Transformer 구조
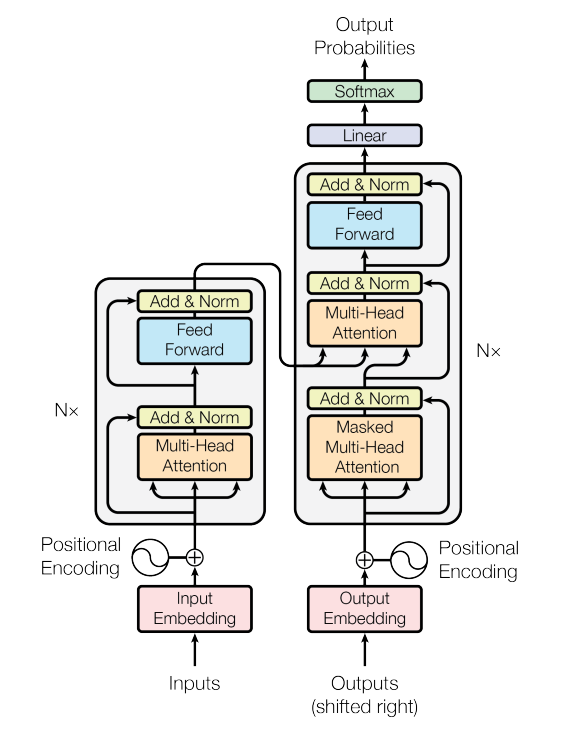
Input Embedding
- 입력은 시퀀스 of 토큰
- 각 토큰은 임베딩 벡터로 변환
- 추가적으로 포지셔널 인코딩을 더해 순서를 고려
Contextualizing the Embedding
- Multi-Head Attention(self-attention)
- 각 토큰을 여러 개의 weight(Head)로 표현
- , , 생성 후:
- 여러 Head의 결과를 Concatenate
- Feed-Forward Layer
- 각 토큰별로 독립적인 FC Layer 적용
서로 다른 토큰들과 연계되지 않고 자기 표현만 바꿀 수 있도록
- 각 토큰별로 독립적인 FC Layer 적용
- Residual Connection + Layer Normalization
- 안정적 학습을 위해 추가
- 위 과정을 N번 반복
Positional Encoding
- 순서를 인코딩해 모델이 위치 정보를 알도록 함
Decoder (Output 생성부)
Decoder는 Auto-Regressive 방식으로 출력 시퀀스를 한 토큰씩 생성함.
즉, 이전에 생성한 토큰들을 바탕으로 다음 토큰을 예측하는 구조.
구성 요소
-
Masked Multi-Head Self Attention
- Decoder 내부에서 이전 출력 토큰들을 참조할 수 있도록 함
- 하지만 현재 시점 이후의 정보는 보지 못하도록 Masking 처리
- 예를 들어 일 때는 까지만 보고 는 보지 못함
- 수식은 Encoder와 동일하지만, Upper Triangular Mask 적용됨
-
Encoder-Decoder Attention
- 현재까지 생성한 Decoder 쿼리(Query)와
Encoder에서 나온 Key, Value를 사용하여 원문 인코딩 결과를 참조 - Query는 Decoder에서, Key/Value는 Encoder에서 가져옴
- Mask는 사용하지 않음 (원문을 모두 참조해야 하므로)
- 현재까지 생성한 Decoder 쿼리(Query)와
-
Feed Forward Layer
- Encoder와 동일한 구조의 Point-wise Fully Connected Layer
- 각 토큰에 대해 독립적으로 작동
-
Residual Connection + Layer Normalization
- 각 Attention Layer와 FeedForward Layer 뒤에 추가되어
안정적인 학습 및 Gradient 흐름 유지
- 각 Attention Layer와 FeedForward Layer 뒤에 추가되어
전체 Decoder 흐름
- 이전까지 생성된 출력 토큰 시퀀스를 임베딩 + 포지셔널 인코딩
- Masked Multi-Head Attention으로 미래 정보 차단
- Encoder의 Key/Value로 Encoder-Decoder Attention 수행
- Feed-Forward Layer로 최종 토큰 표현 정제
- 최종 출력은 Linear Layer + Softmax를 거쳐 다음 토큰 확률 분포로 변환
- Auto-regressively 반복하며 전체 시퀀스 생성
Output Decoding 방식
- Greedy Decoding: 매 시점에서 확률 가장 높은 토큰 선택
- Beam Search: 가능한 시퀀스 후보들을 여러 개 유지하며 탐색
- Top-k / Top-p Sampling: 확률 분포 상위 k개만 고려하거나 누적 확률이 p 이상이 될 때까지 샘플링
Token Aggregation
- 전체 시퀀스를 하나의 벡터로 표현
- 평균:
- CLS Token: 시퀀스 전체 표현을 위해 더미 토큰 추가
- Sequence-Level Task (분류, 회귀): CLS에 Classifier 연결
- Token-Level Task (NER 등): 각 스텝에 Classifier 연결
- 평균:
