논문: https://pmc.ncbi.nlm.nih.gov/articles/PMC7334686/
학습자의 과거 성과를 기반으로
특정 시점에서 추천이 필요한 학습자를 능동적으로 구별하는 기능
1. INTRODUCTION
동적 그래프 기반 지식 추적(dynamic graph-based knowledge tracing) 접근법에서 시계열 노드 분류(time-series node classification)를 제안한다.
- 동적 그래프 기반 지식 추적 접근법은 'Adaptive neural network for node classification in dynamic networks'에서 제안되었다.
-
학습자를 노드로 모델링하여, 특정 지식 개념을 기반으로 학습자를 그래프에서 그룹화한다. 이 과정에서 노드와 그래프의 토폴로지는 학습자의 지식 추적에 맞춰 시간에 따라 변화한다.
- Gated Recurrent Unit(GRU) 네트워크와 Attention Neural Network(ANN)을 활용하여, 노드로 표현된 학습자와 그 이웃 노드의 정보를 집계해 특징 표현(feature representation)을 학습하고, 각 시간 단계에서 네트워크의 토폴로지 정보를 추출한다.
- GRU(Gated Recurrent Unit)는 LSTM의 간소화된 버전이다.
2. PROPOSED APPROACH
Problem Definition
지도 학습 기반 노드 분류(supervised node classification)
-
강의 내용을 로 구조화했으며, 여기서 는 시간 단계(time steps)의 수를 나타낸다. 는 시간 단계 에서의 그래프이자, 노드 집합 를 포함한 그래프를 의미한다. 는 그래프 내 학습자/노드의 수를 나타낸다.
-
노드(학습자)들은 특정 지식 개념 를 의존 관계로 공유하며, 는 개의 존재하는 지식 개념으로 구성된다.
-
는 노드 간 연결을 설명하는 인접 행렬(adjacency matrix)로, 은 시간 에 노드 와 가 공유하는 지식 개념 가 있음을 나타내고, 연결이 없으면 으로 표시된다.
-
는 노드 속성 행렬(node attribute matrix)로, 는 학습자를 표현하는 속성(feature)의 차원 수입니다.
-
시간 단계에 따라 와 는 변화하지만, 와 는 모든 시간 단계에서 고정된다.
Dynamic Graph Based Knowledge Tracing
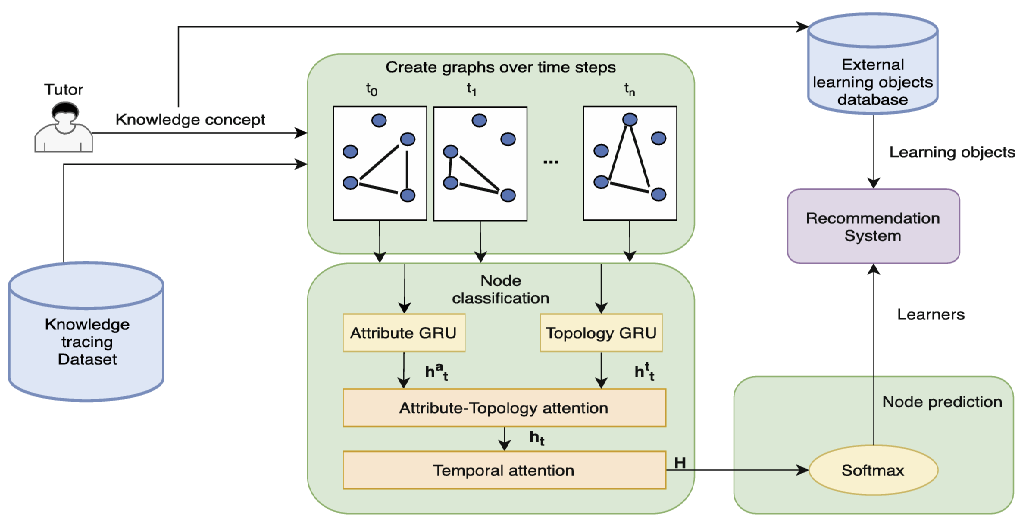
-
먼저, 튜터는 사용할 지식 개념을 선택한다. 지식 추적 데이터셋은 시간 단계에 따라 변화하는 동적 그래프로 변환되며, 각 노드는 학습자를 나타내고 학습자의 이전 지식에서 추출 및 집계된 속성 특징(attribute features)을 포함한다. 생성된 그래프의 모든 학습자는 교사가 선택한 동일한 지식 개념을 공유한다.
-
동적 그래프에서의 노드 분류(Node Classification) 아이디어는 네트워크 구조 정보와 노드 속성 정보를 통합하는데 있다. 이를 위해 두 개의 GRU(Gated Recurrent Unit) 네트워크(A-GRU와 T-GRU)를 사용한다.
-
Attention Neural Network를 통해 관련 노드 정보를 캡처하고 중요한 이웃 노드들을 집계합니다. 이웃 표현(neighbour representation)과 이전 상태의 노드 특징 벡터를 결합하여 새로운 GRU 상태 벡터 를 생성하며, 이는 A-GRU를 나타낸다.
-
T-GRU의 경우, 서로 다른 시간 단계에서 노드/학습자의 토폴로지 컨텍스트 벡터를 고려하여 GRU 상태 벡터 를 생성한다.
-
속성-토폴로지 Attention은 각 시간 단계에서 속성과 토폴로지의 중요도를 결정하며, 상태 벡터 와 를 받아 각각 Attention 값 와 를 계산한다. 따라서, 시간 단계 에서의 최종 상태 벡터는 다음과 같이 정의된다:
-
그래프 구조의 시간적 변화를 감지하기 위해 Temporal Attention이 추가되었다. Attention 모델은 상태 를 입력받아 각 상태에 대한 Attention 값 를 출력한다. 다중 헤드 셀프 Attention을 활용하여 노드의 최종 벡터 표현은 다음과 같이 정의된다:
- : 모든 를 연결한 벡터.
- 는 서로 다른 시간 단계의 Attention 값.
-
-
마지막으로, 교차 엔트로피 손실(cross-entropy loss)과 Softmax 함수를 사용해 노드 레이블을 추정한다. 시간 단계에 걸쳐 선택된 지식 개념에서 낮은 지식 획득을 나타내는 노드(학습자)만 추천 시스템에 입력되며, 해당 지식 개념에 맞는 학습 자료와 함께 제공된다.
3. EXPERIMENT
3.1 Dataset
ASSISTments 학습 플랫폼에서 제공된 데이터셋을 활용했으며, 관련 특징을 추출 및 집계하여 재구성하고 레이블링하였다. 학습자를 나타내기 위해 총 8가지 특징(소요 시간, 정답 수, 힌트 요청 수, 시도 횟수, 좌절 점수, 지루함 점수, 혼란 점수, 집중도 점수)을 선택했다. 각 학습자는 지식 획득이 낮아 추천이 필요한지 여부를 나타내는 이진 값으로 레이블링되었다.
레이블링된 데이터를 기반으로 "덧셈과 뺄셈 정수(Addition and Subtraction Integers)"라는 지식 개념을 예시로 선택했다. 해당 데이터에 따르면 학습자의 42%가 문제를 겪으며 추천이 필요하다고 나타났다. 이후, 선택된 지식 개념을 기반으로 동적 그래프를 생성하였으며, 특정 시간 단계(10)에 걸쳐 과제를 완료한 모든 학습자들을 연결한다.

3.2 Results and Discussion

-
여러 실험을 거친 후, 다음과 같은 매개변수에서 제안된 모델이 가장 높은 성능을 보였다:
batch size = 2048, learning rate = 0.001, epochs = 30, 상태 벡터 크기(dhd_hdh) = 12 -
이 모델은 그래프에서 각 학습자를 나타내는 선택된 특징의 중요성(A-GRU)과 동일한 지식 개념을 공유하는 학습자 간의 연결을 나타내는 그래프 토폴로지(T-GRU)를 결합한다. 시간 단계에 따른 그래프의 동적 표현을 활용하여, 정적 그래프 스냅샷에만 의존하는 정적 방법보다 학습자의 지식 획득을 더 효과적으로 모델링한다.
-
이 모델은 학습자별로 추천 필요성을 높은 정확도로 예측할 수 있으며, 이를 통해 학습자 탈락률을 크게 줄일 수 있다. 또한, 낮은 학습 성과를 보이는 학습자를 위한 적응형 시스템 구축에도 도움을 줄 것이다.
