
출처: coursera https://www.coursera.org/learn/neural-networks-deep-learning
What is a Neural Network?
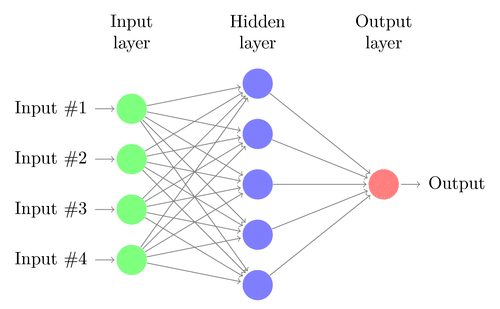
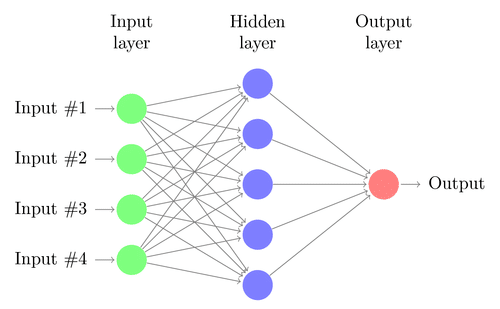
출처: https://research.aimultiple.com/wp-content/uploads/2017/08/neural-network.png
Every input layer feature is interconnected with every hidden layer feature.
Supervised Learning with Neural Networks
structured data : 데이터의 데이터베이스들. 각각의 데이터는 명확한 뜻을 정의.
unstructured data : raw audio, image 같이 이미지 또는 텍스트 내부에 있는 내용을 인식하고자 하는 데이터. 고유의 특성은 이미지의 픽셀 값이나 텍스트에서 개인의 단어가 될 수 있음.
unstructured data를 인식하는 것이 더 어려움.
딥러닝과 신경망의 발전에 따라 unstructured data 인식하는 것이 훨씬 좋아짐.
그러나 경제적 가치를 이끌어 온 상당 부분의 신경망 분야는 structured data.
예) 더 나은 광고 시스템, 수익 추천, 많은 기업들이 정확한 예측을 할 수 있도록 돕는 막대한 양의 데이터베이스들을 프로세싱.
Why is Deep Learning taking off?
강좌에서 m은 # of training examples 의미
Scale drives learning progress
-
Data
-
Computation
-
Algorithms
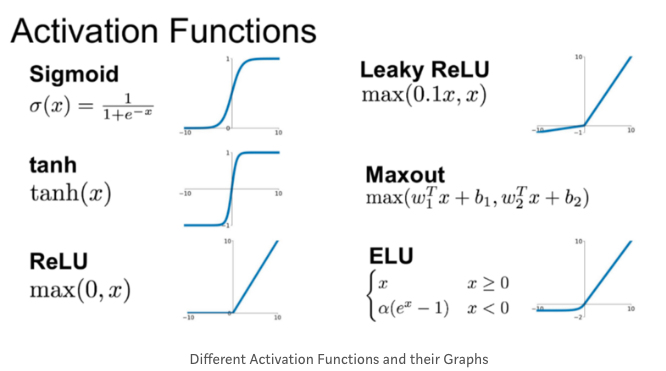
시그모이드 함수에서 ReLU 함수로 변경하면서 gradient descent 알고리즘을 생성해 더 빨리 작용
-
시그모이드 함수는 머신러닝에 적용시키는 경우 함수의 기울기가 0에 가까운 값이 됨 => 러닝 속도가 매우 느려짐. bc 기울기 강하(gradient descent) 도입하는 경우 기울기가 0이면 개체가 매우 느린 속도로 변하기 때문.
-
반면에 Activation function으로 바꾸는 경우엔 신경망이 ReLU(Rectified Liner Unit) 함수를 적용시킴 => 기울기가 모든 양수에 대해 1이 됨 => 기울기가 0으로 줄어드는 확률 급격하게 감소
알고리즘 변형을 통해 코딩이 더 빨리 작동할 수 있도록 환경 제공 => 결과적으로 더 큰 신경망을 트레이닝 가능
빠른 계산이 중요한 또 다른 이유는 네트워크를 트레이닝시키는 과정이 매우 반복적이고 자주 신경망 구조에 대한 발상이나 아이디어가 있는 경우 이러한 발상을 코드화시켜, 그 발상을 바탕으로 실험을 하고, 실험을 통해 신경망이 얼마나 성능을 발휘하는지 확인하고, 다시 돌아가서 네트워크의 상세 내용을 바꾸고, 이러한 원형 프로세스를 계속 반복.
새로운 네트워크가 트레이닝시키는데 오랜 시간이 소요되는 경우엔 이 원형 사이클이 진행되는 시간이 늘어나며 생산성은 큰 차이를 불러옴.빠른 산출은 실험한 내용에 대한 결과를 빨리 확인하는데 큰 도움. 신경망 분야 종사자들이나 리서치 부문 담당자들에게도 도움을 주면서 반복 업무를 더 빨리 가능케 하고 아이디어를 더 신속히 개선시킬 수 있게 되면서 전체적인 딥러닝 커뮤니티에 도움
Quiz
- What does the analogy “AI is the new electricity” refer to?
- Similar to electricity starting about 100 years ago, AI is transforming multiple industries.
- Which of these are reasons for Deep Learning recently taking off? (Check the three options that apply.)
-
We have access to a lot more data.
-
Deep learning has resulted in significant improvements in important applications such as online advertising, speech recognition, and image recognition.
-
We have access to a lot more computational power.
- Recall this diagram of iterating over different ML ideas. Which of the statements below are true? (Check all that apply.)
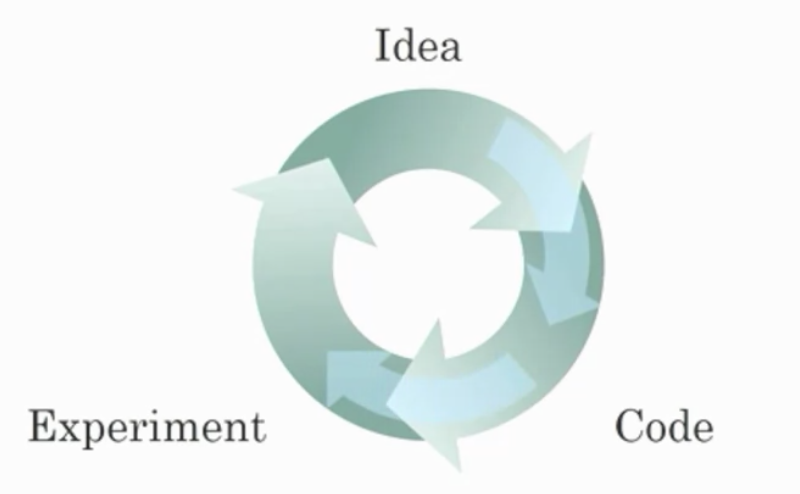
- Being able to try out ideas quickly allows deep learning engineers to iterate more quickly.
- Faster computation can help speed up how long a team takes to iterate to a good idea.
- Recent progress in deep learning algorithms has allowed us to train good models faster (even without changing the CPU/GPU hardware).
- When an experienced deep learning engineer works on a new problem, they can usually use insight from previous problems to train a good model on the first try, without needing to iterate multiple times through different models. True/False?
- False
==> Finding the characteristics of a model is key to have good performance. Although experience can help, it requires multiple iterations to build a good model.
- Images for cat recognition is an example of “structured” data, because it is represented as a structured array in a computer. True/False?
- False
- A demographic dataset with statistics on different cities' population, GDP per capita, economic growth is an example of “unstructured” data because it contains data coming from different sources. True/False?
- False
- Why is an RNN (Recurrent Neural Network) used for machine translation, say translating English to French? (Check all that apply.)
-
It is applicable when the input/output is a sequence (e.g., a sequence of words).
-
It can be trained as a supervised learning problem.
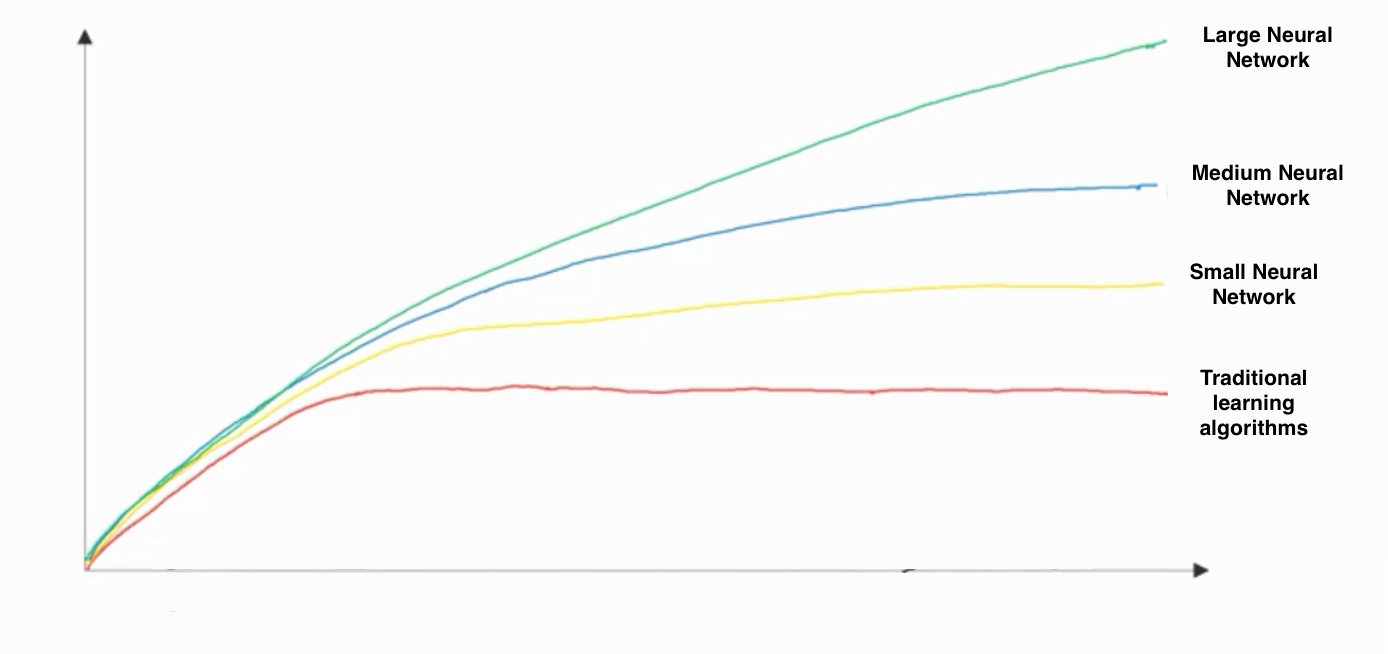
- In this diagram which we hand-drew in lecture, what do the horizontal axis (x-axis) and vertical axis (y-axis) represent?
-
x-axis is the amount of data
-
y-axis (vertical axis) is the performance of the algorithm.
- Which one of these plots represents a ReLU activation function?

- Assuming the trends described in the previous question's figure are accurate (and hoping you got the axis labels right), which of the following are true? (Check all that apply.)
오답:
-
Decreasing the size of a neural network generally does not hurt an algorithm’s performance, and it may help significantly.
==> No. According to the trends in the figure above, big networks usually perform better than small networks. -
Decreasing the training set size generally does not hurt an algorithm’s performance, and it may help significantly.
==> No. Bringing more data to a model is almost always beneficial.
답:
-
Increasing the training set size generally does not hurt an algorithm’s performance, and it may help significantly.
-
Increasing the size of a neural network generally does not hurt an algorithm’s performance, and it may help significantly.

{kind=link}