1. RNN의 근본적인 한계
- RNN은 시퀀스를 순차적으로 처리하기 때문에 기억 용량에 제한이 있음
- 과거 정보가 시간이 지날수록 사라짐 → Long-Term Dependency 문제
- 예를 들어, 입력 문장의 앞부분 정보가 뒤쪽 단어를 예측할 때 중요하지만, 잘 반영되지 않음
→ 단기적인 문맥은 잘 반영되지만, 장기 의존성은 학습이 어려움
2. Attention의 등장
기본 아이디어
"과거 전체 정보를 한 벡터에 압축하지 말고, 필요한 정보를 골라보자"
- 인코더의 모든 hidden state를 저장해두고
- 디코더가 출력할 때마다 어느 부분을 참조할지 선택하도록 함
- 이 선택 과정을 Attention Mechanism이라 부름
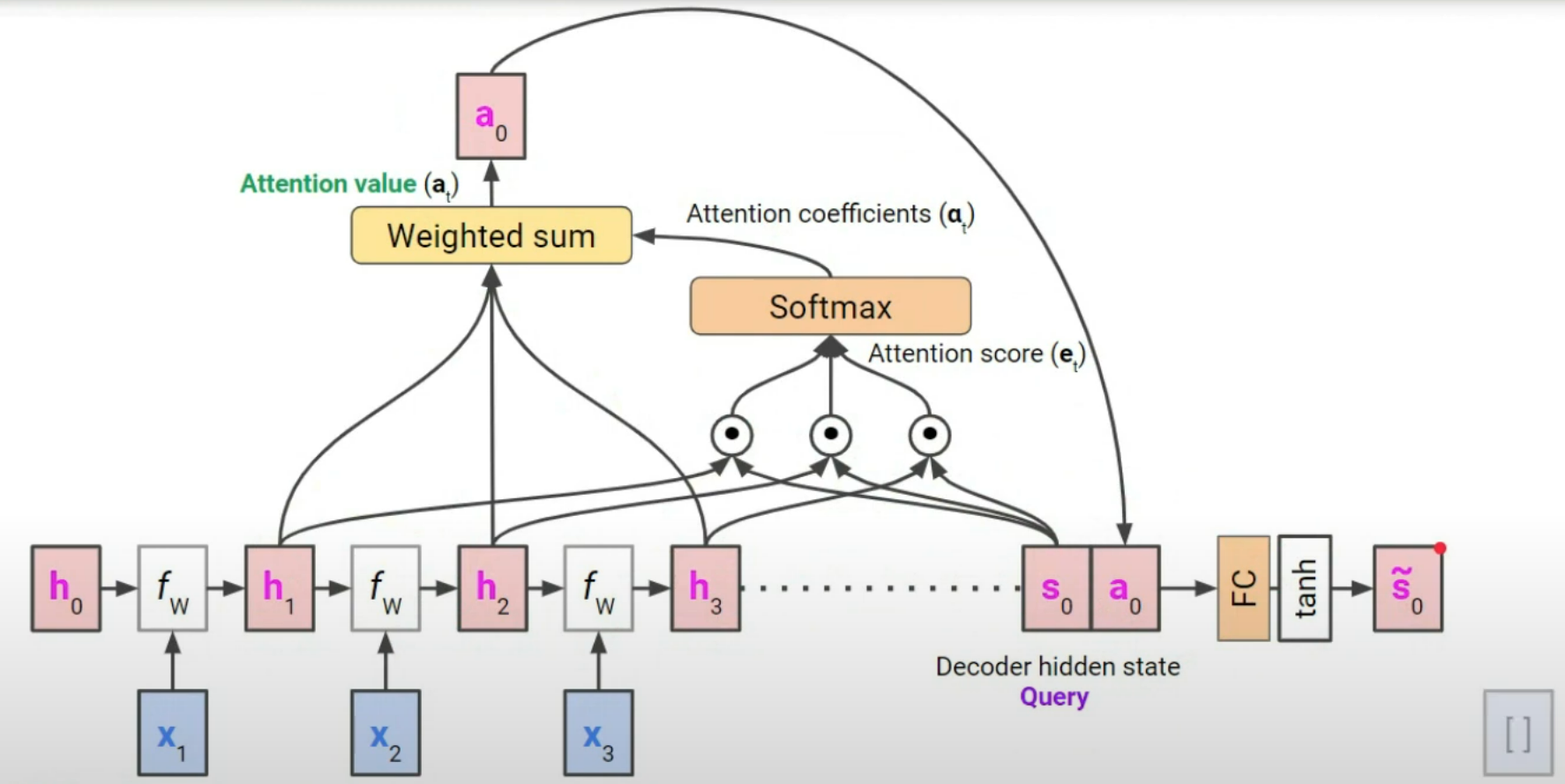
3. Attention의 구성 요소 (Query, Key, Value)
| 이름 | 역할 |
|---|---|
| Query () | 현재 디코더 상태 (어떤 정보를 찾고 싶은지) |
| Key () | 인코더 hidden state들 (참조 대상의 "주소") |
| Value () | 인코더 hidden state들 (참조 대상의 "내용") |
Key와 Value는 보통 동일한 인코더 hidden state에서 만들어짐
Attention 작동 순서
- 디코더의 현재 상태 → Query로 사용
- 인코더 hidden state들 () → Key, Value로 사용
- Query와 각 Key의 유사도(예: dot product)를 계산 → Attention score
- Softmax로 score를 확률로 변환 → 가중치
- Value와 가중치를 곱해 가중합(weighted sum) → Attention value
- 이 값을 현재 디코더 입력과 함께 사용
- FC를 통해 원래 크기로 돌아갈 수 있도록 해줌
4. Dot-Product Attention 공식 정리
1. 입력 정의
- 인코더 hidden states:
- 디코더의 현재 hidden state (query):
2. Attention Score 계산 (유사도 점수)
디코더 상태 와 인코더 각 hidden state 사이의 dot product로 attention score 계산:
는 디코더가 현재 시점에서 각 인코더 위치를 얼마나 중요하게 여기는지를 나타냄
3. Softmax로 Attention Weight 생성
score를 softmax에 통과시켜 가중치(=attention coefficient) 생성:
4. Attention Value 계산 (가중합)
각 인코더 hidden state 에 가중치 를 곱해 합산:
→ 디코더가 인코더에서 얻은 context vector
5. 디코더 입력으로 연결
디코더의 현재 상태 와 attention value 를 연결(concat):
이후 이 결합 벡터를 FC (fully connected layer)나 LSTM 디코더의 다음 입력으로 사용
5. Transformer의 핵심: Self-Attention과 Contextual Representation
1. 기본 아이디어
Transformer는 입력 시퀀스를 구성하는 각 요소(=토큰)들이 서로를 참고해서 자기 자신을 표현하는 구조다.
- 예시:
- 사회라는 전체 시스템 안에 개별 사람
- 문단이라는 구조 안에 각 단어
- 영상이라는 데이터 안에 각 프레임
이처럼 전체는 개별 요소들의 상호작용으로 표현될 수 있다
→ 이 상호작용을 Self-Attention으로 모델링
2. Self-Attention: 내 주변을 보고 나를 표현한다
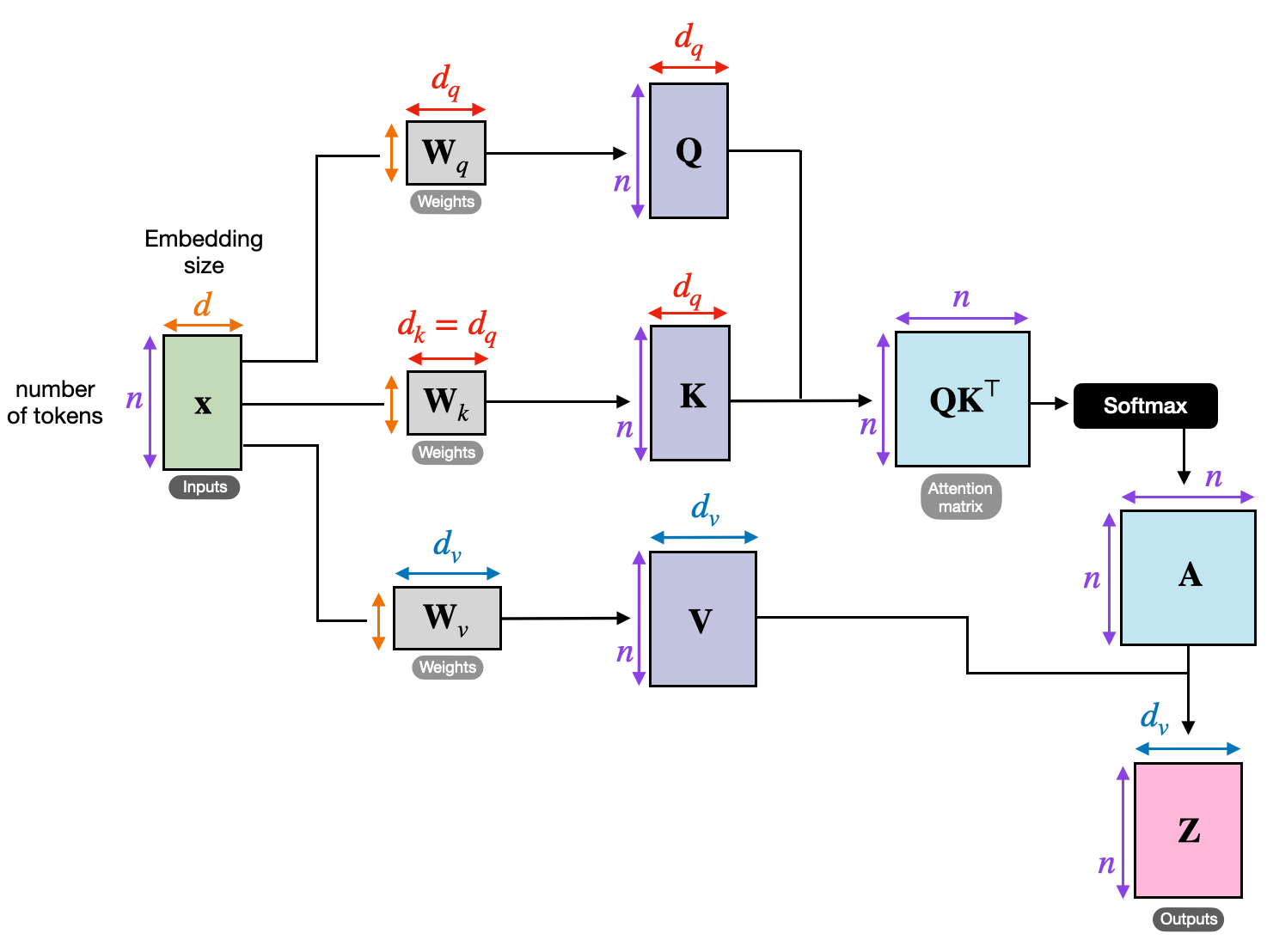
Self-Attention의 입력 변환 단계: Q, K, V 생성
입력 시퀀스 정의
입력 토큰:
( n ): 시퀀스 길이 (토큰 개수)
( d ): 각 토큰의 임베딩 차원
i번째 토큰 벡터
Q, K, V로 변환하기
각 토큰 벡터 ( Xi )는 다음과 같은 학습 가능한 weight 행렬을 통해 Query, Key, Value로 각각 변환:
이 weight들은 모든 토큰에 대해 공통적으로 학습되며 공유됨.
변환 결과 차원 정리
- 입력:
- 결과:
즉, 입력 시퀀스의 각 토큰은 서로 다른 용도로 Query, Key, Value로 분리되어 표현됨.
왜 이렇게 나누는가?
- Query는 "지금 내가 무엇을 알고 싶은가"
- Key는 "나는 어떤 정보를 갖고 있는가"
- Value는 "내가 실제로 줄 수 있는 정보"
→ Self-Attention은 각 토큰이 다른 토큰의 정보를 얼마나 참고할지 동적으로 조절하기 때문에, 이 세 가지 벡터로 역할을 분리하는 것이 핵심.
3. Self-Attention 계산 과정
Q, K, V 만들어놓고 이제 연산 들어감.
1) Query랑 Key로 유사도 점수 계산 (attention score)
- 각 토큰의 쿼리 벡터 ( q_i )랑 모든 키 벡터 ( k_j )들이 dot product로 유사도 계산
- 즉, ( q_i \cdot k_j )
→ 이걸로 시퀀스 안에서 누가 나한테 중요한지 점수 매기는 느낌
2) 스케일링
- dot product 값 너무 커지면 softmax 터지니까 안정화를 위해 나눠줌
3) softmax로 가중치 만들기
- 위에서 계산한 점수들을 softmax로 바꿔서 확률처럼 만듦
→ 여기서 aij는 나(i)가 j번 토큰을 얼마나 참고할지를 의미
4) value들이랑 곱해서 가중합
- value들 ( v_j )이랑 softmax 결과 aij 곱해서 다 더하면
→ 최종적으로 나(i)를 문맥 반영해서 표현한 벡터 ( z_i ) 나옴
4. 행렬 연산으로 한 번에 쓰면
전체 시퀀스에 대해 계산하면 아래처럼 정리됨:
- ( Q, K, V ): 각각 ( n \times d )
- ( Z ): 최종 출력, 문맥 반영된 벡터 모음
요약
- Q랑 K로 유사도 점수 구하고
- softmax로 가중치 만들고
- V랑 곱해서 문맥 벡터 뽑고
- 그게 ( Z ), 최종 결과
→ ( x_i ) 하나짜리 토큰을 주변 맥락 정보랑 섞어서 ( z_i )로 바꾸는 과정
→ 이걸로 '문맥화된 벡터' 만들어내는 게 self-attention 핵심
