⏮️ 지난 포스팅
모델 훈련을 위한 준비
아까 만들어둔 3개의 파일 중 나머지 2개를 작성한다. 이렇게 하는 것이 MLflow Projects를 패키징하는 과정이라고 생각하면 된다.
train.py: 모델 학습 시킬 파일MLproject: 전체적인 프로젝트 관리를 위한 파일python_env.yaml: 설치한 라이브러리 의존성 관리를 위한 파일
# MLproject
name: test
python_env: python_env.yaml
entry_points:
main:
parameters:
learning_rate: {type: float, default: 0.1}
max_depth: {type: int, default: 10}
n_estimators: {type: int, default: 256}
command: "python train.py {learning_rate} {max_depth} {n_estimators}"이 파일은 python_env를 통해 필요한 라이브러리를 명시해주고 entry_points를 통해 run 메서드가 실행되면 어떤 커맨드가 실행될 것인지 정한다.
나는 train.py에서 하이퍼 파라미터를 learning_rate, max_depth, n_estimators를 주었기 때문에 run 할 때마다 하이퍼 파라미터를 조정해서 돌려보고 싶기 때문에 위와 같이 작성했다.
그리고, python_env.yaml 파일은 아래와 같이 작성했는데, 이 파일에 필요한 라이브러리를 설치하지 않으면 run을 해도 라이브러리를 잡을 수 없으니 반드시 여기에 작성한다.
# python_env.yaml
python: "3.10.0"
build_dependencies:
- pip
dependencies:
- scikit-learn==1.2.0
- lightgbm
- mlflow>=1.0
- pandas
- utils모델 학습(기본)
현재 폴더 구조는 아래와 같을 것이다.
my_lgbm
├── MLproject
├── lgb_X_train.csv
├── lgb_y_train.csv
├── python_env.yaml
└── train.py이 상태에서 모델을 학습시키고 그 결과를 보기 위해선 단순히 my_lgbm 폴더에 들어간 상태에서 python3 train.py <실험할 learning_rate> <실험할 max_depth> <실험할 n_estimators>를 쉘에 입력하면 된다. 그러면 아래와 같이 mlruns 폴더가 생긴걸 볼 수 있다.
my_lgbm
├── MLproject
├── lgb_X_train.csv
├── lgb_y_train.csv
├── mlruns
│ └── 0
│ ├── 6b328402e144434a9d7a6ffe75b1876f
│ │ ├── artifacts
│ │ │ ├── confusion_matrix.png
│ │ │ ├── feature_importance_gain.json
│ │ │ ├── feature_importance_gain.png
│ │ │ ├── feature_importance_split.json
│ │ │ ├── feature_importance_split.png
│ │ │ ├── lift_curve_plot.png
│ │ │ ├── model
│ │ │ │ ├── MLmodel
│ │ │ │ ├── conda.yaml
│ │ │ │ ├── model.pkl
│ │ │ │ ├── python_env.yaml
│ │ │ │ └── requirements.txt
│ │ │ ├── precision_recall_curve_plot.png
│ │ │ └── roc_curve_plot.png
│ │ ├── inputs
│ │ │ ├── 2a64431835aedbdaa1aa5533ea68c201
│ │ │ │ └── meta.yaml
│ │ │ └── 78efd3c7557d51966e5ace2d8cfcd78c
│ │ │ └── meta.yaml
│ │ ├── meta.yaml
│ │ ├── metrics
│ │ │ ├── accuracy_score
│ │ │ ├── ...
│ │ ├── params
│ │ │ ├── boosting_type
│ │ │ ├── ...
│ │ └── tags
│ │ ├── mlflow.datasets
│ │ ├── ...
│ ├── datasets
│ │ ├── 63cfb5f42010bae9d190dbbbaae883ab
│ │ │ └── meta.yaml
│ │ └── 9a6e52ba0575d59237a3887935f0e0b5
│ │ └── meta.yaml
│ └── meta.yaml
├── python_env.yaml
└── train.py그 다음 실험 결과는 커맨드 창에 mlflow server 혹은 mlflow ui를 입력하여 기본 주소인 http://127.0.0.1:5000 로 들어가 확인할 수 있다.
모델 학습(심화)
하지만, 위의 상태로는 단순히 모델 학습만 간단히 하는 것이고, 팀 내의 다양한 상황에 적용하기 어렵기 때문에 한 모델 당 experiments(모델을 실험하는 장소)를 나누고 그 안에서 패키징 하여 MLflow Project로써 관리하는 게 좋다. 따라서, 아래와 같은 순서를 따라준다.
$ mlflow experiments create -n <설정하고 싶은 이름>그러면 현재 있는 my_lgbm 폴더 바깥에 mlruns라는 폴더가 생성된 것을 볼 수 있고, 그 안에 이런 식의 폴더가 있는 것을 볼 수 있다.
저기 있는 0과 715..로 시작하는 폴더가 experiments이다. 저 번호를 잘 기억해두었다가, root 폴더로 나와 아래와 같이 입력한다. 하이퍼 파라미터는 대충 적었다.
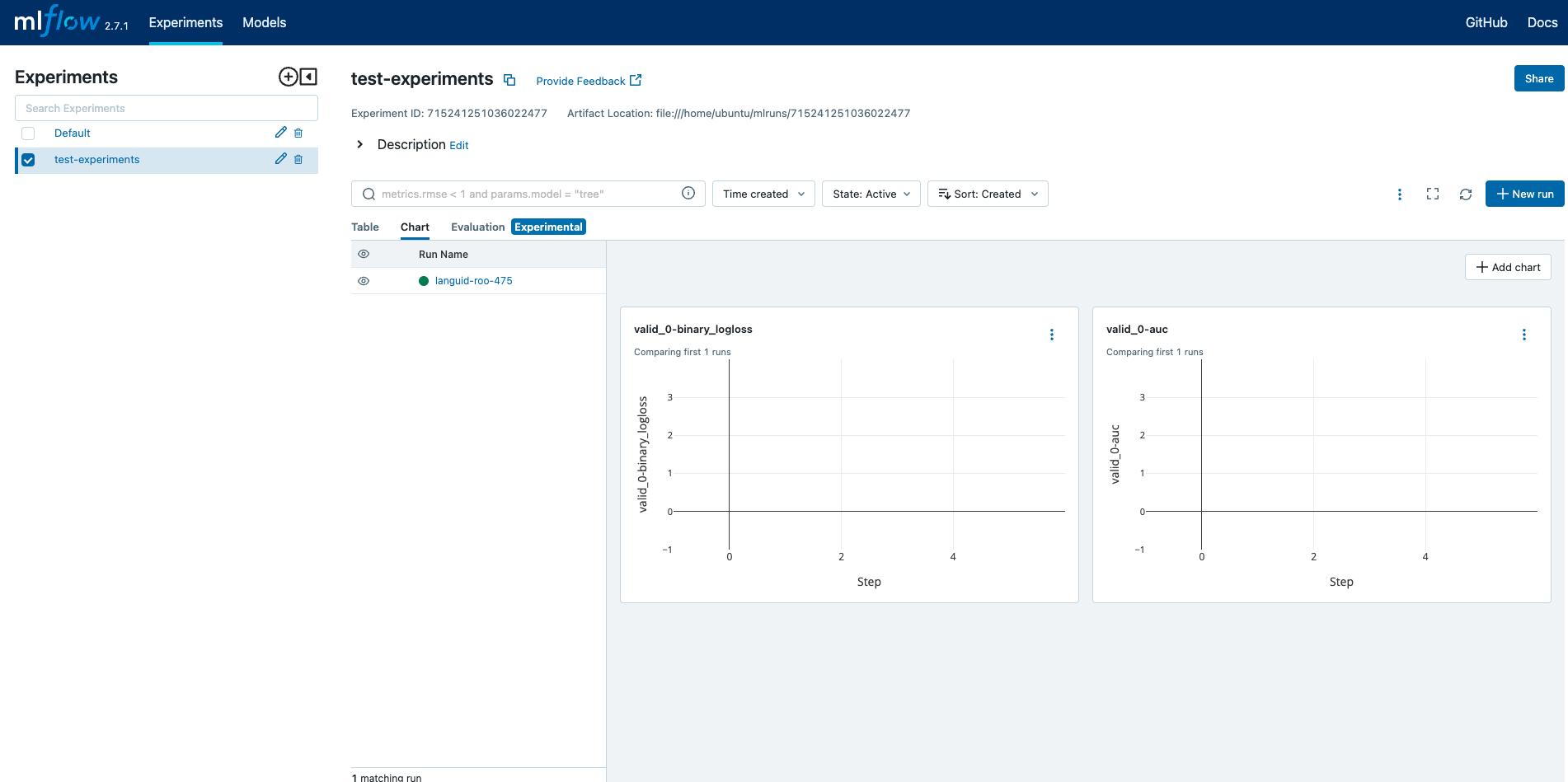
$ mlflow run my_lgbm -P learning_rate=0.3 -P max_depth=6 -P n_estimators=1000 --experiment-id 715241251036022477이런 커맨드를 입력하면 여러 난수 폴더명이 생기는 데 그 폴더들 하나하나가 experiments에서 실행한 run들이라고 생각하면 된다. 그런 다음 다시 mlflow server 혹은 mlflow ui를 입력하여 기본 주소인 http://127.0.0.1:5000 로 들어가 확인해보면 아래와 같은 화면을 만날 수 있다.
왼쪽에 Experiments에 mlflow experiments create -n <설정하고 싶은 이름>에서 설정한 이름의 experiments가 생성된 것을 볼 수 있고, 방금 run 시킨 학습에 대한 지표도 볼 수 있다.
모델 등록
학습이 끝나고 "아 요 모델은 저장해둬도 되겠다!"싶은 run 결과는 MLflow Model Registry에 등록해두어야 한다.
RestAPI, Python API, UI 등 다양한 방법이 있으니 공식문서에서 참고하길 바라며, 나는 UI로 등록하는 법을 작성해보겠다.
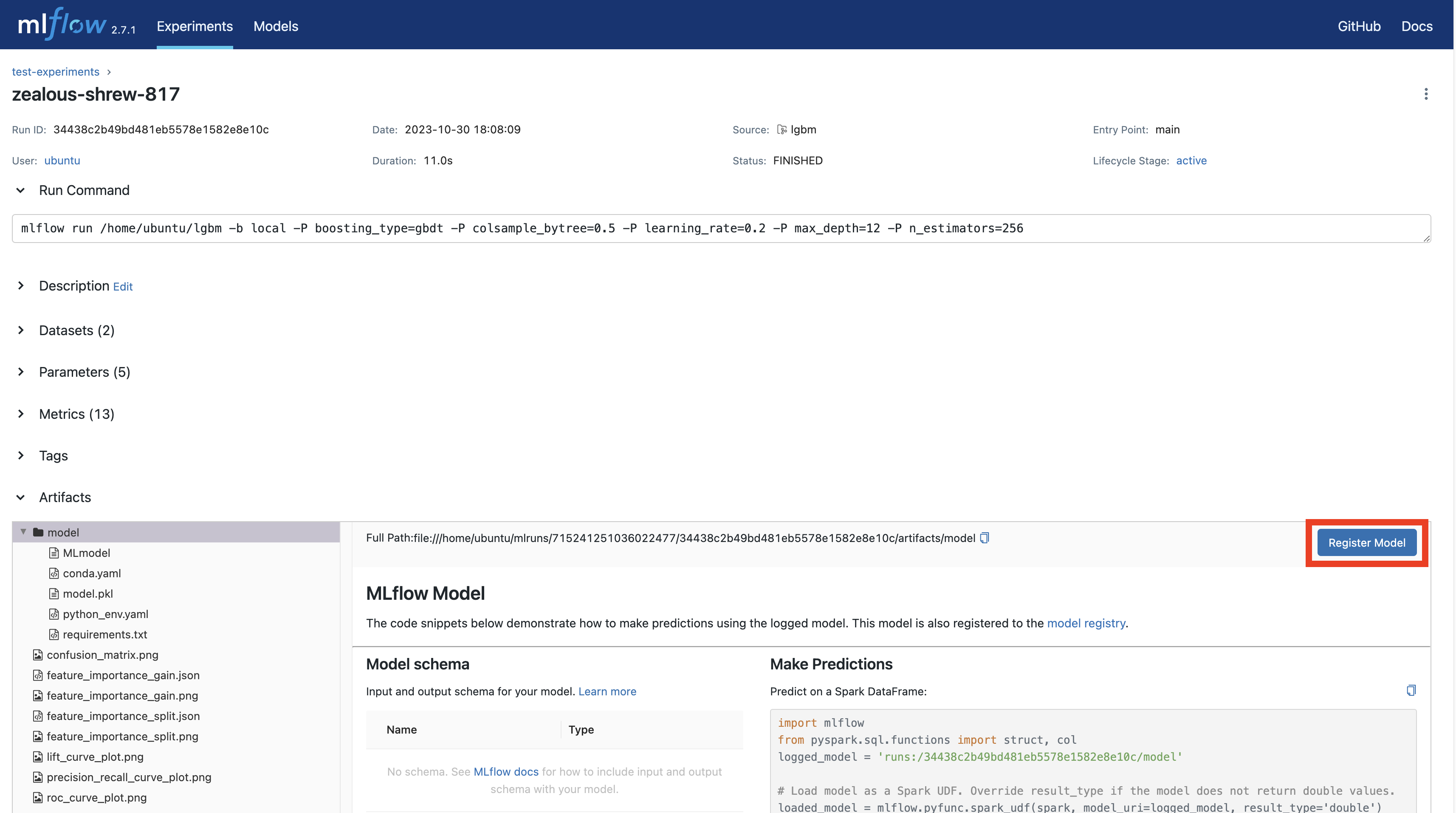
http://localhost:5000으로 접속 후, 해당하는 run 결과를 클릭하고 들어가면 아래와 같은 화면이 나올텐데 거기서Register Model버튼을 눌러준다.
- Models 페이지에 들어가 확인한다.

-
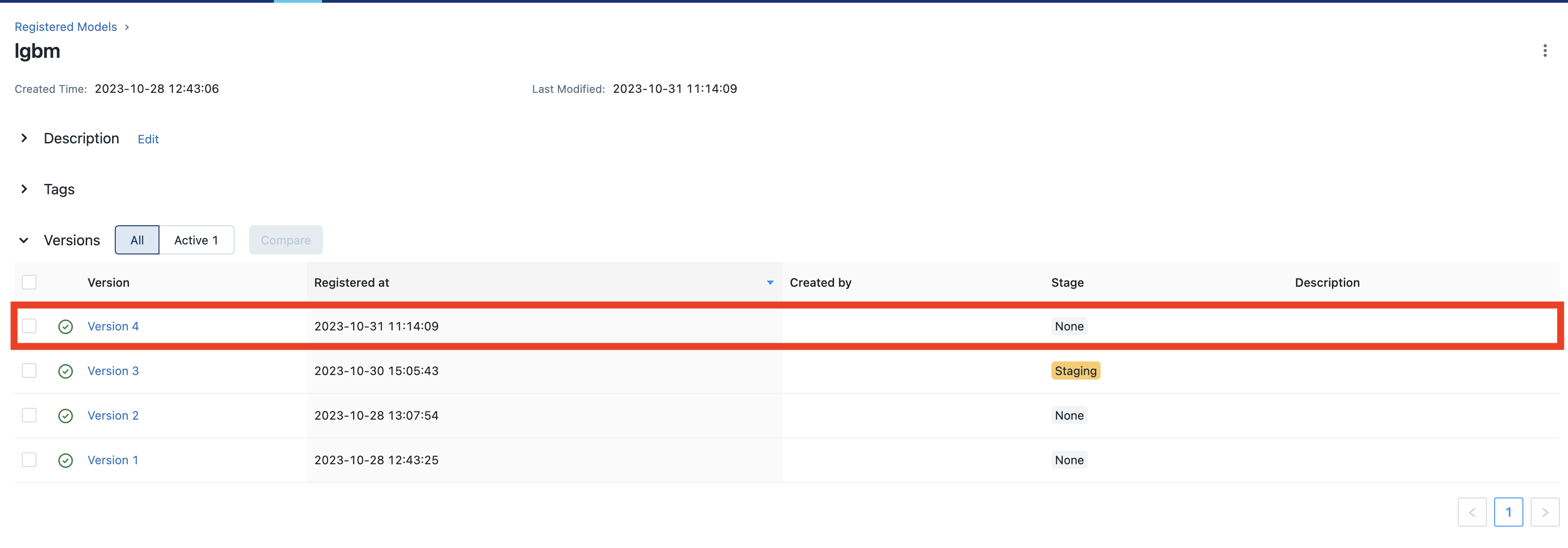
방금 등록한 run이 있는지 확인 후 클릭하여 들어간다.
-
모델의 상태를 선택하고 그 상태를 잘 기억해둔다.
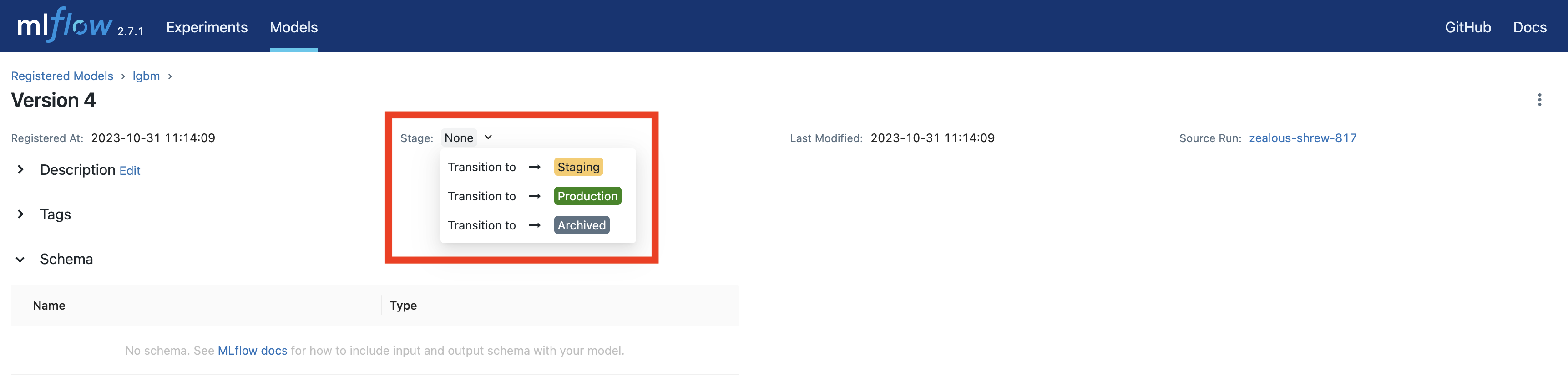
모델을 등록했다!
모델 배포
모델 배포는 생각보다 간단하다. 커맨드 라인에 아래와 같이 써주면 된다.
mlflow models serve -m "models:/<Registerd Models 이름>/<단계>" --port 5002
# 예시
mlflow models serve -m "models:/lgbm/Staging" --port 5002이렇게 되면 localhost 5002번 포트를 통해 모델에 input을 던지고 예측 결과를 받을 수 있다.
마무리
오픈 소스이지만 공식 문서가 상당히 잘 되어 있다. 따라서 더 필요한 공부는 공식 문서를 많이 참조 하면 좋을 것 같다. 다만, 최근 2.7.1 버전으로 업데이트 하면서 커맨드에서 세세한 부분이 업데이트가 많이 되었으니, 버전을 잘 확인하면서 구글링 해야 할 것이다.
