1. Seq2Seq (Sequence-to-Sequence)
개념
- 기계 번역과 같이 입력과 출력이 모두 시퀀스인 Task에 쓰이는 대표적 모델.
- Encoder-Decoder 구조로 이루어짐.
- Encoder: 입력 문장을 읽어 고정된 길이의 Context Vector로 요약.
- Decoder: Context Vector를 입력받아 출력 문장(번역 결과)을 순차적으로 생성.
- 각 모듈은 보통 RNN/LSTM/GRU로 구현됨.

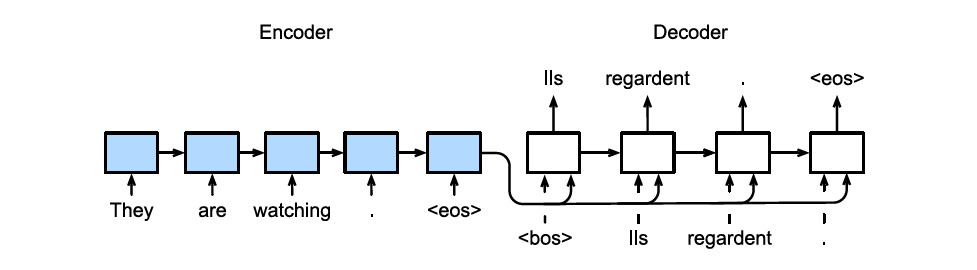
2. Encoder 동작
- 입력 문장: "They are watching the movie."
- 토큰 단위 입력: They → are → watching → the → movie
- 각 시점마다 hidden state 업데이트:
- 최종적으로 Encoder는 Context Vector 를 출력.
- 입력 길이가 달라도 Context Vector는 고정 길이.
3. Decoder 동작
- Context Vector c와 이전 시점의 토큰을 입력받아 번역된 단어를 생성.
- 학습 시에는 Teacher Forcing 사용
- Decoder가 이전 시점의 출력 단어 대신, 정답 라벨을 입력받음.
- 잘못된 예측이 누적되는 것을 방지.
- 테스트 시에는 라벨이 없으므로, Decoder는 자신이 이전에 출력한 단어를 입력으로 사용.
4. 예시
- 번역 Task: 영어 → 한국어
- 입력: "They are watching the movie."
- Encoder → Context Vector 생성
- Decoder:
- t=1: Context Vector + → “그들은”
- t=2: Context Vector + “그들은” → “영화를”
- t=3: Context Vector + “영화를” → “보고 있다”
- t=4: (문장 종료)
- 이렇게 시점마다 단어를 순차적으로 생성.
5. Seq2Seq의 한계
- Context Vector가 고정 길이라 긴 문장의 정보 손실 발생.
- 이후 Attention Mechanism이 도입되어 개선됨. (다음 글에서 다룸 예정)
6. BLEU Score (기계번역 평가 지표)
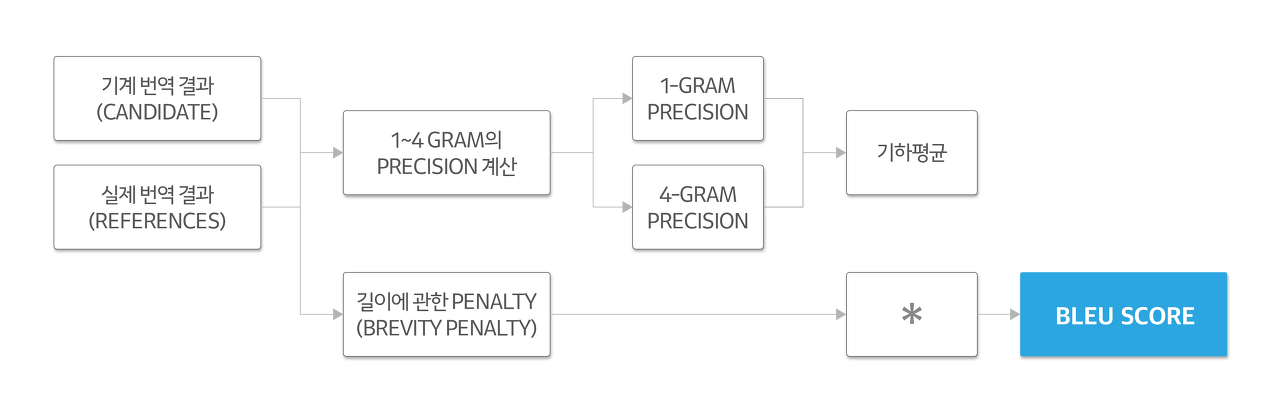
개념
- Candidate(모델 번역 결과)와 Reference(사람 번역 결과)를 비교.
- N-gram Precision과 Brevity Penalty를 결합한 점수.
N-gram Precision
- 문장을 N-gram 단위로 나누어 Reference와 겹치는 부분 비율 계산.
예시
Reference: "나는 오늘 여자친구와 함께 저녁을 먹었다."
Candidate: "나는 어제 여자친구와 따로 저녁을 먹었다."
- 1-gram Precision: Candidate 단어 중 Reference에 있는 단어 비율.
- Candidate 단어: 나는, 어제, 여자친구와, 따로, 저녁을, 먹었다
- Reference에 존재: 나는, 여자친구와, 저녁을, 먹었다 (4개)
- 총 단어 6개 → Precision = 4/6 = 2/3.
Brevity Penalty
- 번역 문장이 Reference보다 지나치게 짧으면 불이익 부여.
- : Reference 길이, : Candidate 길이
최종 BLEU 계산
- 1-gram ~ 4-gram Precision의 기하평균 계산 후 BP와 곱해 점수 산출.
- 값은 0~1 사이, 보통 %로 환산.

Data Engineer