[논문 리뷰] NNCLR) With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations (ICCV 2021)
논문리뷰
https://arxiv.org/abs/2104.14548
1. Introduction
새로운 감각 경험 → 예를 들어 도도새 사진을 보여주었을 때, 그 사람은 비록 도도새가 무엇인지를 명시적으로 알려주지 않더라도, 유사한 다른 class들과 연관 지을 것이다.
예를 들면, 코끼리나 호랑이보다는 닭이나 오리와 유사하다고 생각하게 된다. 이렇게 기존 경험과 비교하고 대조하는 과정은 무의식적으로 발생하며, 이는 인간이 개념을 빠르게 습득하는 데 중요한 역할을 한다.
이처럼 최근 많이 연구된 방식은 동일한 샘플에 대해서 다른 증강을 적용한 후 이를 positive pair로 간주하여 embedding space에서 positive pair 간 거리가 최대한 가까워지도록 학습하는데, 이는 동일한 객체의 다른 시점에 대한 positive pair를 제공할 수 없고, 같은 class 내에서도 다른 유사한 인스턴스들을 positive pair로 제공할 수 없다.
그래서 저자들은 각 샘플에서 embedding space 상 가장 가까운 이웃 샘플을 positive pair로 설정하는 방법을 제시하였다.
2. Related Work
Self-supervised Learning
- Self-supervised learning은 label이나 annotation 없이 robust한 샘플 representation을 얻고자 하며, 초기 방법들은 pre-text tasks를 정의하여 학습한 후 다른 downstream task에 적용하고자 하였다.
- 그 중에서도 contrastive loss를 사용하는 방법은, 양성 샘플끼리는 서로 가깝고, 음성 샘플끼리는 멀도록 하는 latent space를 학습한다.
- Contrastive learning의 변형인 instance discrimination는 supervised learning과의 성능 격차를 줄였고 이를 위해 data augmentation, contrastive losses, momentum encoders, 그리고 memory banks와 같은 기법들의 중요성이 입증되었다.
→ 해당 연구에서는 instance discrimination에서 확장하여, 동일 이미지에서 증강 된 샘플 뿐 아니라, 이미지 임베딩의 support set을 유지하고, 해당 집합에서 가장 가까운 이웃을 사용하여 다른 이미지들 간 non-trivial 양성 샘플도 정의한다.
Queues and Memory Banks
- MoCo와 유사하게, 저자들은 학습 동안 support set을 메모리로써 사용한다. (MoCo는 queue의 요소들을 negative 샘플로써 활용하고, 저자들은 contrastive loss의 맥락에서 queue의 가장 가까운 이웃을 positive 샘플로써 활용한다.)
- 메모리의 크기는 고정하고, 학습 데이터셋와과 독립적이며, latent embedding space에서는 어떠한 aggregation이나 clustering도 수행하지 않는다.
- Support set은 새로운 embedding들로 갱신되고, 이 embedding들에 대한 running averages는 유지하지 않는다.
Nearest Neighbors in Computer Vision
- Nearest Neighbors는 image retrieval, unsupervised feature learning 등 다양한 task 뿐 아니라, video alignment, image alignment에서의 중간 작업으로도 유용하다.
- 저자들 또한 cross-sample nearest neighbors를 사용하지만, 다양한 객체 클래스가 있는 데이터 셋에서 학습하여 transferable feature를 학습하고자 하였다.
- 그리고 RGB 이미지 하나의 modality로 nearest neighbor을 얻고자 하였고, 다양성을 높이기 위해 이전 임베딩의 explicit support set을 유지한다.
- 타 연구에서는 BYOL loss에 nearest-neighbor를 위한 새로운 term을 추가하지만, 본 저자들의 공식은 모든 loss term에서 nearest neighbor를 사용한다.
3. Approach
저자들은 SimCLR을 contrastive learning의 주요 방법이라 생각하며, nearest-neighbors를 positive 쌍으로 활용하는 Nearest-Neighbor Contrastive Learning of visual Representations (NNCLR) 을 제안한다.
3.1. Contrastive instance discrimination
InfoNCE loss
대조 손실이며 instance discrimination에서 자주 사용된다. 주어진 번째 샘플이 임베딩 된 이 있다면, 이에 대응하는 positive 쌍은 이고, 다양한 negative embedding들을 라고 할 때, InfoNCE loss는 아래와 같은 식으로 정의된다.
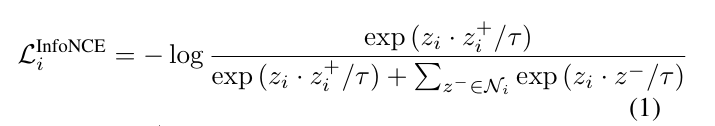
InfoNCE loss를 통해 최적화를 진행하면 embedding space에서 positive pair 끼리는 가깝게 끌어당기고, negative pair 끼리는 분리되도록 표현을 학습하게 된다.
SimCLR
한 이미지로부터 나온 두 개의 views를 positive pair로 사용한다. 각 view들은 한 이미지에서 다른 random augmentation으로부터 만들어지고, 이를 encoder에 입력하여 positive embedding pair 와 를 얻고, negative pairs는 주어진 미니배치 내 다른 모든 임베딩을 사용하여 구성된다.
인코더를 라고 한다면, 로부터 얻어지는 두 positive pair인 와 는 모두 로 표현 가능하다. Encoder인 는 주로 non-linear projection head가 추가된 ResNet50 모델이 쓰인다.
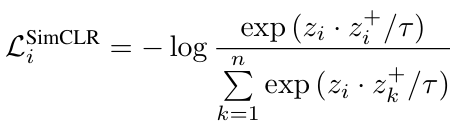
SimCLR에서 사용되는 InfoNCE loss는 위와 같이 정의되고, 이는 embedding space에서 positive pair끼리는 가깝게, negative sample끼리는 멀도록 학습되도록 돕는다.
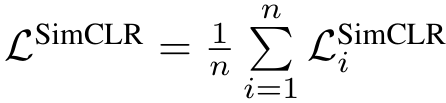
loss를 계산하기 전 각 embedding은 L2 정규화를 거치고, 미니배치 전체의 loss는 위와 같다.
3.2. Nearest-Neighbor CLR (NNCLR)
Latent representation의 풍부함을 증가시키고 단일 인스턴스 양성 샘플에서 더 나아가기 위해, 본 논문 저자들은 nearest-neighbours를 사용하여 더욱 다양한 positive pairs를 정의한다. 이를 위해서 전체 데이터 분포를 대표할 수 있는 embedding의 support set을 유지해야 한다.
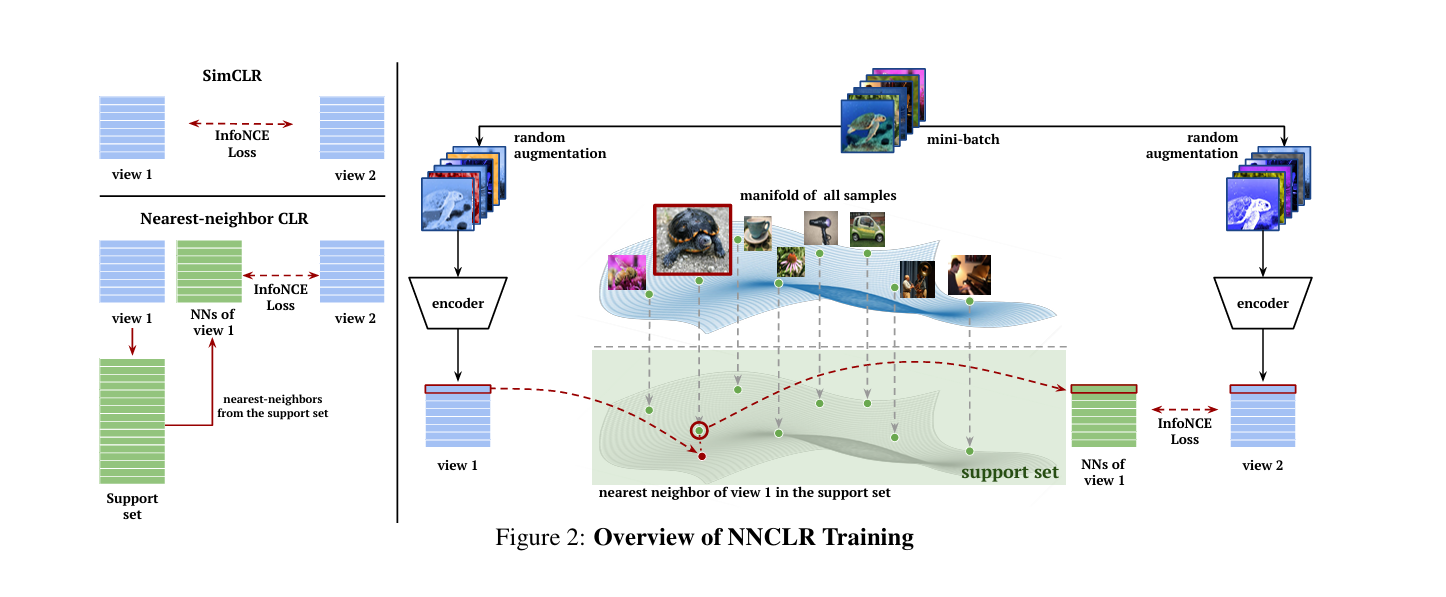
저자들이 제안한 방법은 support set 에서 와 가장 가까운 이웃을 의 positive sample로 사용하는 것이다. 네트워크 전체 구조는 아래 그림과 같다.
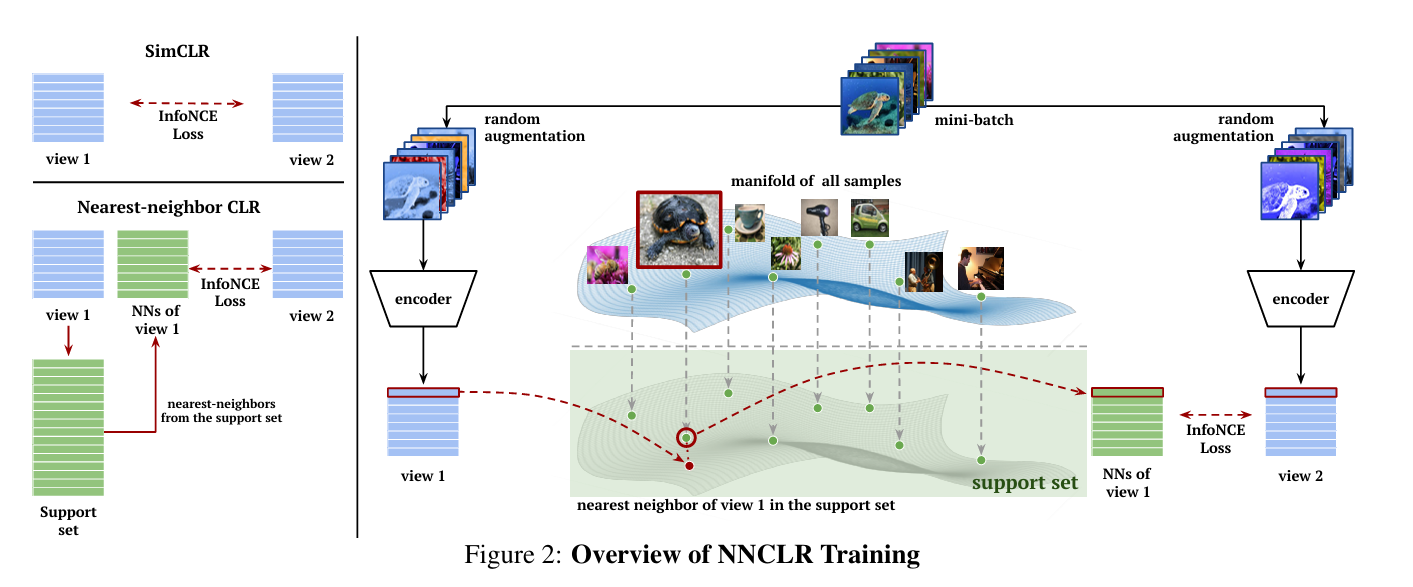
Negative sample들은 SimCLR와 유사하게 미니 배치로부터 얻고, loss는 SimCLR에서 사용된 방식의 InfoNCE loss를 조금 변형하여 사용하였다.
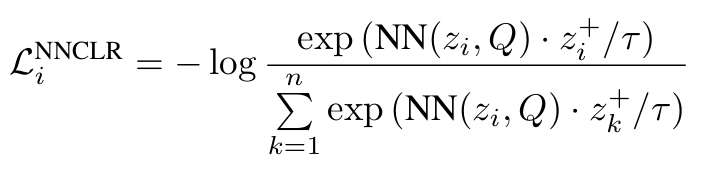
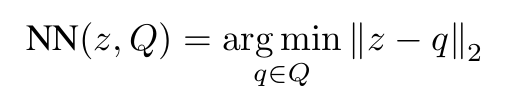
Positive 쌍에 대한 식인 분자식을 보면, 로부터 와 두 개의 augmentation + encoder를 거친 결과를 얻는 것 까지는 SimCLR와 같으나, 이후 와 를 내적하는 것이 아닌, 와 support set 에서 가장 가까운 거리(l2 distance)에 있는 샘플인 와 를 내적한다.
분모 식 또한 와 나머지 음성 샘플인 을 내적한 값들을 모두 합산한다.
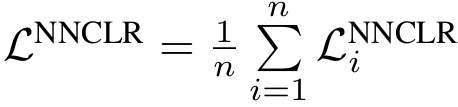
그렇게 마찬가지로 하나의 미니 배치 내 loss는 각 샘플에 대한 NNCLR InfoNCE loss 결과를 평균하면 된다. (그리고 마찬가지로 내적 연산 전에 각 embedding은 l2 정규화 진행한다.)
Implementation details
에는 위와 같은 term을 추가해서 위와 같은 항을 추가해준다. 하지만 이는 실험적으로 성능에 큰 영향을 미치진 않는다고 한다. 그럼 왜 넣은겨
그리고, Bootstrap your own latent (BYOL) 에서 영감을 받아 를 그대로 사용하는 것이 아닌, prediction head 를 통과시켜 얻은 를 사용한다고 한다. 즉, 위 식에서 는 prediction MLP를 통과하여 얻은 로 대체해야 함. 이에 대한 효과는 4.4절 ablation study에서 보일 예정
Support set
Support set은 Queue(First in First out) 형태로 구현하였다. 이는 크기의 랜덤 행렬로 초기화되는데, 여기서 는 queue의 크기이고 는 각 embedding의 크기라고 생각하면 된다.
Support set의 크기()는 latent space에서 전체 데이터 셋의 분포에 근사할 수 있도록 최대한 큰 사이즈로 유지한다.
→ 학습 과정에서 현재 미니배치 개의 임베딩을 큐의 끝에 추가(enque)하고, 가장 오래된 개의 임베딩은 제거(deque)하여 Queue의 크기는 으로 유지하게 된다.
원래 한 샘플에서 view는 총 두 개가 생성이 되는데, 양 쪽의 임베딩을 사용하나 한 쪽에서 생성된 임베딩만 사용하나 성능에는 유의미한 차이가 없어서, 한 쪽 view에서 만들어진 임베딩만 사용하였다고 한다. Ablation study에서 다양한 형태의 support set에 대한 결과를 비교한다.
4. Experiments
해당 섹션에서는 NNCLR가 생성한 feature를 다른 SOTA self supervised image representation들과 비교한다.
4.1. Implementation details
Architecture
Encoder
- 모티브가 된 SimCLR, BYOL과 일관성을 맞추기 위해 encoder는 ResNet50을 사용하였다.
- 이에 추가되는 Projection MLP는 3개의 fully connected layer로 구성되고, 각 layer의 크기는 2048, 2048, 이다. 특별한 언급이 없는 한 실험에서는 256을 사용했다고 한다.
- 각 fully connected layer 뒤에는 Batch Normalization을 적용하고, 마지막 layer를 제외한 모든 Batch Norm 뒤에는 ReLU를 적용하였다.
Prediction MLP
- 는 2개의 fully connected layer로 구성되고, 각 layer의 크기는 4096, 이다.
- hidden layer에는 Batch Norm과 ReLU를 적용하지만, 마지막 layer는 둘 다 적용 x
Training
- 다른 self-supervised method들과 동일하게 NNCLR 표현 학습은 ImageNet-2012 데이터셋으로 진행하고, 이 과정에서 어떠한 label과 annotation도 사용되지 않는다.
- 100 epoch동안 학습 진행하고, 처음 10 epoch은 cosine annealing scheduling을 적용한 warm up 단계로 구성
- 최적화 알고리즘은 LARS(Layer-wise Adaptive Rate Scaling)을 사용
- weight decay는 , bias term에는 적용 x
- 데이터 증강 방식은 BYOL과 동일한 방식
- Contrastive loss 계산에 사용되는 (temperature) 값은 0.1
- Queue 크기는 98304, base learning rate는 0.3
4.2 ImageNet evaluations
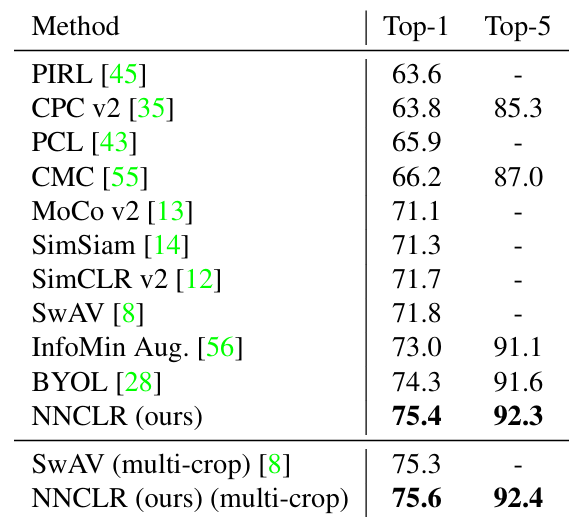
ImageNet linear evaluation
표준 linear evaluation procedure에 따라 ResNet50 encoder에서 추출한 2048 차원의 임베딩을 고정한 채로 linear classifier를 90 epoch 동안 학습시켰다.
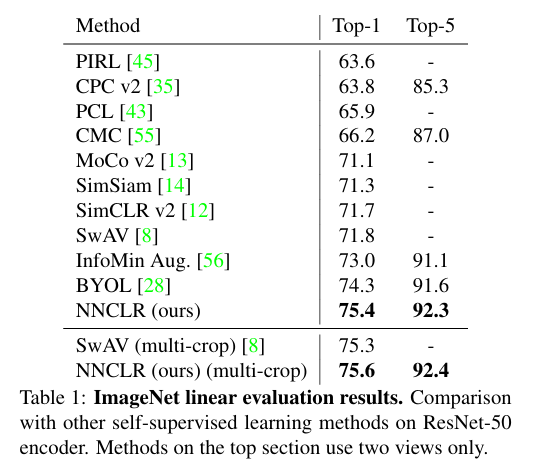
- 두 개의 view를 사용하여 학습된 ResNet50 encoder를 사용하는 타 SOTA들보다 좋은 성능을 보여주었다.
- Clustering based의 SOTA인 SwAV의 multi-crop 과 비교를 위해, 800 epoch동안 2개의 224x224 view와 6개의 96x96 view를 사용하여 pretrain 하였고, SwAV에 비해 0.3% 높은 정확도를 보였다.
- 하지만 SwAV은 multi-crop을 사용함으로써 성능이 35%나 증가하는 반면, NNCLR에서는고작0.2% 증가했고, multi-crop은 메모리와 계산 비용을 기하급수적으로 늘리기 때문에 multi-crop 없이도 유사한 성능 내는 NNCLR가 훨 낫다! 고 말하는 것 같다.
Semi-supervised learning on ImageNet
표준 평가 protocol을 따라서, ImageNet 1%와 10% subset으로 세팅 된 semi-supervised에서의 효과도 훌륭했음을 보이고 있다.
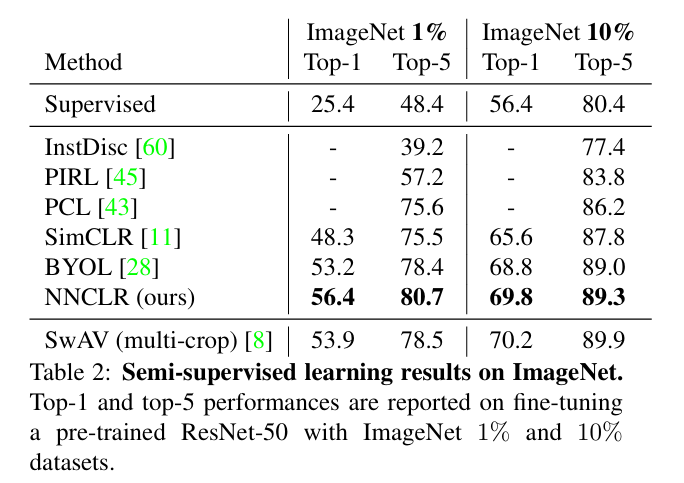
- ImageNet 1% subset에서 NNCLR는 SwAV의 multi-crop을 포함한 다른 SOTA 모델과 비교하여 가장 좋은 성능을 보여주었다. 이는 NNCLR가 few shot learning scenario에서 특히 좋은 일반화 능력을 보인다고 할 수 있다.
- ImageNet 10% subset에서는 SwAV의 multi-crop을 제외한 모델들보다 모두 우수한 성능을 보였다.
4.3 Transfer learning evaluations
해당 섹션에서는 다양한 downstream classification task로의 transfer learning에서 NNCLR의 성능을 보여준다.
BYOL 에서 제시된 evaluation protocol에 따라, 먼저 train set의 label을 사용하여 linear classifier를 학습하고, 각 데이터 셋의 validation set에서 가장 좋은 regularization 하이퍼파라미터를 선택한다.
그 후 train set과 validation set을 합하여 새로운 train set을 만들고, 이를 사용하여 linear classifier를 학습시킨 후 test set에서 평가하였다고 한다.

NNCLR는 12개 데이터 셋 중 11개 데이터셋에서 ImageNet label로 supervised 학습된 ResNet50(표에서 Sup-IN)보다 좋은 결과를 보였고, 8개의 데이터 셋에서 BYOL과 SimCLR 보다 좋은 일반화 성능을 보였다.
4.4 Ablations
해당 섹션에서는 기본 설정에 대해서 논의한 후, 다양한 세팅의 결과를 비교하고 여러 디자인 선택을 제시하고, memory와 computational overhead에 대해서 짧게 논의한다.
Default settings
- 따로 명시되지 않은 경우 support set의 크기는 32,768이고, 배치 사이즈는 4096
- 1000 epoch동안 학습, 10 epoch의 warm-up, 0.15의 base learning rate에서 LARS optimizer를 사용하여 cosine annealing scheduling으로 학습한다.
- Prediction head는 기본적으로 사용한다.
- 모든 ablation은 ImageNet linear evaluation setting에서 진행된다.
Nearest-neighbors as positives
이 논문의 핵심 contribution으로, 가장 가까운 이웃을 positive pair로 사용하는 것과 momentum encoder 유무에 대한 ablation
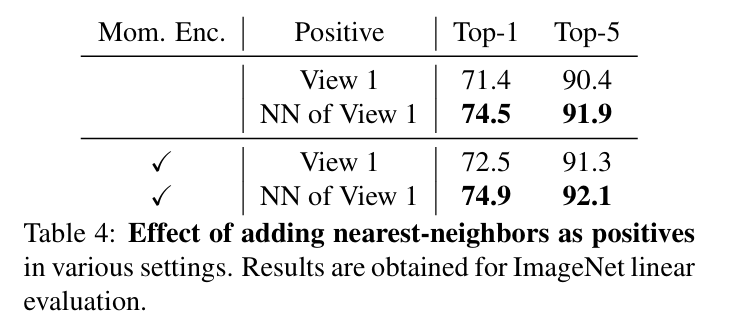
여기서 갑자기 나오는 momentum encoder는 MoCo에서 쓰인 것과 유사하다.
기본적으로 view 1보다, view 1의 Nearest neighbor를 positive 쓰는 것이 더 좋은 결과를 보였고, momentum encoder를 썼을 때 더 좋은 성능이 나왔다.
Data Augmentation
SimCLR와 BYOL은 좋은 성능을 얻기 위해 복잡한 augmentation pipeline에 의존하지만, NNCLR는 nearest-neighbors가 이미 샘플 변형의 다양성을 제공하기 때문에 이에 덜 의존적이라고 한다. 해당 ablation에서는 모든 color augmentation과 gaussian blur를 제거하고, random crop만을 augmentation 방법으로 사용하여 300 epoch으로 학습하였다.

결과를 보면, 이렇게 augmentation의 다양성을 줄인다고 해서 SimCLR나 MoCo처럼 성능의 큰 하락으로 이어지진 않았다. 이러한 특성은 ImageNet에 사용되는 data 변환이 적합하지 않은 domain에서 NNCLR를 pre-trained model로 채택하면 좋을 것으로 보인다.
새벽에 연구실에서 혼자 논문 읽다가 갑자기 짤 생각나서 그냥 만들어봤다..
Pre-training epochs
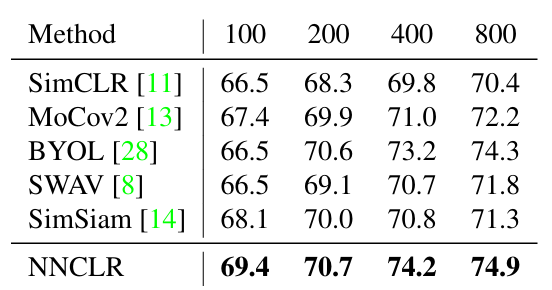
- 다양한 pre-training epoch에서 NNCLR은 pre-training budget이 일정하게 유지될 때 다른 self-supervised method들에 비해 나은 결과를 보였다.
- Lr 0.4는 100 epoch에서, lr 0.3은 200, 400, 800 epoch에서 가장 잘 동작했다.
Support set size

- 일반적으로 support set의 크기를 늘리면, 더 큰 집합을 사용함으로써 전체 데이터 셋에 더 가까운 nearest neighbour를 찾을 확률이 높아져서 더 좋은 성능을 보였다.
- 98304 이상으로 증가시키면 더이상 성능이 크게 향상되진 않는데, 이는 support set 내의 오래된 embedding이 늘어남에 따른 결과일 수 있다고 저자들은 추정한다.
Nearest-neighbor selection strategy
Nearest-neighbor를 사용하는 대신, Top-K개의 nearest neighbors 중 랜덤으로 한 가지를 선택하는 실험도 진행하였다.

→ k값이 증가할수록, 성능이 일관적으로 떨어지는 것을 확인할 수 있다.
또한 soft nearest neighbor를 사용하는 방법과도 비교해 보았을 때,

→ soft nearest neighbor보단 hard nearest-neighbor를 사용하는 방법이 더 나은 결과를 보였다.
Batch size
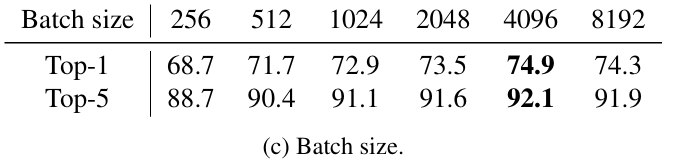
Batch size 는 커질수록 좋은 성능을 보였지만, 4096보다 큰 값으로 설정하면 성능 하락으로 이어지는 결과를 보였다.
Embedding size
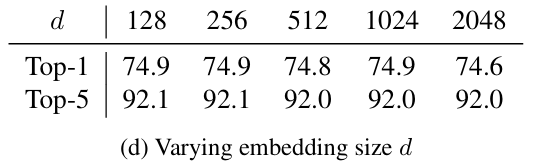
Embedding size에 따른 결과는 모두 큰 차이가 없어서, 선택에 있어서 강건하다.
Prediction head
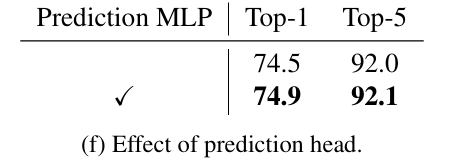
에 prediction MLP를 적용하였을 때 Top-1 performance에서 0.4% 향상된 결과를 보였다.
Different implementations of support set
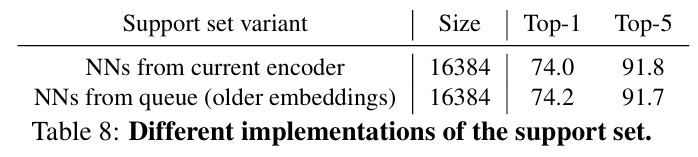
-
Support set을 queue로 사용하는 대신, 데이터 셋에서 랜덤으로 이미지를 선택하여 현재 encoder 를 통과시킨 후 해당 embedding 집합에서의 nearest neighbor를 사용하는 방식
→ 어느정도 성능을 보이긴 하지만, support set 크기를 16,384 이상으로 키우기 어려웠고, queue를 사용할 때보다 약 4배 느려지는 결과를 보였다.
-
Support set을 FIFO 방식이 아닌 무작위로 업데이트 하는 방법
→ ImageNet linear evaluation에서 Top-1 정확도가 2% 이상 저하되었다.
Compute overhead
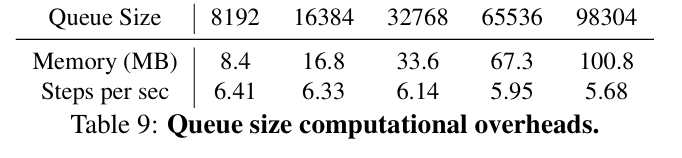
Queue의 크기를 늘릴수록 성능이 향상되지만, 이에 따른 메모리 및 연산 비용이 증가하기에, 저자들은 적절한 trade-off를 찾고자 해당 ablation을 진행한 듯 했다.
그 결과 queue size가 98304일 때 어느 정도 효율성을 보여주었다고 한다.
4.5 Discussion
Ground Truth Nearest Neighbor
저자들은 NN의 두 측면에 대해 조사하였다.
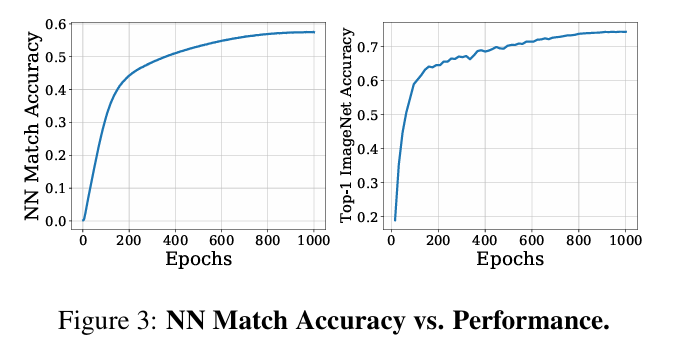
-
NN이 쿼리 이미지와 동일한 label을 갖는 경우가 얼마나 될지?
→ 학습이 진행됨에 따라 후반부에서 NN이 동일한 클래스에서 선택될 확률은 약 57%정도이다. 생각보다 낮은 확률인데, 저자들은 random crop에서 배경만 포함되는 경우가 있어서가 아닐까 추측한다.
-
NN이 항상 동일한 클래스에서만 선택되도록 하여 학습할 경우의 성능
→ 이는 어찌보면 레이블을 사용하는 supervised learning과 유사하지만, 클래스 예측을 직접 학습하는 대신 self-supervised 방식을 유지한다는 점에서 차이가 있다.
→ 이 방식으로 학습을 하면 앞서 보인 실험 결과보다 더 높은 정확도 성능을 보이지만, 이는 완전한 unsupervised learning은 아니기에, 이에 맞춰 구현하려면 쉽지 않음을 이야기한다.
Training curves
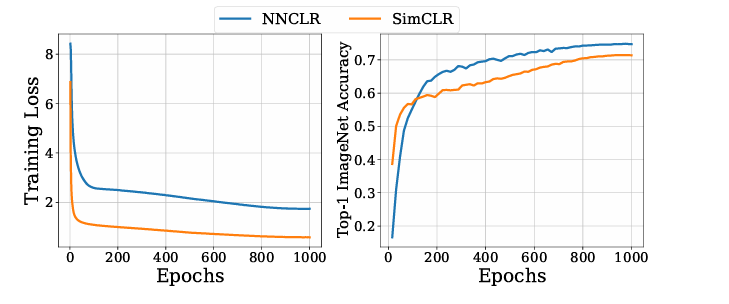
SimCLR와 비교했을 때 NNCLR는 데이터 셋 내 다른 샘플에서 hard positive를 학습해야 하는 더 어려운 학습 과제임에도 약 120 epoch부터 SimCLR 보다 높은 성능을 유지함을 볼 수 있다.
NNs in Support Set

위 그림은 학습이 거의 끝난 시점에서 support set에서 검색된 nearest neighbor 배치를 보여준다. 저자들은 이러한 NN 기반 positive selection이 성능 향상을 보이는 이유는, 기존의 데이터 증강 방식으로는 얻을 수 없는 다양성 때문이라고 가설을 세운다.
실제로 결과들을 보았을 때, row 3의 경우 모두 수중 이미지들이 NNs로 선택되거나, row 4의 경우 view 1의 클래스는 dog(개) 인데, 뽑힌 NNs를 보면 모두 cage가 있으면 선택된 양상을 보였다.
→ 이는 NNCLR로 단순히 클래스 기반 유사성 뿐 아니라, texture와 같은 다른 유사성을 기반으로 하는 일반화된 표현 학습을 수행한다고 시사한다.
