
머신러닝
머신러닝 분류
지도 학습
- 주어진 입력으로부터 출력 값을 예측하고자 할 때 사용
- 입력과 정답 데이터를 사용해 모델을 학습
분류
- 입력 데이터를 미리 정의된 여러 클래스 중 하나로 예측하는 것
- 클래스 개수가 2개면 이진 분류, 3개 이상이면 다중 분류
회귀
- 연속적인 숫자를 예측하는 것, 출력 값이 연속성을 가짐
지도학습 알고리즘
- Linear Regression
- Logistic Regression
- Support Vector Machine
- k-Nearest Neighbors
- Decision Tree
- Ensemble
- Neural Networks
비지도 학습
- 원하는 출력 없이 입력 데이터를 사용
- 입력 데이터의 구조나 패턴을 찾는 것이 목표
클러스터링
- 공간상에서 서로 가깝고 유사한 데이터를 클러스터로 그룹화
- k-Means, DBSCAN, 계층 군집 분석, 이상치 탐지, 특이값 탐지
차원 축소
- 고차원 데이터에 대해 많은 정보를 잃지 않으면서 데이터를 축소
- PCA, kernel PCA, t-SNE
연관 규칙
- 데이터에서 특성 간의 연관성이 있는 흥미로운 규칙을 찾는 방법
- Apriori, Eclat
준지도 학습
- 레이블이 있는 것과 없는 것이 혼합된 경우
- 일부 데이터에만 레이블이 있음
- 지도 학습 알고리즘 + 비지도 학습 알고리즘 조합으로 구성
강화 학습
- 동적 환경과 함께 상호 작용하는 피드백 기반 학습 방법
- Agent가 환경을 관찰하고, 행동을 실행하고, 보상 or 벌점 받음
- Agent는 피드백을 통해 자동으로 학습하고 성능 향상
- 어떠한 지도가 없이 일정한 목표 수행
온라인 학습
- 적은 데이터를 사용해 미니배치 단위로 점진적 학습
- 실시간 시스템이나 메모리 부족 시 사용
배치 학습
- 전체 데이터를 모두 사용해 오프라인에서 학습
- 컴퓨팅 자원이 풍부한 경우 사용
일반화, 과대적합, 과소적합
일반화
- 훈련된 모델이 처음보는 데이터에 대해 정확하게 예측하는 상태
과대적합
- 주어진 훈련 데이터에 비해 복잡한 모델을 사용하여, 훈련 데이터에서만 정확한 성능을 보이고, 평가 데이터에서는 낮은 성능을 보임
과소적합
- 주어진 훈련 데이터에 비해 간단한 모델을 사용하여, 훈련 데이터에서도 나쁜 성능, 평가 데이터에서도 낮은 성능을 보임
모델 복잡도
- 데이터 다양성 클수록 복잡한 모델을 사용하면 좋은 성능
- 큰 데이터셋일수록 다양성 높아서 복잡한 모델 사용 가능
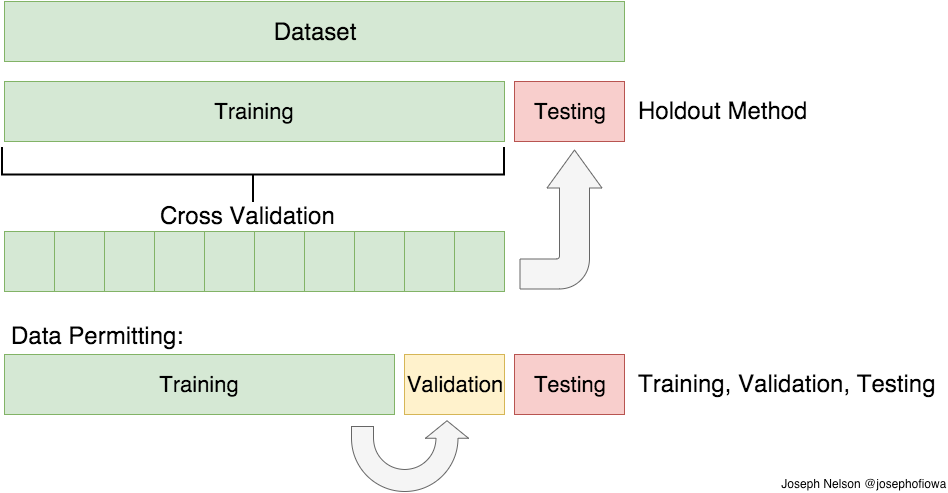
훈련세트 vs 테스트 세트 vs 검증 세트
- 모델의 일반화 성능을 측정하기 위해 훈련, 테스트로 구분
- 훈련 세트로 모델 학습, 테스트 세트로 모델 일반화 성능 측정
- 하이퍼파라미터는 알고리즘 조절 위한 사전 정의 파라미터
- 모델 선택을 위해 훈련, 테스트, 검증 세트로 구분

ComputerVision 누구냐 넌