[논문 리뷰] SNCLR) Soft Neighbors are Positive Supporters in Contrastive Visual Representation Learning (ICLR 2023)
논문리뷰
https://arxiv.org/pdf/2303.17142
1. Introduction
흔히 contrastive learning에서, 서로 다른 이미지에서 생성 된 view는 negative로, 동일한 이미지에서 나온 view는 positive로 간주하게 된다.
하지만 이는 서로 다른 이미지 간의 instance correlation을 충분히 반영하지 못하여 성능이 저하되는 문제가 발생한다.
예를 들어, ImageNet으로 학습을 진행할 때 ‘bloodhound’ 라는 클래스에 속하는 특정 이미지의 인스턴스 로 부터 얻은 view는 양성으로 분류되지만, 같은 클래스에 속하는 다른 인스턴스로부터 얻은 view들은 모두 음성으로 분류된다.
또한, ‘walker hound’에 속하는 의 view와 ‘peacock’에 속하는 의 view 중, 전자의 경우가 훨씬 의 뷰와 유사하겠지만, 둘 다 똑같이 그저 negative로 분류된다. 때문에, 이러한 방법 만으로는 이미지 인스턴스 간 관계를 효과적으로 학습하기 어렵다.
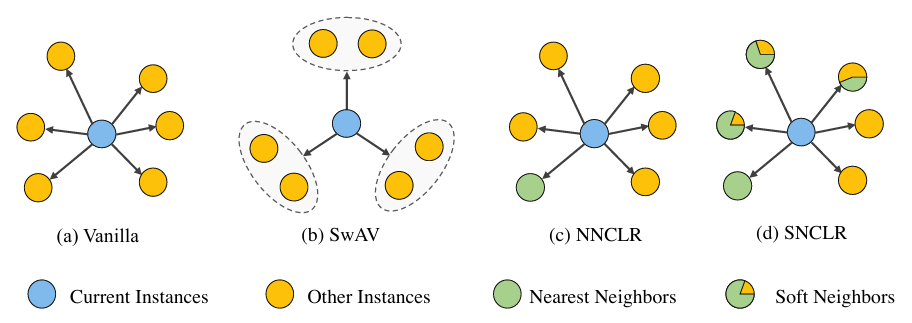
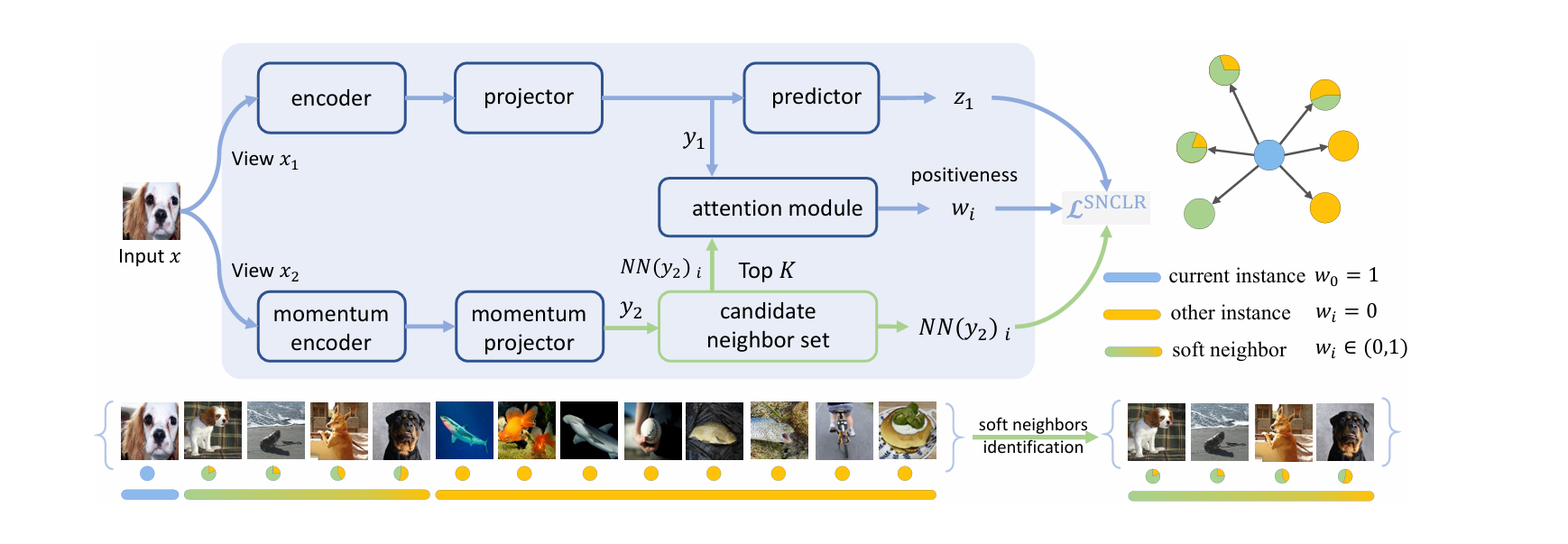
위는 대중적인 contrastive learning들에서 positive / negative sample을 선택하는 방식이다. SNCLR는 SimCLR(vanilla)와 NNCLR의 장점을 모두 활용하여, adaptive weight를 가진 이웃 샘플들을 식별하여 loss를 계산하고자 한다.
2. Related Works
2.1 Self-Supervised Visual Representation Learning
Generative SSL methods
- Image reconstruction을 위한 autoencoder를 도입하거나, 데이터와 representation을 joint embedding space에서 모델링, 또는 최근엔 masked image modeling(MIM) 등의 방법이 있지만 이는 vision transformer를 위해 설계되어서 높은 연산량을 필요로 하며, pre-trained features를 downstream finetuning 없이 쓴다면 인식 성능이 좋지 않을 수 있다.
Discriminative SSL methods
- 동일한 이미지에서 증강된 view들의 feature distance를 최소화하면서, 다른 이미지로부터 증강된 view들의 distance는 최대화하는 방식으로 학습.
- 대표적으로 contrastive learning이 있으며, instnace discriminative paradigm을 기반으로 memory bank, feature coding, multi-modality coding, strong data-augmentation 등의 방법들이 연구되었으며, 그 중에서도 본 연구에서 사용하는 neighboring-based method들은 cluster set이나 nearest neighbor를 사용하여 view들 간의 상관관계를 모델링한다.
2.2 Nearest Neighbor Exploration in Visual Recognition
Nearest neighbor 기법은 다양한 컴퓨터 비전 task들에서 많이 사용되었다. 이는 보통 샘플 간의 전반적인 관계를 탐색한다.
- SwAV
- prototype feature cluster를 설정하고, sample feature와 prototype feature 간의 일관성을 유지하도록 설계
- NNCLR
- Support set을 활용하여 nearest neighbor를 탐색
- 자세한 내용은 NNCLR 논문 리뷰 포스팅 참고
하지만 기존 방법에서는 이웃 샘플이 binary로 정의되는데, 저자들은 실제론 샘플이 여러 이웃들과 부분적으로 연관이 있을 수 있기 때문에 이를 attention module을 추가하여 반영하였다고 한다.
3. Proposed Method
저자들이 제안하는 Soft Neighbor Contrastive Learning (SNCLR)의 전체적인 구조. 하나씩 살펴보도록 하자.
3.1 Revisiting Contrastive Learning
기존 CLR 방법에 대한 간단한 설명이므로 생략
3.2 Soft Neighbors Contrastive Learning (SNCLR)
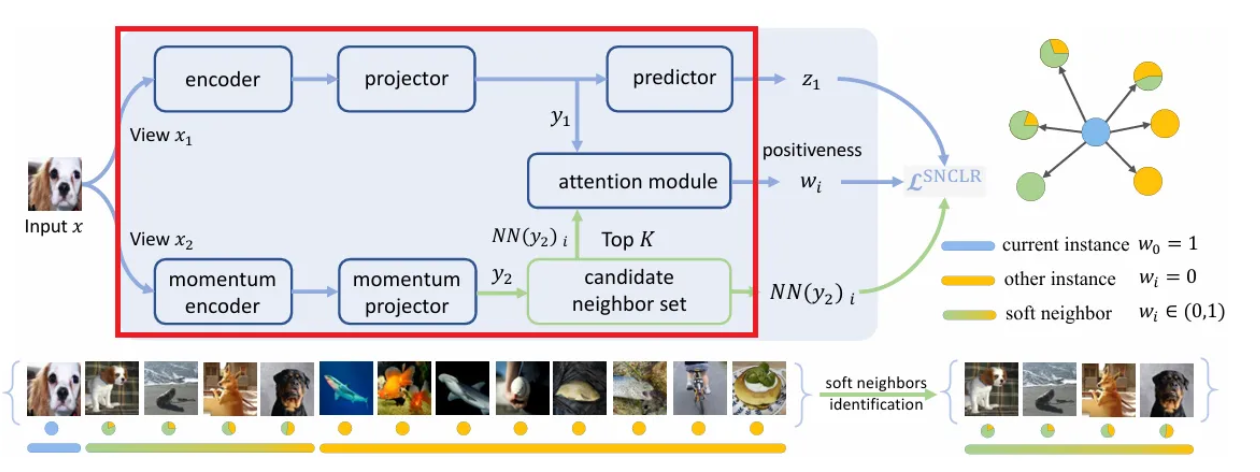
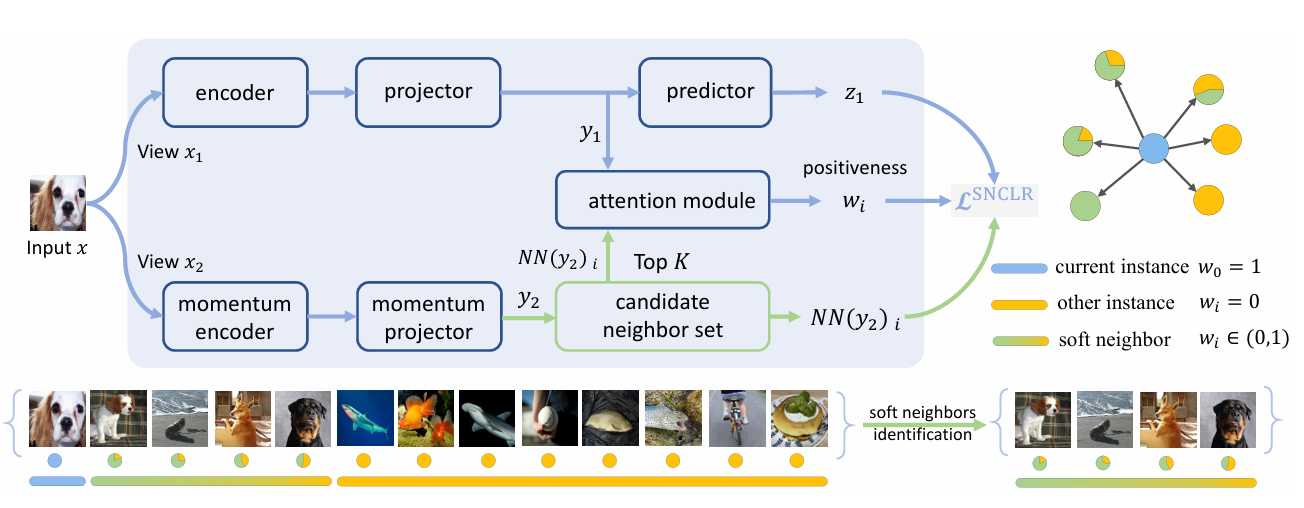
- 기본적인 프레임워크는 SimCLR, NNCLR같은 기존의 CLR 프레임워크를 따라서 현재 샘플 를 입력받으면, 두 번의 증강으로 를 얻고, projector를 통해 까지 얻는다. (은 predictor를 거쳐 projected representation인 (BYOL처럼) 으로 또 변환된다.)
- 현재 샘플인 에 대하여 SNCLR에서는 에 대한 Top-K 이웃들을 뽑아 candidate neighbor set (여기서 는 K개의 이웃 샘플 중 특정 샘플을 의미)을 만들고, 이를 과 attention module에 집어넣는다.
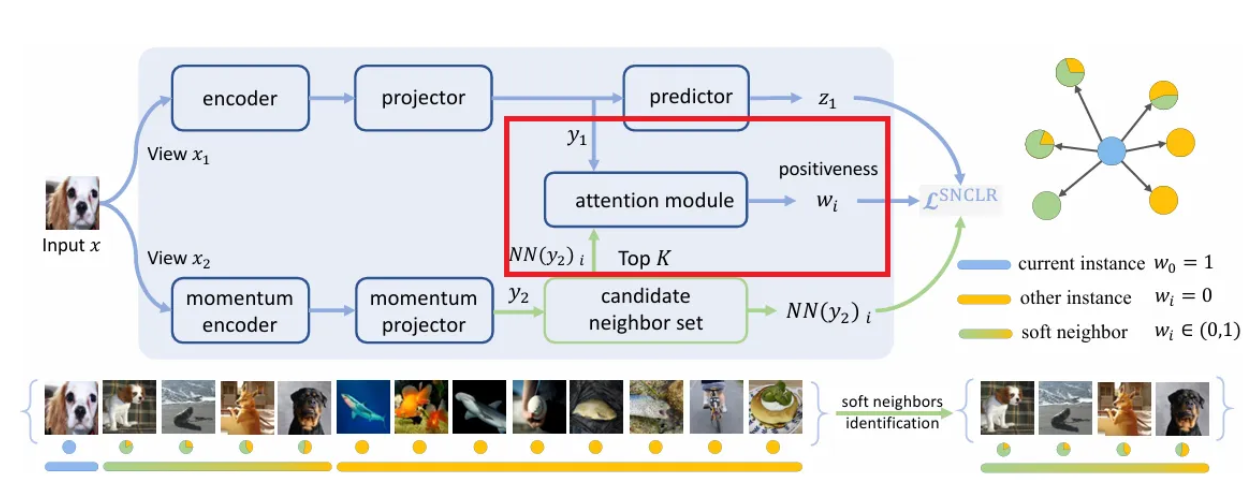
- 각각의 이웃들 는 과 함께 cross-attention 계산을 통해 positiveness value인 를 예측한다. 이 가중치 는 가 에 기여하는 정도를 조정하는 데 사용된다.
Loss는 아래와 같다.
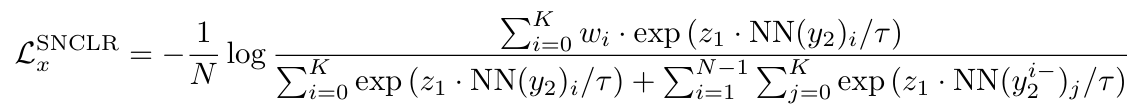
- 은 predictor의 출력 결과로, 현재 샘플의 view 1이 BYOL의 prediction head까지 통과한 상태라고 보면 된다.
- 를 (즉, 현재 샘플로부터 나온 view 2가 projection까지 통과한 상태) 라고 보면 된다.
- 는 와 가장 가까운 개 이웃 중 번째 view의 projection이라고 보면 된다.
- 를 로 보면 된다.
- 는 (현재 샘플이 아닌 개 중 번째 view projection)와 가장 가까운 개 이웃 집합으로 보면 된다.
- 는 현재 샘플에서 가장 가까운 개 이웃 중 번째 view의 projection이라고 보면 된다.
- 은 같은 샘플에서의 가중치이므로 1로 설정된다.
→ 따라서 과 는 partially positive pairs이고, 과 는 negative pairs로 간주한다.
Candidate Neighbors
NNCLR와 같이, candidate neighbor set 로 queue를 사용하였다. 각 요소는 momentum branch로부터 투영된 feature representation이고, 이는 학습 때 배치마다 queue 사이즈에 맞춰서 first-in-first-out(FIFO) 방식으로 최신화 된다.
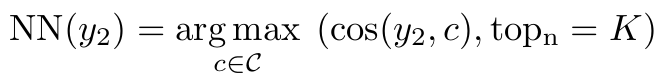
유사도를 구할 땐 cosine similarity를 쓰고, 이 연산은 뿐 아니라 에도 적용되어 각각의 개 이웃을 구한다.
Positiveness Predictions
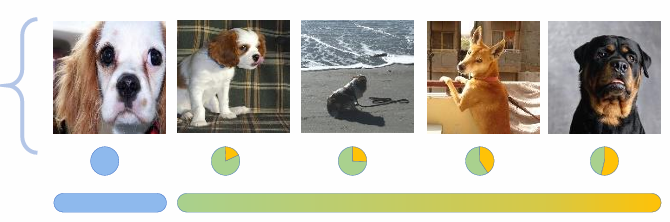
그리고 현재 인스턴스와 선택된 개 이웃들간의 관계를 정량적으로 측정하는데, 위 그림을 보면 input 샘플에 대하여 네 가지 최근접 이웃들이 뽑혔고, 이 중 앞선 두 샘플은 입력 이미지와 같은 클래스인 ‘Cavalier King Charles Spaniel’ 에 속한다. 이후 두 샘플은 같은 클래스는 아니지만, 유사한 ‘dog’ 클래스에 속하는 이미지들이 뽑히게 되었다.
이렇듯 각 이웃과의 상관관계(positiveness)를 뽑기 위해 attention module을 도입하는데, 이는 두 개의 feature projection layers, cross-attention operator, 그리고 nonlinear activation layer를 포함한다.
Input으로 과 가 주어지면, positiveness score는 아래와 같이 계산된다.
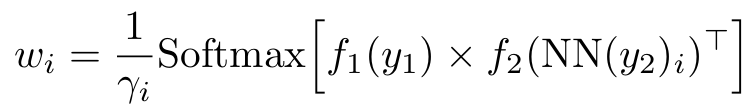
- 과 는 attention module의 projection layers
- 는 positiveness 를 조정하기 위한 scaling factor
- 각 projection layers에 대해 다양한 방식을 시도했으나, 과 를 identity mapping으로 설정하고 위 식을 적용하는 것이 가장 효과가 좋았는데, 이는 인코더를 효과적으로 학습하기 위한 supervised learning의 paradigm 때문으로 생각된다.
Analysis: Computing contrastive loss with more instances
Soft weight cross-attention design을 통해 모델이 현재 샘플과, 다른 샘플 간 상관관계를 적절히 모델링할 수 있다고 한다. 이는 보다 많은 샘플을 활용하여 contrastive loss를 계산할 수 있으며, 두 가지 이점이 있다.
- Positive sample들을 다양하게 하여 현재 샘플을 보다 soft하고 adaptive하게 support할 수 있다.
- 다른 샘플들 간의 상관관계를 탐색
- 같은 semantic category에 포함되는 인스턴스들도 negative로 간주하는 기존 CLR의 한계를 극복
- 기존 방식은 negative 샘플을 현재 미니배치에서만 뽑았으나 SNCLR에서는 추가적인 negative samples를 사용하여 배 더 많은 negative samples를 사용하게 된다.
(중복 되는 것 들이 생기진 않을까? )
Network Training
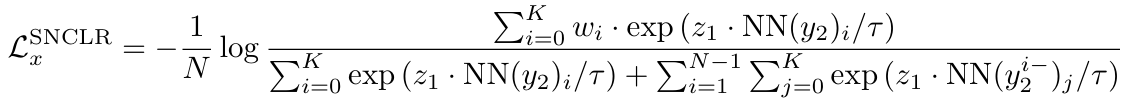
해당 loss를 통해 네트워크 파라미터를 업데이트하고, BYOL과 같이 momentum encoder와 momentum projector에 대해 moving average update를 수행
Neighbors Display

ViT-S의 encoder backbone으로 학습 시킨 모델로 Top-5개 이웃을 시각화 하였다.
- 첫 번째 행은 ‘giant panda’ 카테고리에 속하는 샘플인데, Top-5개 모두 ‘giant panda’ 카테고리에 속하는 샘플들이 높은 positiveness를 가졌다.
- 두 번째 행의 인스턴스는 ‘trolleybus’에 속하는 샘플인데, Top-4까지는 같은 클래스의 이웃들이 선택되는 반면 5번째 샘플은 다른 카테고리의 이미지가 선택되었다. 하지만, positiveness 점수는 확연히 낮다.
→ 이를 통해 저자들은 SNCLR의 attention module이 강한 상관관계를 갖는 이웃을 효과적으로 선택한다는 것을 확인하였다.
4. Experiments
4.1 Implementation Details
Network architectures
- Encoder backbone은 ViT-S, ViT-B, ResNet-50을 사용하여 비교
- Projector와 predictor의 디자인은 BYOL과 같이 세팅
Training configurations
- Pretext training은 ImageNet-1k dataset으로 레이블 없이 학습
- Data augmentation은 BYOL과 같이 세팅 (resolution, 수평 flip, color distortion, gaussian blur 등)
- ResNet backbone
- LARs optimizer with cosine annealing schedule
- 10 epoch의 warm-up을 포함한 800 epoch 동안 학습
- learning rate는
- Momentum network branch의 업데이트 게수는 0.99
- 30개의 soft neighbors 활용
- ViT backbone
- AdamW optimizer
- 40 epoch의 warm-up을 포함한 300 epoch동안 학습
- learning rate는
4.2 Comparison To State-Of-The-ART Approaches
Linear evaluation on image classification
- Standard linear classification protocol에 따라 encoder backbone의 파라미터는 얼리고 linear head를 학습
- Linear training에는 momentum 0.9의 SGD optimizer, batch size는 4096, weight decay는 0
- ResNet에는 learning rate 0.3, ViT에는 3
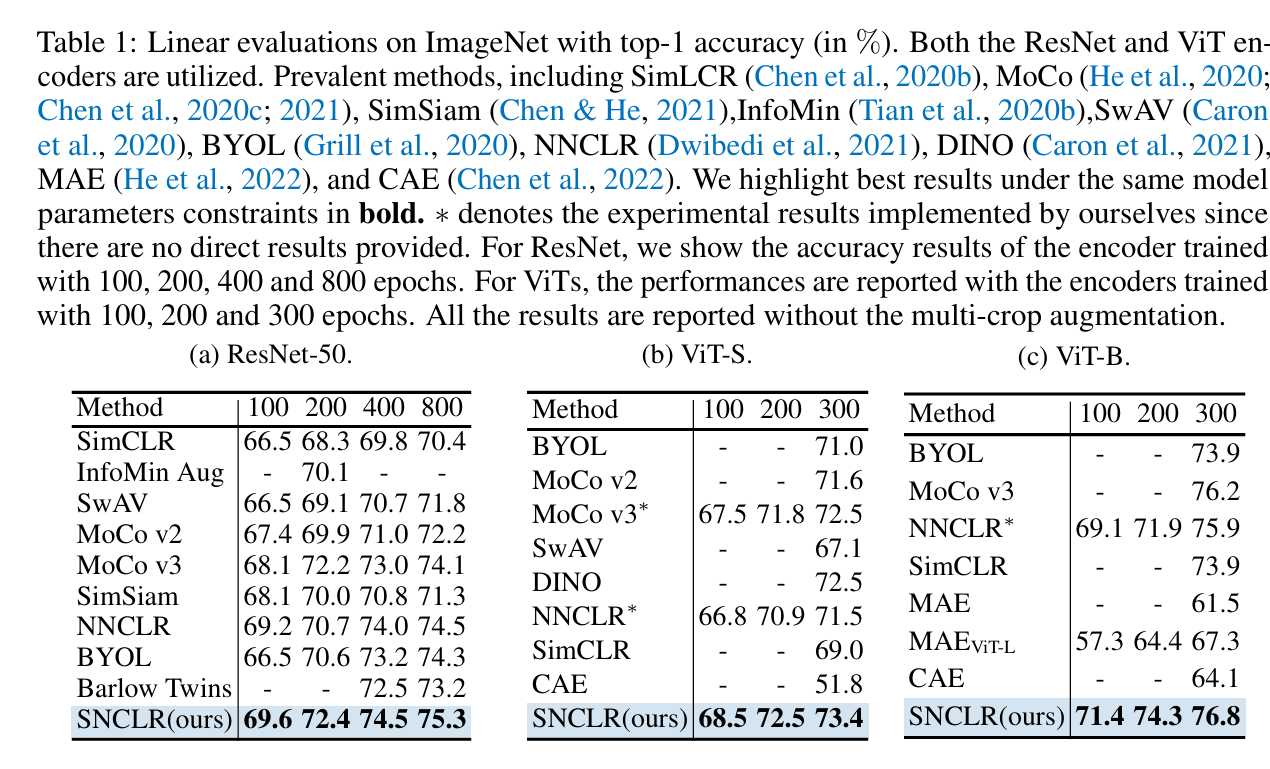
다양한 self-supervised framework들과 비교했을 때, SNCLR의 높은 상관 관계를 갖는 이웃들을 활용하는 방식은 ResNet, ViT 인코더들이 더 차별화된 feature를 추출하는 데 도움을 주었다는 것을 확인 가능하다.
Linear evaluation on image classification with semi-supervised learning
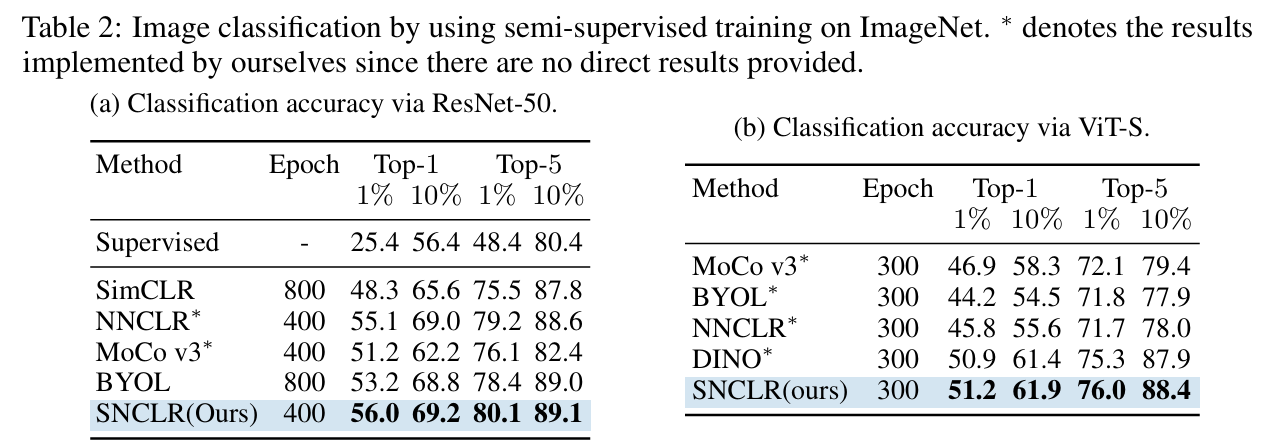
Semi-supervised learning 방식에서, ImageNet-1k subset 10%, 1% 모두에서 다른 모델과 비교하여 가장 좋은 성능을 보여주었다. 이는 SNCLR로 학습된 인코더가 더 일반화 가능한 feature를 생성했다는 것을 보여준다.
Evaluation on object detection and segmentation
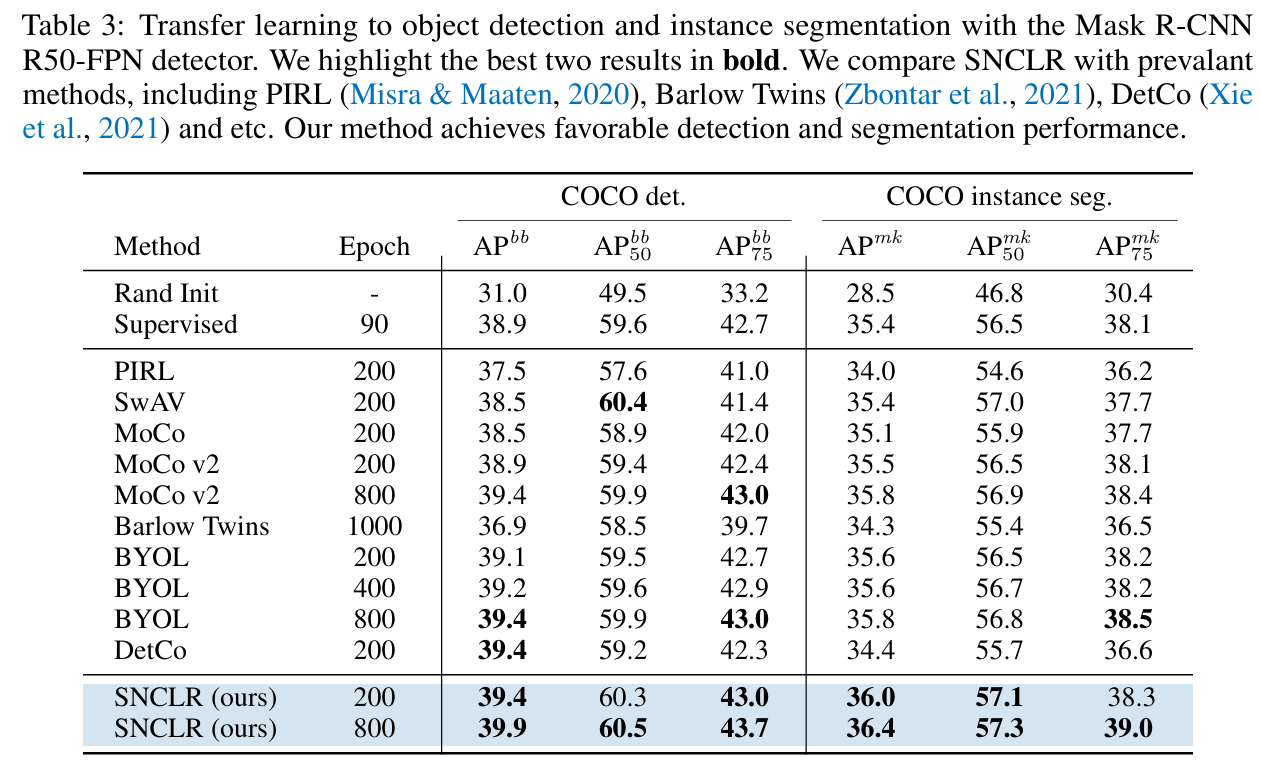
SNCLR는 object detection 및 segmentation task에서도 좋은 성능을 보였고, 이는 SNCLR가 샘플의 content correlation을 인코딩하는 것이 샘플 내에서 많은 정보를 학습 가능하고, 이로 인해 detection 및 segmentation task로의 transferable representations를 생성하는 데 도움이 되었음을 보여준다.
4.3 Ablation Studies
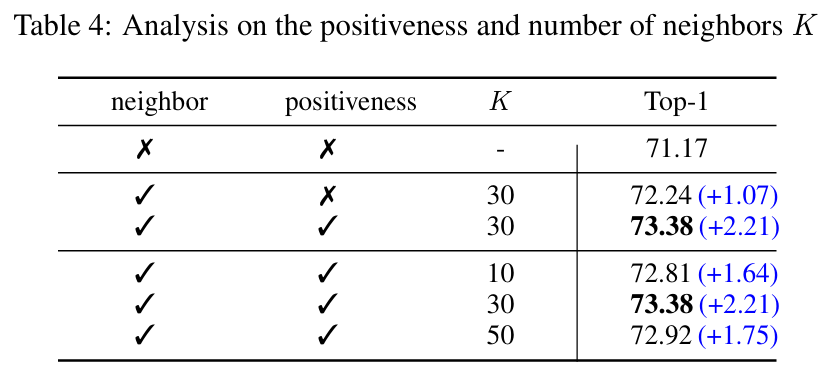
Importance of positiveness
SNCLR의 주 contribution은, 상관관계를 positiveness로 인코딩하여 visual encoder를 학습 시켰다는 데 있다.
- 위 표 4의 두 번째 블럭에서 positiveness 계산을 제거하고 모든 개 이웃을 긍정 샘플로 간주하면 성능이 낮아지는 결과를 보였다.
- 이는 소프트 라벨링의 효과를 보여준다.
Importance of neighbors
선택되는 최근접 이웃의 수인 는 30개로 설정했을 때 가장 좋은 성능을 보였다.
→ 이를 통해, 적당히 충분한 이웃 수는 positive comparison의 다양성을 풍부하게 해주지만, 너무 많은 값으로 설정하면 상관 관계가 거의 없는 샘플이 positive로 선택되어 성능을 저하 시킬 수 있다.
Analysis on the neighbor set length
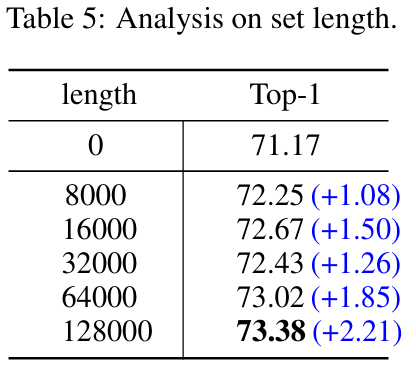
Candidate neighbor set 의 크기에 따라 성능은 달라지는데, 보통 집합이 커짐에 따라 현재 인스턴스가 더 많은 상관관계가 있는 이웃을 찾아 스스로 softly support할 수 있음을 의미한다.
