1. Word Embedding 개념
기본 개념
- 단어를 Dense vector(실수 벡터)로 변환하는 방법.
- 과거에는 Sparse vector(One-hot encoding) 사용:
- “고양이”가 10개 클래스 중 하나라면 [0,0,1,0,0,0,0,0,0,0]
- 대부분 0 → 차원이 커질수록 비효율적.
- Dense vector는 훨씬 작은 차원(예: 128)으로 단어를 표현.
- “강아지” → [0.2, 0.8, -1.1, …, 0.5]
2. Word2Vec (대표적인 Word Embedding 모델)
-
Word2Vec은 분포 가설(distributional hypothesis) 기반
“비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다.” -
학습 방식 두 가지
- CBOW (Continuous Bag of Words)
- 주변 단어(맥락, context) → 중심 단어 예측
- Skip-Gram
- 중심 단어 → 주변 단어 예측
- CBOW (Continuous Bag of Words)
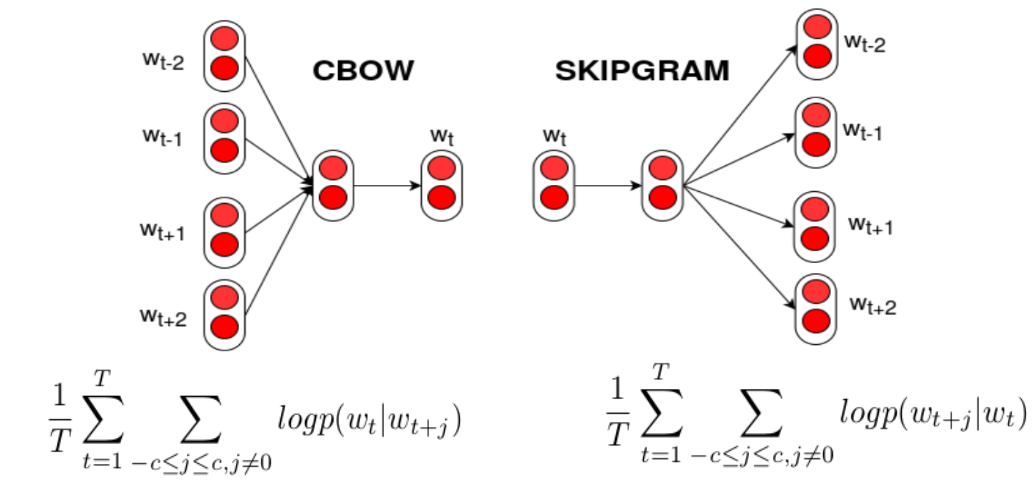
3. CBOW (Context → Center Word)
개념
- 주변 단어들을 입력으로 받아 가운데 단어를 예측.
- 윈도우(Window) 크기를 정해 입력 단어 범위 결정.
예시
문장: “귀여운 강아지가 의자 위에 앉아있다.”
- 목표: “의자” 예측 (w_t)
- 윈도우 크기 = 1이라면 입력: “강아지가”( w{t-1} ), “위에”( w{t+1} )
- 출력: “의자” 원핫 벡터
- Softmax + Cross-Entropy Loss로 학습.
4. Skip-Gram (Center Word → Context)
개념
- 중심 단어를 입력으로 넣고, 주변 단어들을 예측.
- CBOW의 반대 방향.
예시
- 중심 단어: “의자”
- 윈도우 크기 = 2 → 예측 대상: “강아지가”, “위에”, (앞뒤 단어들)
- 일반적으로 CBOW보다 Skip-Gram이 성능이 우수하다고 알려짐.
5. Word2Vec의 신경망 구조
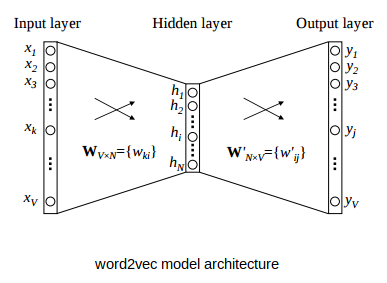
- CBOW, Skip-Gram 모두 얕은 신경망 (hidden layer = 1)
- Activation Function 없음 → 선형 연산만
- 가중치 행렬
- Input–Hidden:
- Hidden–Output:
- 두 행렬 크기는 서로 반대지만 전치 관계는 아님.
- 학습 후, W_1, W_2가 Embedding Matrix로 사용됨.

Data Engineer