1. Recurrent Neural Network (RNN)
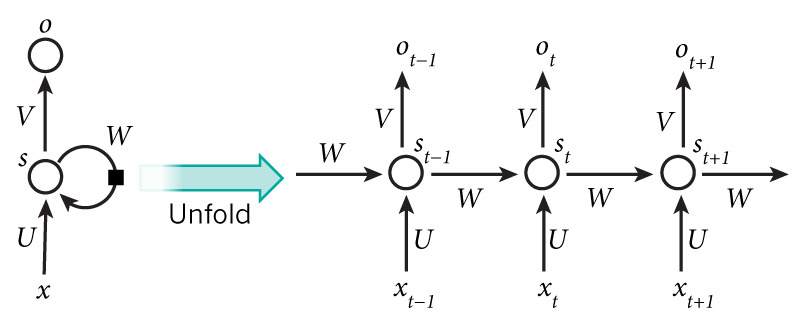
개념
- 순환 구조: Hidden node가 방향을 가진 edge로 연결되어 이전 상태 정보를 다음 state로 전달.
- 입력: 시점 의 단어
- Hidden State:
- 출력:
- Shared Weights: 모든 시점에서 동일한 를 공유.
- 따라서 에는 지금까지의 모든 입력 정보가 메모리처럼 저장됨.
2. RNN의 한계: Gradient Vanishing Problem
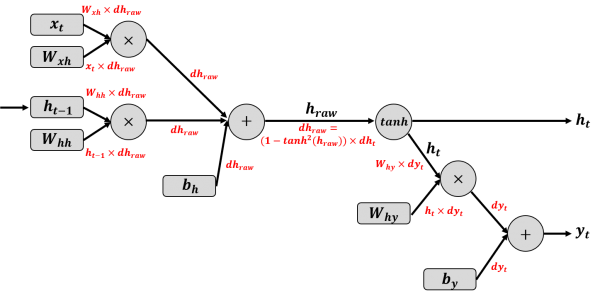
동작
- 학습 시 역전파도 시간축을 따라 거꾸로 전파됨 → 이를 BPTT (Backpropagation Through Time)라고 함.
- 시간이 길어질수록(시퀀스 길어질수록), gradient가 곱해지며 점점 작아져서 0에 수렴.
- 결국 오래된 정보(먼 과거 단어)는 학습이 잘 안 됨.
- RNN은 장기 의존성(long-term dependency) 학습에 취약.
3. LSTM (Long Short-Term Memory)
개념
- Gradient Vanishing 문제 해결을 위해 고안된 RNN 변형.
- 아이디어: 단순히 모든 과거 정보를 전달하지 않고, 시점마다 “무엇을 기억할지 / 무엇을 버릴지”를 Gate로 제어.
- 내부에 별도의 Cell state ()를 두어 정보를 장기적으로 유지.
4. LSTM 동작 단계 (Gate 구조)
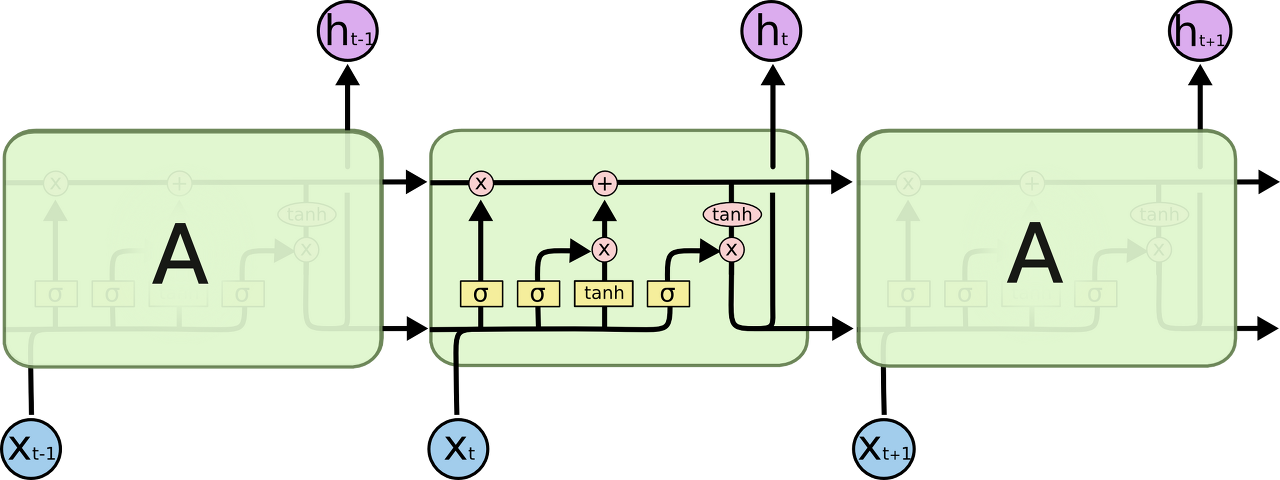
(1) Forget Gate (망각)
- 이전 시점의 정보를 얼마나 버릴지 결정.
- : 전부 버림 / : 전부 유지
(2) Input Gate (저장)
-
현재 시점 입력에서 어떤 정보를 새로 저장할지 결정.
-
후보 정보():
(3) Cell State 업데이트
- 과거 cell state와 현재 정보를 합쳐 새로운 cell state 형성.
(4) Output Gate (출력)
-
최종 출력 를 결정.
-
즉, LSTM은 매 시점마다 버릴 것, 추가할 것, 출력할 것을 선택하며 장기 의존성을 유지.
5. 예시
문장: “나는 오늘 점심에 햄버거를 먹었다.”
- 일반 RNN: 멀리 떨어진 “나는”과 “먹었다” 관계가 gradient vanishing 때문에 잘 학습되지 않음.
- LSTM: “Forget gate”가 불필요한 단어 정보는 줄이고, “Input gate”가 “먹었다”와 관련 있는 단어 정보를 저장하여 장기 의존성 보존.

Data Engineer