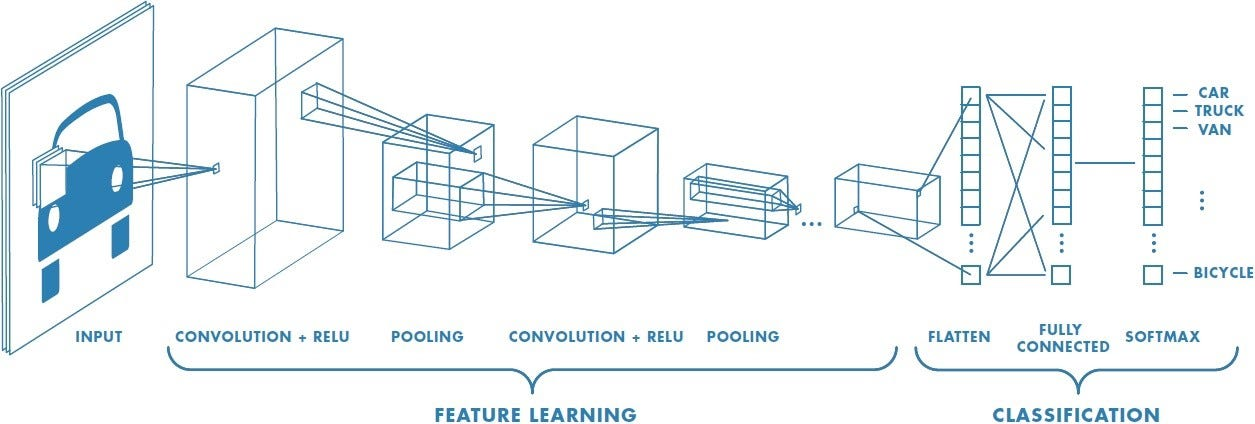
CNN의 핵심 개념과 구조 이해
Fully Connected Layer란?
딥러닝에서 처음 배우는 구조는 Fully Connected Layer (FC Layer)
모든 입력 뉴런이 모든 출력 뉴런과 연결돼 있어서, 말 그대로 완전 연결.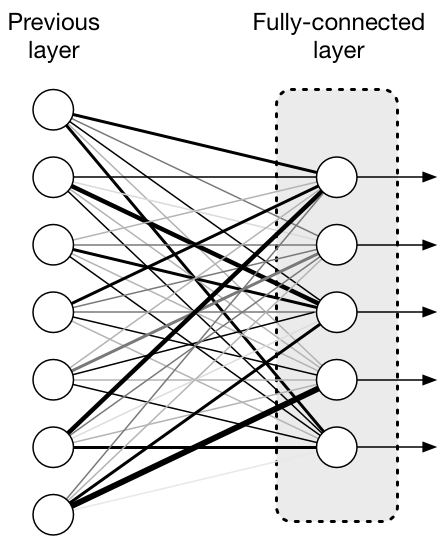
- 입력이 벡터고 출력도 벡터. 각 출력은 전체 입력을 다 본다.
- 수식으로는:
- 이미지처럼 2D 구조가 있는 건 평탄화(flatten)해서 1D로 바꾼 뒤 사용
근데 이게 문제임
- 위치 정보 다 날아감
- 입력 크기 커지면 파라미터 수 폭발함
→ 그래서 이미지엔 CNN이 훨씬 좋음
CNN (Convolutional Neural Network)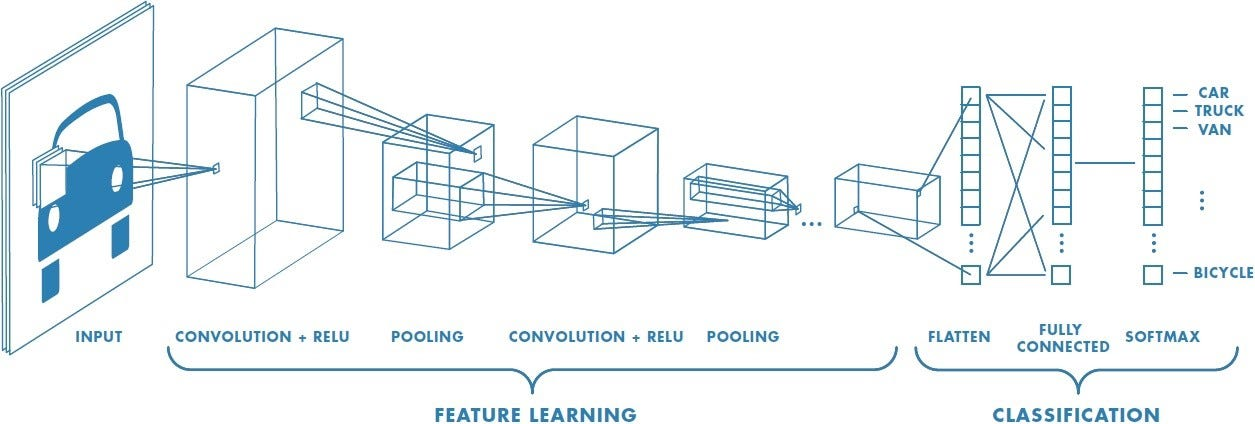
CNN은 이미지처럼 공간 구조가 있는 데이터를 처리하는 데 특화된 모델.
입력 전체를 한 번에 보는 게 아니라 작은 패치(부분 영역)만 보면서 처리함.
특징 추출(feature/learning) 영역은 convolution layer와 pooling layer를 여러 겹 쌓는 형태로 구성됨. convolution layer는 입력 데이터에 필터를 적용 후 활성화 함수를 반영하는 필수적인 요소임.
마지막 부분에는 이미지 분류를 위한 Fully connected layer가 추가됨.
각 layer가 어떤 동작을 하는지 보자.
CNN이 전제하는 두 가지 핵심 가정
1. Spatial Locality (공간 국소성)
- 이미지에서 의미 있는 패턴(예: 눈, 입)은 주변 픽셀끼리 모여 있음
- CNN은 이런 국소 패턴을 감지하기 위해 필터를 작게 만듦
- 각 필터는 이미지의 일부분(local patch)만 봄
예: 눈을 찾으려면 전체 이미지 다 볼 필요 없고, 눈 주변만 보면 됨
2. Positional Invariance (위치 불변성)
- 같은 필터를 이미지 전체에 똑같이 적용
- 눈이 왼쪽 위에 있든 오른쪽 아래에 있든 똑같이 인식 가능
근데 의료 영상처럼, 장기가 항상 같은 위치에 있는 경우엔 이 가정이 안 맞을 수도 있음
Convolution Layer
작동 방식 요약
- 입력 이미지에서 작은 영역(Patch)을 자름
- 필터(커널)랑 곱하고
- 결과를 전부 더해서 하나의 값으로 만듦
- 이걸 전체 이미지에 슬라이딩하면서 반복
→ 이렇게 나온 값들이 Feature Map!
Convolutional Layer에서는 여러 개의 필터(filter)를 사용할 수 있고,
각 필터는 입력 이미지에 동일한 연산을 수행하지만 학습된 가중치(weight)가 다름.
이렇게 필터를 적용한 결과를 Activation Map (또는 Feature Map)이라고 부름.
예시 문제
Q. 입력 이미지가 일 때,
필터 4개를 적용하면
출력 activation map의 크기는?
풀이
- 입력 크기:
- 필터 크기:
- 필터 개수: 4개
- 패딩: 없음 (valid)
- 스트라이드: 1
출력 크기 계산 공식 (정수 나와야 함)
입력: , 필터: , 스트라이드: , 패딩:
-
, ,
-
따라서 각 activation map 크기:
-
필터가 4개 → 출력의 depth는 4
최종 출력 크기
파라미터 수 공식:
- F_H, F_W: 필터의 높이와 너비
- C_in: 입력 채널 수
- C_out: 출력 채널 수 (필터 개수)
- +1: bias (필터마다 1개씩)
Stride란?
필터가 입력 이미지 위를 얼마나 멀리 이동하느냐를 의미!
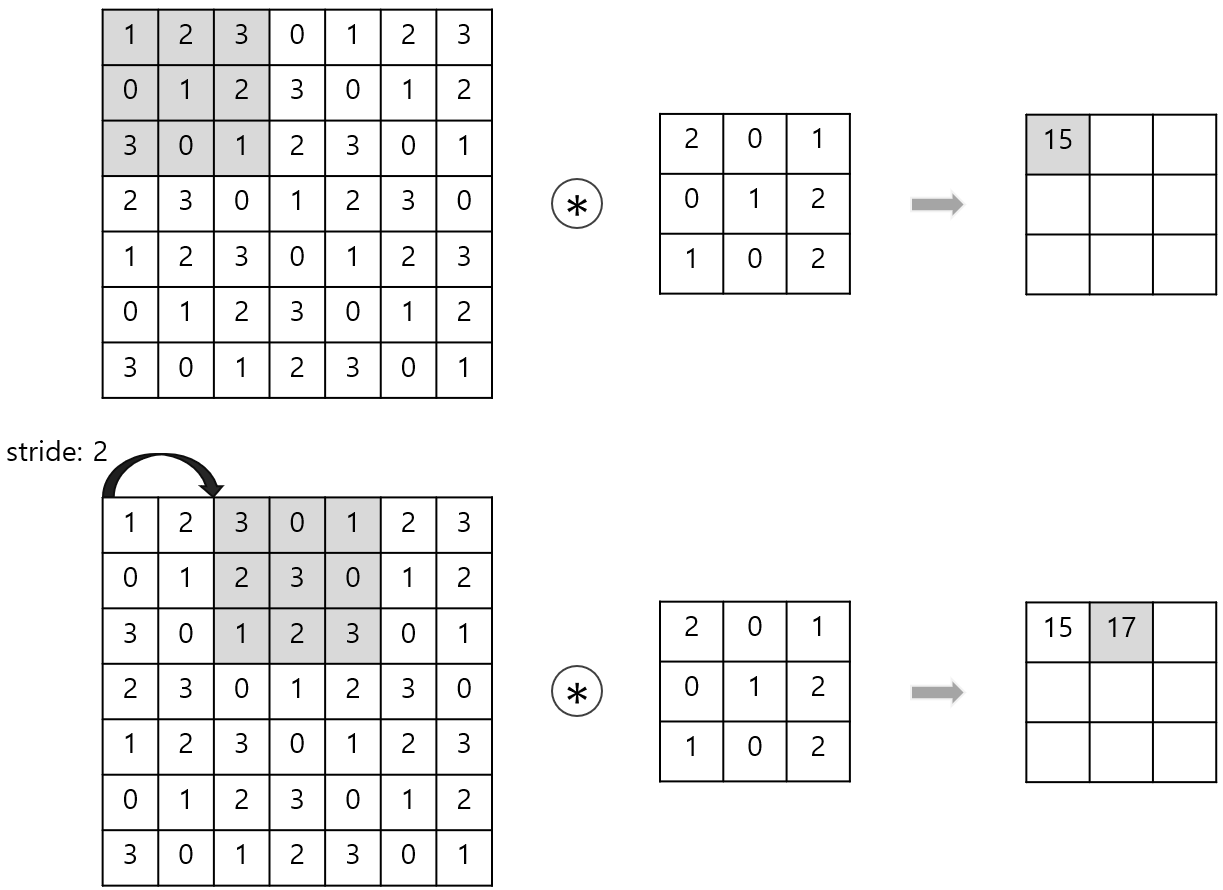
- 기본적으로 Stride = 1일 경우, 필터는 한 칸씩 움직임
- Stride가 커지면 → 더 빠르게 이동 → 출력 크기 작아짐
- Stride는 downsampling 효과를 만들어냄
| Stride 값 | 필터 움직임 설명 |
|---|---|
| 1 | 모든 위치에 적용 (촘촘하게) |
| 2 이상 | 일부 위치만 적용 (성긴 적용) |
Padding이란?
입력의 가장자리 정보 손실을 막기 위해 입력 주변에 0을 추가하는 것!
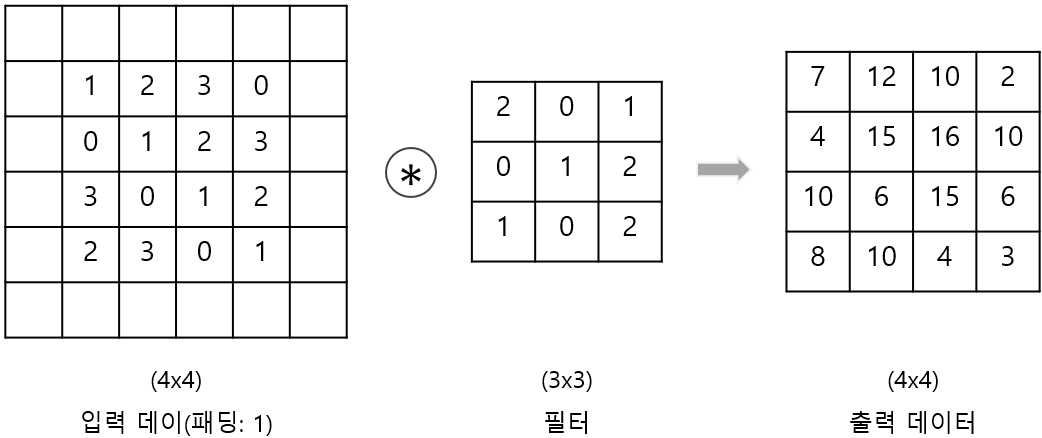
- CNN에서 필터를 적용할 때 가장자리를 살리기 위해 사용
- 출력 크기를 입력과 동일하게 유지할 수도 있음
| 종류 | 설명 |
|---|---|
| Valid | 패딩 없음 → 출력 크기 작아짐 |
| Same | 패딩 추가 → 출력 크기 유지됨 |
Nested Convolutional Layers란?
CNN에서는 Convolution Layer를 여러 층 쌓아서 점점 더 복잡한 특징을 추출하는 구조로 발전시킵니다. 이를 Nested Conv Layers, 즉 중첩된 합성곱 층이라 부르기도 함.
왜 여러 층을 쌓을까?
하나의 필터만으로는 이미지의 로우레벨 정보(선, 모서리)만 추출할 수 있음!
하지만 이를 반복적으로 쌓으면 점점 더 복잡하고 추상적인 정보를 학습하게 됨.
Feature Hierarchy
CNN이 층을 거치며 학습하는 특징들:
| Layer Depth | 추출하는 특징 |
|---|---|
| 1~2층 | Edge, Texture 같은 Low-level feature |
| 3~4층 | Shape, Object part 같은 Mid-level feature |
| 5층 이상 | Face, Object 같은 High-level feature |
예시: 고양이 이미지 분류
이미지를 Conv Layer 여러 층을 통해 아래처럼 처리함:
- 첫 번째 Conv Layer → 수직/수평 선 검출
- 두 번째 Layer → 귀, 눈, 수염 등의 부위 검출
- 세 번째 Layer → 고양이라는 전체적인 패턴 인식
- Fully Connected Layer → 고양이인지 아닌지 분류!
Fully Connected vs Convolution Layer
| 항목 | Fully Connected Layer | Convolution Layer |
|---|---|---|
| 연결 | 전부 다 연결 | 일부만 연결 (국소 영역) |
| 파라미터 | 많음 | 적음 |
| 위치 정보 | 못 씀 | 사용 가능 |
| 용도 | 일반적인 분류기 | 이미지 특화 |
CNN은 FC Layer의 특수한 형태라고도 볼 수 있음 (Conv 크기를 조절하면 FC처럼 만들 수 있음)
Pooling Layer
CNN에서 Pooling Layer는 Feature Map의 크기를 줄이고, 불필요한 정보를 제거하는 역할을 함.
목적
- Spatial Size(공간 크기)를 줄여서 연산량 감소
- 노이즈 제거 및 과적합 방지
- 중요한 특징만 요약해서 다음 계층으로 전달

| 종류 | 설명 |
|---|---|
| Max Pooling | 영역 내에서 가장 큰 값을 선택 |
| Avg Pooling | 영역 내의 평균 값을 선택 |
일반적으로 Max Pooling이 더 자주 사용.
마무리: CNN 요약 정리
CNN은 Convolution Layer와 Pooling Layer를 반복적으로 사용하면서
입력 이미지에서 의미 있는 특징(feature)을 추출하고,
이후 Fully Connected Layer로 전달하여
최종적으로 분류(Classification)를 수행하는 구조.
- Convolution: 필터를 통해 지역적인 특징 추출
- Pooling: 특징을 유지하면서 크기를 줄이고, 노이즈 제거
- Flatten & FC: 추출된 feature를 1차원으로 펼쳐서 클래스 분류
즉, CNN은 이미지에서 학습 가능한 특징을 자동으로 추출하고
그것을 바탕으로 의사결정을 내릴 수 있도록 학습되는 구조이다.
