PROBLEM STATEMENT AND BUSINESS CASE
7만개의 이미지중 6만개의 학습 이미지와 1만개의 검증 데이터셋으로 구성되어있는 데이터셋을 이용하여 프로젝트를 진행할 것이다. 각이미지의 크기는 28x28이며 그레이 스케일이미지로 구성되어있다. 그리고 해당 사진들은 모두 0~9까지의 인덱스로 레이블링 되어있으며
0 => T-shirt/top
1 => Trouser
2 => Pullover
3 => Dress
4 => Coat
5 => Sandal
6 => Shirt
7 => Sneaker
8 => Bag
9 => Ankle boot
위처럼 레이블링되어있다.
IMPORTING DATA
항상 그렇듯 pd,np,plt를 임포트 해온뒤 추가적으로 sns와 random을 import해오면 된다.
train set과 test set을 pd.read_csv함수로 읽어와서 할당해 주면 된다.
VISUALIZATION OF THE DATASET
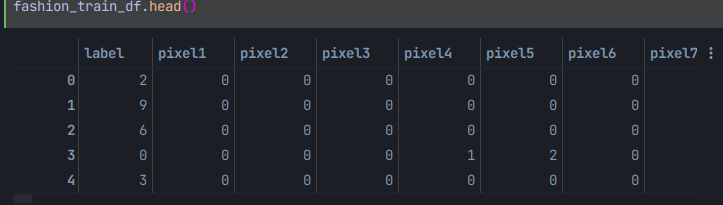
df.head()로 사용할 데이터를 확인한다.
각 이미지를 평탄화 하여서 각행이 이미지를 나타내도록 하였다는걸 확인할 수 있다.

데이터셋을 np.array형태로 바꿔주고
위에서 import해왔던 random함수를 사용하여 무작위수를 생성한뒤 실행해보면
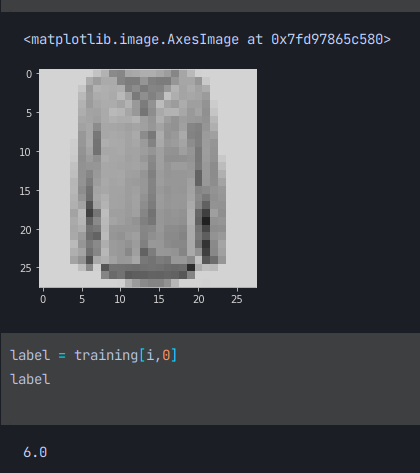
이처럼 6인덱스에 해당하는 셔츠사진이 올바르게 출력된다.
이번엔 하나씩이 아닌 여러가지의 index를 한번에 시각화 해보려 하는데.
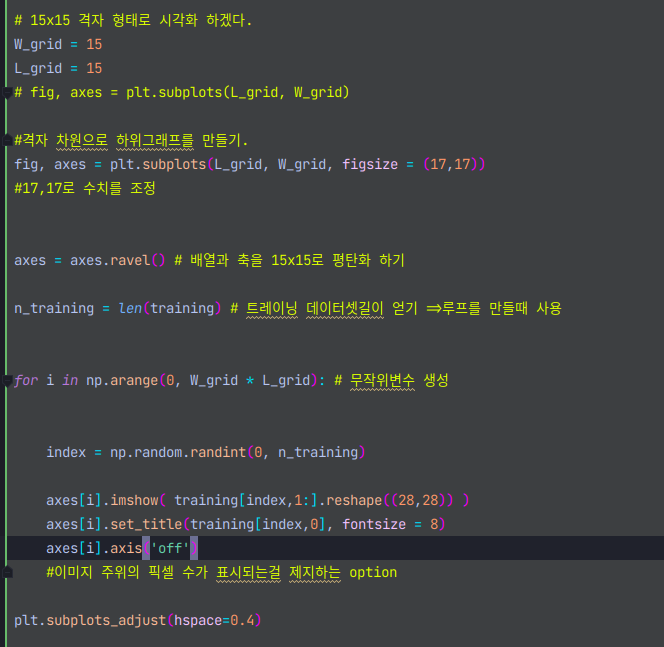
위처럼 격자형태를 지정해주고, subplot생성후 평탄화작업을 수행후 for문 안에서 돌려주면.

이와같이 한번에 여러 index를 시각화 할 수 있다.
TRAINING THE MODEL
Prepare the training and testing dataset
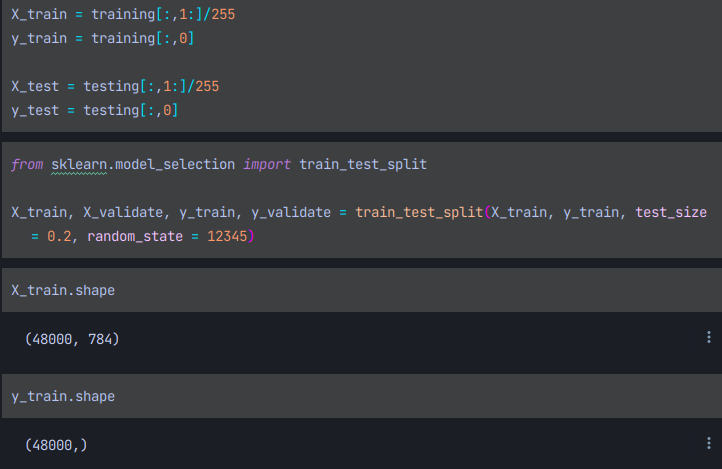
위처럼 표적열을 제외한 후 데이터를 255로 나누어 정규화를 수행해 준다.
그후 y트레인은 x트레인에서 제외했던 표적열만 필요로 하기에 표적열을 할당해 준다.
unpack the tuple
컨볼루션 신경망의 입력형태에 맞게 바꿔주는 부분이다.
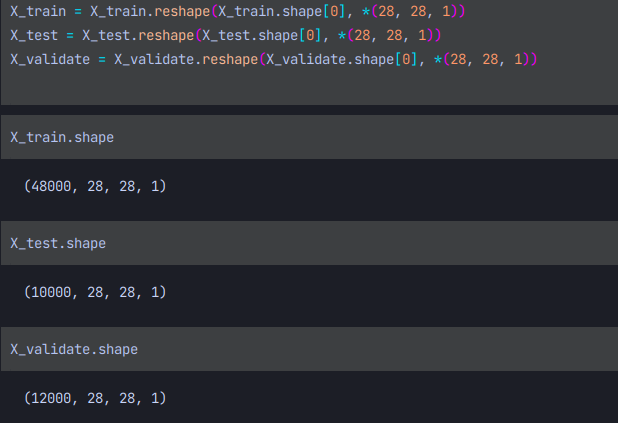
보면 28,28에서 모두 흑백 이미지라는 것을 알 수 있다.
fitting
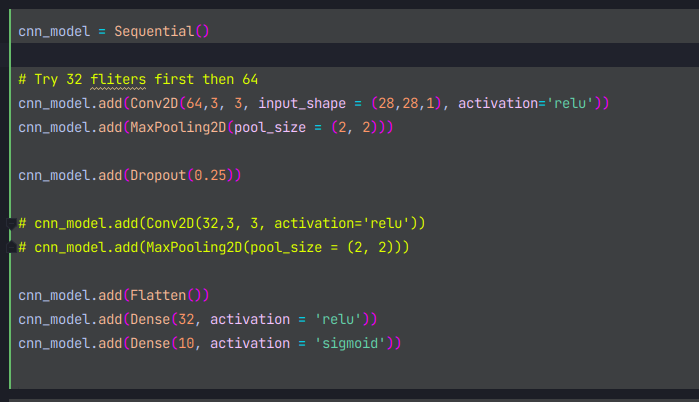
위처럼 작성하면 되는데 활성화 함수는 relu와 sigmoid가 사용된걸 확인할 수 있다.
이제 epochs을 50으로 지정해두고 학습을 시키면 된다.

acc가 0.7에서 시작해서 0.8까지 올라온걸 확인할 수 있다.

EVALUATING THE MODEL
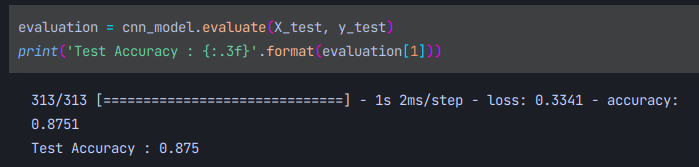
test데이터로 acc를 출력해보면 새로운데이터에 대한 예측을 0.875의 acc로 가능하단걸 알 수 있다.
