자료구조
1.1. Java Features & Algorithms
Reference: Naver boostcourse data structure
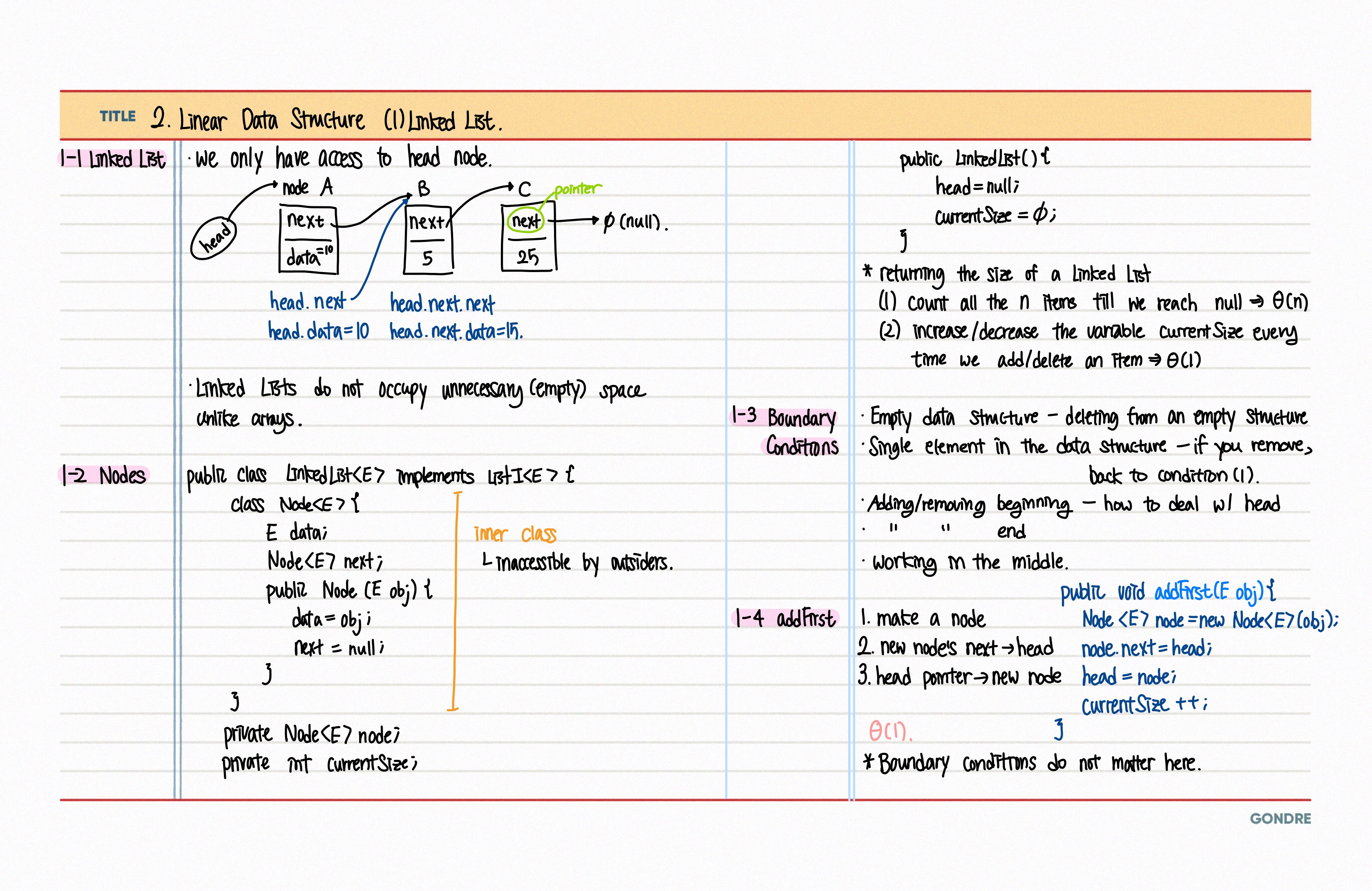
2.2. Linear Data Structure
Reference: Naver boostcourse data structure
3.3. Hashing

Reference: Naver boostcourse data structure
4.4. Heaps and Trees

Reference: Naver boostcourse data structure
5.5. AVL

Reference: Naver boostcourse data structure
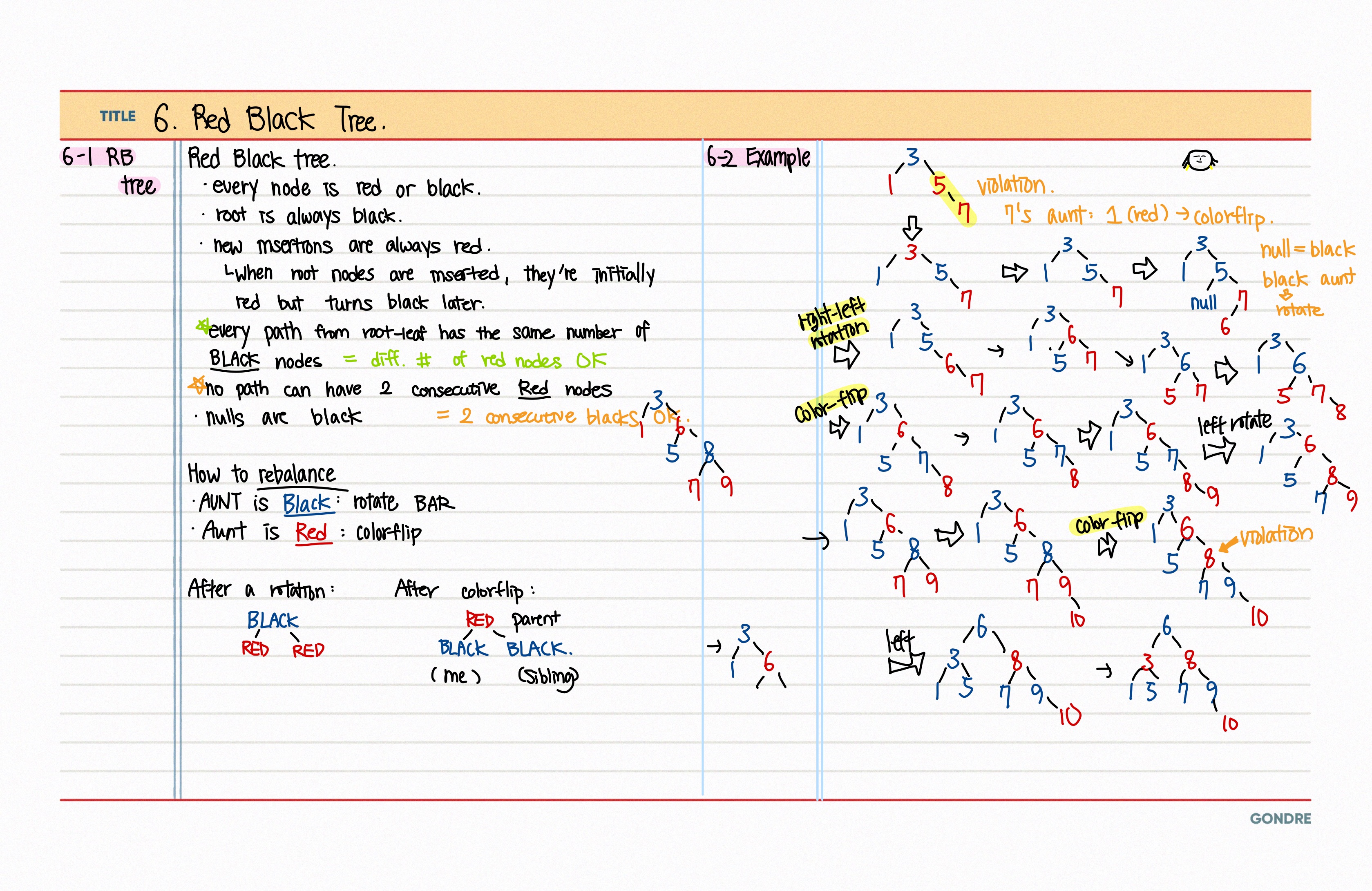
6.6. Red Black Tree
Reference: Naver boostcourse data structure
7.7. Sort

Reference: Naver boostcourse data structure
8.[자료구조] 시간복잡도, 공간복잡도

복잡도가 낮을수록 좋은 알고리즘알고리즘 성능을 평가하기 위한 척도시간 복잡도: 특정한 크기의 입력에 대해 알고리즘의 수행 시간 분석공간 복잡도: 특정한 크기의 입력에 대해 알고리즘의 메모리 사용량 분석 (RAM/하드디스크 메모리 등)시간과 공간은 반비례적 경향이 있는데
9.[자료구조] 링크드 리스트
링크드 리스트: 노드를 연결시킨 자료구조데이터를 갖고 있는 데이터의 묶음장점길이가 가변적임 (배열의 단점 보완)불필요하게 공간을 차지하지 않음 (배열의 단점 보완)단점노드 탐색시 시간 복잡도 문제 배열: 연속된 메모리 공간에 존재링크드 리스트: 메모리 상 떨어져 있는
10.[자료구조] 스택과 큐
Last-in, First-out 방식top으로 정한 곳을 통해서만 접근 가능top은 가장 위의 자료 (가장 최근 들어온 자료)를 가르킴push: top을 통해 삽입하는 연산pop: top을 통해 삭제하는 연산(예) 웹 브라우저 방문기록, 역순 문자열 만들기, 실행 취
11.[자료구조] Hash
해시 테이블key: 고유값hash function의 inputhash function: key를 고정된 길이의 hash로 변경해주는 역할서로 다른 key가 hashing 후 같은 값이 나올 수 있음 > 해시 충돌해시 충돌은 발생확률이 낮을 수록 좋음해시 충돌이 균등하게
12.[자료구조] 트리
자료를 계층적으로(hierarchically) 저장하기 위한 자료구조노드와 링크로 구성모든 노드는 부모-자식 관계root node: 부모가 없는 노드 (구조상 가장 높은 곳의 노드)leaf node(단말 노드): 자식이 없는 노드edge: 부모와 자식을 잇는 선sibl
13.[자료구조] Heap
Priority Queue: 우선순위 개념을 도입한 큐큐인데 우선순위가 높은 데이터 먼저 삭제됨 - 배열/연결리스트/힙으로 구현 가능힙: 완전 이진 트리(Complete BT)의 일종종류: 최대 힙(Max heap), 최소 힙(Min heap)Max heap: 부모 노
14.[자료구조] BBST
Balanced Binary Search Tree, 균형 이진 탐색 트리: 왼쪽 서브트리와 오른쪽 서브트리의 height 차이가 1 이하인 이진트리노드의 삽입/삭제 시에도 높이 차이를 유지해야 함종류: Red-black 트리, AVL 트리트리의 모든 노드는 레드 or
15.[자료구조] 정렬 알고리즘
특징크기 작은 배열에 적합O(1) 공간복잡도stable과정첫 원소부터 시작해서 다음 원소와 비교하여 swap다시 처음부터 하나씩 비교하며 swap더이상 swap할게 없을 때까지 반복특징작은 배열에 적합O(1) 공간 복잡도가장 작은 원소를 찾아 첫 인덱스의 값과 swap
16.[자료구조] 그래프
그래프: 노드와 그 노드를 연결하는 간선을 모아 놓은 자료구조정점(vertex): 위치. aka 노드간선(edge/link/branch): 위치 간의 관계. 노드를 연결하는 선인접 정점(adjacent vertex): 간선에 의해 직접 연결된 정점정점의 차수(degre
17.[자료구조] 최단 거리 구하기
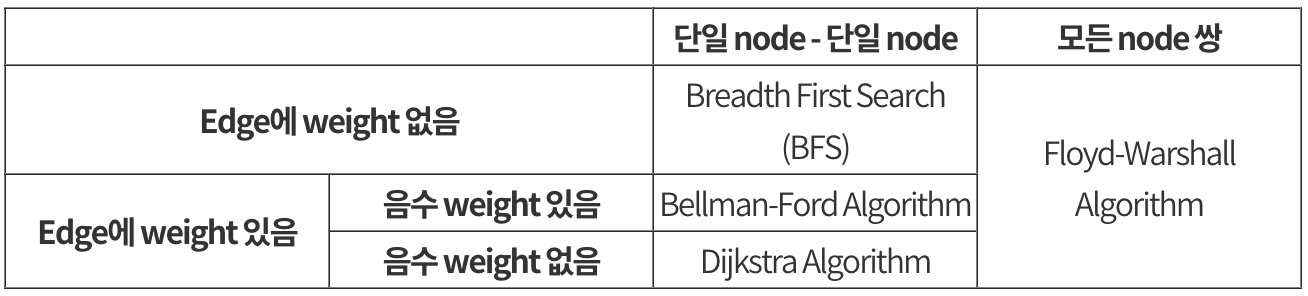
그래프에서 최단거리 구하는 방법BFS/너비 우선 탐색시작 노드로부터 인접한 노드 먼저 방문모든 노드들의 최단 거리 계산용도: 두 노드 사이의 최단 경로/임의의 경로가 필요한 경우트리에서 사용 가능과정시작 노드 방문방문한 노드는 체크 (큐에 방문한 노드 삽입)큐에서 꺼낸
18.[자료구조] MST
Spanning Tree (신장 트리): 그래프 내의 모든 정점을 포함하는 트리그래프의 최소 연결 부분 그래프최소 연결: 간선의 수가 최소n개의 정점을 갖는 그래프의 최소 간선 수는 n-1n-1개의 간선으로 연결하면 필연적으로 트리 형태가 됨즉, 그래프에서 일부 간선을
19.[자료구조] Thread-Safe한 자료구조
java.concurrent 패키지의 thread safe 자료구조: Hashtable, ConcurrentHashMap, AtomicInteger, BlockingQueuesynchronized 키워드 이용다수의 스레드가 하나의 자원을 접근하면 하나의 스레드만 작업을
20.[자료구조] 문자열 저장 자료구조/알고리즘
Trie: 문자열 저장/탐색을 위한 트리 형태의 자료구조DFS으로 검색하면 단어 찾을 수 있음루트 노드: 비어있음나머지 노드: 집합에 포함된 문자열의 prefix부터 시작해서 서브트리로 문자열 형성리프 노드: 문자열의 끝을 나타냄장점: 문자열 탐색/삽입이 빠름삽입: O
21.[자료구조] 이진탐색
이진 탐색: 데이터가 정렬된 배열에서 특정값을 찾아내는 알고리즘배열의 중간에 있는 임의의 값을 선택해 찾고자하는 값과 비교찾고자 하는 값보다 중간 값이 작으면 중간 값을 기준으로 좌측의 데이터 대상으로 다시 탐색찾고자 하는 값보다 중간 값이 크면 중간 값을 기준으로 우
22.[자료구조] 그리디 알고리즘과 다이나믹 프로그래밍
탐욕법현재 상황에서 지금 당장 좋은것만 고르는 방법현재의 선택이 나중에 미칠 영향은 고려하지 않음최적의 답이 보장되지 않음용도애초에 완벽한 답이 필요 없을 때그리디 알고리즘이 최적의 답을 보장해줄 때Dynamic Programming하나의 큰 문제를 여러 개의 작은 문