1. Image Data vs Sequence Data
- Image Data: 고정된 길이(shape)를 가짐 (예: 28×28 픽셀 MNIST).
- Sequence Data: 가변 길이를 가짐.
- 입력이 time step 에 따라 순차적으로 들어옴.
- 문장의 경우 단어 단위(token)로 들어오며, 단어 길이도 다르고 문장 길이도 다름.
예시
“나는 오늘 점심에 햄버거를 먹었다. 햄버거는 맛있다. 하지만 치킨을 더 좋아한다.”
→ "나는" → "오늘" → "점심에" → … → "좋아한다." 순서대로 time step에 맞춰 입력됨.
2. 분포 가설 (Distributed Hypothesis)
- 핵심 가설: “단어의 의미는 주변 단어(문맥)에 의해 결정된다.”
- 즉, 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가짐.
- 현재의 자연어 처리(NLP)는 이 가설을 기반으로 발전.
3. Sequence Data와 RNN
- Sequence Data는 순서가 중요한 데이터이므로 단순 CNN, MLP가 아닌 순환 신경망(RNN)이 적합.
- 대표적 Sequence Model → Language Model.
- 입력 데이터는 반드시 숫자로 표현되어야 하므로 벡터화(Embedding) 필요.
- 과거: One-hot embedding
- 이후: Word2Vec → Sparse vector를 Dense vector로 바꿔 의미 있는 공간에 임베딩.
- 지금은 대부분 학습 가능한 임베딩 레이어 사용.
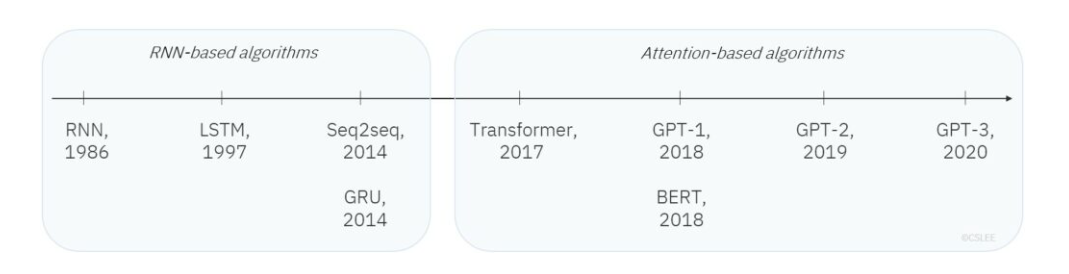
4. NLP 발전 동향
- 초기: RNN 기반
- 이후: Attention 기반 (Transformer 등장, 2017 Attention is All You Need)
- Transformer는 Encoder/Decoder 구조를 활용해 다양한 모델이 탄생:
- BERT: Transformer Encoder
- GPT: Transformer Decoder
- 현재의 대형 언어 모델(ChatGPT, Bard 등) 모두 Transformer 기반.
- Attention mechanism은 현재 딥러닝의 기본 알고리즘.
5. Markov Condition
- 언어 모델은 특정 단어의 등장 확률을 이전 문맥에 의존해 추정.
- 일반적인 수식:
- 전체 문장 확률:
- 하지만 t가 크면 너무 많은 과거 단어들을 고려해야 함 → 비효율적.
- 따라서 최근 n개의 단어까지만 고려한다고 가정. (예: t-1, t-2 단어만)
- 이때, 먼 과거 단어와는 조건부 독립(Conditional Independence) 관계를 맺는다고 가정 → 이것이 Markov Condition.
예시 문장
“나는 오늘 점심에 햄버거를 먹었다.”
- 단어 5개짜리 시퀀스
- Markov 조건을 적용하면:
6. Language Model의 역할
- Language Model의 목표:
즉, 문장 전체가 등장할 확률을 추정하는 것.
- 모델이 예측한 확률이 높고 그 문장이 실제 데이터셋에 존재한다면 → 좋은 성능.
- 반대로 확률이 낮거나 실제 데이터와 안 맞는다면 → 학습이 부족한 상태.
- 결국 Language Model은 text sequence의 joint probability를 추정하는 모델

Data Engineer