커널 SVM
XOR은 본질적으로 linear 하게 분류를 할 수가 없습니다. 하지만 1992년에 커널 트이 등장하게 됩니다. 커널 트릭이 바로 svm 을 기계학습 분야에 대세로 만든 방법 입니다.
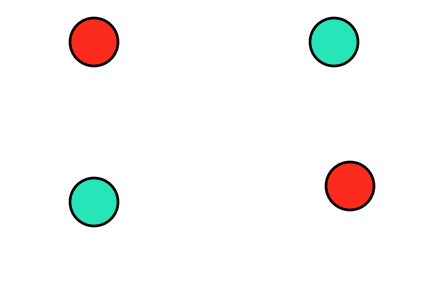
Basic Idea
커널은 쉽게 말해 더 높은 차원에서 데이터를 바라보는 것입니다. 차원이 높아지면 전 차원에서는 볼 수 없었던 것들을 쉽게 바라볼 수 있게 된다.

이 미로가 5cm의 벽으로 만들어졌다고 해봅니다. 만약 개미가 이런 미로를 통과한다고 하면 매우 어렵겠죠. 자기가 가는 길을 모두 기억해야 하니까요. 하지만 사람이 책상에 앉아 미로를 보면 금세 미로를 빠져나갈 길을 찾을 수 있습니다.
개미에게는 왜 미로가 어렵고 사람한테는 쉬울까요?
바로 사람은 한차원 높은 공간에서 미로를 바라보기 때문입니다. 개미는 미로 속을 돌며 2차원의 공간에서 답을 찾지만 사람은 그 위인 3차원에서 답을 찾습니다. 단지 차원이 하나만 높아졌지만 답을 찾기는 훨씬 쉬워졌죠.
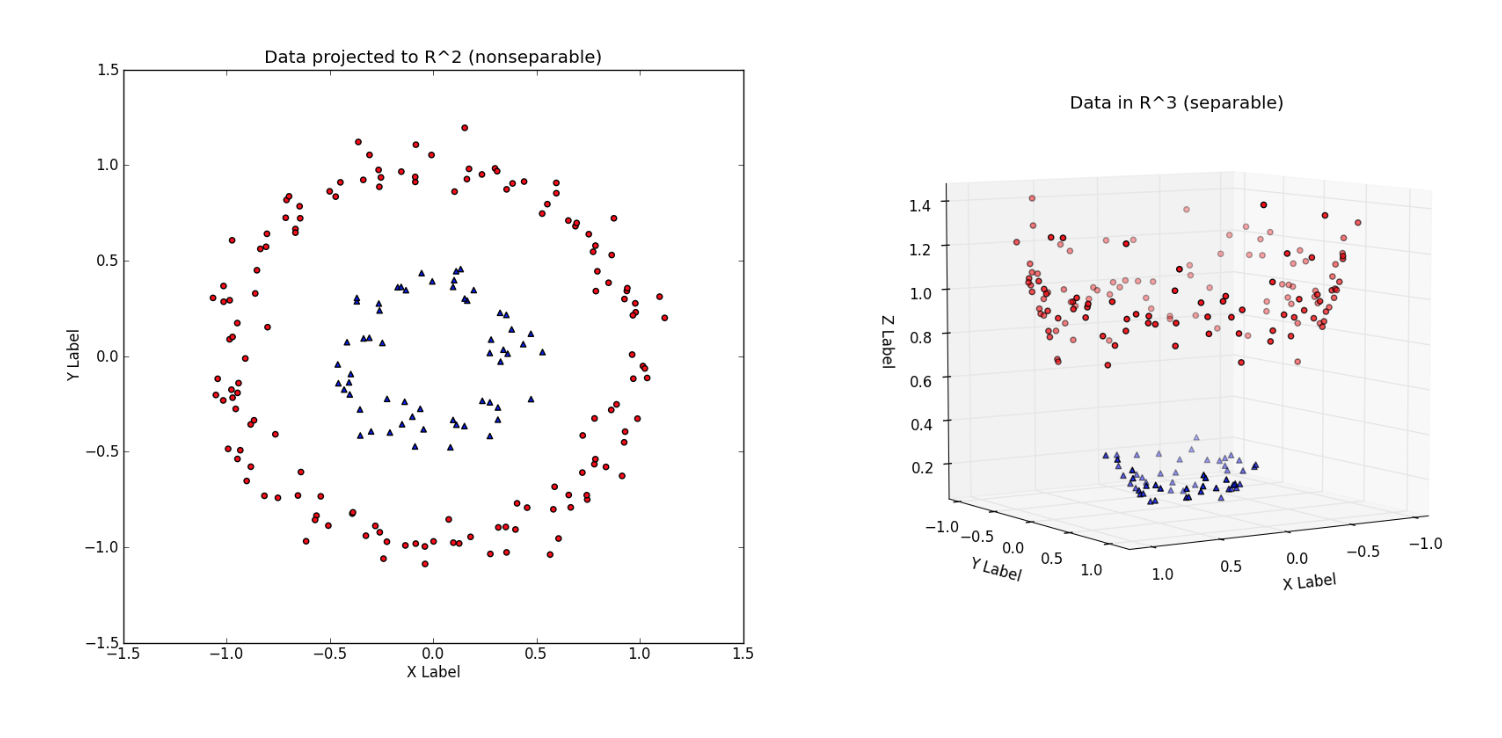
이 그림은 2차원에 있던 데이터를 3차원으로 바라보았습니다. 2차원에서는 불가능하던 linear 분류를 3차원에서는 면을 중간에 그음으로 가능하게 되었죠.
Mapping
커널은 input space 에 존재하는 데이터들을 feature space 로 옮겨주는 역할을 하는 mapping 입니다. 보통은 ϕ로 표기한다. 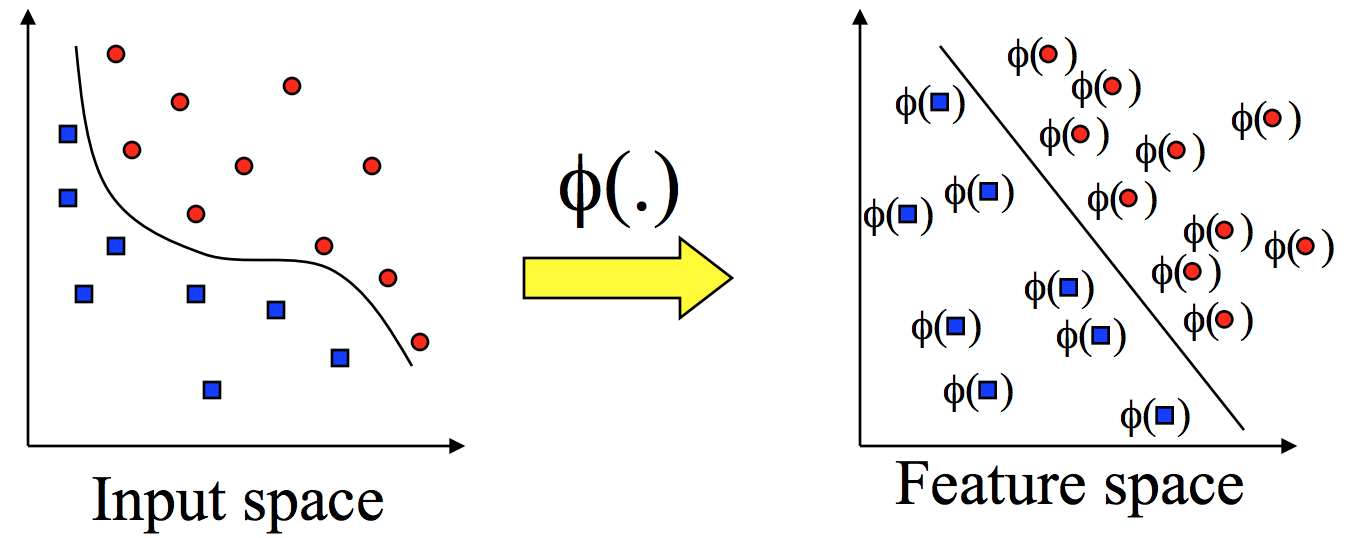
NB(Naive Bayes)
나이브 베이즈 분류는 베이즈 정리에 기반한 통계적 분류 기법입니다. 가장 단순한 지도 학습 (supervised learning) 중 하나입니다. 나이브 베이즈 분류기는 빠르고, 정확하며, 믿을만한 알고리즘입니다. 정확성도 높고 대용량 데이터에 대해 속도도 빠릅니다.
나이브 베이즈는 feature끼리 서로 독립이라는 조건이 필요합니다. 즉, 스펨 메일 분류에서 광고성 단어의 개수와 비속어의 개수가 서로 연관이 있어서는 안 됩니다.
나이브 베이즈는 어떻게 동작하는가?
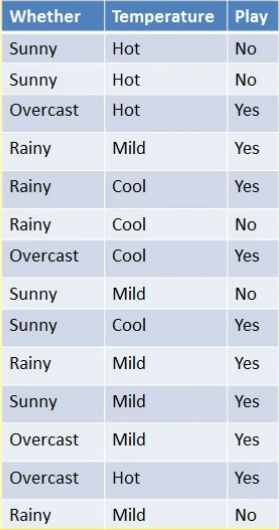
날씨 정보와 축구 경기 여부에 대한 데이터가 있습니다. 날씨에 대한 정보를 기반으로 축구를 할것인지 안 할 것인지 확률을 구하는 예제입니다.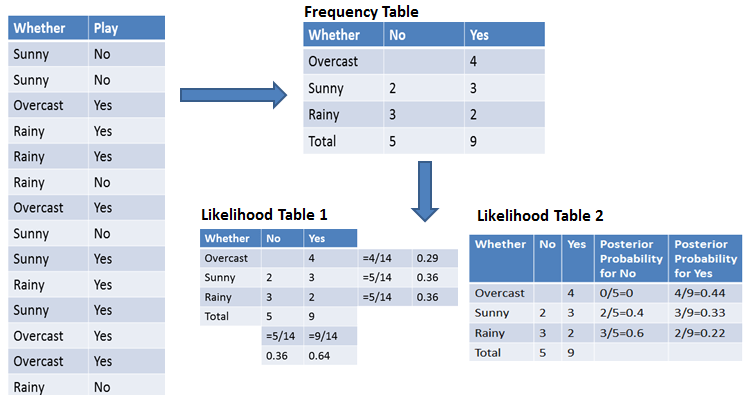
먼저, 맨 왼쪽 테이블을 보겠습니다. 날씨에 따라 축구를 했는지 안했는지에 대한 과거 데이터입니다. 이 과거 데이터를 먼저 Training 시켜 모델을 만든 뒤 그 모델을 기반으로 어떤 날씨가 주어졌을 때 축구를 할지 안 할지 판단하는 것이 목적입니다.
Frequency Table은 주어진 과거 데이터를 횟수로 표현한 것입니다. Likelihood Table 1은 각 Feature (여기서는 날씨)에 대한 확률, 각 Label (여기서는 축구를 할지 말지 여부)에 대한 확률을 구한 것입니다. Likelihood Table 2는 각 Feature에 대한 사후 확률을 구한 것입니다.
나이브 베이즈의 장점
- 간단하고, 빠르며, 정확한 모델입니다.
- computation cost가 작습니다. (따라서 빠릅니다.)
- 큰 데이터셋에 적합합니다.
- 연속형보다 이산형 데이터에서 성능이 좋습니다.
- Multiple class 예측을 위해서도 사용할 수 있습니다.
나이브 베이즈의 단점
-feature 간의 독립성이 있어야 합니다. 하지만 실제 데이터에서 모든 feature가 독립인 경우는 드뭅니다. 장점이 많지만 feature가 서로 독립이어야 한다는 크리티컬한 단점이 있습니다.
의사결정 트리
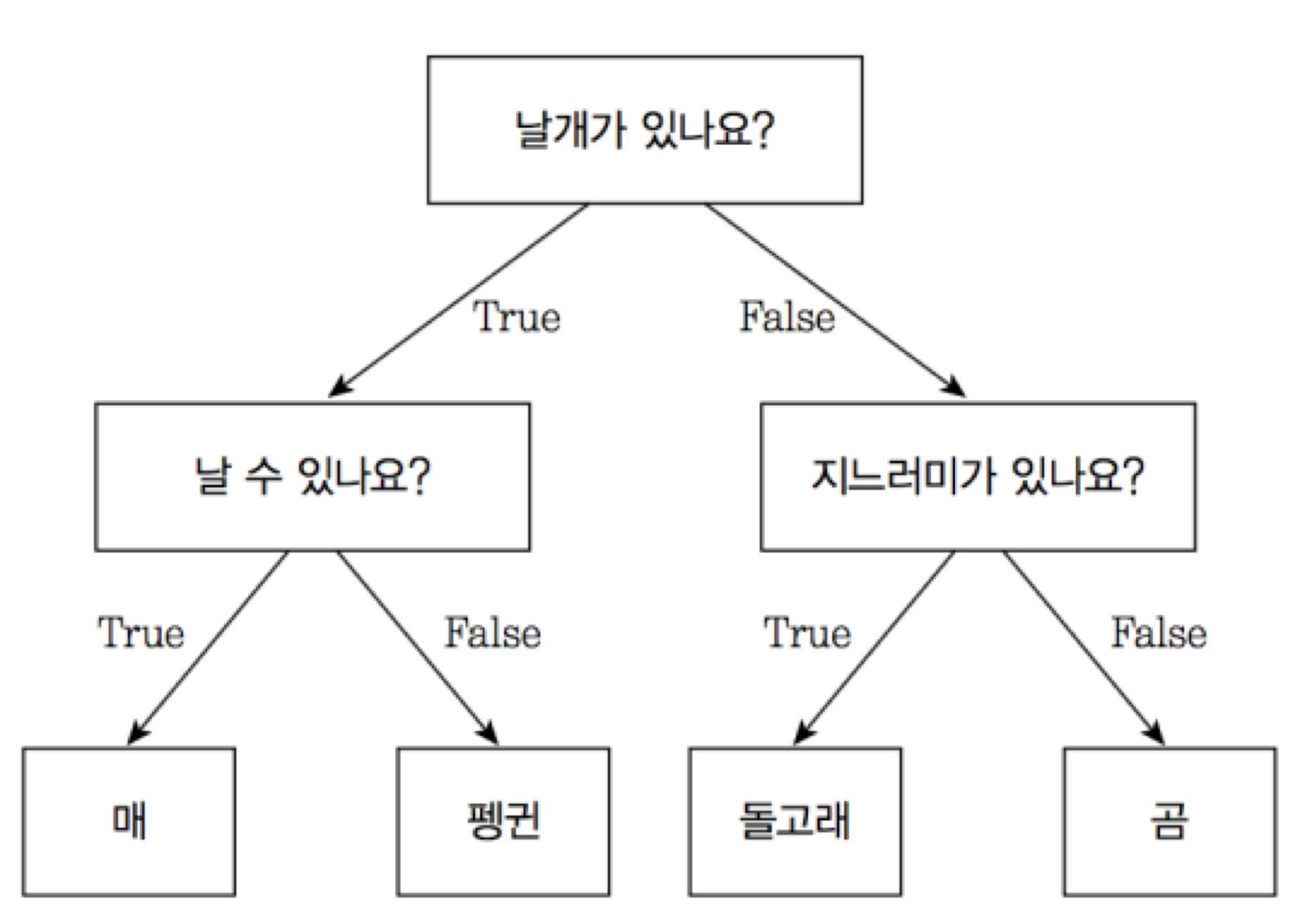
우리가 자주하는 스무고개와 같은 방식으로 예, 아니오를 반복하며 추론하는 방식입니다. 생각보다 성능이 좋아 간단한 문제를 풀 때 자주 사용된다.
랜덤 포레스트
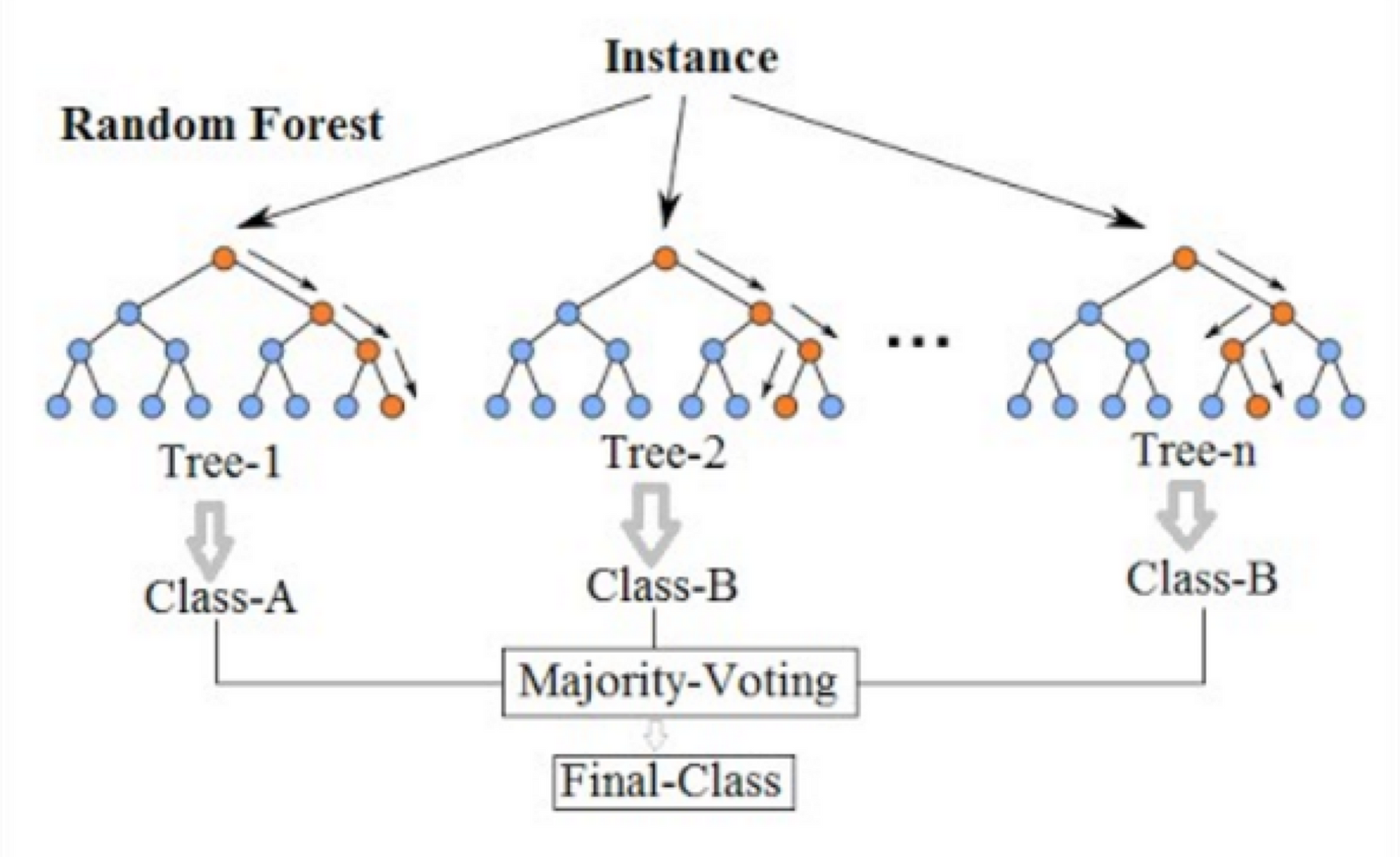
의사결정나무를 여러개 합친 모델입니다. 의사결정나무는 한 사람이 결정하는 것이라고 하면 랜덤 포레스트는 자유민주주의라고 보면 이해가 빠릅니다. 각각의 의사결정나무들이 결정을 하고 마지막에 투표(Majority voting)을 통해 최종 답을 결정하게 되는 모델입니다.
