1. CNN (Convolutional Neural Network)
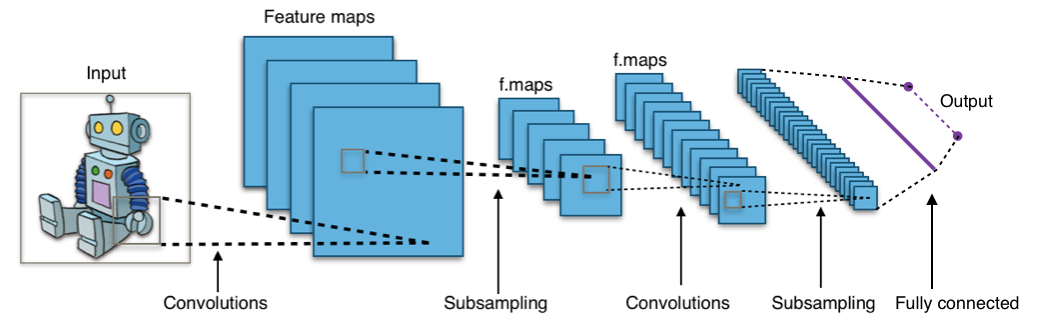
- 적용 분야: 이미지, 영상 등의 공간적 구조가 있는 데이터에 특화된 신경망.
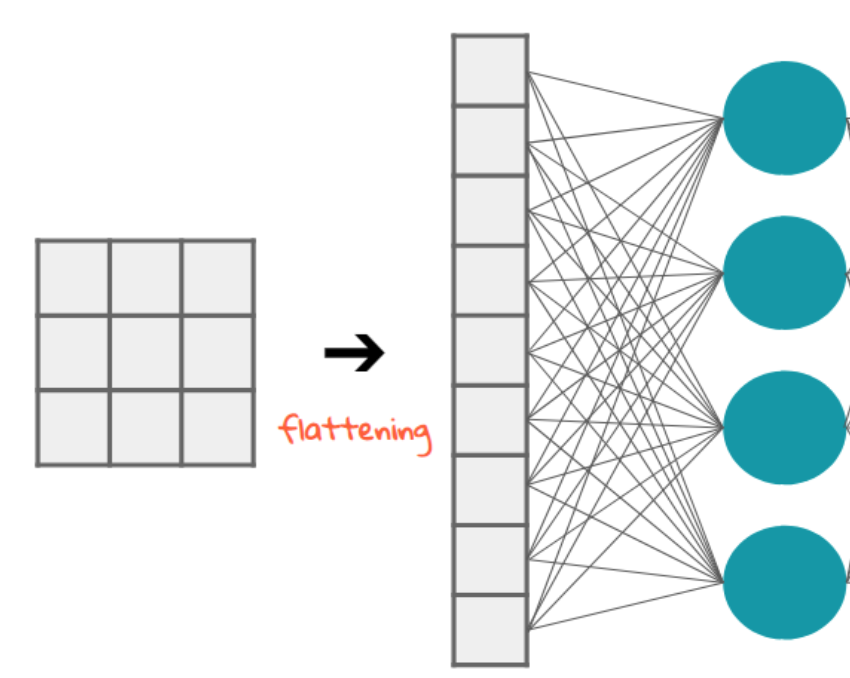
- 기존 방식의 한계: 1D로 펴는 방식(flattening)은 픽셀 간 공간 관계를 없애버려 정보 손실 유발.
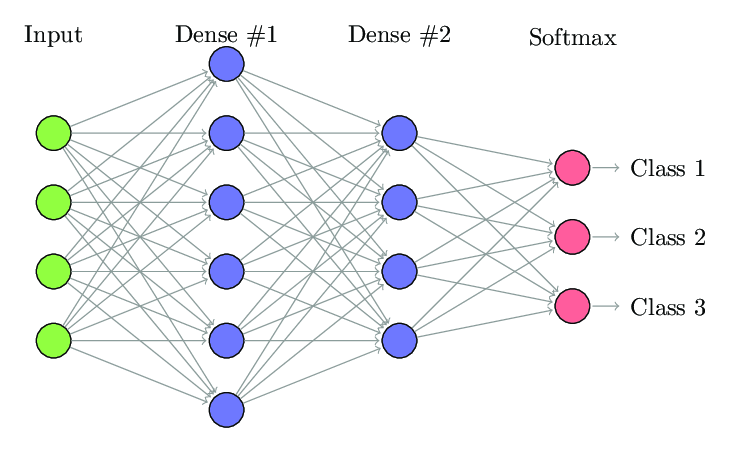
-
해결책: 위 그림은 Fully Connected Layer 이다. 기존의 Fully Connected Layer에 Convolution Layer와 Pooling Layer를 추가.
-
구성 요소 역할
-
Convolution: 지역 특징 추출 (필터로 인접한 픽셀의 상관관계를 효율적으로 반영)
-
Pooling: 축소 및 요약 → 위치 불변성 확보
-
결국, 이미지의 특징(feature)을 뽑아서 분류(classification)를 수행.
-
2. RNN (Recurrent Neural Network)
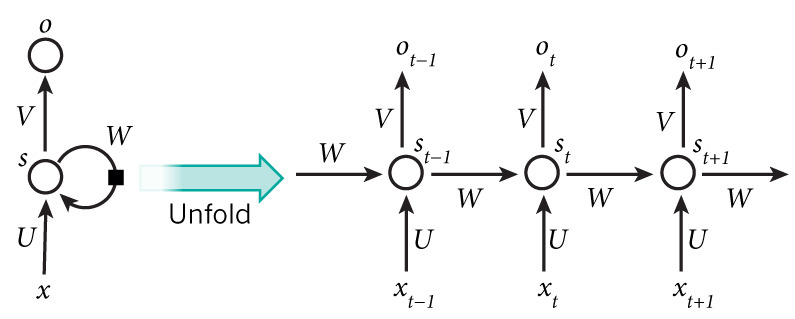
-
적용 분야: 순서(sequence)가 중요한 데이터 (예: 자연어 처리)에 특화된 구조.
-
핵심 구조 차이점
- 이전 신경망 계층들은 “Feed-Forward” 방식이었는데,
- RNN은 현재 입력뿐만 아니라 이전 시점의 hidden state도 함께 입력으로 받아 순환 구조를 이룹니다.
-
의미: 각 시점 에서 입력 와 이전 시점의 hidden 상태 를 이용해 를 계산 → 시퀀스의 시간적 맥락을 반영.
-
학습 방식: 역전파의 시퀀스 확장 버전인 Backpropagation Through Time (BPTT)를 사용.
3. GAN (Generative Adversarial Network)
-
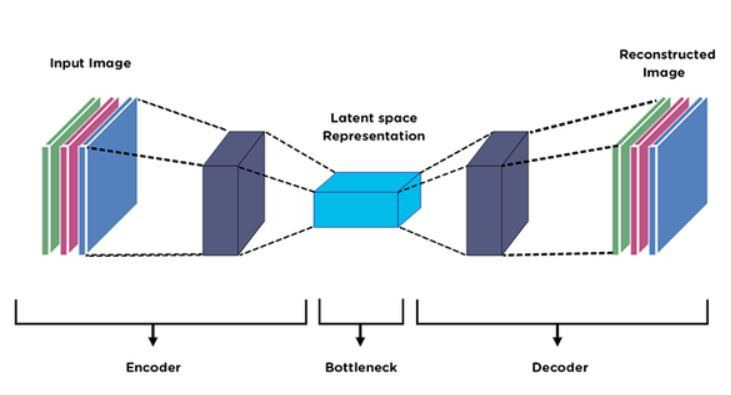
구조 기반: 데이터의 잠재 공간(latent space)을 학습하고, 재구성하는 Encoder–Decoder 기반 아키텍처 이해에서 출발.
-
Encoder–Decoder 구조
- Encoder: 원본(input) 데이터를 저차원 latent space representation으로 압축.
- Decoder: latent representation에서 다시 원본 데이터 형태로 복원.
-
GAN 구성 요소
- Generator: latent representation을 입력받아 ‘진짜처럼 속일 수 있는’ 가짜 데이터를 생성.
- Discriminator: 생성된(fake) 데이터와 실제(real) 데이터를 구분하는 판별자 역할을 수행.
-
적대적 학습: Generator는 Discriminator를 속이려고, Discriminator는 가짜 데이터를 잘 구분하려는 경쟁적(adversarial) 관계 형성.
요약
-
CNN은 어떤 특성을 기반으로 이미지에 강한가요?
- 공간 구조를 보존하면서 지역 특성을 추출하기 때문입니다. Flatten하지 않고 convolution + pooling을 통해 효율적으로 특징을 잡아냅니다.
-
RNN은 언제 사용되며, 왜 순환 구조가 중요한가요?
- 언어와 같이 순서가 중요한 데이터를 순차적으로 처리하며, 이전 상태를 현재 계산에 반영해 문맥을 이해할 수 있습니다.
-
GAN이 왜 “적대적” 네트워크인가요?
- Generator는 진짜 같은 데이터를 만들고, Discriminator는 이를 구분하려고 하며, 이 경쟁적 학습 구조가 고품질 데이터 생성을 가능하게 합니다.

Data Engineer