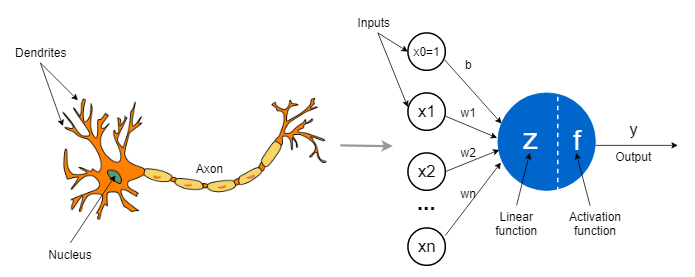
Nerual network의 등장 배경 요즘 딥러닝에서 쓰이는 뉴럴 네트워크가 갑자기 생긴 건 아니다. 애초에 사람 뇌처럼 생각하고 학습하는 걸 기계로 흉내 내보자는 시도에서 출발한 거임 . 1. 생물학적 뉴런 모방 -> 인공 뉴런 1943년: McCulloch & Pitts가 뇌 뉴런을 수학적으로 모델링한 논문 발표함. 기본 개념: 여러 입력이 들어...
2.합성곱 신경망 (CNN, Convolutional Neural Network)
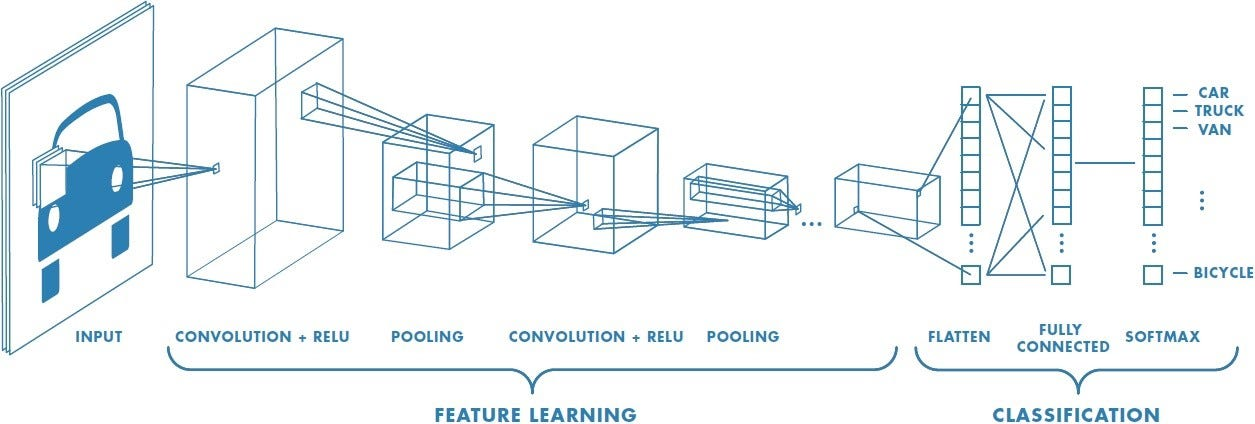
CNN의 핵심 개념과 구조 이해 Fully Connected Layer란? 딥러닝에서 처음 배우는 구조는 Fully Connected Layer (FC Layer) 모든 입력 뉴런이 모든 출력 뉴런과 연결돼 있어서, 말 그대로 완전 연결. 입력이 벡터고 출력도
3.Training Neural Networks I
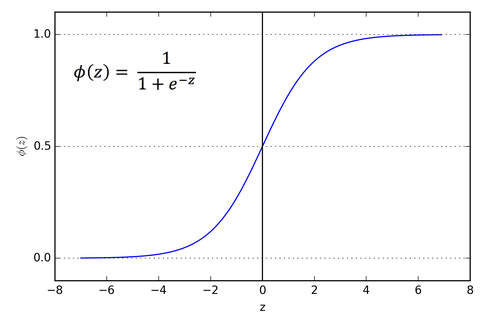
출력 범위: 0 ~ 1직관적인 출력Gradient vanishing→ 입력값이 크면 기울기 0 근처로 수렴Not zero-centered→ 항상 양수 출력 → gradient가 한쪽 방향만 흐름 입력이 항상 양수면$$ \\frac{\\partial L}{\\parti
4.Training Neural network II

딥러닝 Regularization & Optimization 1. Regularization(정규화) > 목적 : 딥러닝은 overfitting에 취약하기에 additional penalty term을 목적 함수에 추가하여 가중치를 작거나 0으로 만듦. 예시: L
5.Sequential Data & Recurrent Neural Networks I
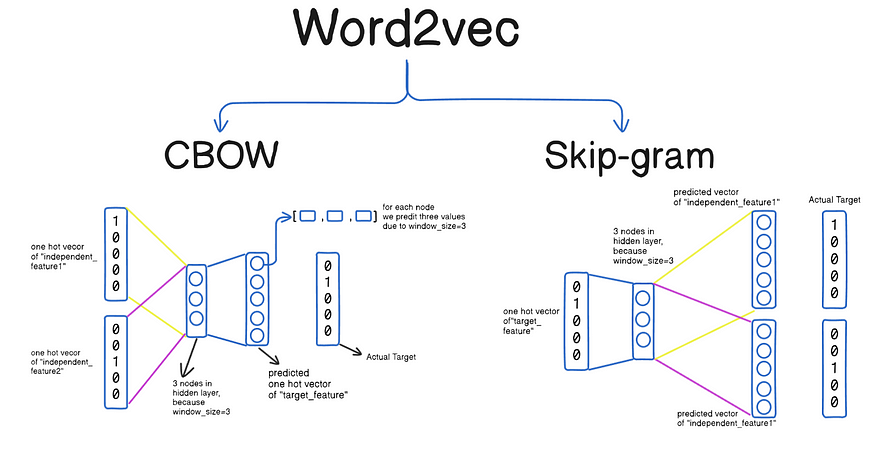
순서(temporal order)가 중요한 데이터 예: 문장, 오디오, 주가, 센서 로그 Target $y$ 시퀀스인지(=sequence-to-sequence) or 스칼라인지(=sequence-to-one)는 task에 따라 달라짐 단어를 $d$-차원 유클리디
6.Recurrent Neural Networks II (LSTMs & Seq2seq Models)
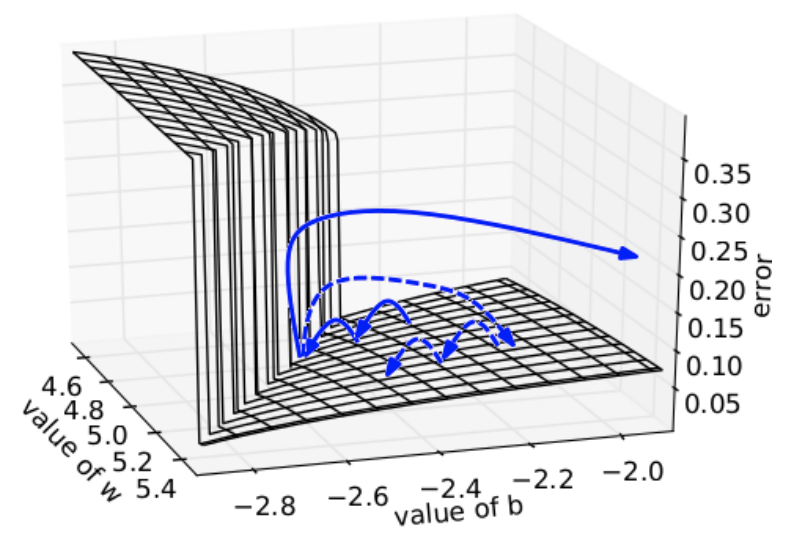
RNN의 문제와 해결책 정리 1. RNN의 핵심 문제: Exploding / Vanishing Gradient Backpropagation Through Time (BPTT) RNN의 순전파는 다음과 같다: $$ ht = \tanh(W{hh} h{t-1}
7.Attention Mechanism & Transformers I
RNN의 한계와 Attention, Transformer의 등장 1. RNN의 근본적인 한계 RNN은 시퀀스를 순차적으로 처리하기 때문에 기억 용량에 제한이 있음 과거 정보가 시간이 지날수록 사라짐 → Long-Term Dependency 문제 예를 들어, 입력 문
8.Transformers II
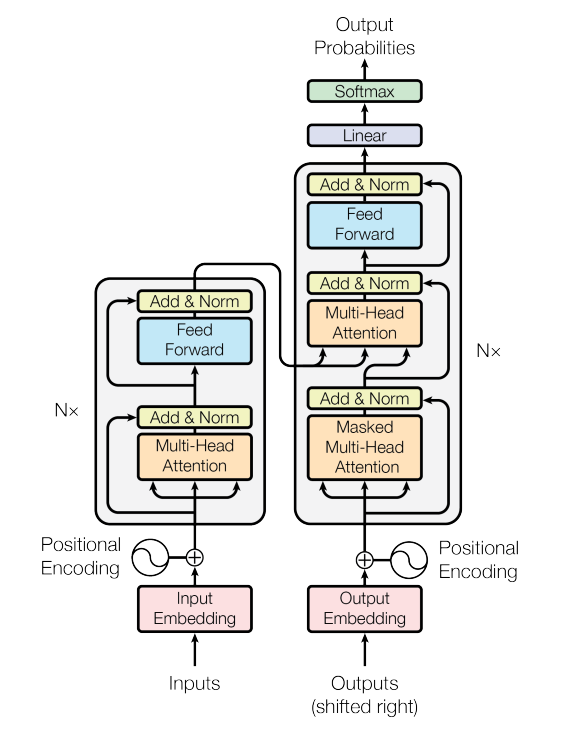
입력은 시퀀스 of 토큰각 토큰은 임베딩 벡터로 변환추가적으로 포지셔널 인코딩을 더해 순서를 고려$$\\textbf{Embedding} + \\textbf{Positional Encoding}$$Multi-Head Attention(self-attention)각 토큰을