
오늘은 유방암 분류 프로젝트를 해볼 생각이다. 우선 데이터셋에는 30개의 특징(feature)이 있고 해당 데이터가 악성인지==0,혹은 음성인지==1 이진 분류가 되어있는 상태이다. 기법으로느 SVM을 사용할 예정이다.
SVM
분류(classification), 회귀(regression), 특이점 판별(outliers detection) 에 쓰이는
지도 학습 머신 러닝 방법 중 하나이다. 이 프로젝트는 데이터가 이진으로 나뉘어져 있기 때문에 선형일거라 가정을하고 SVC(Support Vector Classification)을 사용할 것이다.
SVC
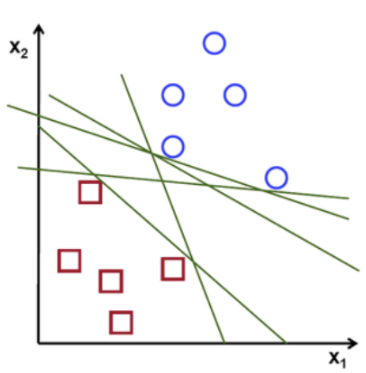
예를 들어, 동그라미와 네모로 두 범주를 나누는 분류 문제를 푼다고 가정해보자.
구분을 위해 두 범주 사이에 선을 긋는다고 한다면, 위 그림과 같이 다양한 방법으로 선을 그을 수 있다.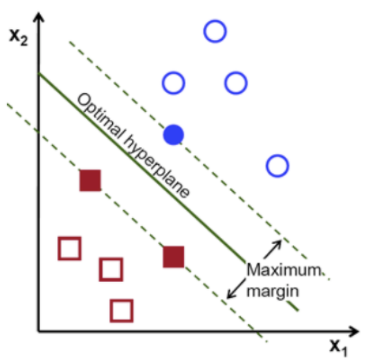
만약, 위 그림처럼 두 개의 점선으로 두 그룹을 구분할 수 있다면
두 점선 간 거리를 마진(Margin) 이라고 하며
마진이 최대값을 가질 때의 중간 경계선을, 최적 초평면(optimal hyperplane) 또는 결정 경계(Decision Boundary) 라고 한다.
따라서, SVM 은 각 그룹이 최대로 떨어질 수 있는 최대 거리(최대마진)를 찾고 ,
해당 거리의 중간지점(최적 초평면)으로 각 그룹을 구분짓는 기법이다.
이와 같은 SVC 는 데이터가 선형인 경우에는 잘 작동하지만, 데이터가 비선형인 경우에는 잘 작동하지 않을 수 있다. 반대로 SVR은 데이터가 비선형일때 사용하기 적절하며, SVC와 그목표를 반대로 하면 되는데, 마진 내부에 데이터가 최대한 많이 들어가도록 학습하는 것이다.
마진의 폭은 epilson 이라는 하이퍼파라미터(절대상수)를 사용하여 조절이 가능하다.
Importing data
필요한 라이브러리들을 importing 해준다.

그리고 우리가 오늘 사용할 데이터를
from sklearn.datasets import load_breast_cancer부분으로 지정을해주고
cancer = load_breast_cancer()이 구문으로 인스턴스화 시킨다. cancer을 찍어보면 이와같이 출력된다.
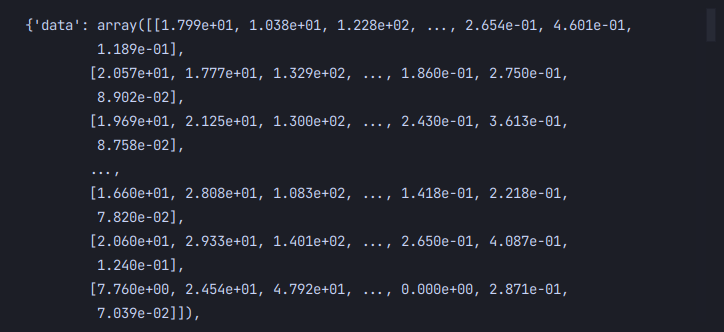
해당 데이터가 dic형태로 되어있기에 .keys로 key값에 접근할 수도 있다.

shape을 찍어보면
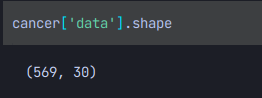
이처럼 569개의 데이터가 30개의 칼럼을 갖고있는걸 확인할 수 있다!
마지막으로 df에 가둬주면 모든 준비는 끝난다!
Visualizing
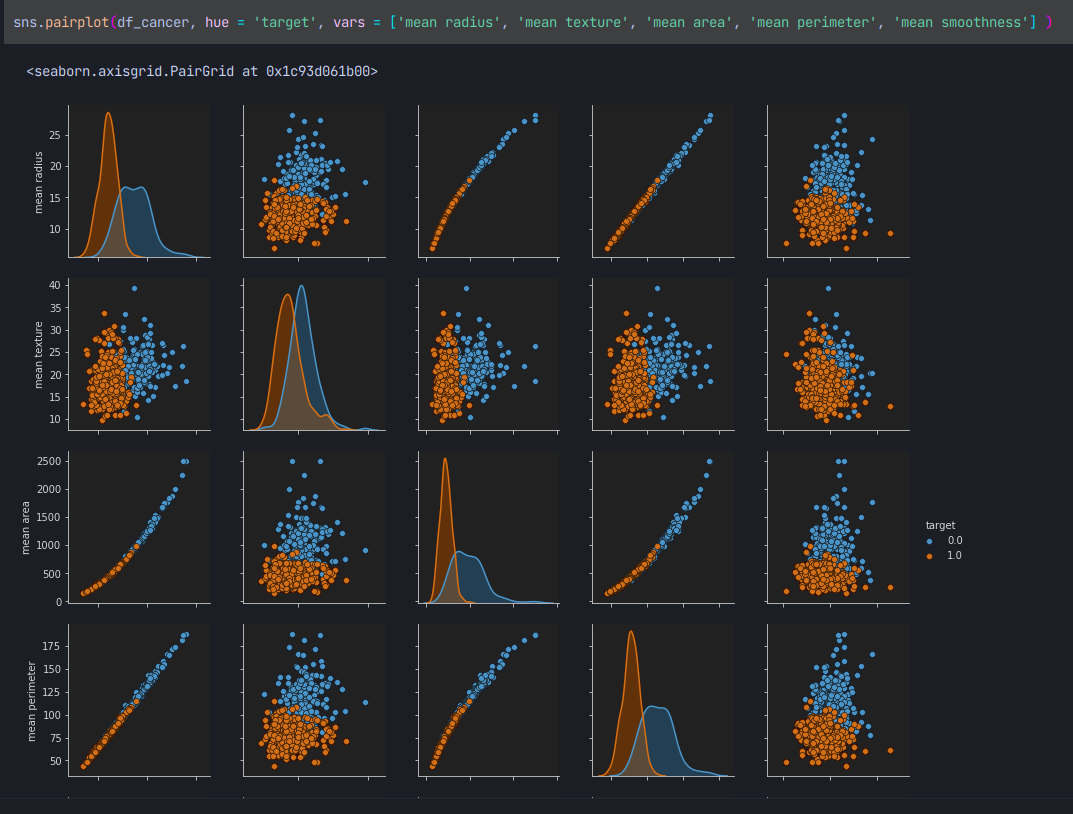
아까 불러왔던 seaborn을 이용하여 원하는 컬럼의 데이터를 시각화 할수 있다.
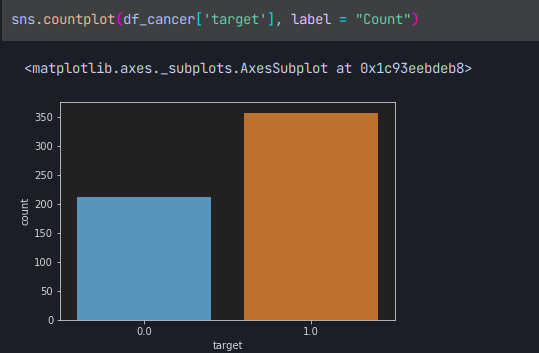
악성종양과 음성의 수를 시각화 할수 있다.
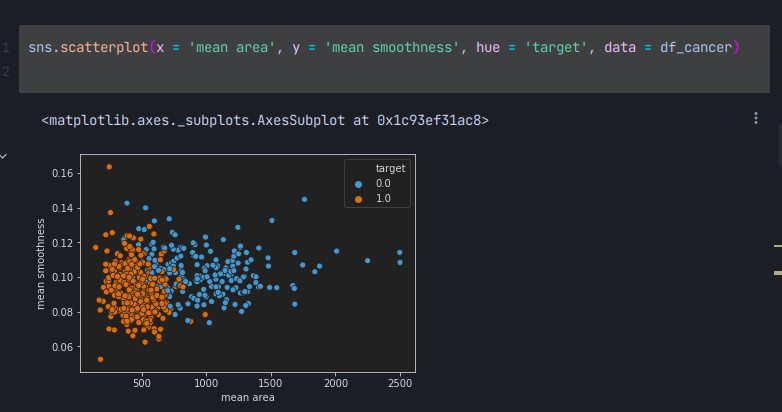
마지막으로 산포도를 그려보면
히트맵도 그려볼수 있는데

이와같이 작성해주면
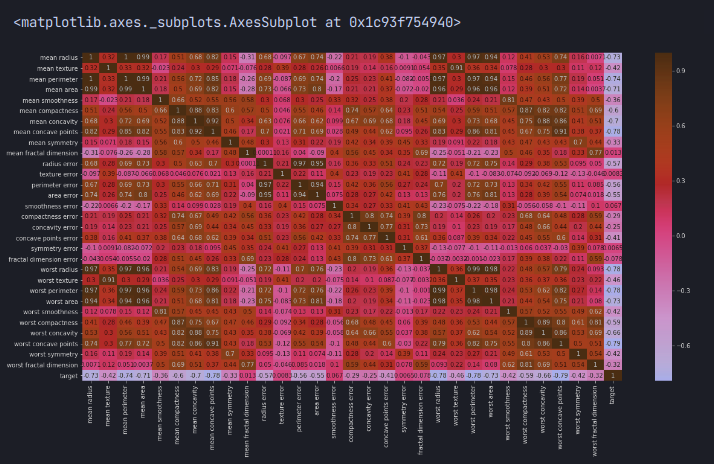
다소 어지러운 히트맵도 그려볼 수 있다.
Fitting
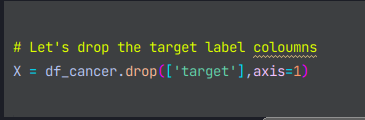
drop함수를 사용하여 target을 제외한 칼럼을 axis=1로 합쳐주어야 한다.
y 는우리가 예측할 값인 악성종양인지, 음성인지를 나타내는 지표이므로 'target'을 지정해준다.
데이터셋 분할

데이터셋을 sklearn의 train_test_split 함수를 사용하여 간단히 분할해주면 된다. test_size를 지정해주면 되는데 R에서는 test_size가 아닌 학습데이터셋을 지정해주어야 하는걸 주의해야 한다.
데이터셋 분할이 완료 되었으면 fitting을 하면되는데 우리는 이번 유방암 분류 모델을 SVC로 학습시킬 계획에 있기에 svm중에서도 SVC함수를 사용하여 학습시키면 된다.
모델평가
seaborn을 이용하여 다시 히트맵을 그려보면
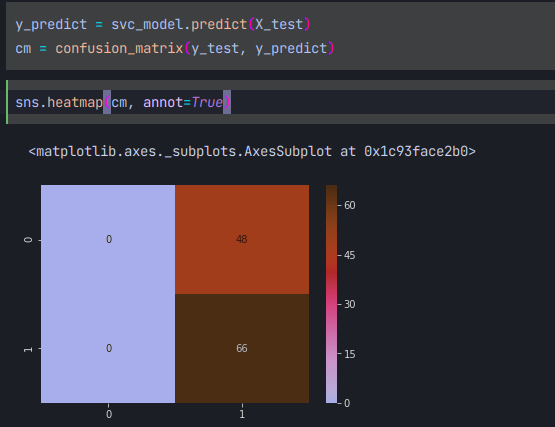
이와같은 히트맵을 얻을수 있고, 오분류가 48개 인것을 확인할 수 있다. 이는 오분류가 상당히 많은 수치인 것인데. 특히나 의학관련 머신러닝 모델은 상당히 높은 acc을 요구하는것이 일반적이기에 실사용은 어려운 모델이라는 것을 알 수 있다. 쉽게 생각해서 최적의 경계선을 DB를 찾지 못하였음을 우리는 인지할 수 있다.
모델 개선하기
감마 파라미터와 C 파라미터(절대상수,하이퍼 파라미터)를 조정해야 하니 우리는 정규화를 수행해야 한다.
위처럼 Xtrain의 min값을 얻은후
X_train_scaled = (X_train - min_train)/range_train이처럼 스케일해주게되면
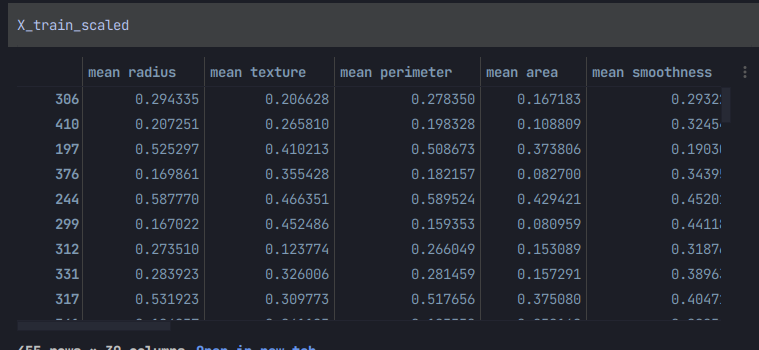
스케일된 데이터를 얻을 수 있다
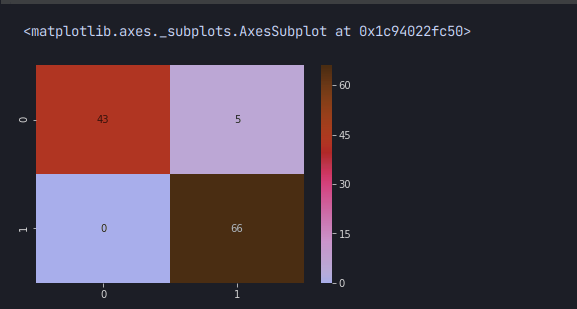
이를 다시 학습시킨후 히트맵을 그려보면
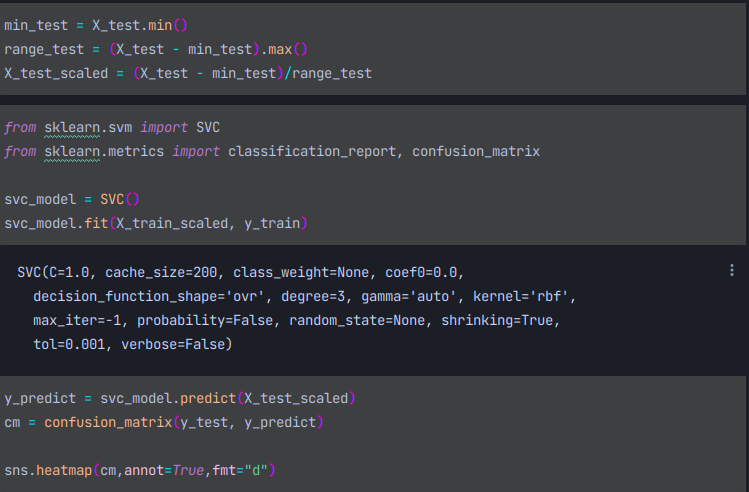
오분류가 단 5건밖에 되지 않는다.
위에서 말했듯이 최적의 절대상수를 찾아야 하는데 이는 sklearn의 GridSearchCV를 사용하여 찾으면 된다.

커널은 지정해주지 않으면 알아서 rbf가 디폴트로 지정되지만 명시적으로 적어주었다.
grid.bestparams
grid.bestestimator
위의 두코드만 적어주면 최적의 감마 파라미터와 C파라미터를 자동으로 찾아준다
마지막으로 행렬 계산만 해주면되는데
이와같이 작성해주면 계산이되고 이를 히트맵으로 그리면
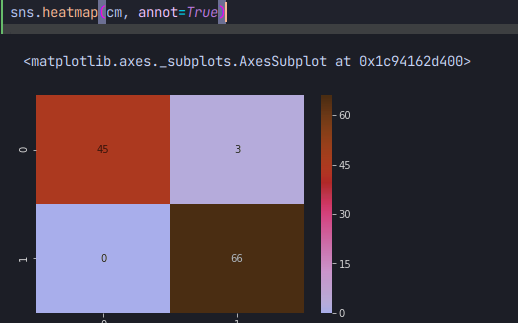
이와같은 결과가 출력된다.
마지막으로 우리모델의 분류보고서를 출력해보면
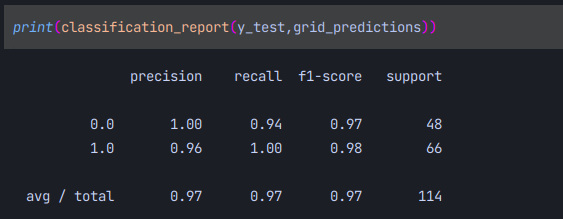
오분류3건의 정확도 acc 97%의 모델을 빌드할 수 있었다!
